







NVIDIA TensorRT 是一个高性能的深度学习推理 SDK,专为在 NVIDIA GPU 上加速深度学习模型的推理过程而设计。它支持多种主流深度学习框架,如 TensorFlow、PyTorch 等,并通过一系列优化技术提高模型的推理速度和效率。
主要功能和优势
-
性能优化:TensorRT 通过层和张量融合、内核自动调整、多流并行等技术,显著提高推理性能。
-
降低延迟:优化后的模型可以显著降低推理延迟,这对实时应用(如视频分析和自动驾驶)非常重要。
-
减少内存占用:通过优化神经网络的内存使用,降低对 GPU 资源的要求。
-
支持多种精度:TensorRT 支持 FP32、TF32、FP16 和 INT8 精度,可以根据应用场景灵活调整计算精度,权衡计算速度与模型精度。
-
跨平台支持:支持从多种框架导出模型,并通过 ONNX 标准使其与 TensorRT 兼容
1、下载安装包【迅雷网盘-下载速度快】请转存文件,后续会持续更新教程资源
2、网盘下载ComfyUI_TensorRT.zip插件包

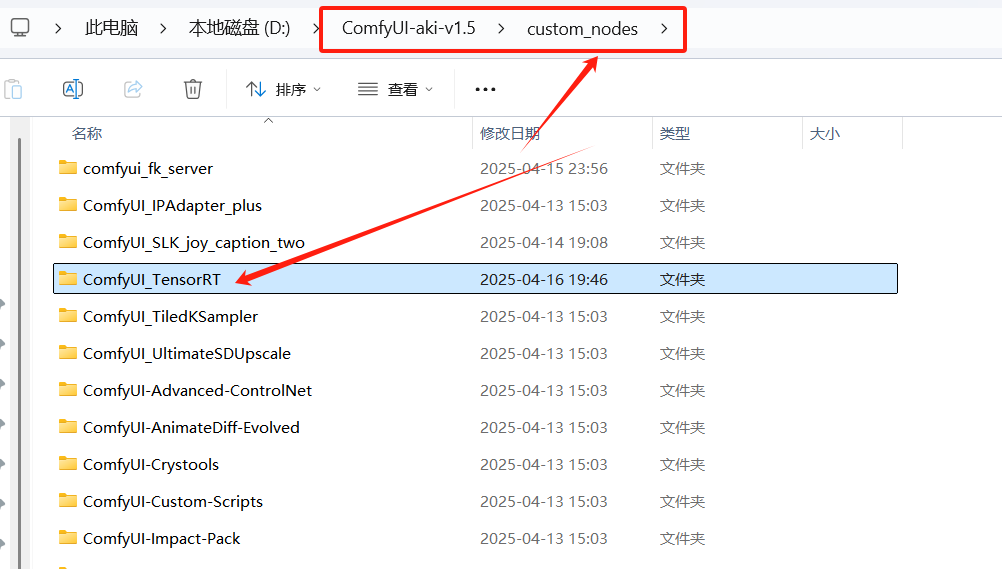
3、将ComfyUI_TensorRT.zip解压到comfyui安装目录下的custom_nodes目录下,如图:
4、启动comfyui【下载依赖包需要一点时间请耐心等待】
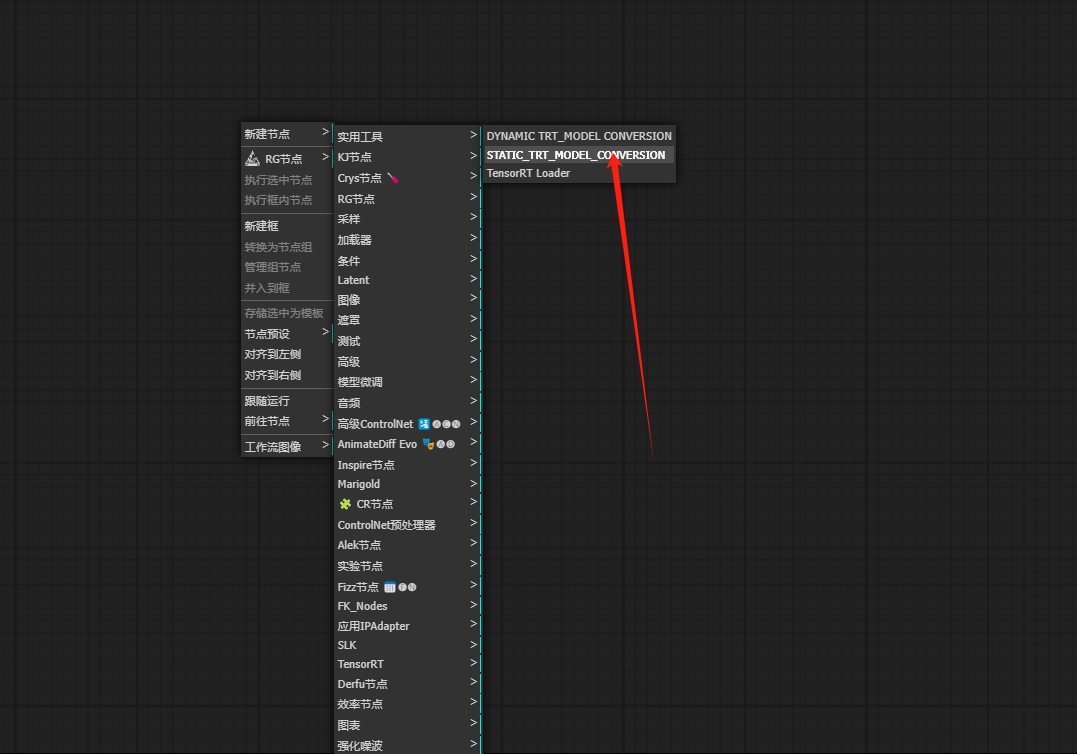
5、训练加速模型【创建静态转换模型】
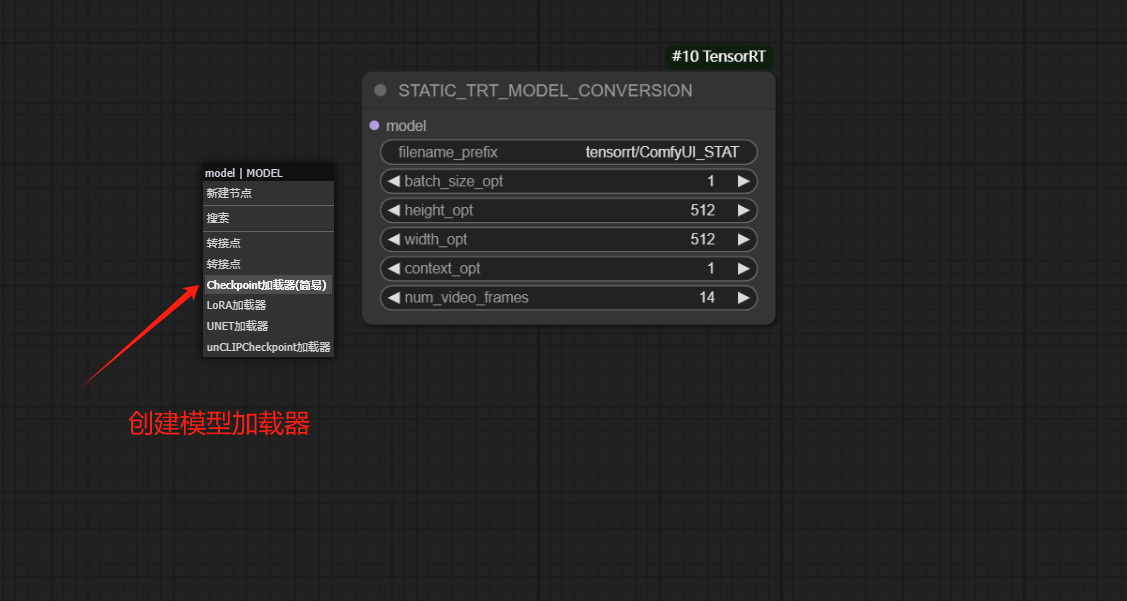
6、训练加速模型【创建模型加载器】
7、训练TensoRT加速模型:按【ctrl+enter】运行模型或者点击【执行】
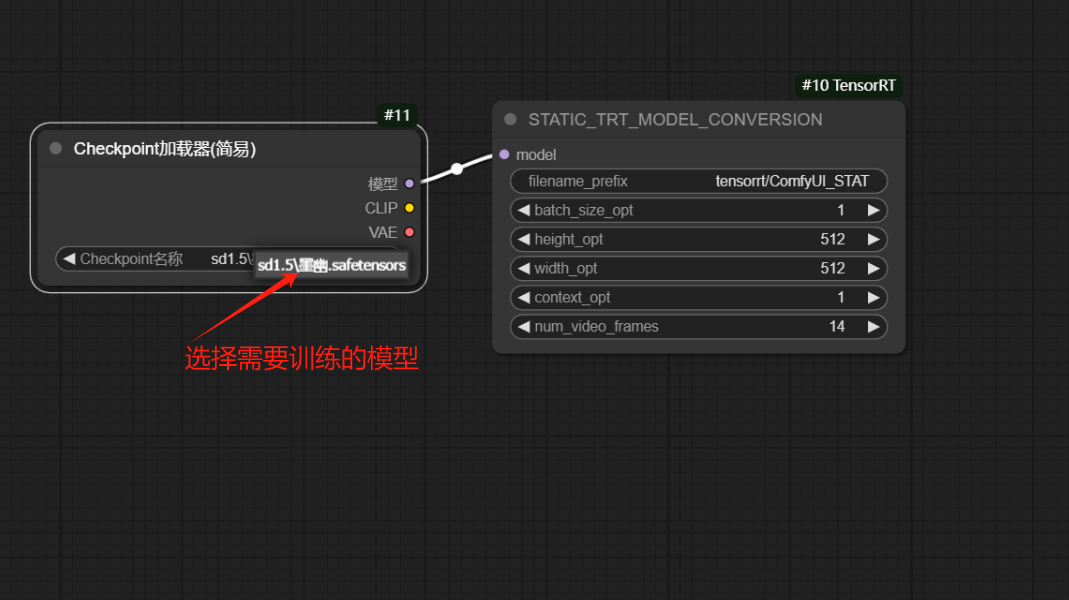
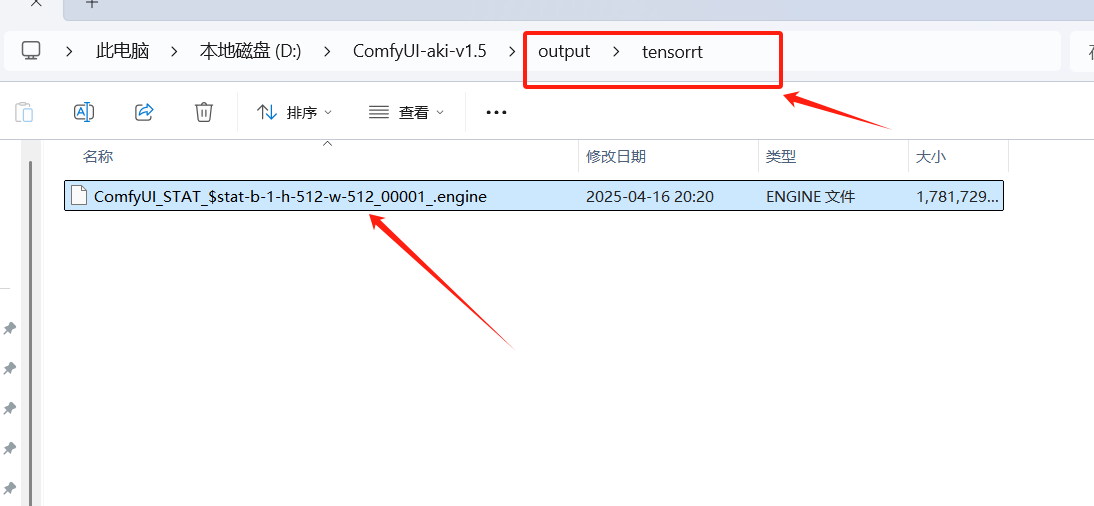
8、找到训练好的加速模型:
9、使用上一章节中创建的文生图工作流:【网盘下载工作流】
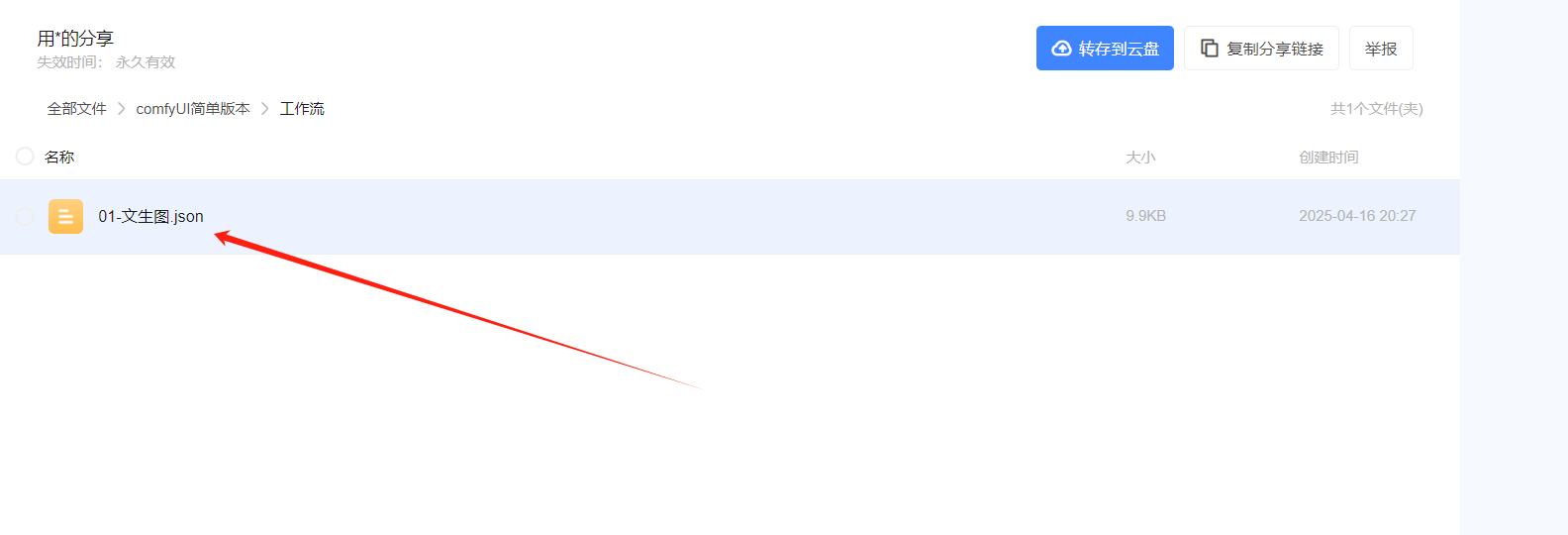
10、导入工作流:

11、替换模型为训练好的加速模型:【创建加速模型加载器】
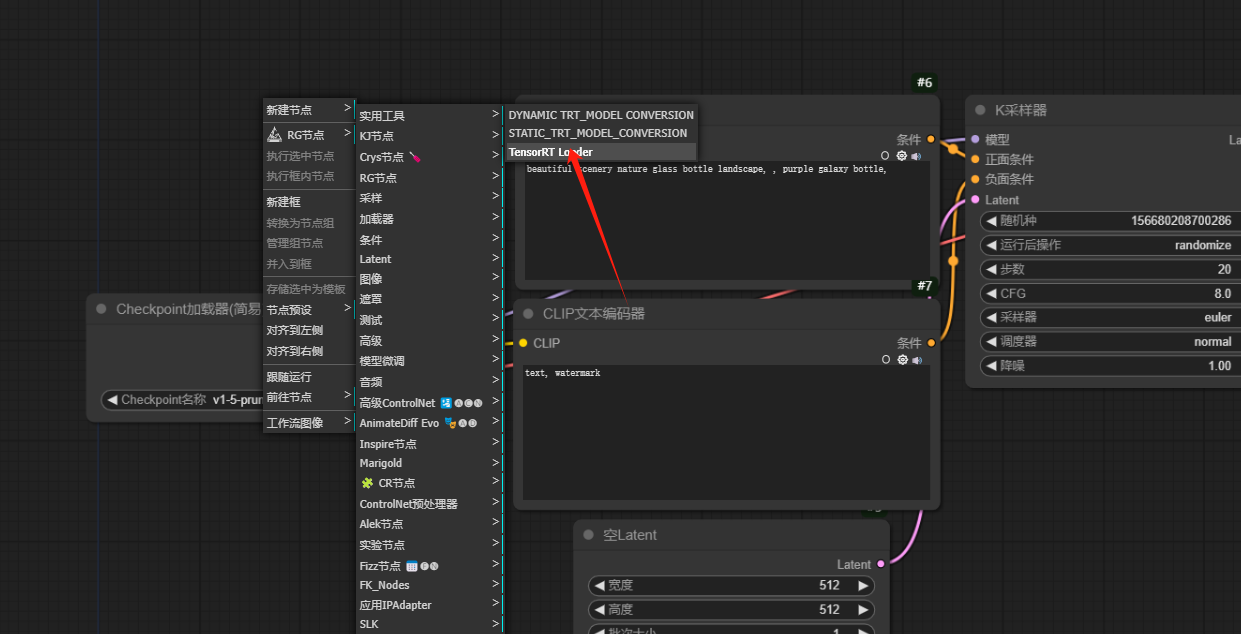
12、替换模型,将加速模型与k采样器连接起来
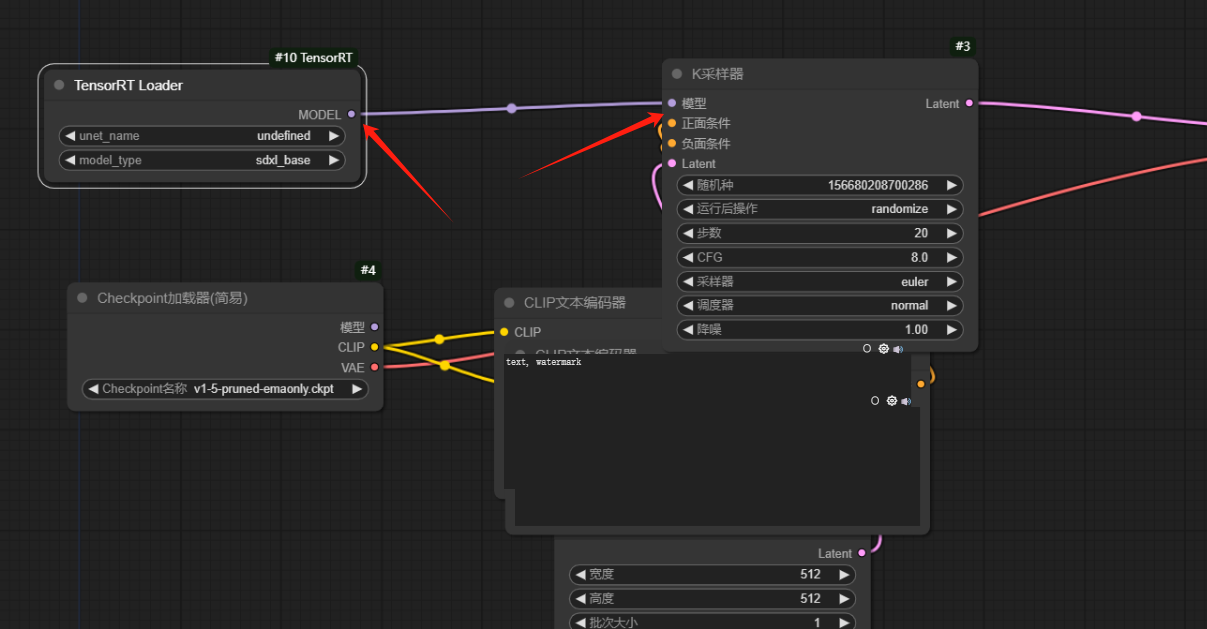
13、选择训练好的大模型和对应的加速模型:【注意这里需要重启comfyui不然训练好的模型会找不到】
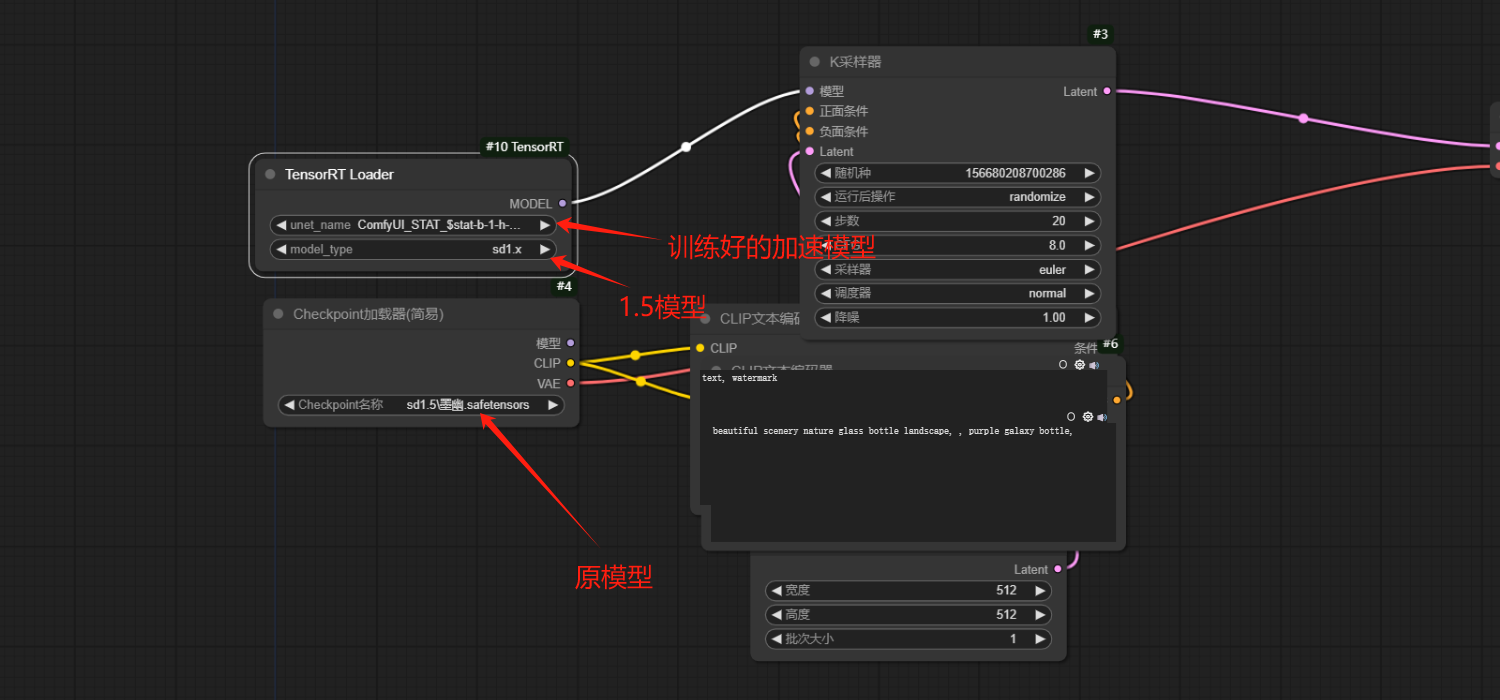
14、运行加速模型按【ctrl+enter】总耗时只有原来的一半
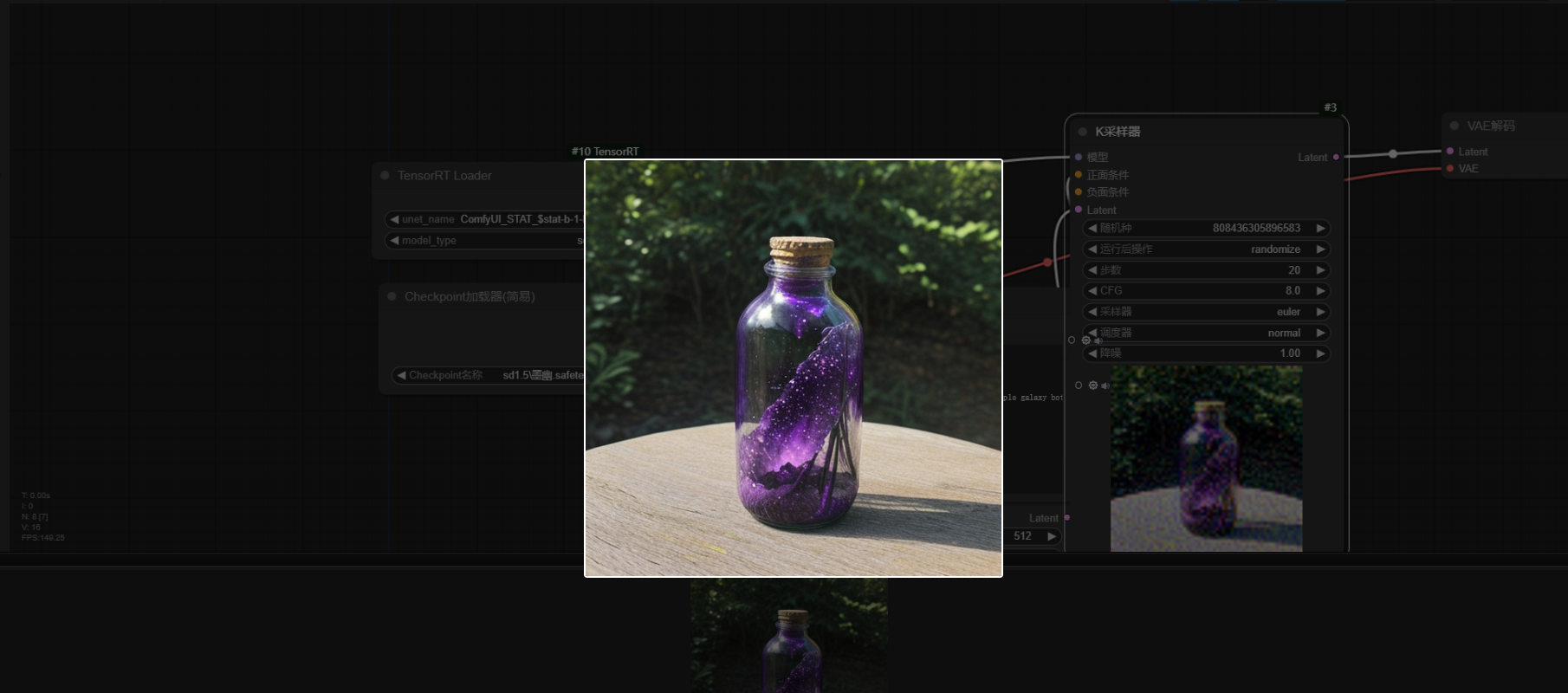
15、请去网盘下载我修改的工作流,用于参考:



















 5302
5302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











