







文章简述
本文简单列出了编写Tensorrt插件所需要的关键方法,分为两个部分,一是插件类的具体实现方法,另外是插件工厂的调用方法,插件类最终将编译为.so文件,使用时在c++或python中调用,所以插件类的方法调用在其他部分,在本文中难以直观的体现调用流程,需编写并运行代码,体验各个方法在插件生命周期中的作用。关于插件工厂的构造与调用在本文进行了解释。本文参考如下:
-
1.大牛的网络笔记
-
2.官方文档
-
3.官方提供的插件例子:
-
https://github.com/NVIDIA/TensorRT/tree/master/plugin
-
https://github.com/NVIDIA/TensorRT/tree/release/7.2/plugin
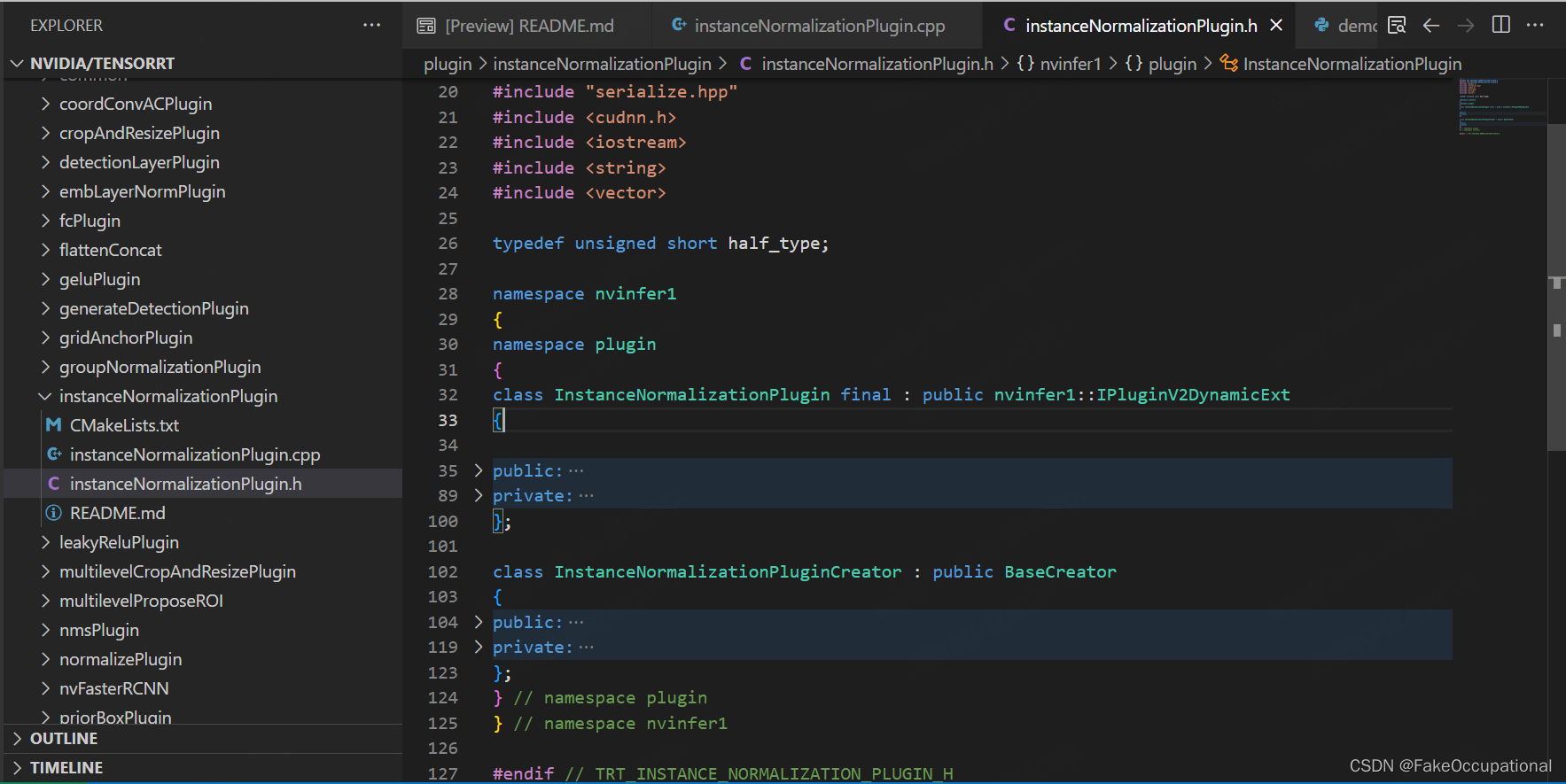
- class InstanceNormalizationPlugin final : public nvinfer1::IPluginV2DynamicExt 继承IPluginV2DynamicExt,是插件类,用于写插件具体的实现
- class InstanceNormalizationPluginCreator : public BaseCreator 继承BaseCreator,是插件工厂类,用于根据需求创建该插件
class LReLU : public BasePluginhttps://github1s.com/NVIDIA/TensorRT/blob/release/7.2/plugin/leakyReluPlugin/lReluPlugin.h#L32
流程简述

// https://github1s.com/NVIDIA/TensorRT/blob/release/7.2/plugin/fcPlugin/fcPlugin.cpp#L570-L579
// IPluginV2 Methods
const char* FCPluginDynamic::getPluginType() const
{
return FC_NAME;
}
const char* FCPluginDynamic::getPluginVersion() const
{
return FC_VERSION;
}
//https://github1s.com/NVIDIA/TensorRT/blob/release/7.2/plugin/fcPlugin/fcPlugin.cpp#L646-L654
const char* FCPluginDynamicCreator::getPluginName() const
{
return FC_NAME;
}
const char* FCPluginDynamicCreator::getPluginVersion() const
{
return FC_VERSION;
}
//https://github1s.com/NVIDIA/TensorRT/blob/release/7.2/plugin/fcPlugin/fcPlugin.cpp#L49
REGISTER_TENSORRT_PLUGIN(FCPluginDynamicCreator);
=============
// https://github1s.com/NVIDIA/TensorRT/blob/release/7.2/include/NvInferRuntimeCommon.h#L1351-L1354
//!
//! \brief Return the plugin registry
//!
extern "C" TENSORRTAPI nvinfer1::IPluginRegistry* getPluginRegistry();
插件类
父类
-
class MyCustomPlugin final : public nvinfer1::IPluginV2DynamicExtExt类 IPluginV2DynamicExt
-
IPluginV2DynamicExt中有很多纯虚函数,描述了继承这个类的函数规范,继承时必须要重写。
注:
| TensorRT版本 | 混合精度 | 动态大小输入 | Requires extended runtime | example | |
|---|---|---|---|---|---|
| IPluginV2Ext | 5.1 | Limited | No | No | |
| IPluginV2IOExt | 6.0.1 | General | No | No | https://github1s.com/NVIDIA/TensorRT/blob/release/7.2/samples/opensource/sampleUffPluginV2Ext/sampleUffPluginV2Ext.cpp#L337 |
| IPluginV2DynamicExt | 6.0.1 | General | Yes | Yes |
IPluginV2插件的工作流
parse phase/ parse阶段
-
在模型的parse阶段会通过CustomPlugin(const Weights *weights, int nbWeights)创建模型中每一个自定义层的实例,
-
在这个阶段还会调用到getNbOutputs()和getOutputDimensions()来获取自定义层的输出tensor个数和维度。这个步骤的目的是为了构建整一个模型的工作流.如果自定义层的输出个数和维度跟其他层匹配不上,parse就会失败.所以如果你的自定义层在parse阶段就parse失败了,可以先检查一下这两个函数的实现.
-
这个阶段创建的CustomPlugin实例会在engine构建阶段(下一阶段)被析构掉.
build engine phase / engine构建阶段
- engine构建阶段会再次通过CustomPlugin(const Weights *weights, int nbWeights)创建自定义层的实例.然后调用supportFormat()函数来检查自定义层的支持的Datatype和PluginFormat, 在build的过程中,会调用configureWithFormat,根据设定的类型(见参数)对插件进行配置.调用完这个函数之后,自定义层内部的状态和变量应该被配置好了.在这里也会调用getWorksapceSize(),但是这个函数不怎么重要.最后会调用initialize(),进行初始化.此时已经准备好所有准备的数据和参数可以进行执行了.构建结束后当调用builder, network或者 engine的destroy()函数时,会调用CustomPlugin的destroy()方法析构掉CustomPlugin对象.
InstanceNormalizationPlugin::InstanceNormalizationPlugin(
float epsilon, nvinfer1::Weights const& scale, nvinfer1::Weights const& bias)
: _epsilon(epsilon)
, _nchan(scale.count)
, _d_scale(nullptr)
, _d_bias(nullptr)
, _d_bytes(0)
{
ASSERT(scale.count == bias.count);
if (scale.type == nvinfer1::DataType::kFLOAT)
{
_h_scale.assign((float*) scale.values, (float*) scale.values + scale.count);
}
else if (scale.type == nvinfer1::DataType::kHALF)
{
_h_scale.reserve(_nchan);
for (int c = 0; c < _nchan; ++c)
{
unsigned short value = ((unsigned short*) scale.values)[c];
_h_scale.push_back(__internal_half2float(value));
}
}
else
{
throw std::runtime_error("Unsupported scale dtype");
}
if (bias.type == nvinfer1::DataType::kFLOAT)
{
_h_bias.assign((float*) bias.values, (float*) bias.values + bias.count);
}
else if (bias.type == nvinfer1::DataType::kHALF)
{
_h_bias.reserve(_nchan);
for (int c = 0; c < _nchan; ++c)
{
unsigned short value = ((unsigned short*) bias.values)[c];
_h_bias.push_back(__internal_half2float(value));
}
}
else
{
throw std::runtime_error("Unsupported bias dtype");
}
}
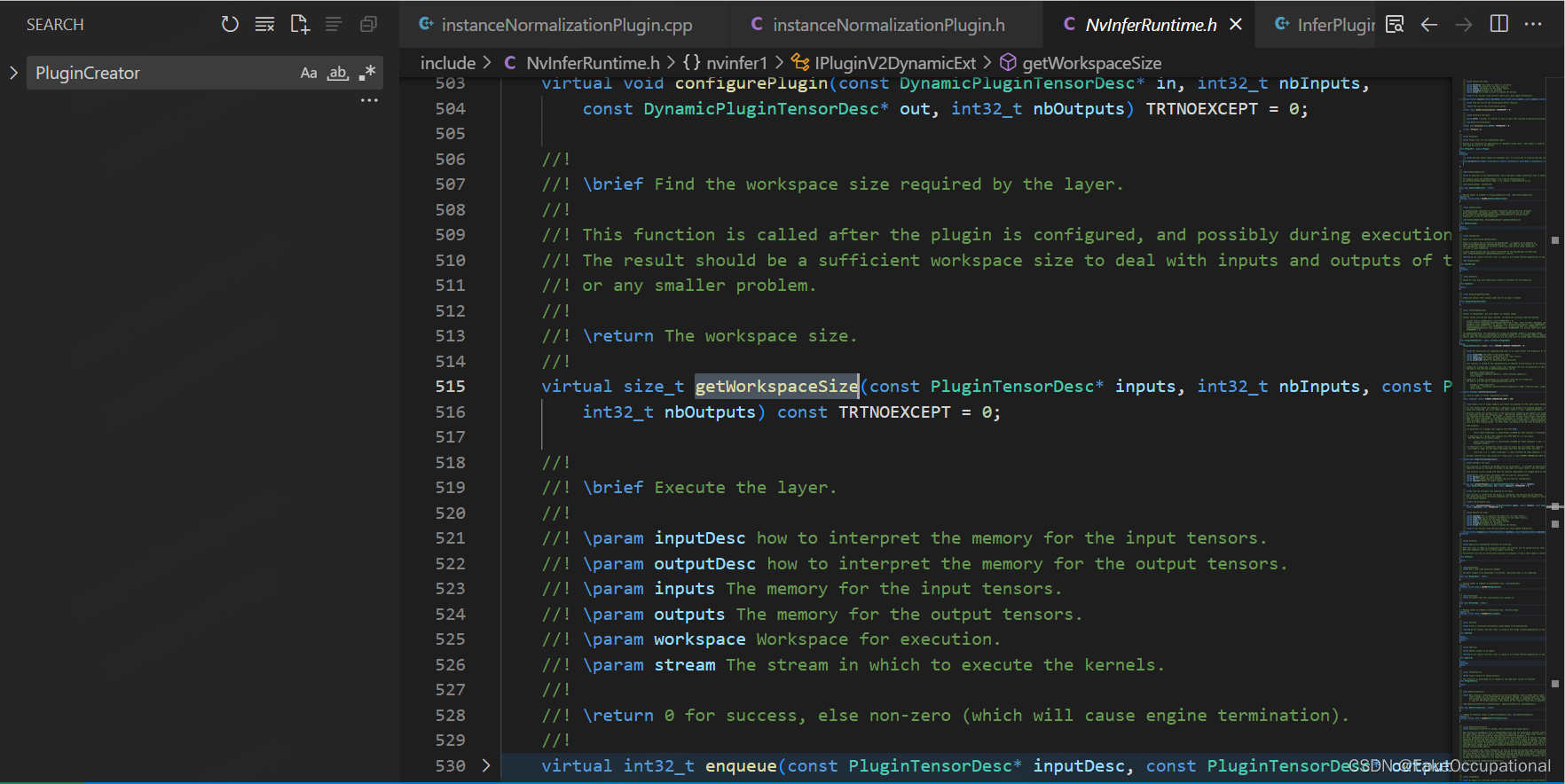
size_t InstanceNormalizationPlugin::getWorkspaceSize(const nvinfer1::PluginTensorDesc* inputs, int nbInputs,
const nvinfer1::PluginTensorDesc* outputs, int nbOutputs) const
{
return 0;
}
int InstanceNormalizationPlugin::initialize()
{
return 0;
}
注
这个函数需要返回这个插件op需要中间显存变量的实际数据大小(bytesize),这个是通过TensorRT的接口去获取,是比较规范的方式。
我们需要在这里确定这个op需要多大的显存空间去运行,在实际运行的时候就可以直接使用TensorRT开辟好的空间而不是自己去申请显存空间。
// https://zhuanlan.zhihu.com/p/297002406
size_t MyCustomPlugin::getWorkspaceSize(const nvinfer1::PluginTensorDesc* inputs, int nbInputs, const nvinfer1::PluginTensorDesc* outputs, int nbOutputs) const
{
// 计算这个op前向过程中你认为需要的中间显存数量
size_t need_num;
return need_num * sizeof(float);
}
save engine phase / 引擎保存阶段
保存引擎到序列化文件会调用getSerializationSize()函数来获取序列化所需要的空间,在保存的过程中会调用serialize()函数将自定义层的相关信息序列化到引擎文件.
// https://github1s.com/NVIDIA/TensorRT/blob/release/7.2/plugin/instanceNormalizationPlugin/instanceNormalizationPlugin.cpp#L129
InstanceNormalizationPlugin::InstanceNormalizationPlugin(void const* serialData, size_t serialLength)
{
deserialize_value(&serialData, &serialLength, &_epsilon);
deserialize_value(&serialData, &serialLength, &_nchan);
deserialize_value(&serialData, &serialLength, &_h_scale);
deserialize_value(&serialData, &serialLength, &_h_bias);
}
engine running phase / 引擎推理阶段
-
在这个阶段会调用用
enqueue()进行模型推理 -
https://github1s.com/NVIDIA/TensorRT/blob/release/7.2/plugin/instanceNormalizationPlugin/instanceNormalizationPlugin.cpp#L172
int InstanceNormalizationPlugin::enqueue(const nvinfer1::PluginTensorDesc* inputDesc,
const nvinfer1::PluginTensorDesc* outputDesc, const void* const* inputs, void* const* outputs, void* workspace,
cudaStream_t stream)
{
nvinfer1::Dims input_dims = inputDesc[0].dims;
int n = input_dims.d[0];
int c = input_dims.d[1];
int h = input_dims.d[2];
int w = input_dims.d[3] > 0 ? input_dims.d[3] : 1;
size_t nchan_bytes = c * sizeof(float);
// Note: We repeat the data for each batch entry so that we can do the full
// computation in a single CUDNN call in enqueue().
if (_d_bytes < n * nchan_bytes)
{
cudaFree(_d_bias);
cudaFree(_d_scale);
_d_bytes = n * nchan_bytes;
CHECK_CUDA(cudaMalloc((void**) &_d_scale, _d_bytes));
CHECK_CUDA(cudaMalloc((void**) &_d_bias, _d_bytes));
}
for (int i = 0; i < n; ++i)
{
CHECK_CUDA(cudaMemcpy(_d_scale + i * c, _h_scale.data(), nchan_bytes, cudaMemcpyHostToDevice));
CHECK_CUDA(cudaMemcpy(_d_bias + i * c, _h_bias.data(), nchan_bytes, cudaMemcpyHostToDevice));
}
CHECK_CUDNN(cudnnSetTensor4dDescriptor(_b_desc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, 1, n * c, 1, 1));
cudnnDataType_t cudnn_dtype{};
CHECK_CUDNN(convert_trt2cudnn_dtype(inputDesc[0].type, &cudnn_dtype));
CHECK_CUDNN(cudnnSetTensor4dDescriptor(_x_desc, CUDNN_TENSOR_NCHW, cudnn_dtype, 1, n * c, h, w));
CHECK_CUDNN(cudnnSetTensor4dDescriptor(_y_desc, CUDNN_TENSOR_NCHW, cudnn_dtype, 1, n * c, h, w));
float alpha = 1;
float beta = 0;
void const* x_ptr = inputs[0];
void* y_ptr = outputs[0];
CHECK_CUDNN(cudnnSetStream(_cudnn_handle, stream));
// Note: Use of CUDNN_BATCHNORM_SPATIAL_PERSISTENT can cause numerical
// overflows (NaNs) for fp32 data in some circumstances. The lower-
// performance CUDNN_BATCHNORM_SPATIAL should be used if this is not
// acceptable.
CHECK_CUDNN(cudnnBatchNormalizationForwardTraining(_cudnn_handle, CUDNN_BATCHNORM_SPATIAL_PERSISTENT, &alpha, &beta,
_x_desc, x_ptr, _y_desc, y_ptr, _b_desc, _d_scale, _d_bias, 1., nullptr, nullptr, _epsilon, nullptr, nullptr));
return 0;
}
- https://github1s.com/NVIDIA/TensorRT/blob/release/7.2/plugin/fcPlugin/fcPlugin.cpp#L515
- static_cast是一个强制类型转换操作符。强制类型转换,也称为显式转换,C++中强制类型转换操作符有static_cast、dynamic_cast、const_cast、reinterpert_cast四个
inference with engine file / 使用引擎文件进行推理
在使用引擎文件进行推理的过程中,从序列化文件恢复权重和参数,所以会先调用SamplePlugins(const void *data, size_t length)读取自定义层的相关信息,然后调用initialize() 进行初始化.在推理的过程中调用enqueue()进行推理.推理结束后如果在调用engine的destroy方法的时候会调用terminate()函数,释放 掉initialize()申请的资源.
- 三个构造函数
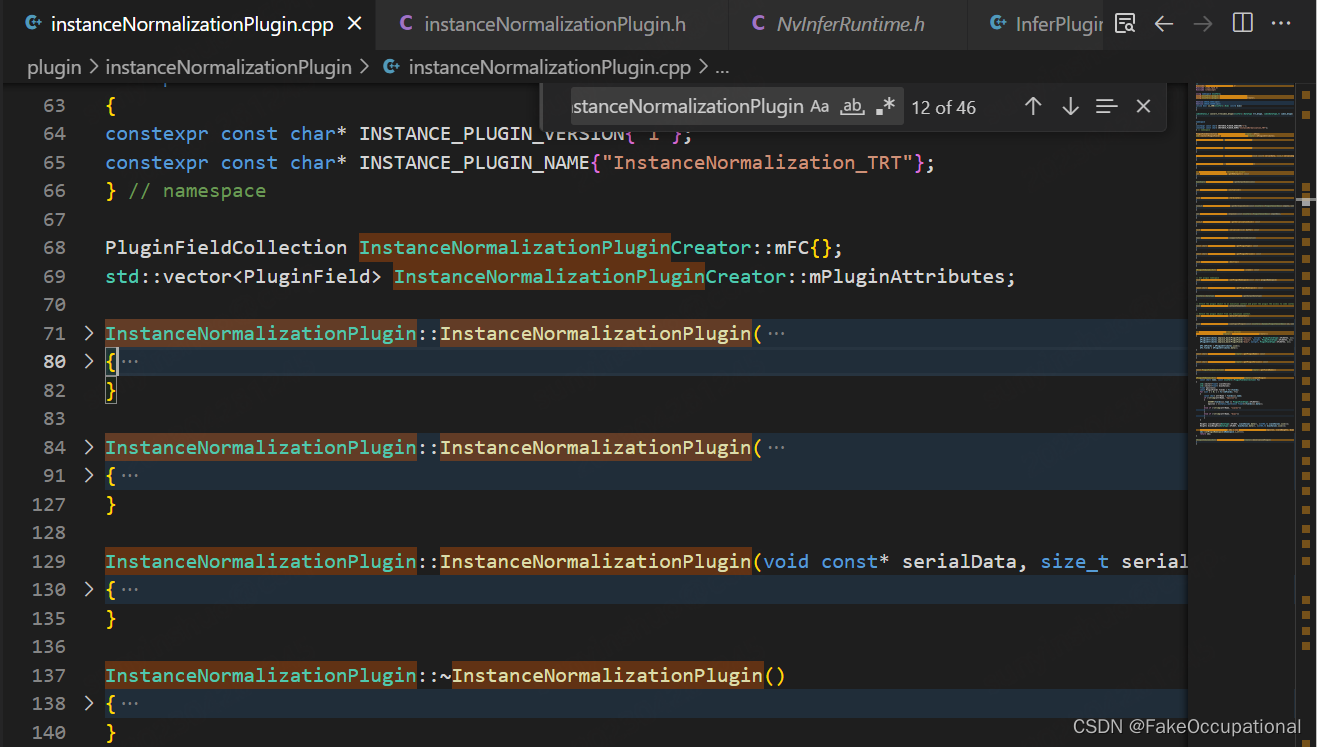
InstanceNormalizationPlugin(float epsilon, nvinfer1::Weights const& scale, nvinfer1::Weights const& bias);
InstanceNormalizationPlugin(float epsilon, const std::vector<float>& scale, const std::vector<float>& bias);
InstanceNormalizationPlugin(void const* serialData, size_t serialLength);
- 一个析构函数
InstanceNormalizationPlugin::~InstanceNormalizationPlugin()
{
terminate();// terminate函数就是释放这个op之前开辟的一些显存空间:
}
插件工厂类
class InstanceNormalizationPluginCreator : public BaseCreator
{
public:
InstanceNormalizationPluginCreator();
~InstanceNormalizationPluginCreator() override = default;
const char* getPluginName() const override;
const char* getPluginVersion() const override;
const PluginFieldCollection* getFieldNames() override;
IPluginV2DynamicExt* createPlugin(const char* name, const nvinfer1::PluginFieldCollection* fc) override;
IPluginV2DynamicExt* deserializePlugin(const char* name, const void* serialData, size_t serialLength) override;
private:
static PluginFieldCollection mFC;
static std::vector<PluginField> mPluginAttributes;
std::string mNamespace;
};
cpp中有关InstanceNormalizationPluginCreator的代码
createPlugin
这个成员函数作用是通过PluginFieldCollection去创建plugin,将op需要的权重和参数一个一个取出来,
然后调用上文提到的第一个构造函数(返回指向插件的指针)去创建plugin(这个函数可能在最后调用注册的时候才会用到):
-
MyCustomPlugin(int in_channel, nvinfer1::Weights const& weight, nvinfer1::Weights const& bias); -
对应于下面代码块的
InstanceNormalizationPlugin* obj = new InstanceNormalizationPlugin(epsilon, scaleWeights, biasWeights);
// \plugin\instanceNormalizationPlugin\instanceNormalizationPlugin.cpp
IPluginV2DynamicExt* InstanceNormalizationPluginCreator::createPlugin(
const char* name, const nvinfer1::PluginFieldCollection* fc)
{
std::vector<float> scaleValues;
std::vector<float> biasValues;
float epsilon{};
const PluginField* fields = fc->fields;
for (int i = 0; i < fc->nbFields; ++i)
{
const char* attrName = fields[i].name;
if (!strcmp(attrName, "epsilon"))
{
ASSERT(fields[i].type == PluginFieldType::kFLOAT32);
epsilon = *(static_cast<const float*>(fields[i].data));
}
else if (!strcmp(attrName, "scales"))
{
ASSERT(fields[i].type == PluginFieldType::kFLOAT32);
int size = fields[i].length;
scaleValues.reserve(size);
const auto* w = static_cast<const float*>(fields[i].data);
for (int j = 0; j < size; j++)
{
scaleValues.push_back(*w);
w++;
}
}
else if (!strcmp(attrName, "bias"))
{
ASSERT(fields[i].type == PluginFieldType::kFLOAT32);
int size = fields[i].length;
biasValues.reserve(size);
const auto* w = static_cast<const float*>(fields[i].data);
for (int j = 0; j < size; j++)
{
biasValues.push_back(*w);
w++;
}
}
}
Weights scaleWeights{DataType::kFLOAT, scaleValues.data(), (int64_t) scaleValues.size()};
Weights biasWeights{DataType::kFLOAT, biasValues.data(), (int64_t) biasValues.size()};
InstanceNormalizationPlugin* obj = new InstanceNormalizationPlugin(epsilon, scaleWeights, biasWeights);
obj->setPluginNamespace(mNamespace.c_str());
return obj;
}
=========================================================================
\include\NvInferRuntimeCommon.h
struct PluginFieldCollection
{
int32_t nbFields; //!< Number of PluginField entries
const PluginField* fields; //!< Pointer to PluginField entries
};
=========================================================================
//! \include\NvInferRuntimeCommon.h
//! \class PluginField
//!
//! \brief Structure containing plugin attribute field names and associated data
//! This information can be parsed to decode necessary plugin metadata
//!
//!
class PluginField
{
public:
//!
//! \brief Plugin field attribute name
//!
const char* name{nullptr};
//!
//! \brief Plugin field attribute data
//!
const void* data{nullptr};
//!
//! \brief Plugin field attribute type
//! \see PluginFieldType
//!
PluginFieldType type{PluginFieldType::kUNKNOWN};
//!
//! \brief Number of data entries in the Plugin attribute
//!
int32_t length{0};
PluginField(const char* name_ = nullptr, const void* data_ = nullptr, const PluginFieldType type_ = PluginFieldType::kUNKNOWN, int32_t length_ = 0)
: name(name_)
, data(data_)
, type(type_)
, length(length_)
{
}
};
=====================================================================================
#include "instanceNormalizationPlugin.h"
#include <cuda_fp16.h>
#include <stdexcept>
using namespace nvinfer1;
using nvinfer1::plugin::InstanceNormalizationPlugin;
using nvinfer1::plugin::InstanceNormalizationPluginCreator;
PluginFieldCollection InstanceNormalizationPluginCreator::mFC{};
std::vector<PluginField> InstanceNormalizationPluginCreator::mPluginAttributes;
//同一文件中的所有代码都可以看到未命名命名空间中的标识符,但标识符以及命名空间本身在该文件外部不可见 https://learn.microsoft.com/en-us/cpp/cpp/namespaces-cpp?view=msvc-170
namespace
{
constexpr const char* INSTANCE_PLUGIN_VERSION{"1"};
constexpr const char* INSTANCE_PLUGIN_NAME{"InstanceNormalization_TRT"};
} // namespace
PluginFieldCollection InstanceNormalizationPluginCreator::mFC{};
std::vector<PluginField> InstanceNormalizationPluginCreator::mPluginAttributes;
// InstanceNormalizationPluginCreator methods
InstanceNormalizationPluginCreator::InstanceNormalizationPluginCreator()
{
mPluginAttributes.emplace_back(PluginField("epsilon", nullptr, PluginFieldType::kFLOAT32, 1));
mPluginAttributes.emplace_back(PluginField("scales", nullptr, PluginFieldType::kFLOAT32, 1));
mPluginAttributes.emplace_back(PluginField("bias", nullptr, PluginFieldType::kFLOAT32, 1));
mFC.nbFields = mPluginAttributes.size();
mFC.fields = mPluginAttributes.data();
}
const char* InstanceNormalizationPluginCreator::getPluginName() const
{
return INSTANCE_PLUGIN_NAME;
}
const char* InstanceNormalizationPluginCreator::getPluginVersion() const
{
return INSTANCE_PLUGIN_VERSION;
}
const PluginFieldCollection* InstanceNormalizationPluginCreator::getFieldNames()
{
return &mFC;
}
deserializePlugin
这个函数会被onnx-tensorrt的一个叫做TRT_PluginV2的转换op调用,这个op会读取onnx模型的data数据将其反序列化到network中。
IPluginV2DynamicExt* InstanceNormalizationPluginCreator::deserializePlugin(
const char* name, const void* serialData, size_t serialLength)
{
InstanceNormalizationPlugin* obj = new InstanceNormalizationPlugin{serialData, serialLength};
obj->setPluginNamespace(mNamespace.c_str());
return obj;
}
关于plugin的注册
简单说下plugin的注册流程。
注册
关于plugin的注册

//https://github1s.com/NVIDIA/TensorRT/blob/release/7.2/include/NvInferRuntimeCommon.h#L1374-L1377
#define REGISTER_TENSORRT_PLUGIN(name) \
static nvinfer1::PluginRegistrar<name> pluginRegistrar##name {}
} // namespace nvinfer1
- 在 bool initLibNvInferPlugins(void* logger, const char* libNamespace)加入initializePlugin<***>(logger, libNamespace);即可
// \plugin\InferPlugin.cpp
// 参考https://github1s.com/NVIDIA/TensorRT/blob/release/7.2/plugin/InferPlugin.cpp#L175
extern "C"
{
bool initLibNvInferPlugins(void* logger, const char* libNamespace)
{
******
initializePlugin<nvinfer1::plugin::InstanceNormalizationPluginCreator>(logger, libNamespace);
******
return true;
}
} // extern "C"
- 注册过程会“将creater对象放到stack和list的存储结构”中
注册过程
template <typename CreatorType>
void initializePlugin(void* logger, const char* libNamespace)
{
PluginCreatorRegistry::getInstance().addPluginCreator<CreatorType>(logger, libNamespace);
}
template <typename CreatorType>
void addPluginCreator(void* logger, const char* libNamespace)
{
// Make accesses to the plugin creator registry thread safe
std::lock_guard<std::mutex> lock(mRegistryLock);
std::string errorMsg;
std::string verboseMsg;
std::unique_ptr<CreatorType> pluginCreator{new CreatorType{}}; //TODO 在这里创建了对象
pluginCreator->setPluginNamespace(libNamespace); //应该会调用BaseCreator的方法
nvinfer1::plugin::gLogger = static_cast<nvinfer1::ILogger*>(logger);
std::string pluginType = std::string{pluginCreator->getPluginNamespace()}
+ "::" + std::string{pluginCreator->getPluginName()} + " version "
+ std::string{pluginCreator->getPluginVersion()};
if (mRegistryList.find(pluginType) == mRegistryList.end())
{
bool status = getPluginRegistry()->registerCreator(*pluginCreator, libNamespace);
if (status)
{
mRegistry.push(std::move(pluginCreator)); // 栈 mRegistry: std::stack<std::unique_ptr<IPluginCreator>> mRegistry;
// IPluginCreator 是BaseCreator的父类
// 移动构造 https://en.cppreference.com/w/cpp/utility/move
mRegistryList.insert(pluginType);
verboseMsg = "Registered plugin creator - " + pluginType;
}
else
{
errorMsg = "Could not register plugin creator - " + pluginType;
}
}
else
{
verboseMsg = "Plugin creator already registered - " + pluginType;
}
if (logger)
{
if (!errorMsg.empty())
{
nvinfer1::plugin::gLogger->log(ILogger::Severity::kERROR, errorMsg.c_str());
}
if (!verboseMsg.empty())
{
nvinfer1::plugin::gLogger->log(ILogger::Severity::kVERBOSE, verboseMsg.c_str());
}
}
}
调用注册
在加载NvInferRuntimeCommon.h头文件的时候会得到一个getPluginRegistry,这里类中包含了所有已经注册了的IPluginCreator,在使用的时候我们通过getPluginCreator函数得到相应的IPluginCreator。
- https://zhuanlan.zhihu.com/p/460901713

















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









