






计算机科学的先驱Donald Knuth(高德纳)曾经说过:“过早的优化是万恶之源”,更详细的原文如下:“We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%. A good programmer will not be lulled into complacency by such reasoning, he will be wise to look carefully at the critical code; but only after that code has been identified.”它向我们揭示了一个道理,我们应该首先定位到那3%真正成为瓶颈的代码,而忽略97%那些“small efficiencies”,所谓“将军赶路,不打小鬼”,这是我们进行一切性能优化的前提。因此,剖析(profiling),成为了性能优化中最重要的环节之一。
性能剖析,要求我们的思维方式主要是top-down的,我们能全局地从顶部向下的看问题,这就像一个全科医生,出了问题后,能大致估摸出一个方向知道是哪个器官可能出了问题。但是,我们同时也必须具备down-top的能力,正如一个专科医生,能看到细小器官的癌细胞最终会怎样向全身发散,从而危机到人的健康和生命。
系统的性能优化不太是一个通过review几千万行代码,发现问题,然后更正问题优化的过程。而更多是一个通过某些剖析手段,把系统当成黑盒子,暴露数据,top-down地看这个系统,在发掘问题后,再深入到白盒down-top的过程。《魏略》曰:“亮在荆州,以建安初与颍川石广元、徐元直、汝南孟公威等俱游学,三人务於精熟,而亮独观其大略。”性能优化本身,是一个从统帅诸葛亮逐步变身单兵战神吕布的过程,而你首先必须是统帅。
一、性能剖析的总体认识
下面我们也来一个“观其大略”的环节,先“不求甚解”地看一看内核性能分析关注的指标,分析角度和一些其他基本常识。
吞吐
吞吐强调单位时间里可以做多少有用功。比如,我们会用netperf来评估网络的带宽;用sysbench来评估MySQL的QPS(Queries Per Second)和TPS(Transactions Per Second);用vm-scalability来评估Linux内存管理的吞吐性能等;用tbench来评估内核调度器wake-up路径上的优化是否有效等。
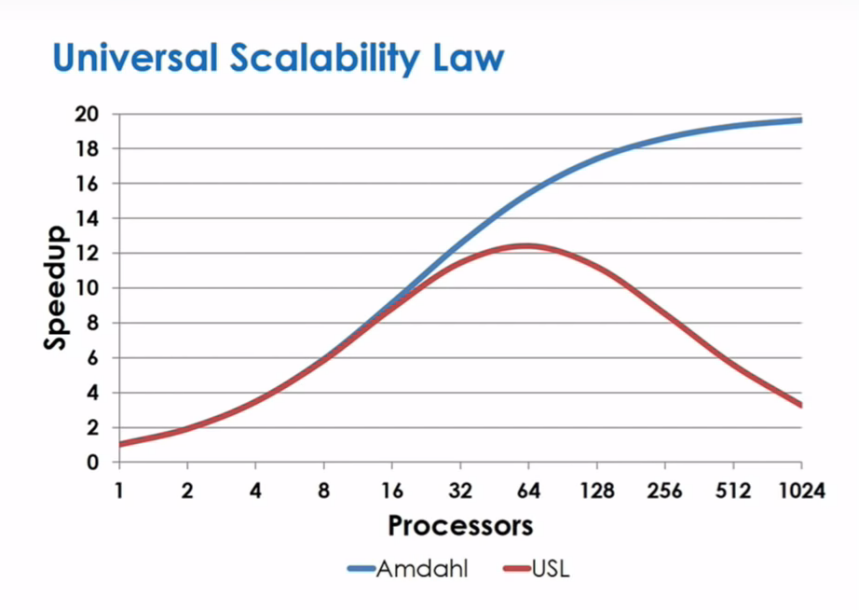
为了提高吞吐,我们常常采用的一个方法是横向拓展硬件或者软件的规模,比如增加更多的CPU、使用多线程等。然而世间万物,不如意者十之八九,不是你爱她多一点,她就一定会爱上你。吞吐的拓展受限于著名的Amdahl's law和Universal Scalability law(USL)。
按照USL,核多(核数为p),实际的加速倍数是:
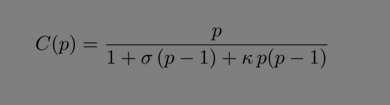
p增大的时候,不仅仅是分子增大,分母也增大,分母σ因子随着p线性增大,k因子随着p的平方线性增大。USL的分母中去掉+k*p*(p-1)就是Amdahl's law,所以Amdahl's law并没有USL完整准确。
其中的σ系数是contention(核间、多线程间因为竞争等锁、同步等而不能并行执行),k系数是coherency(核间、多线程之间的协同形成共识的开销)。σ系数比较好理解,比如两个CPU访问同一个链表,他们需要竞争锁,假设平均1秒里面0.1秒在等锁,则2个cpu实际只有2*0.9=1.8秒在做有用功,而不是2.0。k系数相对难理解一点,比如我们在CPU0释放一个spinlock,在ticket spinlock里面,这个spinlock的新值要通过cache同步网络同步给系统的每个CPU形成所有CPU对这个新值的一致性理解,这个cache同步的开销很大,而且随着p的平方而增大。这就是为什么内核针对spinlock不断在进行优化,比如从ticket spinlock变成qspinlock,其实是减小了需要coherency的CPU个数。
举一个栗子,软件的童鞋很可能会天真地以为内核的atomic_inc()、TLB flush之类的操作是非常便宜的,其实它们都有严重的k因子问题,就是coherency开销。如果做一个简单的操作:
lcase A: 100核,100个线程同时做atomic_inc(),做一秒钟;
lcase B: 10核,10个线程同时做atomic_inc(),做一秒钟。
case A原子操作的次数不会是case B的10倍,它实际远小于10倍,比如实测结果可能是吓死你的4倍(当然每个具体的SoC都可能不一样),等于10倍的硬件目前这个世界还没有做出来,未来也造不出来。
这些σ系数、k系数对服务器的影响,远大于对桌面和手机等系统,因为服务器上的p特别大。所以,长期困扰服务器的问题,比如我从50个cpu变成100个cpu,MySQL的吞吐一定增加了一倍了吗?不好意思,很可能只是吓死你的1.3倍,如果运气不好的话,还可能倒退。
再回到spinlock,大量的文献显示,由于ticket spinlock等在核间coherency上的巨大开销,许多业务的性能可随着CPU核数量的增大而减小【1】。
最开始核增加的时候,相关业务的性能在提升,到某个拐点后,再增加更多的CPU,性能不升反降,出现了collapse。
延迟
甲骨文的“山”,是一个象形字,它较好地贴合了Linux世界里的延迟模型。Linux世界的延迟往往呈现为这种multi-modal(有多个峰值而不是只分布在一个峰值周围)或者两极分化特性。

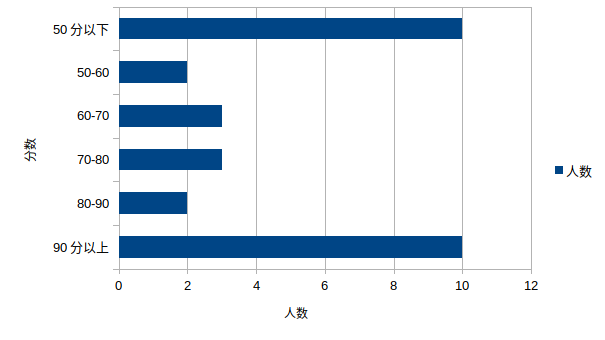
由于这种multi-modal分布的存在,这个时候,我们描述平均值的意义其实不是特别大。比如一个班上有30个学生,其中10个人90分以上(学霸),还有10个人50分以下(学渣),另外还有10个在50-90分之间。我们说这个班的学生平均分60分,其实没有任何意义,拉马老师来和我们平均,没意思的。这个时候,我们需要直方图来描述这种分布,从而更加直观地看出来这个班的学霸和学渣比率。
如果我们想看一个真实的Linux例子,下面是我的PC在运行“sudo cat /dev/nvme0n1 > /dev/null”的过程中,我看到的BIO(block I/O)的延迟分布:
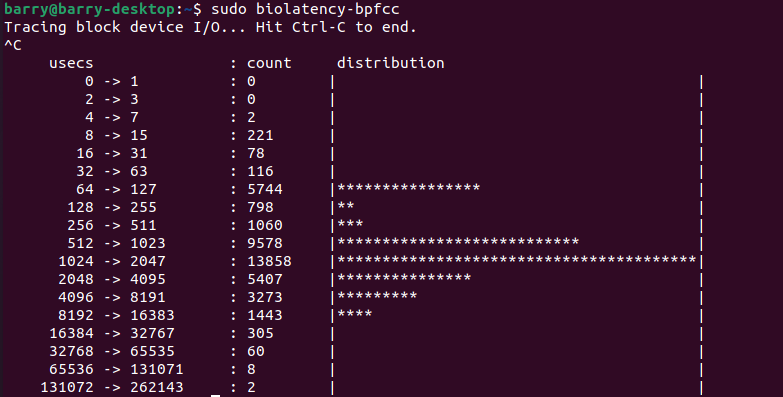
我们看到了2个峰值,一个峰值在64us-127us之间;另外一个峰值,则围绕着1024-2047us分布。当然,还有一个值会偏移地特别远,比如有2个采样点,落在了131072us-262143us之间。那2个离群很远的值,我们一般也称呼它们为outlier,它们是夜空中最闪亮的星,天生不是凡人。
种种迹象表明,我们仅关注平均值的意义非常有限。对于偏移中线的部分,在延迟分析领域,我们还特别关注一个非常重要的概念,tail latency,中文可译为尾延迟。比如我们说,90%的延迟落在1ms以内,99%的延迟在10ms以内,但是还有1%的延迟可能更大,甚至形成一个很长很长的尾巴,可能有的达到了1秒也说不定。在延迟分析领域,我们很可能关注这些尾部,比如大家一起竞争mutex,那些延迟很大的case,可能会形成手机系统的卡顿,因此丢帧。对于服务器、电商、云服务等领域而言,高的尾延迟,会直接影响到企业的revenue。
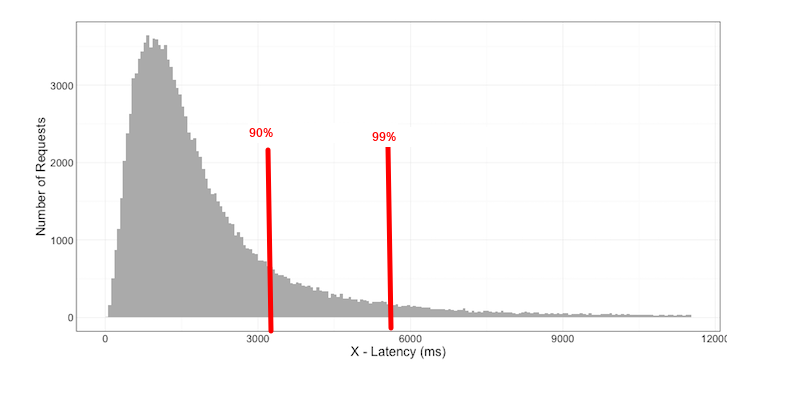
延迟的几个主要可能的来源:
1.进程实际可以运行(TASK_RUNNING),但是由于调度延迟的原因抢不到CPU;
2.进程同步等待一个I/O动作的完成,这些I/O动作可能是syscall的read/write,也可能是mmap内存page fault后的I/O;
3.系统内存吃紧,进程陷入direct memory reclaim,直接回收内存;
4.进程等其他进程释放锁,这里又分2种可能性
a.等锁队列比较长,比如等mutex、spinlock,前面已经挂了一个连在等,等到自己的时候,心已经碎了;
b.等锁队列可能不长,但是持有锁的进程遭遇了情况1、情况2和3,导致长期不放锁。类似你在等厕位,他却坐马桶上看了场电影。
所有的上述不确定情况,都可能形成不确定的tail latency。我们需要某些手段把它剖析和呈现出来。
功耗
内核有cpufreq, cpuidle,意识到功耗的调度器等。这些都致力于在降低功耗的情况下,总体不降低性能。除这些以外,我们也应该认识到,降低内核本身的CPU利用率,比如内存compaction、内存swap/reclaim、锁自旋等的开销,也能进一步降低功耗。在一个内存受限的系统中,我们不能低估内核本身的开销所引起的功耗增加。
比如,我在 qemu上ARM64 Linux-5.19-rc2内核,然后运行下面简单的程序:
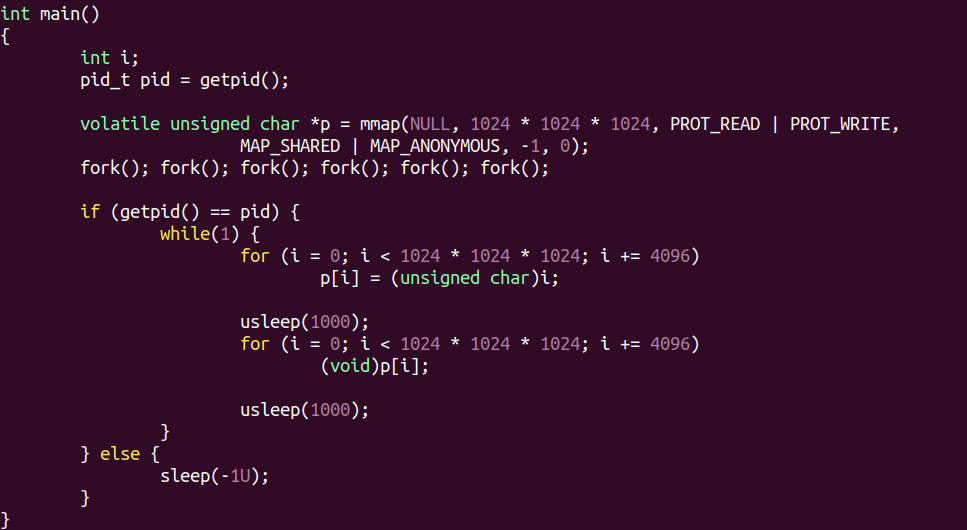
这个程序申请了1GB内存,然后fork出来64个进程,其中最原始那个父进程不停读写这个1GB的内存。代码gcc编译结果a.out。系统的内存是900M,并开启了zRAM交换功能。运行起来后,我们看它的CPU消耗,a.out固然是很大,可是kswapd0这个内核线程也是非常大的CPU占用。
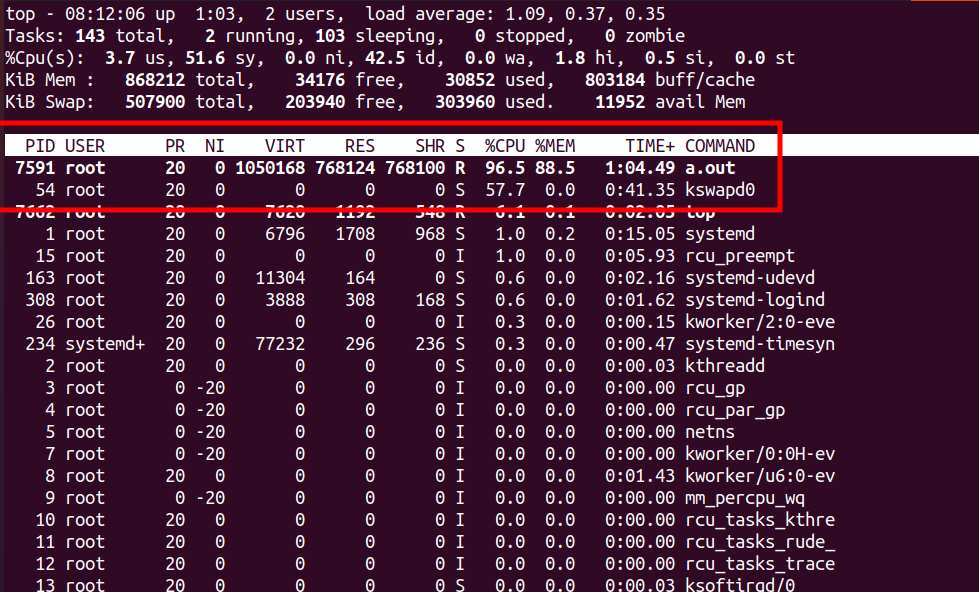
kswapd0相对我们的有用功a.out,只是辅助的工作,本质属于浪费电。此外,我们的a.out本身占用的接近100%的CPU,也主要耗费在a.out自身的动作上吗?这个时候我们也有兴趣看一下,我们“perf top -p <a.out pid>”一下,我们发现a.out也有大量的时间落在了内核的各种函数里面:
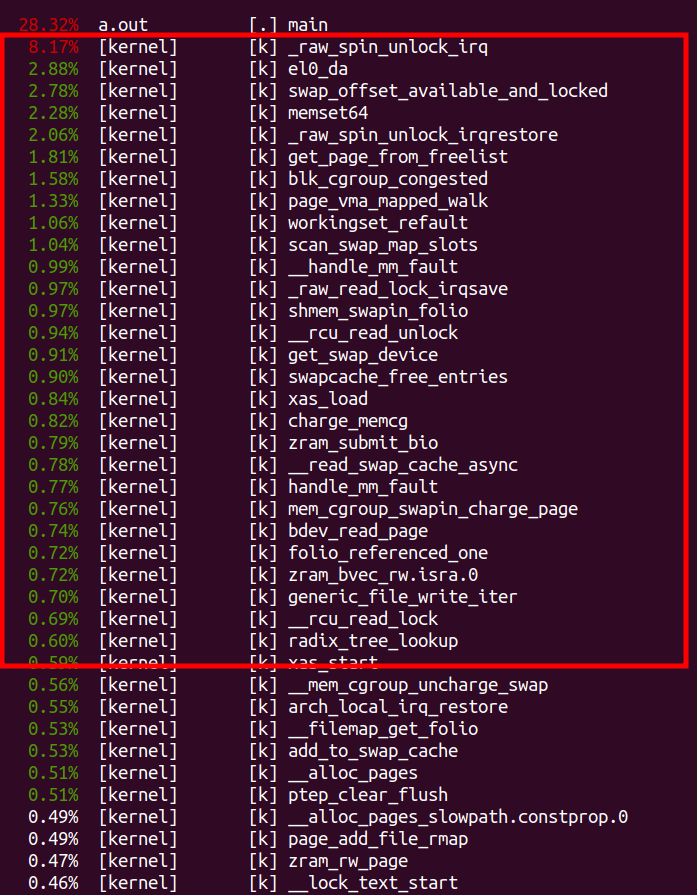
所以从性能分析的角度来说,我们也要把这些红框部分挖掘出来进行分析优化,因为本质他们也是纯耗电,属于overhead而不是real work。
90分到100分特别难
在所有的性能优化领域,我们都不得不正视一点,无论你多么地不愿意:就是前期的优化是相对比较容易的,越到后来越难。一个考10分的学渣,也许经过努力比较容易考到60分,再继续挑灯夜战,可能也能考到90,但是哪怕本着“只要学不死,就往死里学”的极限热情,他也不一定能从90分考到100分,当然它可能考到91分。
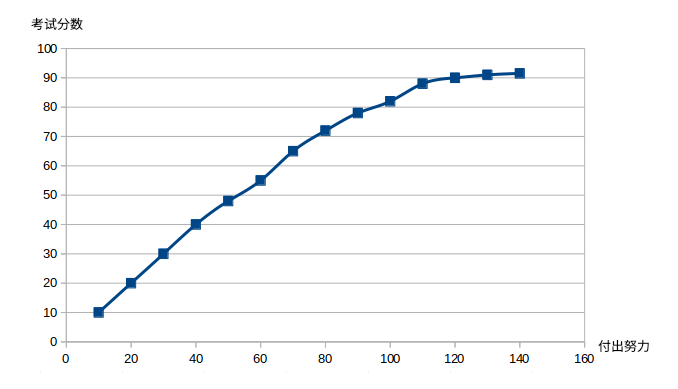
努力到一定程度后,有没有可能越努力成绩越差呢?我觉得是可能的,因为Universal Scalability law(USL),学麻了容易走火入魔,反而出现性能的collapse。
成年人最重要的心理素质是学会和自己的平凡和解,打牌输了不要赖着不走再打一局不如隔天换个场子打。性能优化也是一样的,在某个角度已经搞到了91分,这个时候继续钻牛角尖的代价可能就比较大了。也许我们可以换另外一个角度,来做个从30分到91分的过程,最终实现总成绩91+91=182分,而不是100+30=130分。
在总成绩182的情况下,再去追求总成绩200,心态和效率都高很多。
off-cpu和on-cpu分析同样重要
当我们分析代码在CPU的耗时花费在哪里的时候,我们关心系统的on-cpu profiling,但是,当我们关注延迟等问题的时候,我们不仅要关注on-cpu profiling,更多的时候,我们需要关注off-cpu profiling。off-cpu profiling的目的在于全面地评估进程不在CPU上面跑的时候,因为什么原因被调度出去。off-cpu profiling完整地打印出进程离开CPU的原因的调用栈和时间分布,比如off-cpu发生在等锁(如mutex和rwsem)、等I/O完成、被调度抢占等情况。
性能profiling应同时着眼于on-cpu和off-cpu这两种情况。这个和优化我们的工作效率是一样的,我们既要上班时候尽可能降低CPU消耗,on-cpu的时候少做纯耗电的无用功;也要看看是什么原因引起我们上班的时候钓鱼划水,把引起我们off-cpu的原因分析出来从而减少摸鱼。
二、on-cpu分析
on-cpu分析主要着眼于2个点:一是找到占用CPU大的热点代码;二是提高单位运行时间内,CPU执行有效指令的条数。前一个点重心在于降低CPU利用率,后一个点则着重于提高CPU的工作效率。下面层层展开,展开过程中会直接介绍相关的工具。
on-cpu火焰图
我们看到前述代码中,kswapd0占据了57.7%的CPU。所以我们现在特别感兴趣,它的CPU的具体走向,火焰图可进行一个比较完整的呈现。假设kswapd0的PID是54,下面我们抓取内核线程54的信息:

我们把采样到的数据,通过火焰图工具进行绘制:

我们得到如下火焰图:
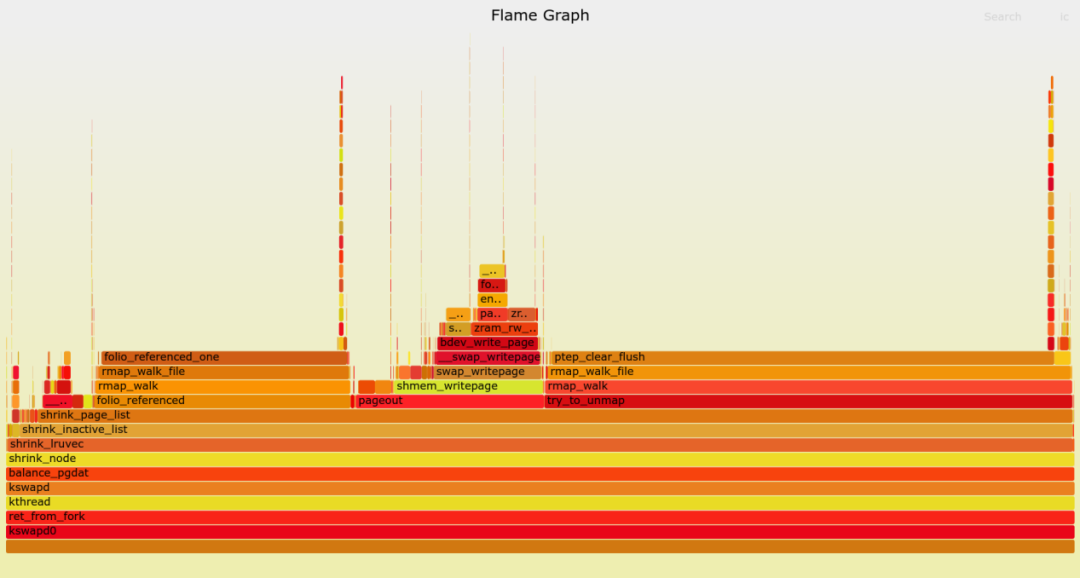
火焰图上我们发现,kswapd的时间有小部分发生在swap_writepage向zRAM写被替换的页面,而大部分发生在判断页面是否被访问的folio_reference_one(),以及页面向zRAM写之前unmap这个页面后的ptep_clear_flush()这2个动作上面。
你也许会想到要去减少folio_reference_one()和ptep_clear_flush()上面的开销,这是一个剖析和发现的过程。
CPU消耗比例分布
火焰图固然呈现了相关函数的CPU比例,但是,很多时候我们生成报告,尤其是向社区发patch,我们需要发送文字版的优化报告,这些报告可以突出CPU热点在哪里。这个时候,我们可以用perf report的功能。
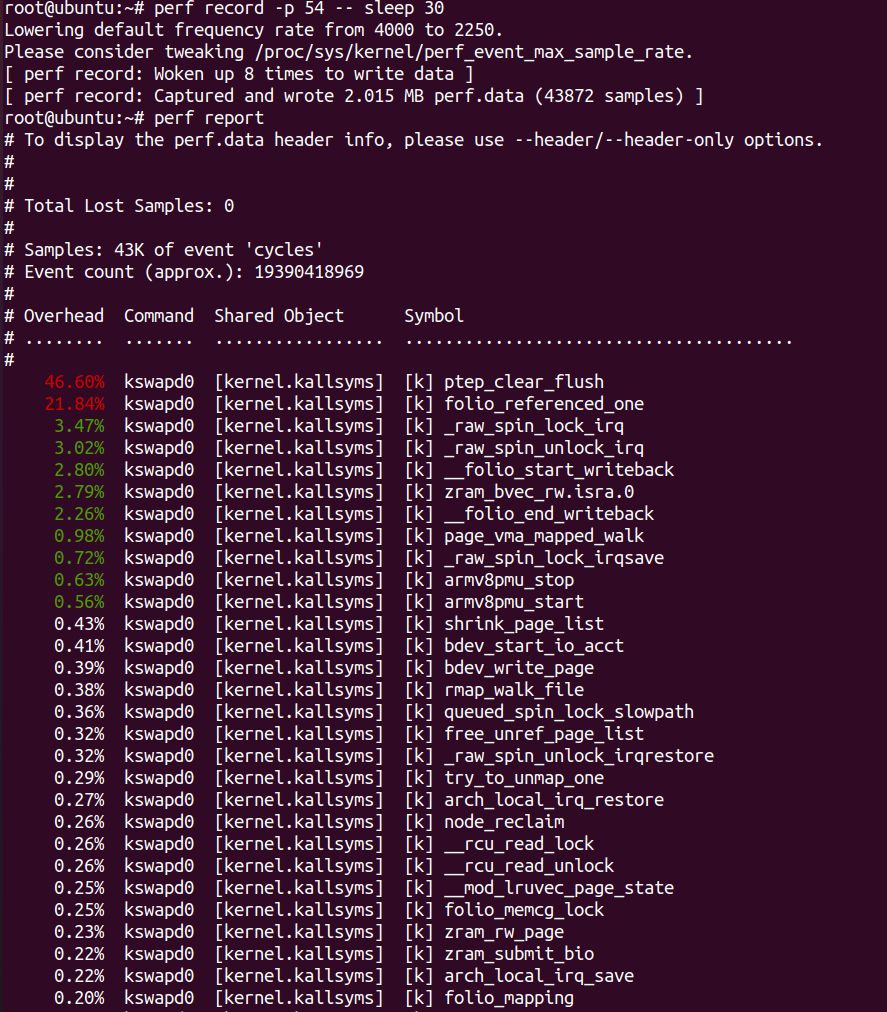
啥也不说了,盯着perf report里面排名第1,第2的整起来。相关的这种数据报告在Linux社区非常常见,比如MGLRU的patch 【2】 里面就列出了MGLRU中某一特性优化前后的CPU消耗对比数据:
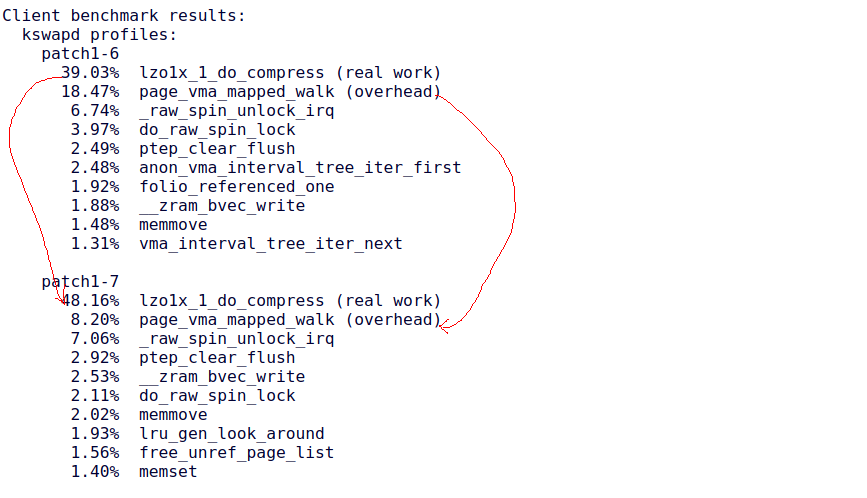
我们看到属于overhead的page_vma_mapped_walk()的减小,但是属于lzo1x_1_do_compress()的real work的增大。所以,我们看数据说话,没有数据支撑的性能优化,是很难形成任何说服力的。这也就是为什么我们在内核社区发性能优化的patch,必然会被要求大量benchmark数据支撑。
最后一公里
前面我们发现try_to_unmap()后调用的ptep_clear_flush()是热点函数,但是它热在哪里,具体热在哪一行代码呢?这个时候,我们需要进一步“perf annotate ptep_clear_flush”。
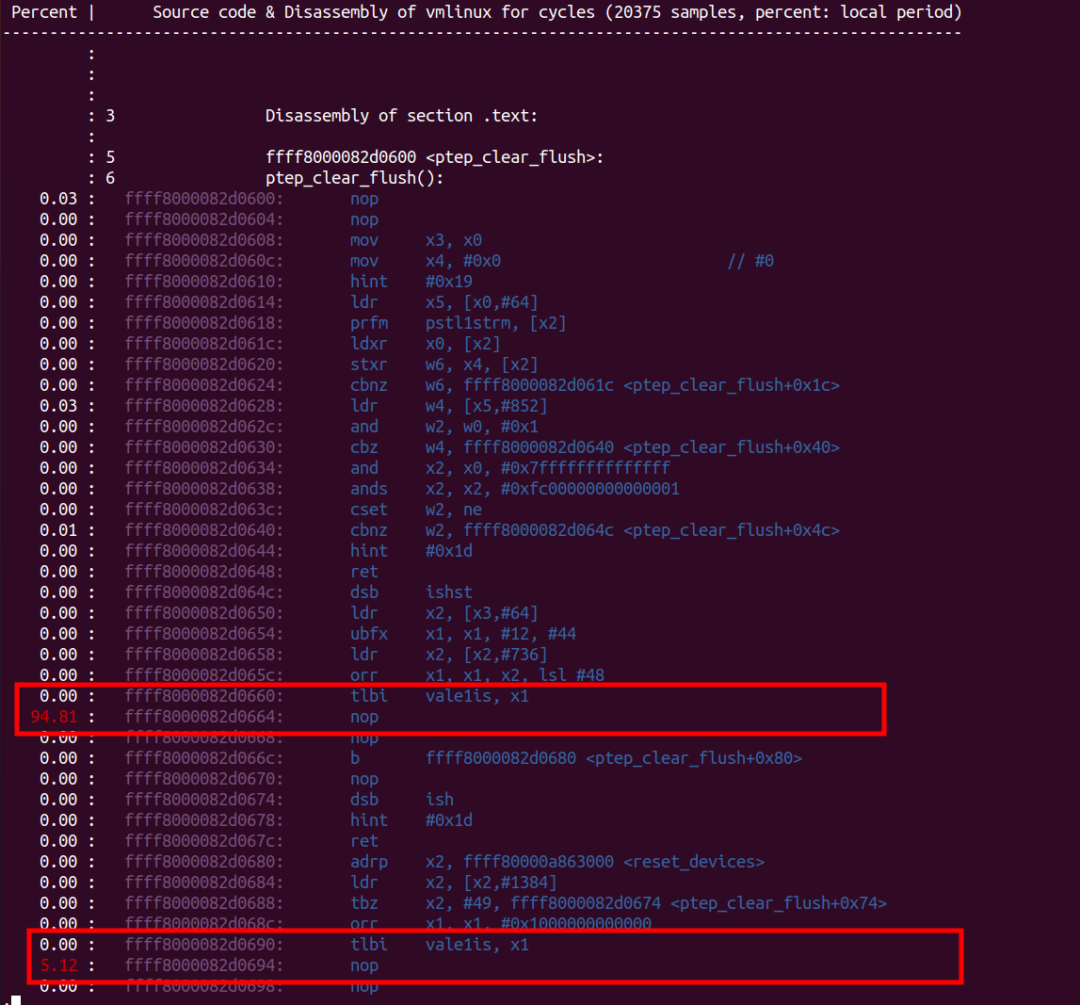
从annotate的结果可以看出,至少,在笔者运行的qemu平台上,tlbi附近的开销是非常大的,其他的代码开销几乎可以忽略不计。当然,真实的ARM64硬件上,tlbi也绝对不便宜。
中断屏蔽的问题
在一个类似如下spin_lock_irqsave()、spin_unlock_irqrestore()的区间里,由于采样的中断都是被屏蔽的,所以中间perf的采样结果,都会在spin_unlock_irqrestore()开启中断的这一刻爆出来,导致ARM64平台下,采样的热点落在类似spin_unlock_irqrestore()这样的地方。这是不准确的。
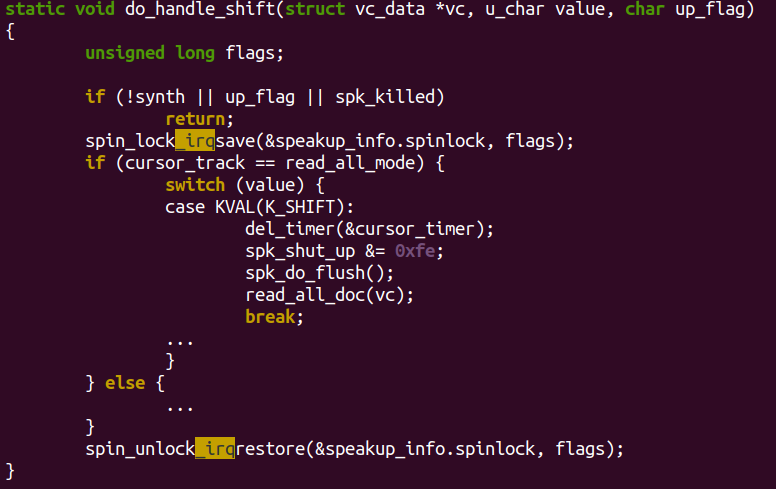
我们在调试时,可以使能ARM64_PSEUDO_NMI选项,并传递irqchip.gicv3_pseudo_nmi=1这样的bootargs参数。这样,内核会用GIC的高优先级中断模拟NMI,在local_irq_disable()、spin_lock_irqsave()、spin_lock_irq()这样的API里面只是屏蔽低优先级中断。

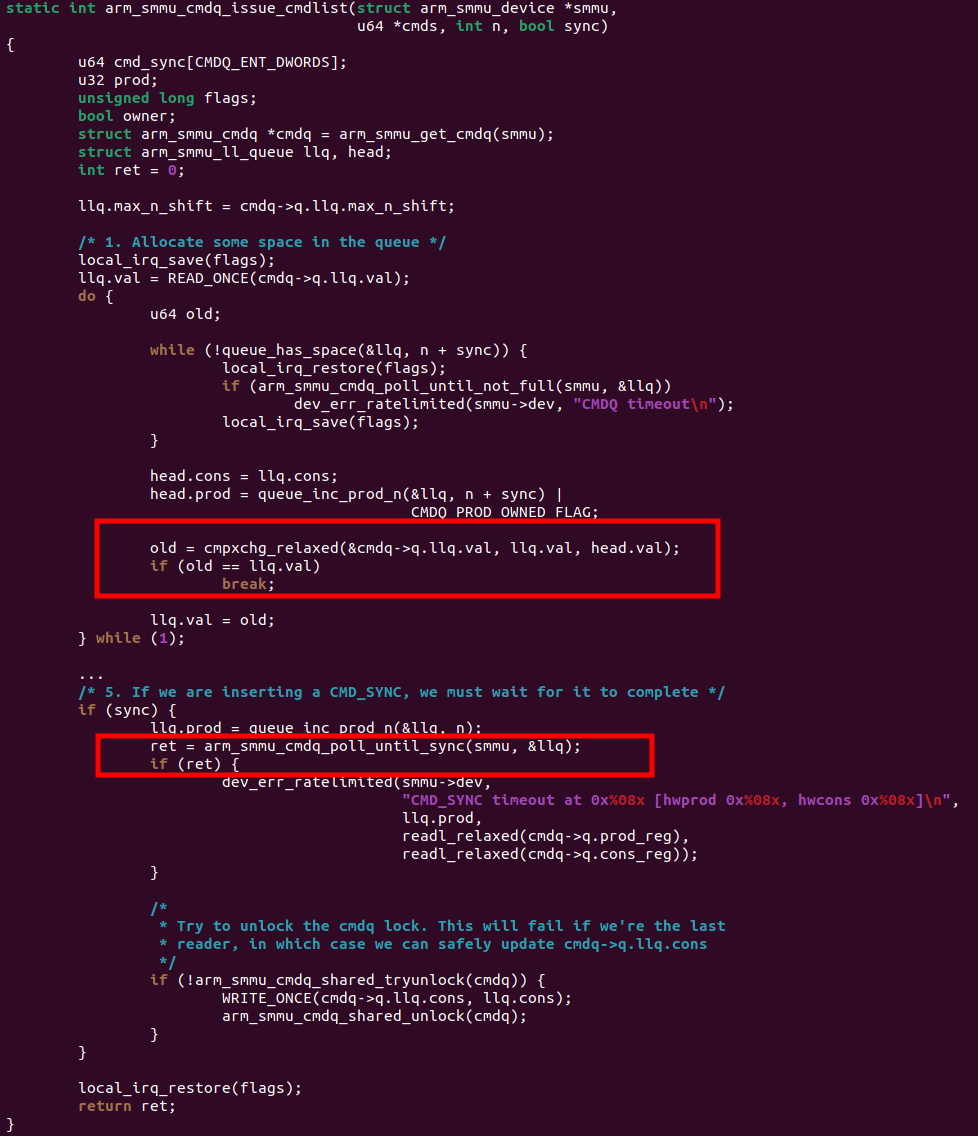
举一个典型的栗子,ARM64 IOMMU(SMMU)的map/unmap开销大,导致dma_map_single/sg, dma_unmap_single/sg这些APIs在开启IOMMU的情况下,吞吐率不高。这个时候,我们通过前面的火焰图、CPU利用率分布报告很可能已经抓到了热点在drivers/iommu/arm/arm-smmu-v3/arm-smmu-v3.c【3】的arm_smmu_cmdq_issue_cmdlist()这个函数,但是这个函数长成这个样子,进去的时候就关中断,出来的时候才开中断:
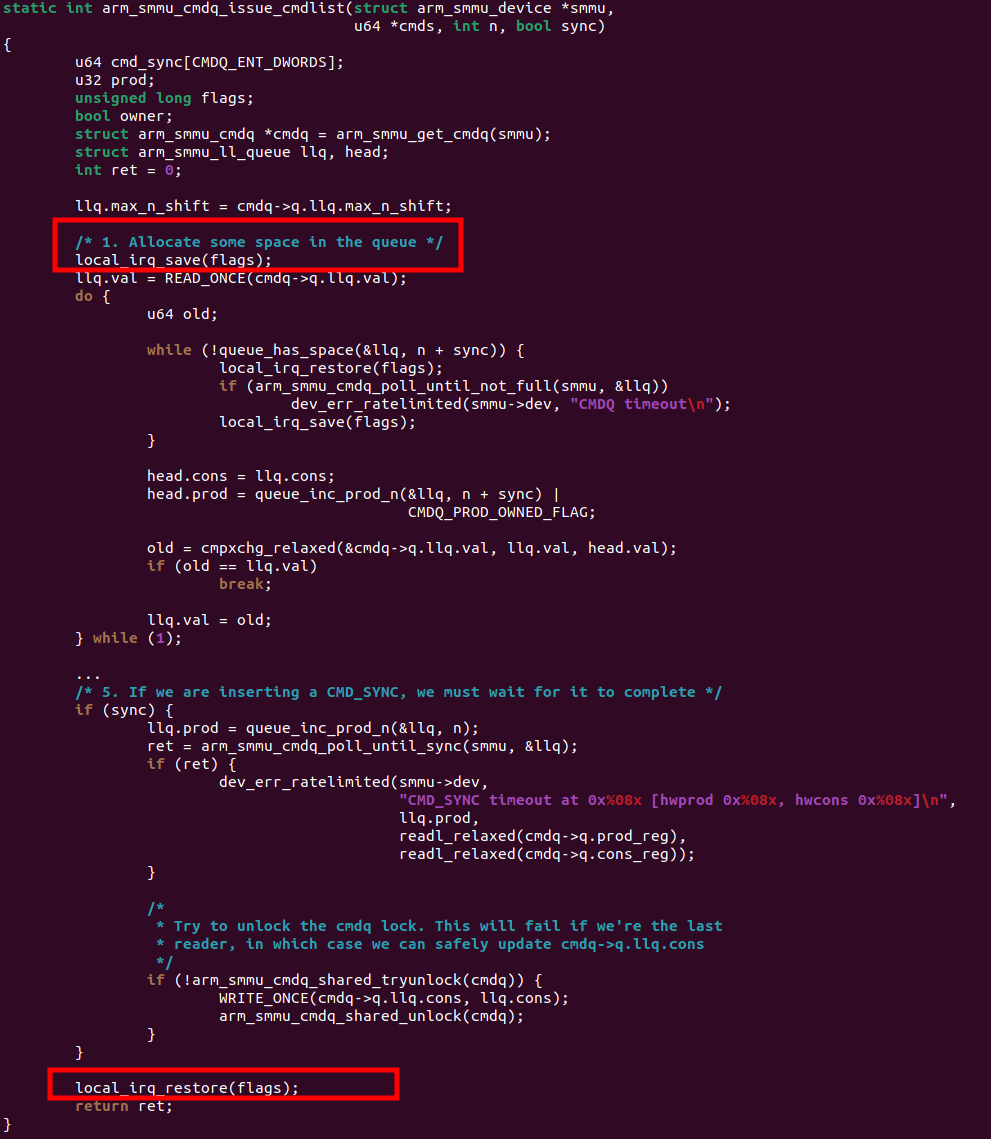
这个时候,你不开启irqchip.gicv3_pseudo_nmi=1是不可能perf annonate出来这个函数哪句话是热点的,所有热点都会落在末尾的local_irq_restore()这句话。但是开启后,你才会抓到真正的热点:
CPU执行效率topdown分析
CPU利用率相等的情况下,执行效率是不是一样的呢?比如都是一秒里面干0.5秒的活,CPU利用率50%,干出来的活是一样多吗?不是的,现代计算机系统普遍采用多发射、流水线、分支预测、预取、乱序投机执行等各种复杂机制,这使得同样时间段内能实际执行的有效指令条数,会是可变的。有两个非常重要的概念值得所有人关注:
CPI:(Cycles Per Instruction)每个指令要多少周期。
IPC:(Instructions Per Cycle)每个周期执行多少指令。
CPI和IPC为反比例关系。在同样CPU利用率的情况下,我们追求尽可能高的IPC。比如1个代码跑起来IPC是2.0,另外一个1.0,那么意味着同样的时间段,前者执行的指令是后者的2倍,CPU执行指令更顺畅,stalled(被添堵、处理器空转)的环节更少。
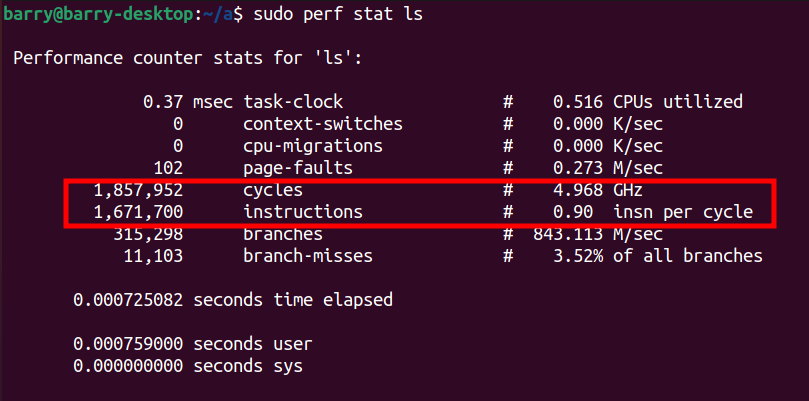
比如我在我的PC上面运行ls,可以看到IPC是0.9:
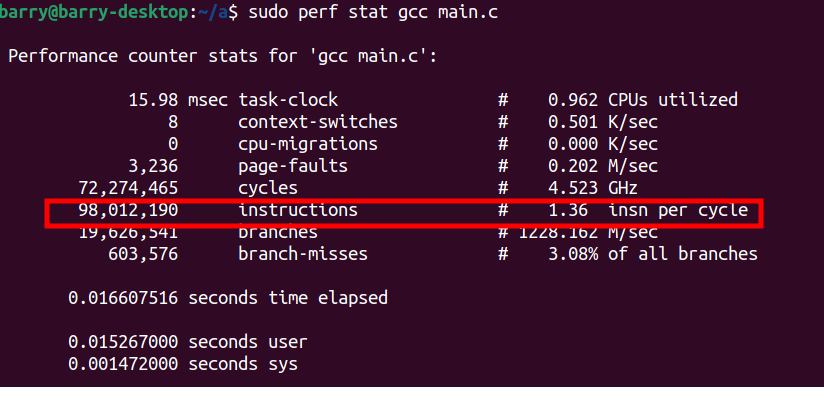
比如运行gcc main.c,可以看到IPC是1.36:
Ahmand Yasin在它的IEEE论文《A top-down method for performance analysis and counter architercture》中,革命性地给出了一个从CPU指令执行的顺畅程度来评估和发现瓶颈的方法,允许我们从黑盒的角度以诸葛孔明“隆中对”式的格局来看问题。
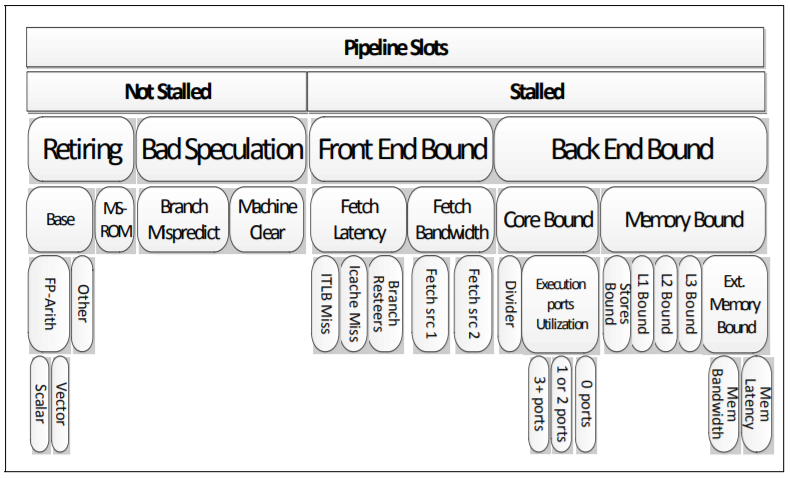
现在处理器,一般在4个方面占用流水线的时间,而top-down方法,可以黑盒地呈现软件在CPU上面运转的时候,CPU的流水线究竟在干什么。
Front End Bound(前端依赖): 处理器的前端主要完成指令的译码,把获取的指令翻译为一系列的micro-ops(μops)。当CPU stalled在Front End,通常意味着CPU在取指慢(比如icache miss、解释执行等),或者复杂指令的翻译过程由于μops cache不命中等原因而变地漫长。Front End stalled多,意味着前端无法及时给后端“喂饱”μops。目前主流的x86处理器,每个cycle可以给Back End喂4个指令,如果Back End也及时执行的话,IPC最高可达4.0。
Back End Bound(后端依赖):处理器的后端主要完成前端“喂”过来的μops的执行,执行的过程可能涉及读写操作数(load/store)、对操作数进行加减乘除各种运算之类。Back End Bound又可再细分为2类,core bound意味着软件更多依赖于微指令的处理能力;memory bound意味着软件更加依赖CPU L1~L3缓存和DRAM内存性能。当CPU stalled在Back End,通常意味着复杂运算指令延迟大,或操作数从memory(包括cache和DDR)获取的延迟大,导致部分pipeline slots为空(stall)。
Retiring:μops被执行完成,最终的retire动作,提交结果到寄存器或者内存。
Bad Speculation:处理器虽然在干活,但是投机执行的指令可能没有用。比如分支本身应该进“else”的,预测的结果却进了“if”执行错误的分支,虽然没有stall,但是这些错误分支里面的指令实际白白执行了不会retire,所以也浪费了pineline的时间。这里有一个基本常识,比如“if(a) do x; else do y;”,处理器并不是等待a的判决结果后,再去做x或者y,而是先根据历史情况投机执行x或者y,当然这个投机有可能出错。
注意Front End Bound、Back End Bound和我们平时说的软件是CPU bound还是I/O Bound是相似概念,比如CPU bound的软件更加依赖计算能力并对CPU性能敏感(比如编译Linux内核、编译Android),I/O bound的软件更加依赖于I/O动作本身并对I/O性能敏感(比如你把硬盘dd if=/dev/sda1 of=xxx到xxx地方去)。
我们把CPU pipeline上的任何一个硬件资源想象成一个pipeline slots,假设CPU可以同时处理4条μops,下图共有40个slots,如果所有slots都做有用功,μops都能retiring,则IPC为4.0:
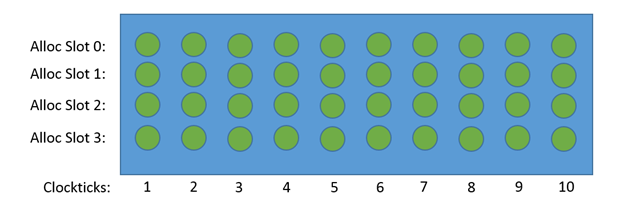
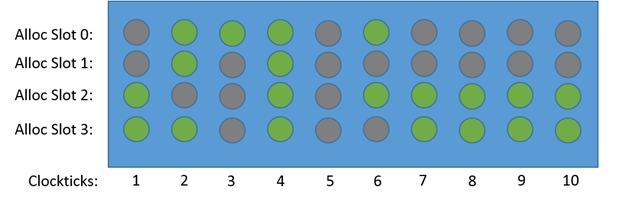
假设其中的20个slots要么是empty没活干(stalled),或者做的是无用功(分支预测错误等情况),那么它的IPC可能就是2.0了。
Intel处理器架构下,已经将top-down完全地工具化,有专门的top-down工具,有的甚至已经图形化了,比如VTune Profiler里面就有类似功能【4】,可以具体化到每一个特定函数的Front-end Bound、Back-End Bound、Bad Speculation、Retiring等的情况:
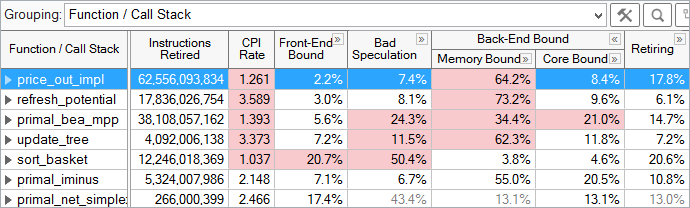
大家从上表可以看出,基本retiring的比例越低,证明pipeline slots的stall越大,CPI也就越高(IPC越低)。比如,refresh_potential()的CPI高达3.589,主要是它的Back-End Bound严重,其中Memory Bound高达73.2%,所以优化这个函数,要多从cache命中率(L1,L2,L3)、DDR带宽/延迟角度考虑。而优化sort_basket()函数则要多从分支预测优化角度考虑,因为它的Bad Speculation高达50.4%。
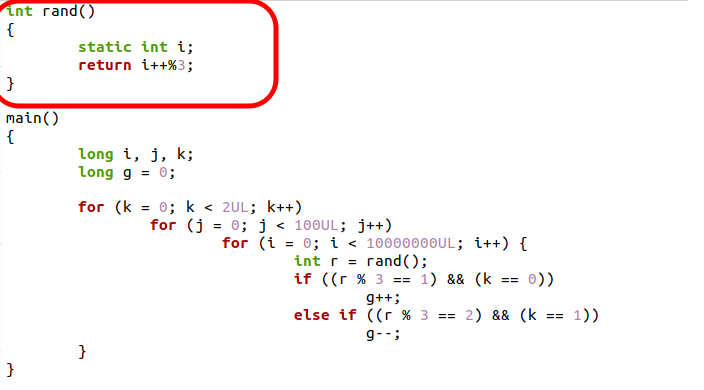
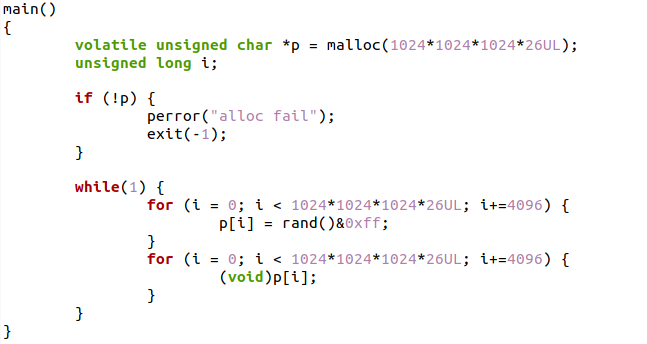
有的童鞋对Bad Speculation可能还是不太明白,下面我们通过一个代码栗子:

这个里面有个随机数r = rand(),会极大地破坏分支预测的准确性,所以topdown的结果如下:

如果我们把里面的rand()函数变成自己的版本,让分支结果并不那么随机:
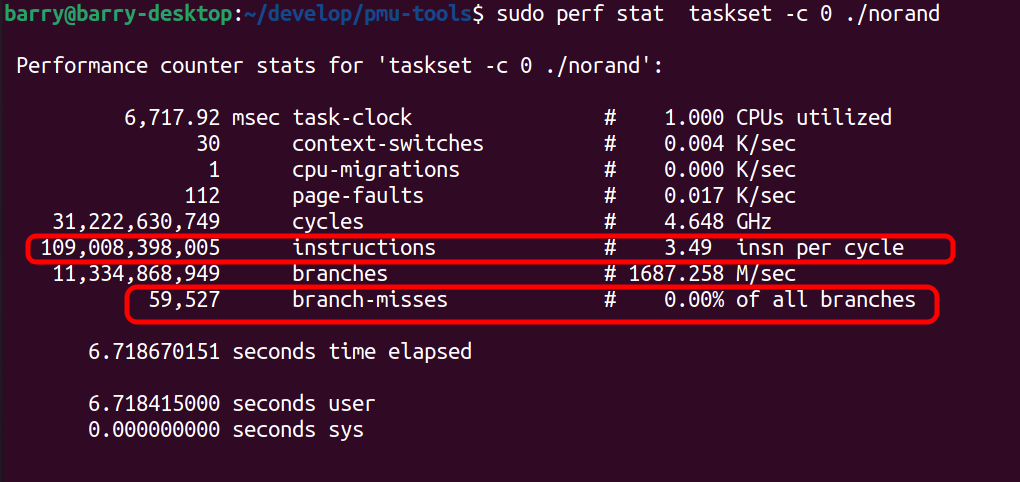
再次topdown,结果则是(retiring很大,绿色友好程序):

此时的IPC也很大,达到3.49,比较接近4.0了:
Intel方面,脚本化的工具则有pmu-tools【5】。比如笔者在自己的X86 PC(内存24GB)上面开启zRAM后运行如下代码:
假设kswapd的PID是202,我们捕获以下kswapd的bound情况:
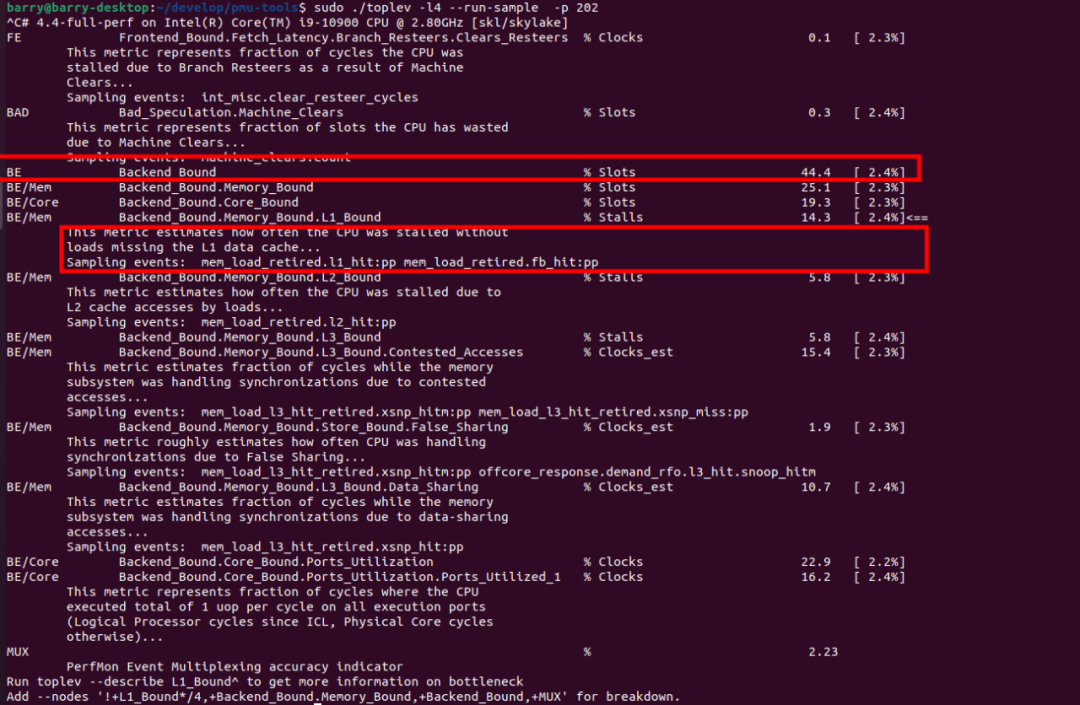
由此我们可以看出,在上述场景下,kswapd跑起来主要是一个Back End Bound,其中Back End Bound里面的memory和core bound各占25.1%和19.3%,至于memory bound的部分,它又可以细分到L1,L2,L3 cache更深层次的原因。
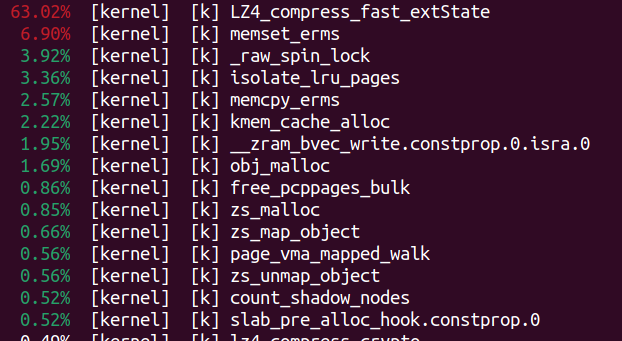
我们现在觉得memory bound是上述场景下kswapd的大头,我们实际也可以采样下kswapd的cache-misses。简单运行“sudo perf top -e cache-misses -p 202”命令看一下,cache misses率最高的是LZ4_compress_fast_extState()、memset_erms()和isolate_lru_pages()。你也许可以怎么去优化这些函数,从而减小它们的Back-End bound的部分,提高kswapd的IPC。
Intel的平台享受上面的工具化优势。其他平台的童鞋也不必懊恼,perf本身也具有topdown能力,perf stat后面有个参数是--topdown:
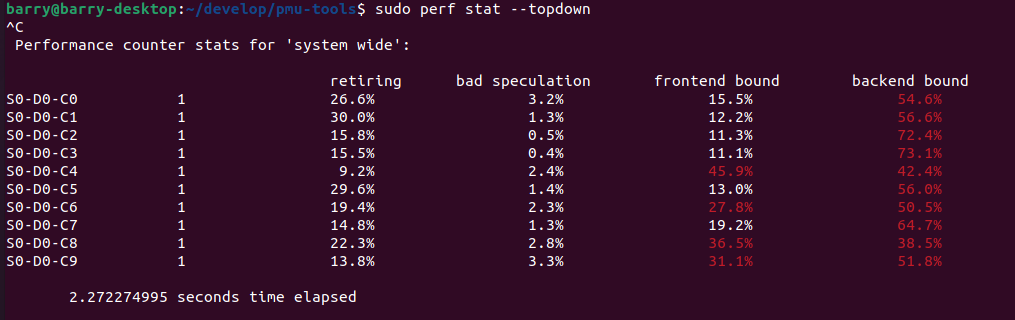
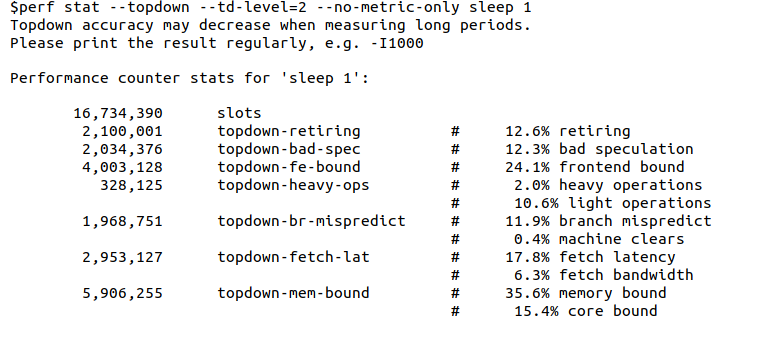
查看Intel童鞋的这个patch【6】,最新版本的perf实际也可以支持td-level=2这样更细粒度的topdown打印:
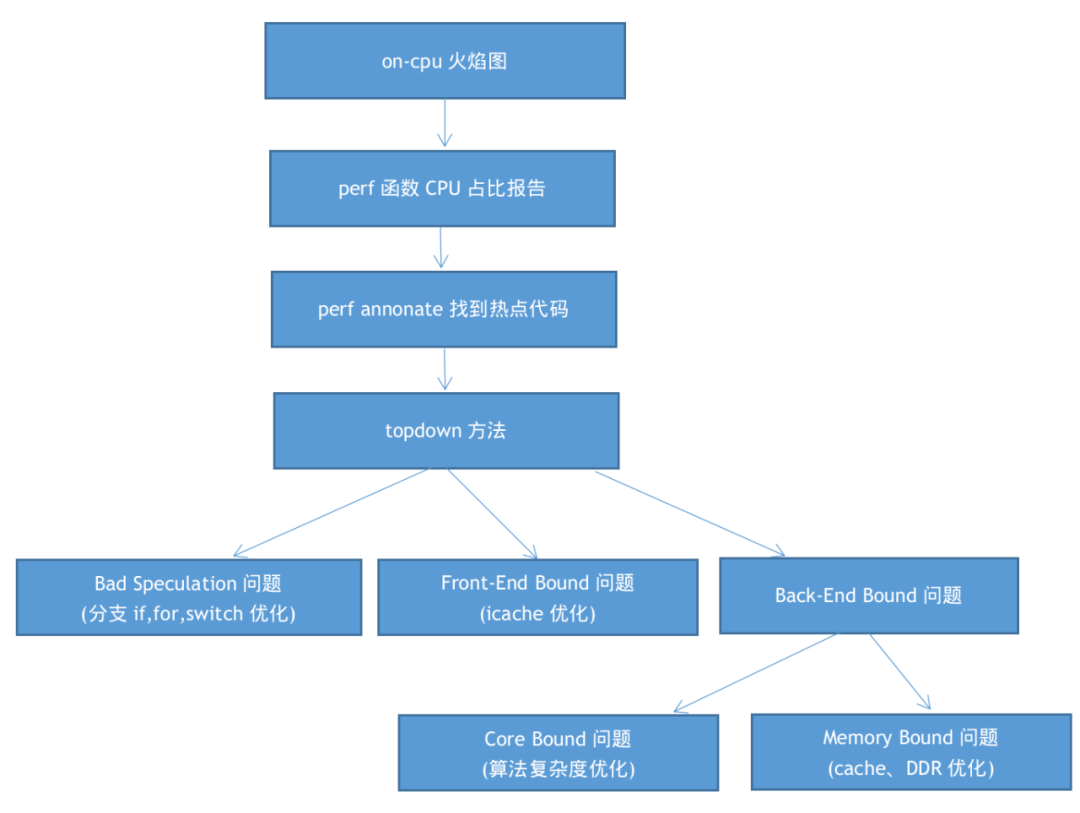
整个on-cpu分析的过程是top-down的,过程中的某些步骤也是topdown的,我们用一个流程图来描述:
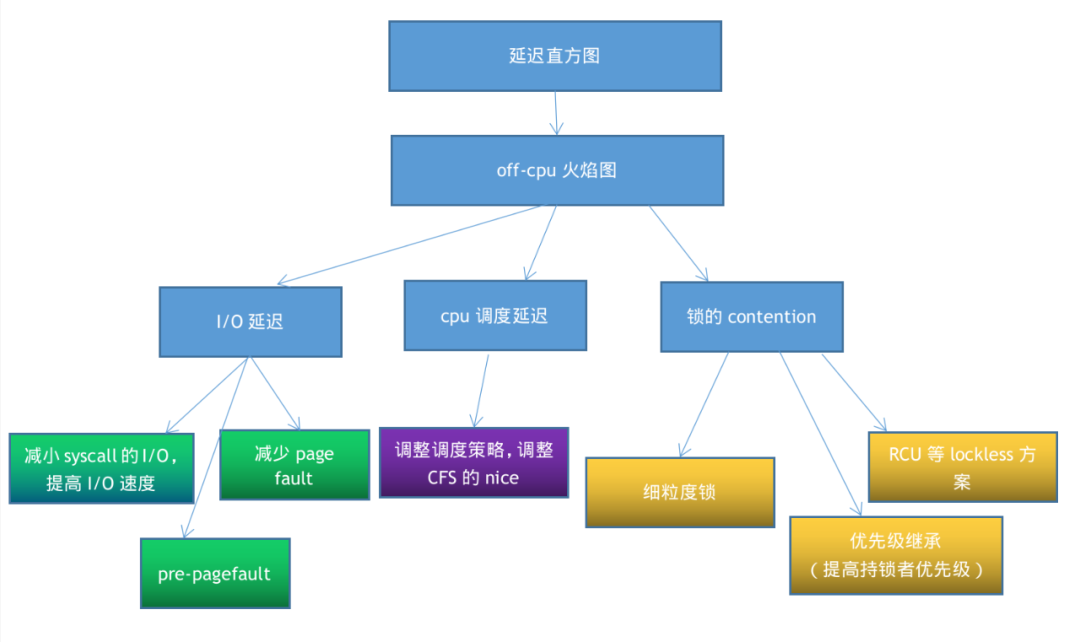
三、off-cpu分析
off-cpu分析更多关注延迟问题,所以我们首先要获知延迟的分布,这个时候我们最好使用直方图。之后,我们可以过度到用off-cpu火焰图等进一步分析off-cpu在等什么,而在lock contention的场合,则可以使用perf lock来进一步进行锁的分析。
直方图
直方图深入人心,哪怕什么工具都没有,纯粹地用Linux内核也可以划出直方图。这个功能位于菜单tracer->Histogram triggers,通过内核tracepoints实现。

下面我们随便举个例子,看看mm/vmscan.c中shrink_inactive_list()一般回收page个数的分布。注意,这纯粹是一个栗子,不对应任何的实际工程。
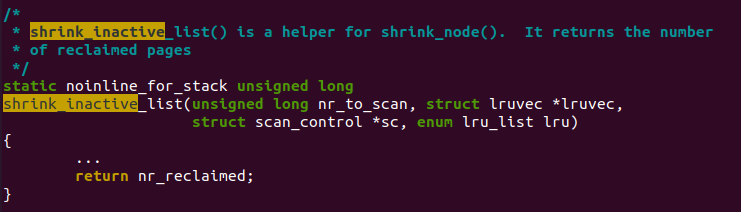
在直方图中,我们关心2个点,一个是key,一个是value。比如我们以回收页面的个数为key,回收到这一key值页面个数的次数为value。
我们在include/trace/events/vmscan.h和mm/vmscan.c中增加这个trace:
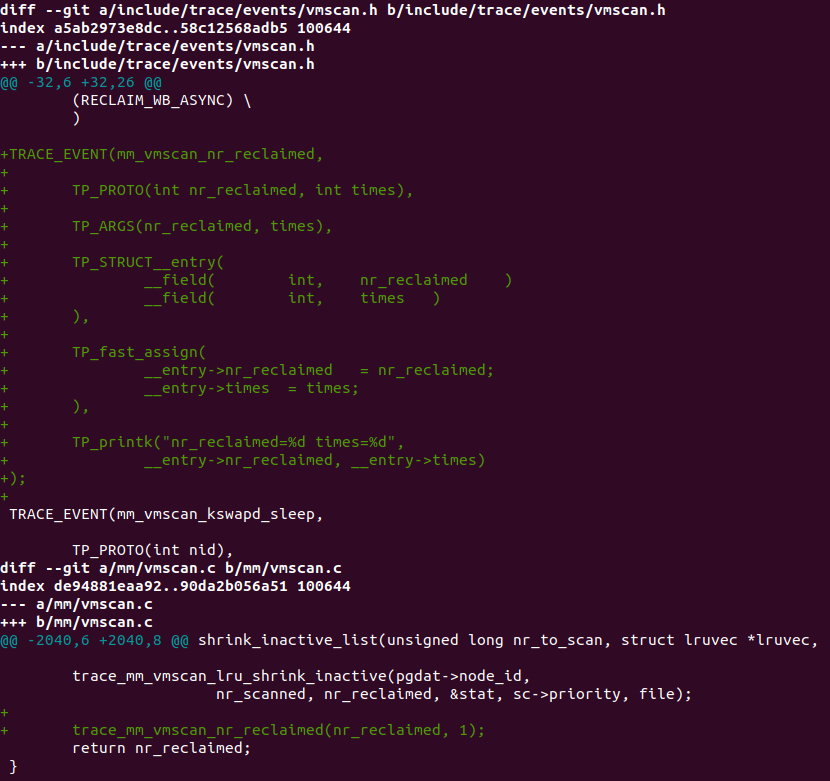
trace_mm_vmscan_nr_reclaimed(nr_reclaimed, 1);这句话表示回收nr_reclaimed个页面的次数增加1。
现在我们使能tracer,以nr_reclaimed为key, times为value,按照times降序排列:

运行系统,触发一些内存回收动作,采样到一些值后,直接读取直方图:
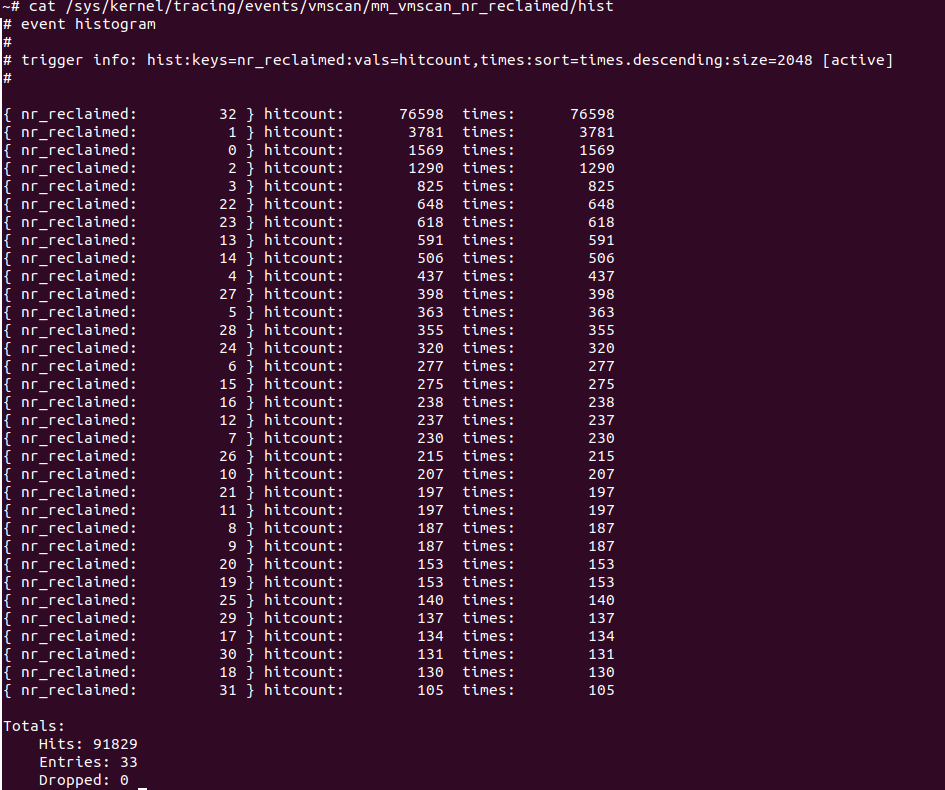
从直方图可看出,实验场景中,回收到32个pages的机会最多,占据76598次,其次是回收到1个、0个和2个的。
下面我们把所有采样复原,改为依据nr_reclaimed升序显示:
复原:

开启新的采样:

运行系统,触发一些内存回收动作,采样到一些值后,直接读取直方图:
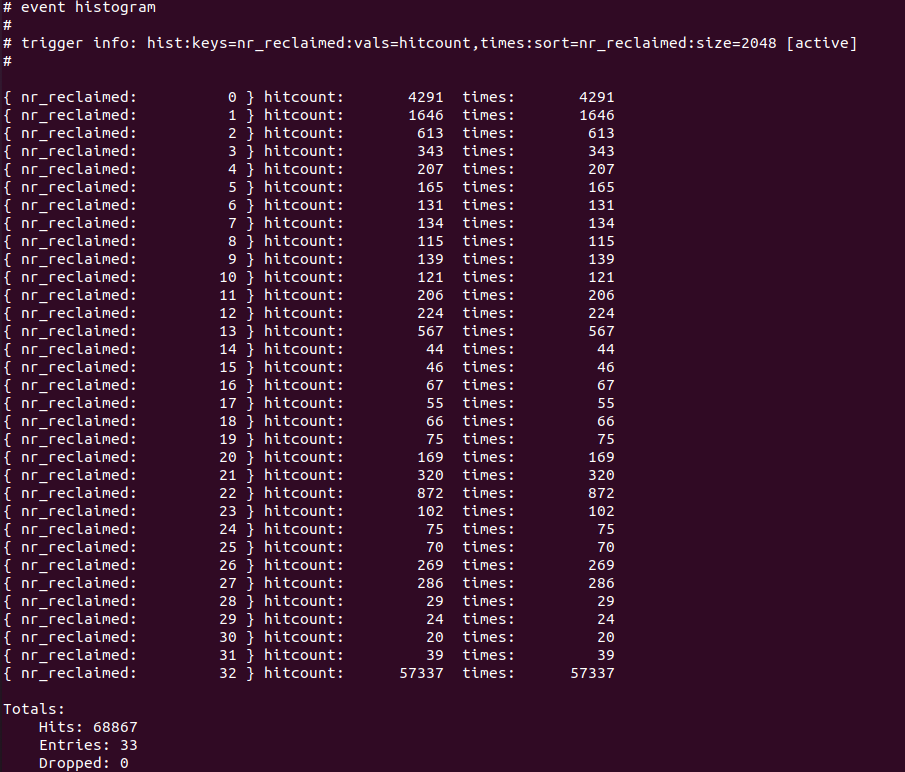
有的童鞋说,我现在关注的是延迟时间的分布,不是nr_reclaimed。这完全不影响我们的原理,比如latency单位是us,我想搜集0-5ms, 5-10ms, 10-15ms, 15-20ms各个档次的分布,我只需要trace:
trace_xxx_sys_yyy_latency(latency/5000, 1);
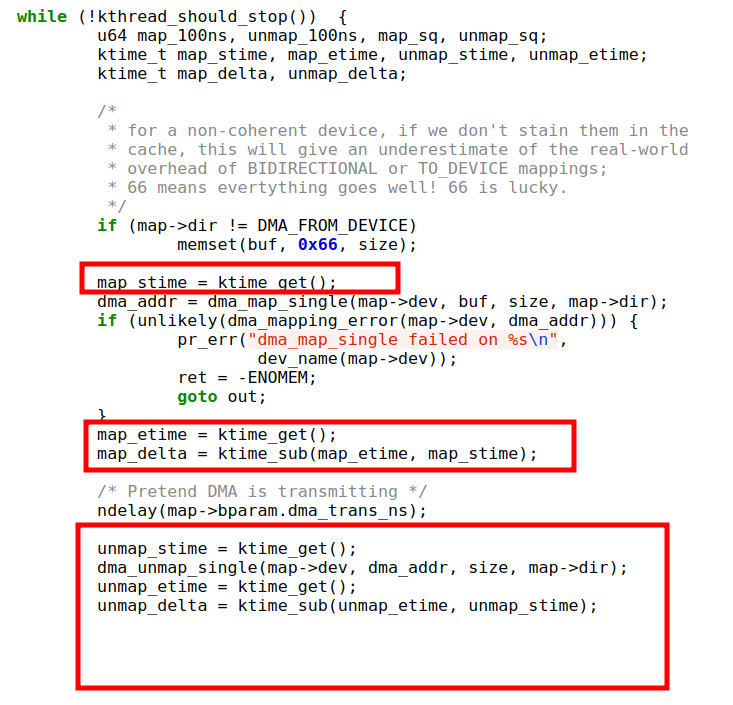
后面在hist中,0-5ms会是一行,5-10ms会是一行,依此类推。另外,内核里面统计延迟可用类似的代码逻辑(来源于kernel/dma/map_benchmark.c的map_benchmark_thread函数):
eBPF/BCC中本身内嵌多个直方图工具,可满足许多常见的生活必须,比如之前演示的biolatency,还有这些已经自带:
bitehist.py: Block I/O size histogram.
argdist: Display function parameter values as a histogram or frequency count.
bitesize: Show per process I/O size histogram.
btrfsdist: Summarize btrfs operation latency distribution as a histogram.
cpudist: Summarize on- and off-CPU time per task as a histogram.
dbstat: Summarize MySQL/PostgreSQL query latency as a histogram.
ext4dist: Summarize ext4 operation latency distribution as a histogram.
funcinterval: Time interval between the same function as a histogram.
runqlat: Run queue (scheduler) latency as a histogram.
runqlen: Run queue length as a histogram.
xfsdist: Summarize XFS operation latency distribution as a histogram.
zfsdist: Summarize ZFS operation latency distribution as a histogram.
funclatency这个笔者也经常用,比如看一下vfs_read()这个函数的执行时间分布,只需要把函数名加在funclatency之后就好:
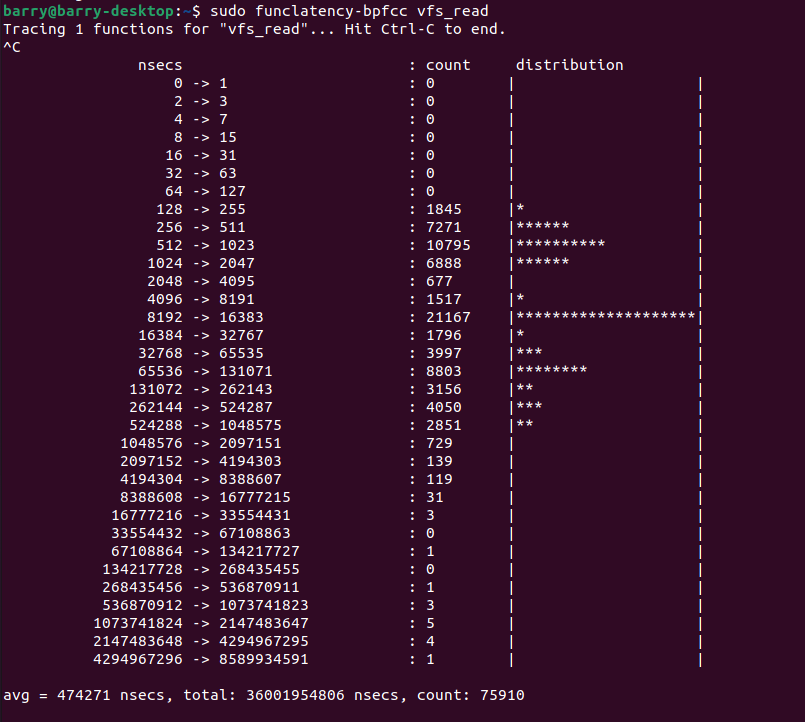
我们看到vfs_read()在实验场景,一般延迟是8-16us之间占据第一名。但是偶尔也能大到惊人的4294967296ns,也就是4.2秒,从直方图最后一行可以看出,这些可能就是outlier了。
eBPF/BCC可以依附于kprobe、tracepoints上,在eBPF/BCC上定制直方图,只用写非常简单的脚本即可,因为直方图是其本身内嵌的功能。比如在patch【7】中,笔者想知道kernel/sched/fair.c的select_idle_cpu()在进程被唤醒的时候,统计选中与target同cluster idle CPU,不同cluster idle CPU和没找到idle cpu的比例,只需要写一个简单的脚本:
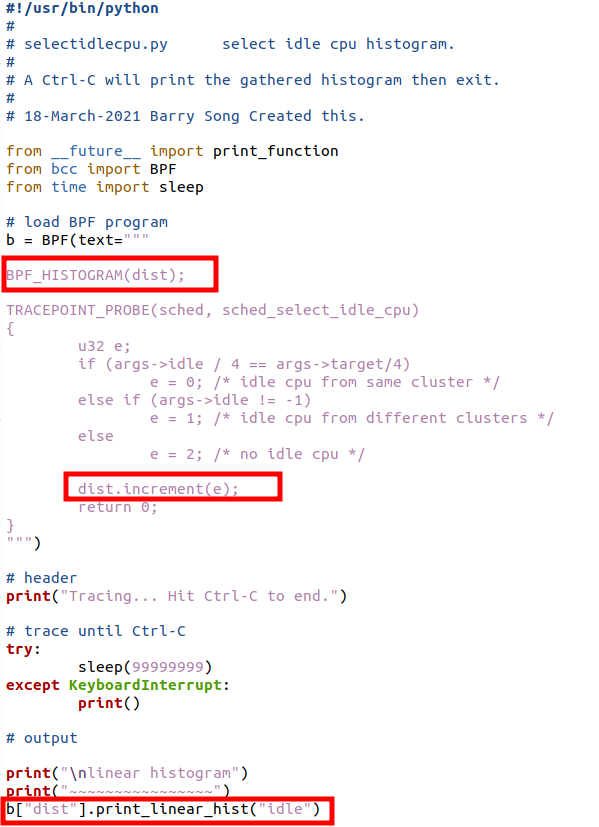
这个脚本的关键是涂了红色的三行,定义了一个直方图对象dist,然后就在里面通过dist.increment(e)增加采样点,最后通过b["dist"].print_linear_hist("idle")把直方图画出来:

eBPF/BCC里面有许多直方图的例子,我们定制自己的直方图的时候,依葫芦画瓢就好。
off-cpu火焰图
实际上,eBPF/BCC的代码仓库已经写好了off-cpu工具,可以直接拿来用:
https://github.com/iovisor/bcc/blob/master/tools/offcputime.py
它的原理是抓捕内核进行进程上下文切换的时间和backtrace,比如可以对finish_task_switch()内核函数施加探针。因为我们在这个点可以知道什么进程被切换走了,什么进程被切换回来的,结合这些点的backtrace搜集,我们就可以得到睡眠和唤醒的调用栈,以及时间差。可以在这个函数加tracepoint,但是没有tracepoint的情况下,我们也可以直接attach kprobe探针。
finish_task_switch()的函数原型是:

可见参数prev是被切换走的进程,而我们通过current可以拿到当前的进程,也即我们切入的进程。通过下面的算法,即可求出整个off-cpu区间的时间和backtrace:

通过在内核finish_task_switch()的kprobe点上插入eBPF/BCC代码来完成这个算法,这样不需要修改和重新编译内核。之后,我们可以把eBPF/BCC捕获的数据,借助flamegraph工具,绘制出off-cpu火焰图。
下面给一个非常简单的案例,在我的Ubuntu x86 PC上面运行以下代码,创建32个进程,每个进程申请1G内存,然后循环执行:16字节对齐的时候写入一个字节,1MB对齐的时候睡眠30us。
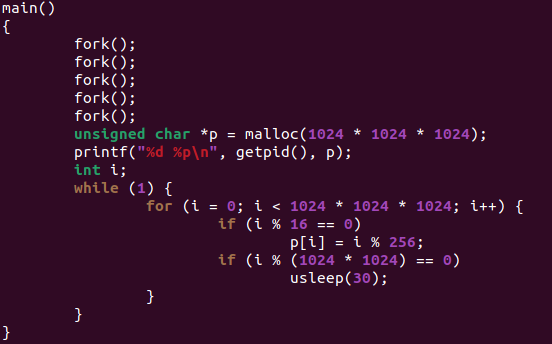
测试内核是5.11.0-49-generic,内核未开启抢占,但是允许PREEMPT_VOLUNTARY:
# CONFIG_PREEMPT_NONE is not set
CONFIG_PREEMPT_VOLUNTARY=y
# CONFIG_PREEMPT is not set
测试的环境开启了zRAM的swap,但是关闭了磁盘相关的swap:

捕获a.out 30秒的off-cpu数据,并绘制火焰图。

得到如下火焰图:
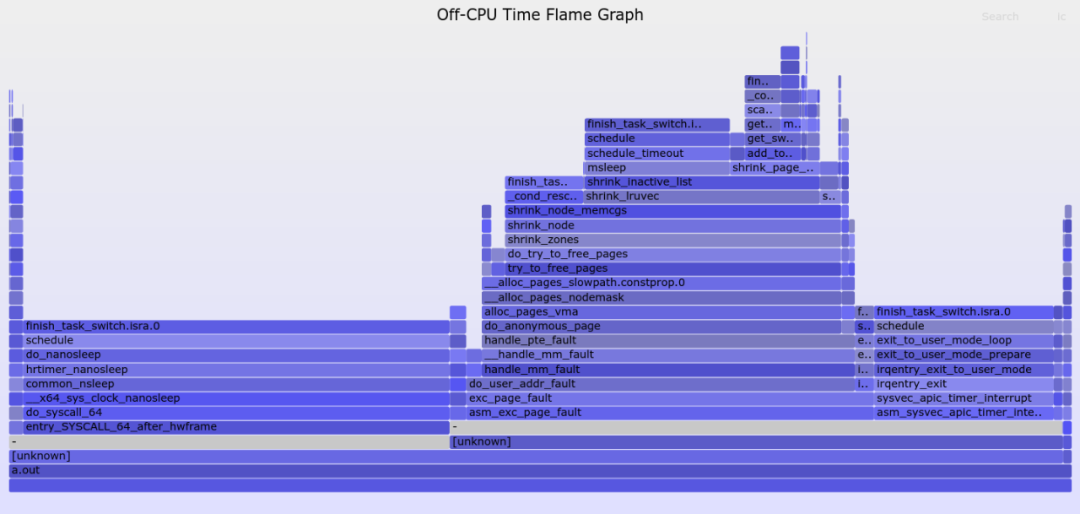
从以上火焰图可以看出,a.out的延迟主要是3个方面原因:
发生在其用户态代码本身调用的nanosleep()上;
发生在page_fault的处理上;
时间片到期后, timer中断进来,把它切换走。
我们把这3个块分别画3个圆圈:
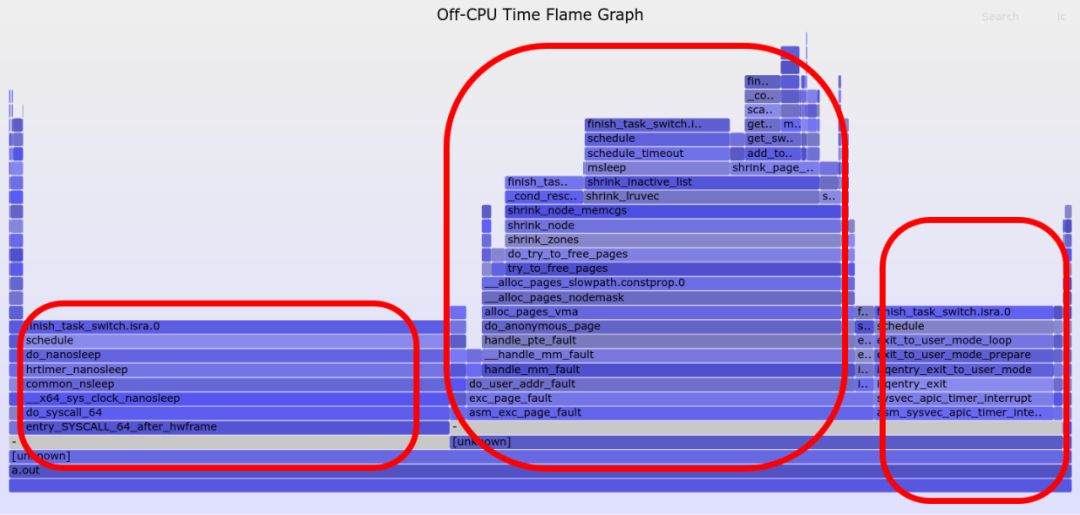
火焰图的纵向是backtrace,横向是每一种情况的off-cpu时间,横向越宽代表这个调用stack上的off-cpu时间越久。
假设我们shrink_inactive_list()这个函数特别感兴趣,则可点击shrink_inactive_list()这个函数,单独查看这个函数的off-cpu细节,我们发现,它其中一半的off-cpu是因为它自己调用了一个msleep(),还有很大一部分发上在它主动call了_cond_resched(),然后CPU被别人抢走;如果我们关注mutex_lock() 的延迟,则显然发生在shrink_inactive_list() -> shrink_page_list() -> add_to_swap -> get_swap_pages() -> mutex_lock()这个路径上。

如果我们把焦点移到kswapd,我们还是运行上面的a.out代码,但是我们捕获和分析的对象换为kswapd。捕获kswapd的off-cpu数据30秒并绘制off-cpu火焰图。

绘制出来的kswapd的off-cpu火焰图如下:
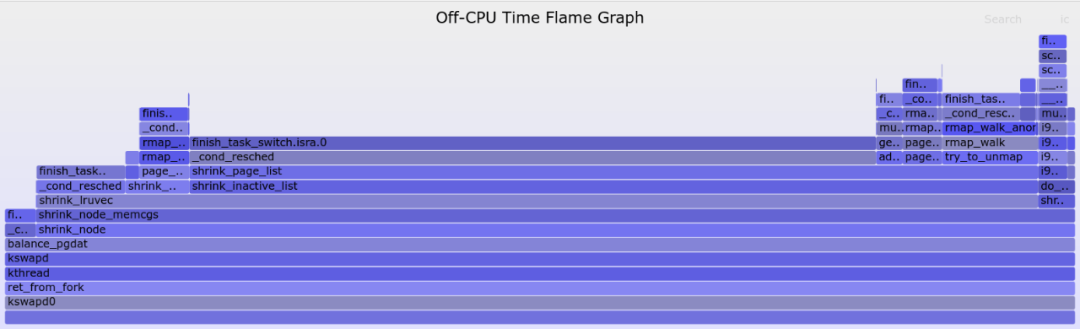
可见多数延迟发生在kswapd各种路径下(比如shrink_inactive_list -> shrink_page_list路径)主动调用_cond_resched()出让CPU,还有一部分延迟发生在最右边的shrink_slab的i915显卡驱动的slab shrink,点击放大它:
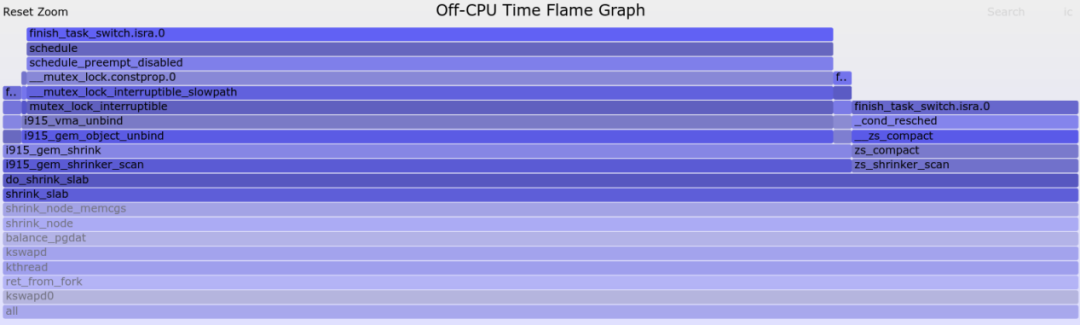
从上图可以看出,我们在内存回收shrink_slab()的时候,被i915驱动的i915_gem_shrink()堵住了,而i915_gem_shrink()被一个mutex_lock_interruptible()堵住了,所以i915驱动持有的一个mutex实际上给shrink_slab()是添堵了。
特别有意思的是,这个off-cpu火焰图,还可以变成双层的off-wake火焰图。比如A进程等一个锁睡眠了,B进程是持有锁的人,B唤醒了A,在off-wake火焰图上,它会以双层调用栈的形式进行展示。比如在a.out引起匿名页频繁swap的情况下,抓一下kswapd的off-wake火焰图:

得到的图如下:

从图上可以完整看出,kswapd off-cpu的原因和唤醒者。比如画红圈的区域,kswapd因为调用kswapd_try_to_sleep()而主动进入睡眠,a.out在swap in的过程中do_swap_page()因而需要alloc_pages()的时候因为申请内存的压力,唤醒了kswapd内核线程。天蓝色的是kswapd,淡蓝色的是唤醒者。唤醒者的调用栈是从上到下,off-cpu的kswapd的调用栈是从下到上,中间通过灰色隔离带隔开。这种描述方式,确实看起来比较惊艳有木有?

Lock Contention分析
在使能内核CONFIG_LOCKDEP 和CONFIG_LOCK_STAT 选项的情况下,我们可以通过perf lock来进行lock的contention分析。其实perf lock主要是利用了内核一系列的锁的tracepoints,比如trace_lock_acquired(lock, ip)、trace_lock_acquired(lock, ip)、trace_lock_release(lock, ip)等。
在我运行一个匿名页频繁swap out/in的系统里,抓取lock情况:

然后生成报告:
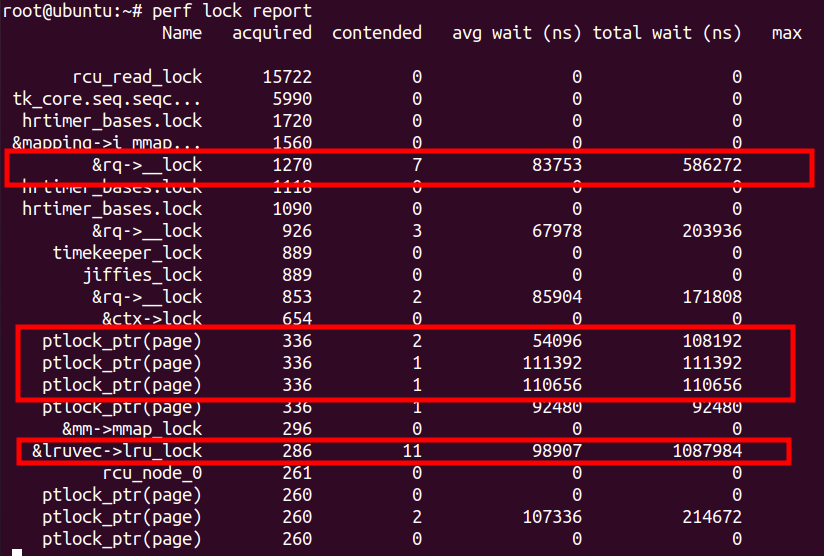
看起来&rq->__lock、ptlock_ptr(page)、&lruvec->lru_lock的竞争比较激烈。尤其是&lruvec->lru_lock,由于contention比较多,total wait时间比较大。这里要特别留意一点,lock contention不一定是off-cpu的,可能也有on-cpu的,对于mutex, rwsem更多是off-cpu的;spinlock,则更多是on-cpu的。
对于off-cpu以及相关的延迟问题,我们需要通过直方图获知延迟分布、off-cpu/off-wakeup火焰图获知off-cpu的原因和唤醒者,如果是锁竞争的情况,则进一步通过内核perf lock剖析锁竞争。
四、总结
性能优化经常是一个全栈的工作,对工程师的要求也比较高。它是一个很难用一篇文章完整描述清楚的话题,所以本文更多只是起一个提纲挈领的作用,许多话题有待以后有机会进一步展开。文中疏漏,在所难免,还请读者朋友海涵。最后推荐给亲爱的读者朋友们2本书:
BrenDan Gregg的《System Performance Enterprise and the Cloud(Second Edition)》;
Denis Bakhvalor的《Performance Analysis and Tuning on Modern CPUs》
参考文献
【1】https://people.csail.mit.edu/nickolai/papers/boyd-wickizer-locks.pdf
【2】https://lore.kernel.org/linux-mm/20220614071650.206064-8-yuzhao@google.com/
【3】https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/drivers/iommu/arm/arm-smmu-v3/arm-smmu-v3.c
【4】https://www.intel.com/content/www/us/en/develop/documentation/vtune-cookbook/top/methodologies/top-down-microarchitecture-analysis-method.html#top-down-microarchitecture-analysis-method_GUID-FA8F07A1-3590-4A91-864D-CE96456F84D7
【5】https://github.com/andikleen/pmu-tools
【6】https://lore.kernel.org/all/1612296553-21962-9-git-send-email-kan.liang@linux.intel.com/
【7】https://www.spinics.net/lists/arm-kernel/msg882962.html

长按关注内核工匠微信
Linux 内核黑科技 | 技术文章 | 精选教程














 3417
3417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











