






根据中国音像与数字出版协会发布的《2024年中国游戏产业报告》显示,中国游戏用户规模已经达到6.74亿人,在这庞大的市场中,移动游戏实际销售收入占比为73.12%,持续稳居主导地位。这说明如今手机用户玩游戏已经是主流趋势,作为开发者必须为用户提供更好的游戏体验。在游戏体验优化这方面,可能大家第一个想到的是游戏开发商,他们必须合理利用手机系统提供的资源,给玩家流畅舒适的游玩体验。但与主机和PC游戏开发不同的是,由于移动设备的安全限制,游戏开发商并没有足够的系统权限,无法根据手机实际的硬件情况进一步调优。因此,在移动游戏体验的优化上,除了游戏开发者们自己的优化,移动设备生产商的努力也同样至关重要的(这就是为何即便是同一芯片平台的设备不同品牌实际体验也有着明显差别的原因)。
本篇文章将以移动设备厂商开发者视角,围绕性能和功耗两个最重要的方面,深入探讨如何优化游戏体验,力求为玩家提供更流畅和持久的游戏体验。需要说明的是,游戏体验是一个非常主观且庞大的话题,本篇只是介绍其中的性能和功耗,其他诸如触控、插帧、超分等不在讨论话题之内。
量化游戏体验
在具体讲性能功耗优化之前,首先得说明一下如何量化性能和功耗两者的游戏体验,熟悉游戏帧率、功耗概念的朋友可以直接跳过本节。
帧率
相信经常玩游戏的朋友肯定听说过帧率(FPS,Frames Per Second)这一概念,它指的是游戏中显示屏实际每秒显示出来的帧数,我们常常可以通过游戏里面的设置来告诉游戏我们期望的游戏帧率,比如在王者荣耀设置->图像->帧率中可以设置帧率为极高(对应120FPS)。
但玩家设置好了帧率不代表实际游戏中帧率真能一直维持在120,具体取决于使用的手机硬件配置和软件系统上的优化。前者最相关的莫过于SOC芯片,例如高通的骁龙系列芯片、联发科的天玑系列芯片,后者指的就是今天我们要讲的软件上的优化。只有硬件上具有相应能力、软件做好了相应适配,玩家游戏中实际帧率才能与设置的相符合。
在实际中,我们主要使用平均帧、标准差、最低帧三个指标来衡量游戏的帧率体验。
平均帧就是一段时间FPS的平均值,它越高代表游戏越流畅;
标准差代表游戏中FPS的波动情况,越低代表波动越小帧率越稳定;
最低帧反应游戏中是否有瞬时的明显卡顿。
因此,在性能优化这一话题里,我们的目标就是针对这三个指标,研究如何使平均帧高、标准差低、最低帧高以及三个指标之间的权衡,在后文中我们会看到,实际上我们的最终目标就是如何让帧率稳定在期望的目标帧率。
功耗
另外一个移动游戏里与性能相当的体验就是功耗了,反映在实际中就是续航,用户肯定希望自己手机能多玩几局游戏,谁也不希望在玩的开心的时候手机没电了需要去充电,更糟糕的可能是当时充电器还不在身边。
对于功耗,我们常常使用平均电流(mA)或瓦特(W)来衡量体验,两者实际上是等价的,所以这里就关注前者就好了,比如某游戏的平均电流为1200mA,用户用的手机电池容量为6000mAh,那么就可以预估用户从100%电量玩到0%关机可以玩5小时,如果在同样的游戏场景下把功耗优化到1000mA,那么用户可以玩6小时,节省出的200mA功耗对应的就是用户的1小时游戏时长。
到这里,可能有读者会发现,帧率体验和功耗功耗两者看起来是负相关的,更高的帧率(好的体验)应该意味着更高的功耗(坏的体验),实际上往往也是这样的,针对性能功耗的优化可能就是对性能和功耗体验的权衡取舍。它的另一种具象表述就是能效曲线(如果你之前看过极客湾这类的评测博主,相信你不会陌生),下图是高通和联发科最新旗舰SOC的CPU能效曲线,纵坐标的分数反映在游戏上就是帧率体验。
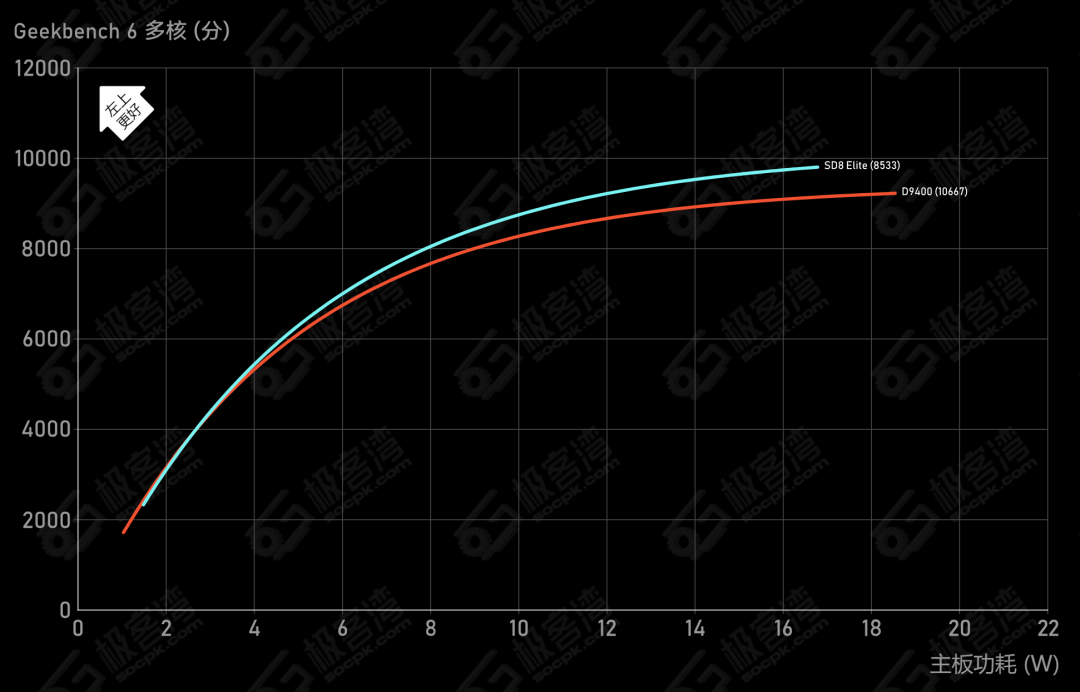
(图源:CPU能效曲线)
需要补充的是,性能与功耗并非绝对的负相关,由于软件系统的复杂性,游戏的实际体验往往不会准确落在能效曲线上,而是在能效曲线的右下方,这意味着通过适当的优化,做到性能与功耗的双丰收并非不可能。
术语
为避免混淆,这里我们统一一下术语:
追帧。有两种解释,1. 游戏性能优化中计算目标帧率这一单一步骤;2. 整个帧率体验优化统称为追帧。为避免混淆,本文不使用这一概念;
控帧。替代追帧的第一种解释,指软件实时计算目标帧率的算法;
调频。软件以帧为单位预测接下来一帧需要多少算力(即CPU频率)的算法;
boost。当调频预测的算力少于实际需求时在帧内调高频率的算法,急拉、rescue、jerk与boost都是同一个概念,本文统一使用boost。
控帧
关于游戏的性能优化,首先我们必须要做的就是控制帧率,也就是通过特定的规则或配置计算确定出当前游戏应该达到的目标帧率。
你可能会疑问,这不是游戏厂商自己的事情吗?玩家在设置里选择帧率选项不就好了,选60帧就60,选120就120,这不就是目标帧率吗?
实际并没有这么简单,有时候用户并不知道自己设备的能力,如果平台能力差,用户在游戏里仍设置了较高的目标帧率,那么用户游戏时帧率的波动就特别大比如一会儿120帧,一会儿帧率降到80帧。这种大的波动用户感知特别强,且波动大的时候往往是游戏最关键的时刻,如10人团战,实际游戏体验往往不如将目标帧率设置在90帧。
所以我们需要在用户设置的基础之上,根据具体游戏、具体平台能力,调整目标帧率,让帧率稳定在固定值周围。
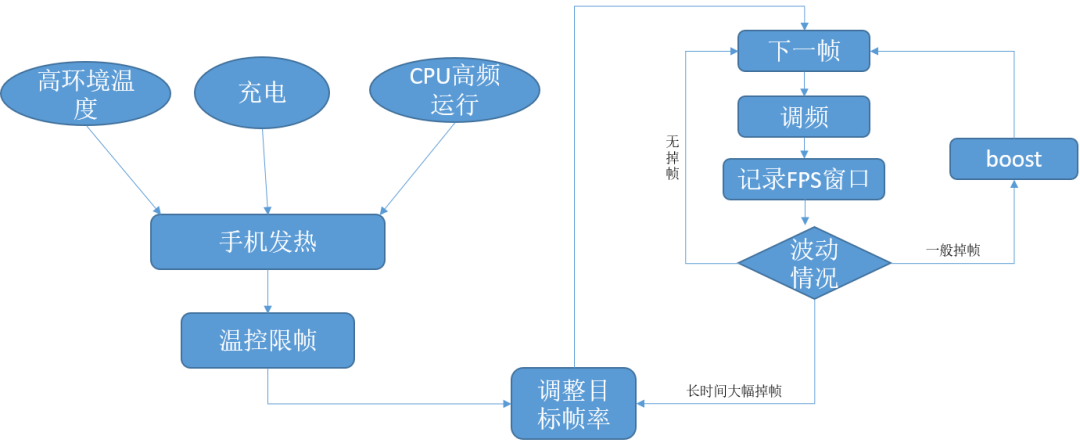
温控限帧
在一些游戏场景下,例如环境温度高、边充电边玩,手机的温度会越来越高,可能达到了无法忍受的程度(甚至烫伤),这时候就应该触发温控限帧,调整目标帧率,降低性能需求以减少手机发热对游戏体验的影响。同理,在手机性能需求特别高时,比如游戏是开启悬浮小窗,此时CPU长时间频率特别高时,由能效曲线可知这时候的功耗会特别高,此时手机发热也会特别严重,需要温控限帧。
由于这部分主要是经验和白名单为主,所以没有太多代码值得介绍。结合后文调频和boost,简单画了一个控帧算法示意图:
调频
通过控帧算法得到目标帧率后,我们需要做的就是想办法达到目标帧率了,即告诉系统我们需要多少的算力,当前CPU应该跑在多高的频率。在具体将调频算法之前,有必要介绍一下常用的调频的基础设施:PM QoS和uclamp。
使用PM QOS给CPU调频
依托于DVFS(Dynamic Voltage Frequency Scailing),我们有能力在游戏中以每帧为单位来调整游戏的频率,以120FPS为例,我们可以轻松做到每8.3ms调整至少一次CPU的频率。在内核中,我们一般调用PM QOS(Power Management Quality of Service)接口来进行调频,其接口定义如下(qos.c - kernel/power/qos.c - Linux source code v6.12.3 - Bootlin Elixir Cross Referencer):
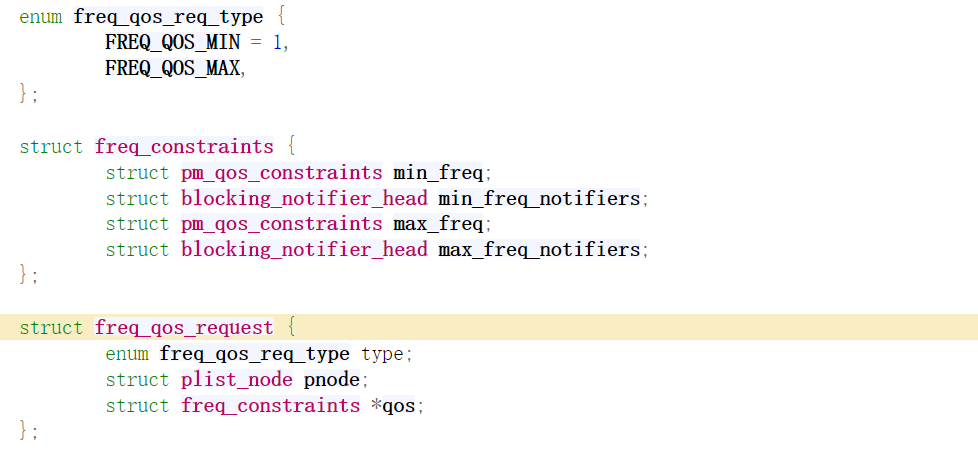

通过freq_qos_add_request接口,以频率上限max_freq(天花板频率)和下限min_freq(地板频率)的方式,我们可以向内核CPUfreq子系统通知(通过内核通知链)当前频率请求的改变,最后由frequency governor来做实际的调频,以schedutil governor为例,代码如下(cpufreq_schedutil.c - kernel/sched/cpufreq_schedutil.c - Linux source code v6.12.3 - Bootlin Elixir Cross Referencer):


freq_qos_add_request请求最终会通知调用schedutil的sugov_limit接口,然后它向驱动写入请求的min_freq和max_freq。
使用uclamp给任务调频
基于PM QoS的调频是per cpu的,无法给指定任务进行限频,使用uclamp(Utilization Clamping)则可以做到。
在游戏中,我们关注的往往是固定几个高负载线程,例如游戏的逻辑线程和游戏的渲染线程(在Unity引擎游戏中一般为UnityMain和UnityGfx),由于内核中任务可能被抢占或被负载均衡迁移,任务不太可能完全固定在单个CPU上,per cpu的调频可能会不够精确或者计算会更加复杂,通过uclamp来per task设定任务的算力可以做到更加精确地分配算力资源以节省功耗。uclamp在sched_attr结构体中表示为sched_util_min和sched_util_max(types.h - include/uapi/linux/sched/types.h - Linux source code v6.12.3 - Bootlin Elixir Cross Referencer):

在用户空间可以通过系统调用(sched_setattr(2) - Linux manual page)设置uclamp或在内核直接使用sched_setattr_nocheck接口(syscalls.c - kernel/sched/syscalls.c - Linux source code v6.12.3 - Bootlin Elixir Cross Referencer):

当任务在enqueue时触发schedutil governor计算util时,会考虑uclamp(cpufreq_schedutil.c - kernel/sched/cpufreq_schedutil.c - Linux source code v6.12.3 - Bootlin Elixir Cross Referencer):

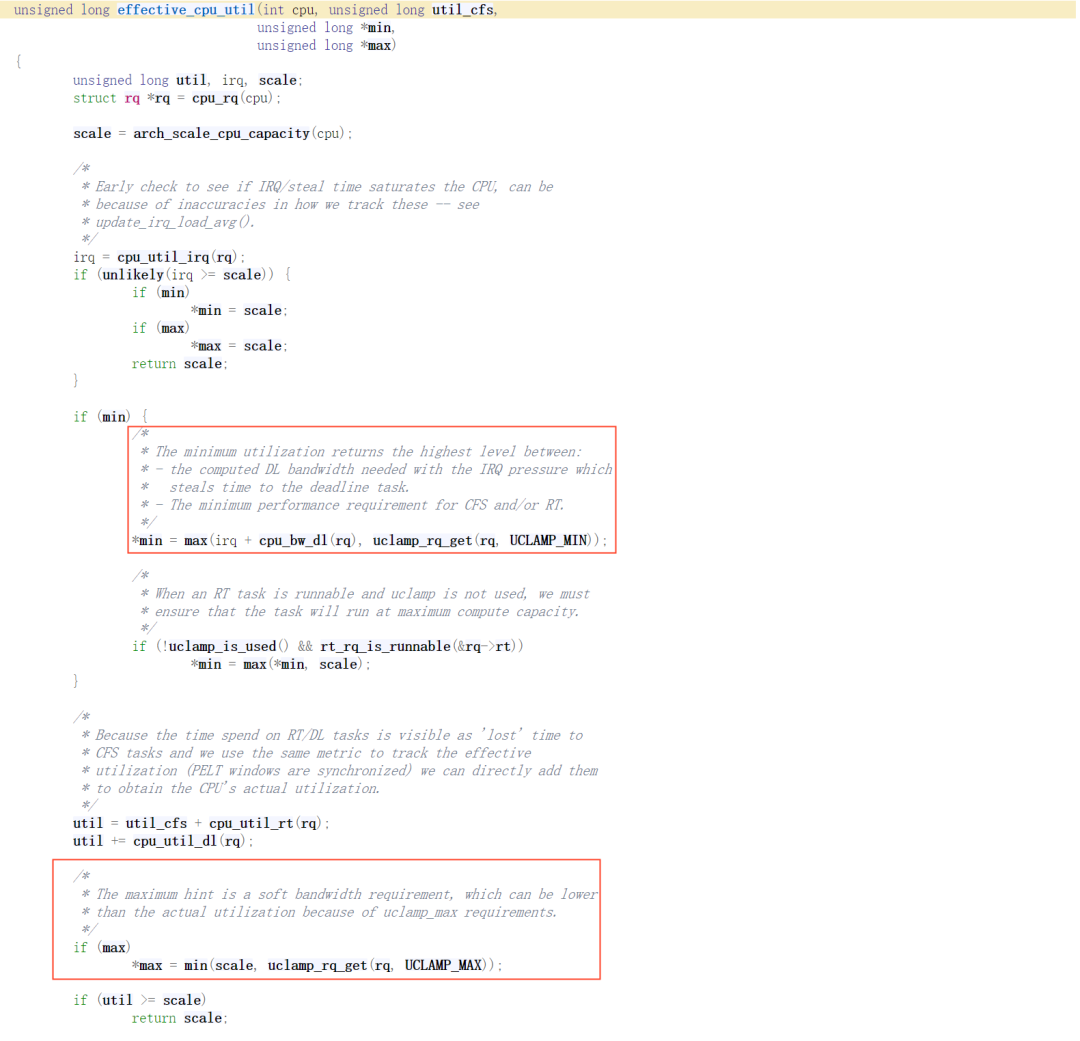
简单来说,在计算时使用sched_util_min和sched_util_max做clamp操作,最终util为:
final_util = clamp(util, sched_util_min, sched_util_max);
使用uclamp的缺点是当runqueue任务不为1时,sched_util_max的实际值为runqueu里最大的,也就是说可能sched_util_max并不能100%保证为设置的,如果其他任务设置了更大的值,就以更大的为准,这样实际使用时可能会压不住频率。所以我们通常使用uclamp来设置任务的地板频率,而天花板频率使用PM Qos来设置。
调频算法
有了调频的能力,那么我们怎么确定改调多大的频率呢?一般的思路就是看负载,也就是任务在CPU上运行的时间,如果任务运行时间过长,例如目标是每帧8.3ms,实际却运行了12ms,那么我们需要再高一点的频率,如果实际运行了4ms,那么我们需要调低一点频率。注意我们并不能预见未来CPU的负载,所以我们只能根据历史上的负载表现来推测出一个算力值,最简单的方法就是指数移动平均EMA(Exponential Moving Average),计算方法如下:
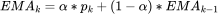
其中,是第个观测点,此处即为CPU的负载,是观测的个数,比如取过去30帧的平均负载,然后依据这个负载(为了方便,将它归一化为0-1024的值,下文以util表示)算出接下来一帧需要的频率(下文以freq表示):
freq = C * util / max_util_this_cpu * max_freq_this_cpu
其中C是一个常数,例如我们想让cpu上负载保持20%的余量,那么C = 1 / (1 - 20%) = 1.25。
这里区分一下内核里面的负载追踪算法,例如通用的PELT算法或者高通的WALT算法,当任务负载(这里用util表示)改变时,也会通知governor(仍然以schedutil governor为例)调频,schedutil会根据任务util的大小以同样的计算方法将util换算成具体的频率freq。
与游戏调频的区别是,governor算的是确定的值,PM QoS和uclamp设定的是min和max,即天花板和地板,ucalmp是governor在计算util时做的clamp,PM QoS则是在发送频率给驱动时做的clamp,即:
final_freq = clamp(freq, min_freq, max_freq);
以cpufreq_driver_fast_switch执行路径为例,代码如下:
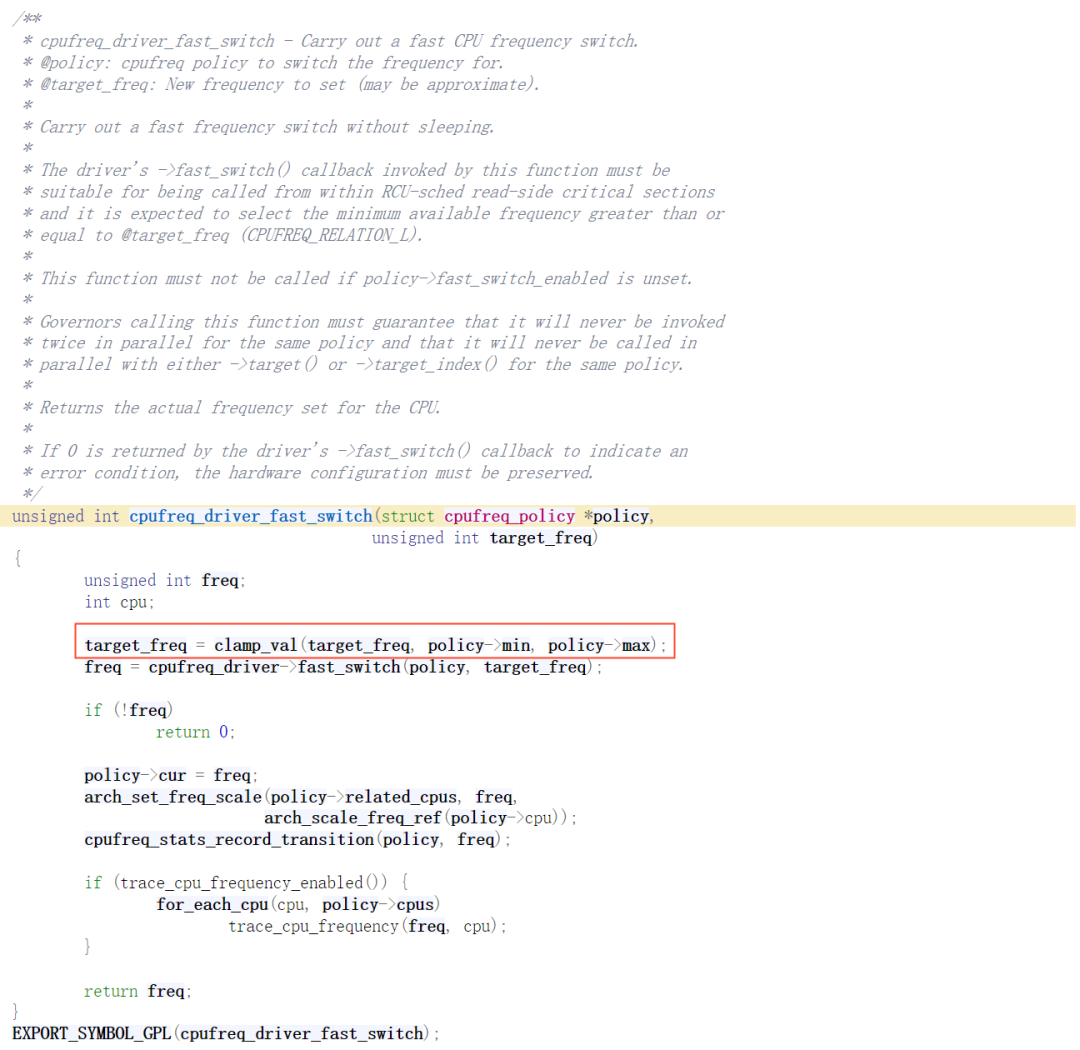
不难发现,如果我们对自己调频算法有自信,可以在添加qos请求时将min_freq和max_freq始终保持一致,或者将uclamp的min与QoS的max保持一致,这样内核自己的负载追踪算法就不会被使用。
这里说到自信,并不是玄学,因为我们调频本质上做的事情就是预测未来,EMA用的最多的地方是股市,如果真能通过EMA或者任何算法准确预测未来的话,那炒股的人都会只赚不赔,哪儿会有那么多“天台见”的说法呢。这里的意思是,我们必须对未来的不确定性做好提前的准备,在意外发生时给出弥补的方法(本文中指的就是boost啦)。
在开始讲boost之前,我们还可以看看有什么其他办法来缓解调频不准的问题。这里介绍一种Closed Loop Control的方法:
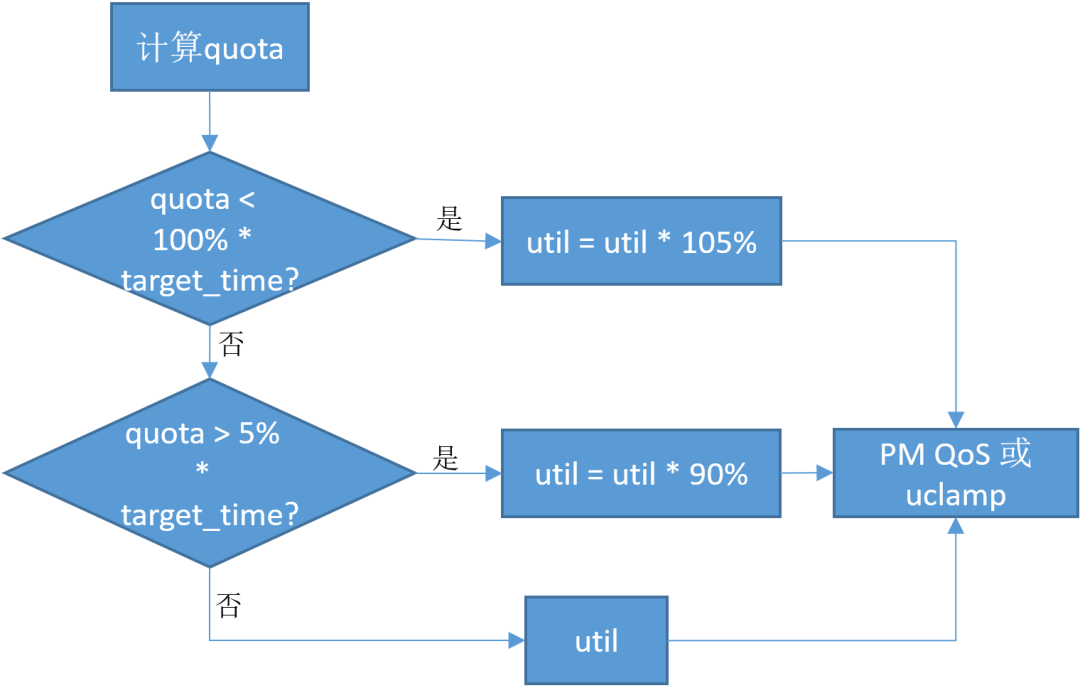
1.计算1s窗口内每帧余量之和:,其中n是窗口内帧数,例如120,q2q_time表示实际一帧的时长,target_time表示期望的帧长;
2.如果quota < -100% * target_time,上修util:util= util+ 5;
3.如果quota > 5% * target_time,下修util:util= util- 10。这里的数值都是经验值,可调;
通过这样一种类似负反馈的方法,我们期望最终预测的freq与实际游戏需求的相当。
Boost
上文我们表达过“历史可能相似,但不会简单重复”的观点,接下来我们就看看如何来未雨绸缪,迎接不确定的未来吧。在游戏的性能优化里,我们广泛使用boost这一术语来表达性能不够需要采取补救措施的意思。
在调频给的算力长时间未能使游戏出帧时,我们通过boost把频率进一步拉高,以期望当前帧时间不要和期望的相差很高。由于我们是以帧为单位调频和boost,通过这种补救措施,就可以让用户即便在复杂的场景下也能用稳定帧率的体验。
那具体什么时间点boost呢,这里利用上文调频计算的quota值给出一种计算思路:
time_boost = target_time * (1 + a) + quota * b
即在帧开始时设置计时器,经过time_boost后触发boost。其中a、b均是可调参数。
在触发boost后,下一步就是确定应该boost多大的频率。由于不同芯片平台的能力各不一样,这里通常我们也会设置成可配置的参数,可以配置绝对的值,也可以相对调频的频率配置一个相对的值。
为了避免不必要的boost浪费功耗,实际boost的时候还可以依据具体出帧进度来区别boost,思路如下:
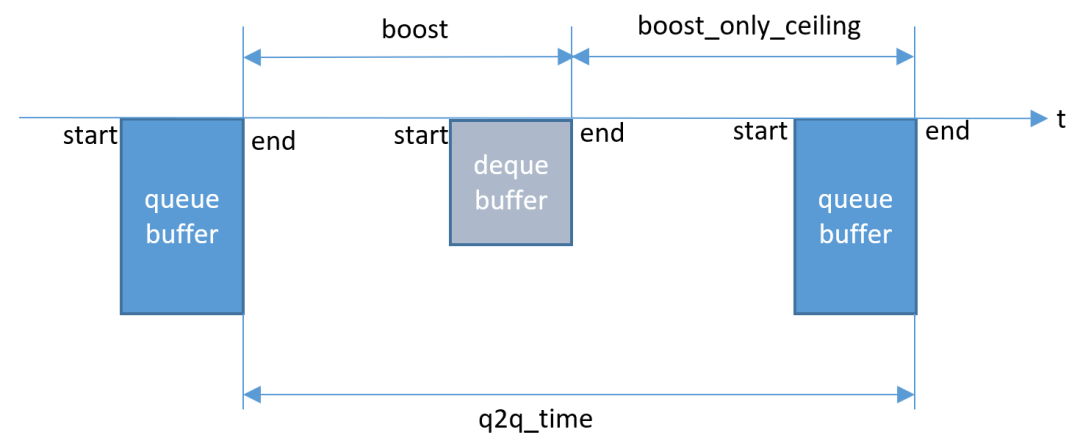
如图,游戏渲染线程queue buffer给surfaceflinger(以下称SF)结束为帧开始时间,到下一帧queue buffer结束之间的时间叫做q2q_time,也就是实际一帧的时长,如果目标帧率是120,那目标时间target_time = 8.3ms,如果q2q_time > target_time,那么就需boost,根据经过target_time实际进度来区别boost:
1.如果还在enqueue end 和dequeue end之间,说明当前性能严重不足,需要同时拉高天花板频率和地板频率;
2.如果在dequeue end之后,说明当前帧已经生成,仅急拉天花板频率,不需要拉高地板频率
注意这里没有考虑SF的buffer堆积,实际实现中如果SF有buffer堆积也应暂缓boost。
将控帧、调频和boost三者结合,大致流程如下:
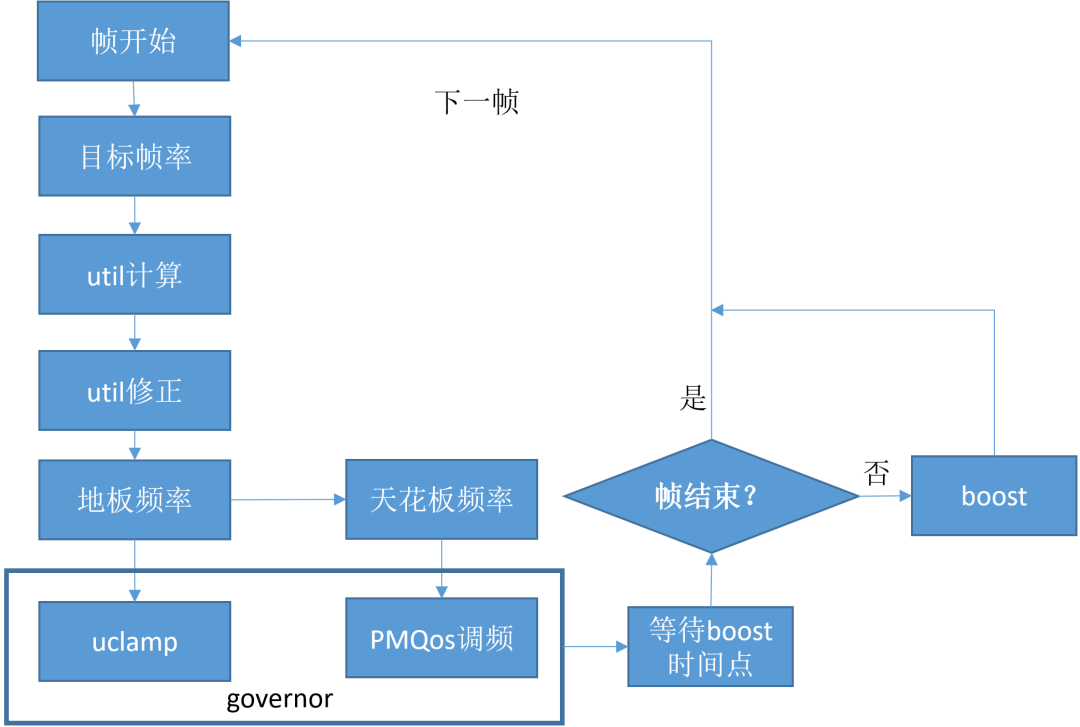
由于Linux通用的调频governor并没有考虑游戏场景,所以有关调频和boost公开的代码不多,各个厂商具体思路肯定不会完全一致,本文主要参考的思路是联发科开源的fpsgo代码,有兴趣的朋友可以阅读。
特定场景的优化
上述性能功耗优化思路是针对所有游戏普适的优化思路。实际上我们还可以针对一些特定的游戏场景进行性能和功耗的优化,下面简单举例介绍几种思路。
识别掉帧场景
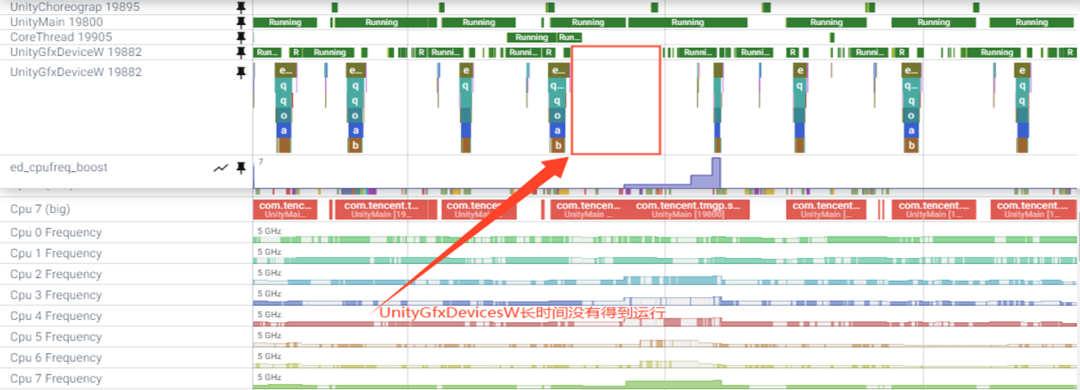
对于一些热门游戏,我们可以观察掉帧场景做专门的优化,例如通过trace分析发现一些有规律的掉帧现象,我们可以通过代码识别这些掉帧特征,然后及时地boost。下图是在王者荣耀游戏里,我们发现渲染线程长时间没得到运行时容易掉帧的情况:
将关键线程绑定在CPU上
在游戏场景里,一般只有已知的一些游戏相关线程负载特别高,且他们往往都是固定的,例如使用Unity引擎的游戏UnityMain任务和UnityGfx任务通常是负载最高的。我们自然可以将这些高负载地关键线程绑定在固定CPU上,这样做地好处是:
1.简化选核逻辑。任务在EAS选核或负载均衡时,可以更快地返回,跳过不必要的逻辑,减少实际执行的指令数,从而节省功耗;
2.减少缓存的迁移。对Big.Little架构的平台而言,簇间任务迁移的开销是非常大的(跨L2缓存),因此将任务固定在CPU上可能减少系统调度的开销,提升性能,节约功耗;
3.把关键线程完全固定在指定CPU上。解决上文提到的PM QoS无法per task调频的问题。
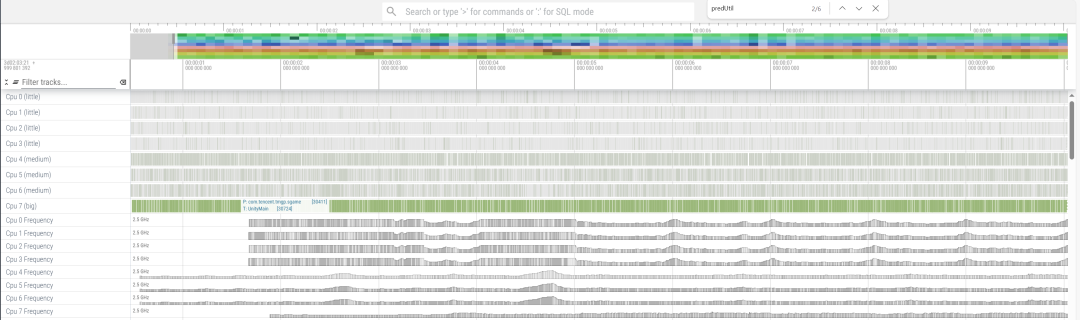
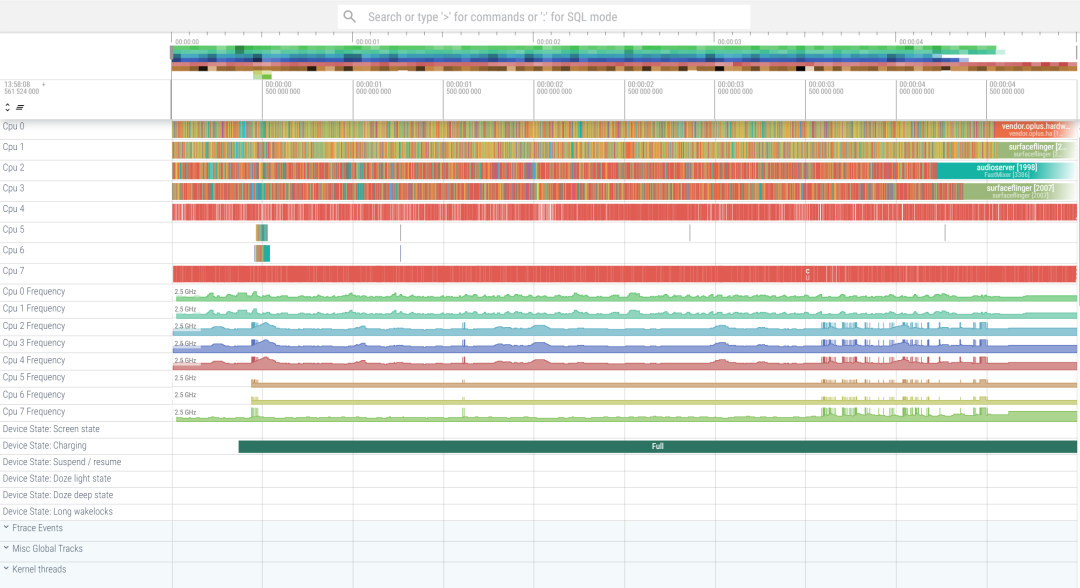
下图是将UnityMain线程绑定在超大核上的systrace截图:
调度器的客制化
在实际实现中,要保证100%将任务固定在指定CPU上是非常困难的,例如任务可能被RT线程抢占。为避免该问题,可以定制一个专门针对游戏场景的调度类(具体思路可以看之前关于sched-ext调度类的分享)。当然定制调度类的好处远远不止绑定CPU这一个好处,它同样可以减少调度执行的指令。更重要的是,通过定制调度类,可以轻松地指定任务实际该运行在哪个CPU上,这样可以做到在游戏负载特别低的时候,部分CPU可以完全不运行任务,此时CPU可以进入patial halt状态(可以理解为深度睡眠状态),可以节省非常可观的功耗。
下图是使CPU5和CPU6进入patial halt状态的systrace截图
总结
在本文中,我们从手机制造商的开发者角度出发,探讨了如何通过优化性能和功耗这两个关键因素来提升移动游戏体验。这不仅可以增强游戏的流畅度,还能延长用户的游戏时长,更好地满足玩家的需求。随着中国移动游戏用户规模的迅速增长,提供卓越的用户体验已成为行业的重要目标。优化用户游戏体验是一个复杂而综合的课题,需要游戏开发商、手机制造商和芯片厂商等合作伙伴共同努力,以推动行业的进步与发展。
参考1.https://github.com/deadman96385/android_kernel_zte_mt6761/tree/master/drivers/misc/mediatek/performance/fpsgo
2.qos.c - kernel/power/qos.c - Linux source code v6.12.3 - Bootlin Elixir Cross Referencer
3.Power Management — The Linux Kernel documentation
4.[RFT][PATCH 1/3] PM: QoS: Introduce frequency QoS - Rafael J. Wysocki
5.Utilization Clamping — The Linux Kernel documentation
6.Scheduler — The Linux Kernel documentation
7.socpk.com
8.《2024年中国游戏产业报告》发布 游戏用户规模6.74亿人--金报--人民网

往
期
推
荐
探索Android动态埋点的新视界:UprobeStats深度解析



















 1064
1064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











