









目录
3. userspace设置task的uclamp- __setscheduler_uclamp()
8. 修改group的clamp并update到group中的task
简介
uclamp是在kernel5.3引入的新feature,又在kernel5.4引入了cgroup的的支持。通过设置task的util值,可以boost task util,达到和android schedtune相似的效果。
一. 数据结构
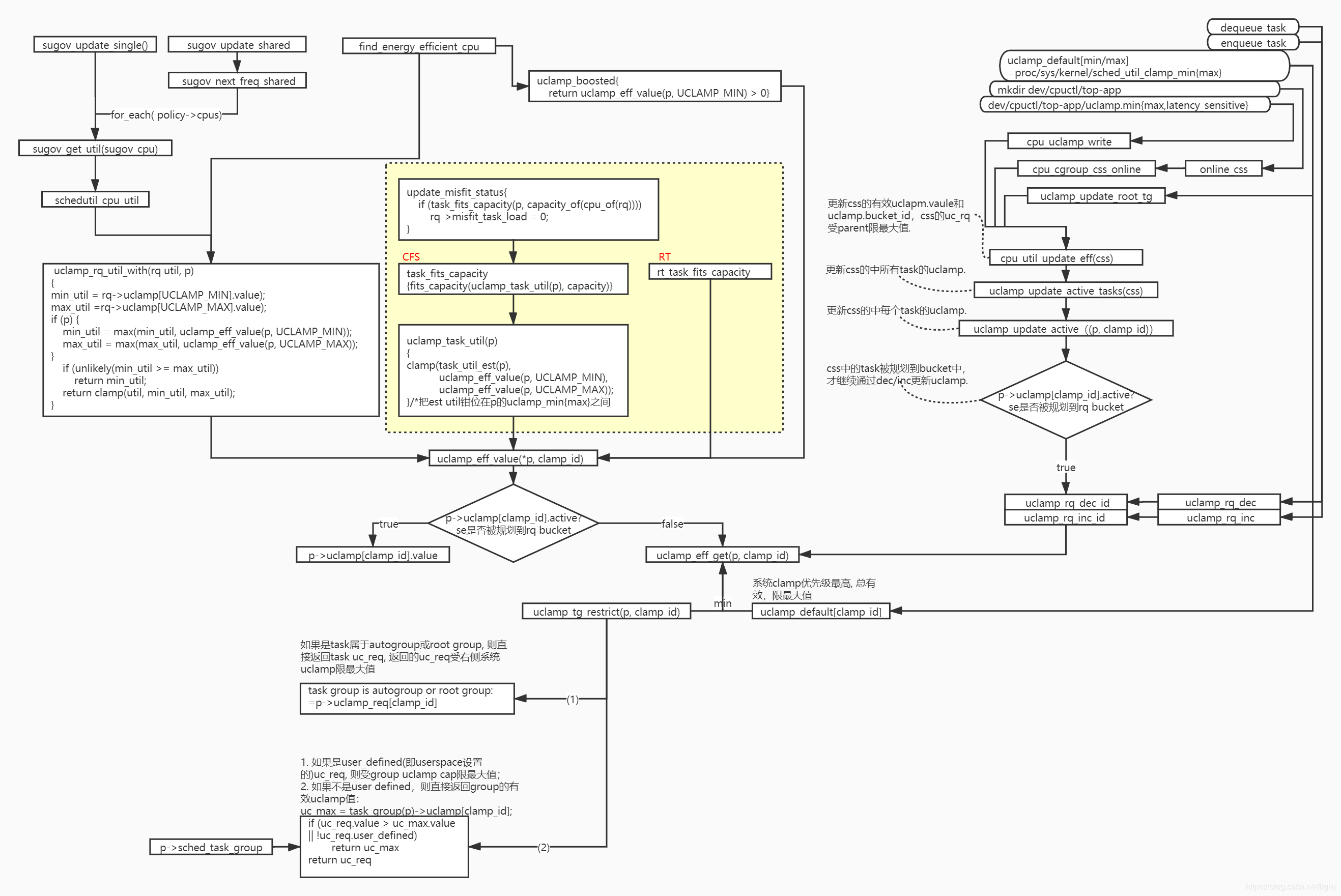
1. rq中uclamp的实现
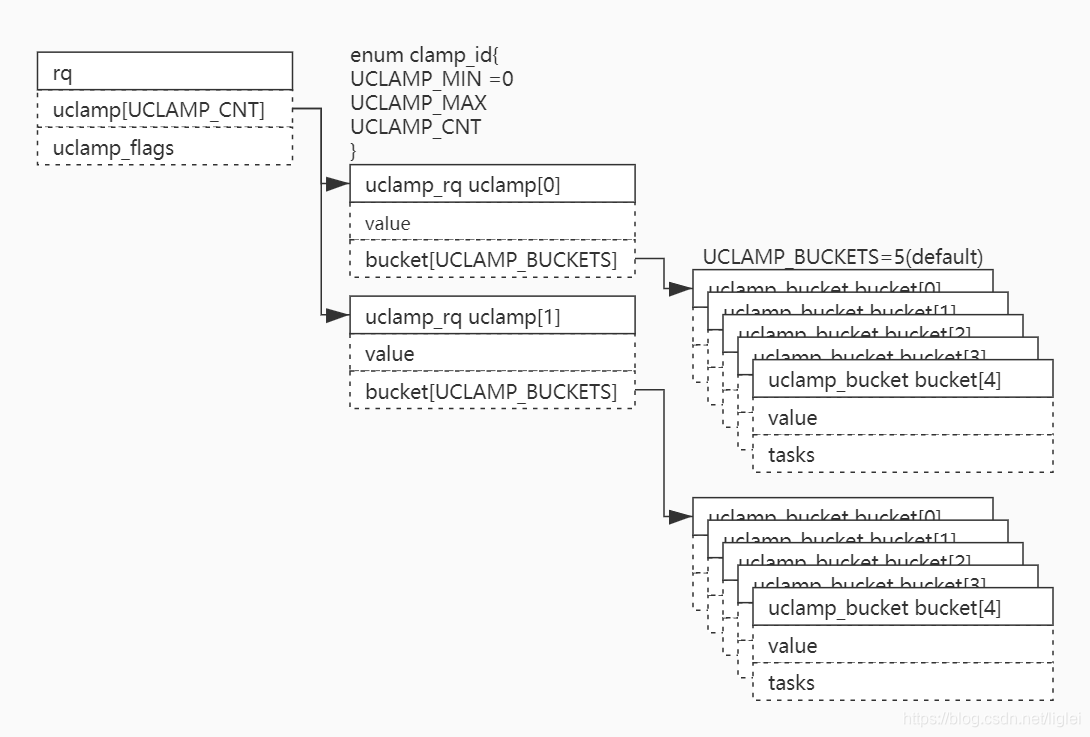 图1-1 rq中uclamp的实现
图1-1 rq中uclamp的实现
#ifdef CONFIG_UCLAMP_TASK
/* Utilization clamp values based on CPU's RUNNABLE tasks */
struct uclamp_rq uclamp[UCLAMP_CNT] ____cacheline_aligned;
unsigned int uclamp_flags;
#define UCLAMP_FLAG_IDLE 0x01
struct uclamp_rq {
unsigned int value;
struct uclamp_bucket bucket[UCLAMP_BUCKETS];
};
在rq中,通过嵌入两组uclamp,即一组最小值uclamp[UCLAMP_MIN]和一组最大值uclamp[UCLAMP_MAX]实现对cpu的util clamp。
每组中的value表示rq当前生效的clamp值,两组中默认各包含5个buckets,可以通过CONFIG_UCLAMP_BUCKETS_COUNT
配置其它buckets数(5~20个)。uclamp_flags在uclamp初始化init_uclamp()时置零,目前只有一个标志位UCLAMP_FLAG_IDLE ,
标识cpu上是否还有task运行。
每个bucket表示一定范围的util值,以系统默认的5个buckets为例,每个bucket的范围是cpu最大capacity的20%:
SCHED_CAPACITY_SCALE/UCLAMP_BUCKETS_COUNT,即1024/5。
rq上的task会根据task的值将其规划到对应的bucket中。比如taskA在cpu0上run,要求25%的util值,会被规划到bucket[1]中,
bucket[1]::value=25%,记录生效的util值,tasks计数加1,表示规划到当前bucket中task又多了一个。如果同时35% util值的taskB被
调度到cpu0上,则此时bucket[1]::value=35%,tasks计数加1。此时taskA受益于taskB 35%的util值,直到taskA退出rq。如果系统中
对taskA受益taskB更高的boot util不能接受(10%),比如功耗增加显著?可以增加bucket数量,这样就减少了每个bucket对应的
util范围,提高了bucket util的统计精度,代价是使用更多的memory分配buckets。当bucket中没有task时,value被设置成默认的
bucket范围的最小值,bucket[1]中没有task时,bucket[1]::value=%20。
2. task中uclamp的实现
图1-2 task中uclamp的实现
struct task_struct
{
#ifdef CONFIG_UCLAMP_TASK
/* Clamp values requested for a scheduling entity */
struct uclamp_se uclamp_req[UCLAMP_CNT]; (1)
/* Effective clamp values used for a scheduling entity */
struct uclamp_se uclamp[UCLAMP_CNT]; (2)
#endif
}
struct uclamp_se {
unsigned int value : bits_per(SCHED_CAPACITY_SCALE);
unsigned int bucket_id : bits_per(UCLAMP_BUCKETS);
unsigned int active : 1;
unsigned int user_defined : 1;
};value:最大值是1024,11bit,表示调度实体的clamp值
bucket_id:默认每个uclamp_id各5个bucket,使用3bit表示,表示clamp值对应的bucket id
active:task被规划到rq的一个bucket中,此bucket::tasks值为此task计数加1,bucket::value值也作用于此task
user_defined:标识是usersapce请求的clamp值 。可以更改system给task默认分配的boost.
uclamp以调度实体的方式嵌入task_struct中,包含两种uclamp_se:
(1) 记录请求的clamp值的request se
(2) 记录生效的clamp值的avtive se
3. 扩展 CPU's cgroup controller
cpu cgroup支持uclamp,通过在cftype cpu_files中添加新系统节点uclamp.{min,max},可以设置group中所有task的boost util值和最大util值,需要配置CONFIG_UCLAMP_TASK_GROUP。
kernel5.4/kernel/sched/sched.h
struct task_group {
#ifdef CONFIG_UCLAMP_TASK_GROUP
/* The two decimal precision [%] value requested from user-space */
unsigned int uclamp_pct[UCLAMP_CNT];
/* Clamp values requested for a task group */
struct uclamp_se uclamp_req[UCLAMP_CNT];
/* Effective clamp values used for a task group */
struct uclamp_se uclamp[UCLAMP_CNT];
/* Latency-sensitive flag used for a task group */
unsigned int latency_sensitive;
#endif
}kernel5.4/kernel/sched/core.c
static struct cftype cpu_files[] = {
#ifdef CONFIG_UCLAMP_TASK_GROUP
{
.name = "uclamp.min",
.flags = CFTYPE_NOT_ON_ROOT,
.seq_show = cpu_uclamp_min_show,
.write = cpu_uclamp_min_write,
},
{
.name = "uclamp.max",
.flags = CFTYPE_NOT_ON_ROOT,
.seq_show = cpu_uclamp_max_show,
.write = cpu_uclamp_max_write,
},
{
.name = "uclamp.latency_sensitive",
.flags = CFTYPE_NOT_ON_ROOT,
.read_u64 = cpu_uclamp_ls_read_u64,
.write_u64 = cpu_uclamp_ls_write_u64,
},
#endif
}通过android的配置,示例如下,通过task group实现对task util的钳制。root_task_group不支cpu.uclamp.min{max}的配置,参见”7274a5c sched/uclamp: Propagate system defaults to the root group“
/dev/cpuctl/top-app/cpu.uclamp.min 30.00
/dev/cpuctl/top-app/cpu.uclamp.max 100.00
/dev/cpuctl/top-app/cpu.uclamp.latency_sensitive 0
二. 关键函数
1. uclamp的初始化
static void __init init_uclamp(void)
{
struct uclamp_se uc_max = {};
enum uclamp_id clamp_id;
int cpu;
mutex_init(&uclamp_mutex);
for_each_possible_cpu(cpu)
init_uclamp_rq(cpu_rq(cpu)); (1)
for_each_clamp_id(clamp_id) {
uclamp_se_set(&init_task.uclamp_req[clamp_id], (2)
uclamp_none(clamp_id), false);
}
/* System defaults allow max clamp values for both indexes */
uclamp_se_set(&uc_max, uclamp_none(UCLAMP_MAX), false); (3)
for_each_clamp_id(clamp_id) {
uclamp_default[clamp_id] = uc_max; (4)
#ifdef CONFIG_UCLAMP_TASK_GROUP (5)
root_task_group.uclamp_req[clamp_id] = uc_max;
root_task_group.uclamp[clamp_id] = uc_max;
#endif
}
}
uclamp的初始化函数,在调度器初始化函数sched_init()最后被调用。
(1) 初始化每个cpu所属rq的uclamp,设置为默认值rq->uclamp[0,1].value={0,1024}。
(2) 初始化init_task的request se,UCLAMP_MIN初始化value=0,UCLAMP_MAX初始化value=1024,并计算对应的bucket id。
(3) 定义了一个uc_max se,并初始化value=1024,计算对应的bucket, uc_max表示clamp的最大值。
(4) 定义了uclamp_default se,并初始化UCLAMP_MIN和UCLAMP_MAX value都为uc_max。uclamp_defaut是所有clamp se的上限,任何clamp se都要小于等于uclamp_default的值。
(5) 初始化root_task_group的request se和active se为uc_max
2. fork task的uclamp
static void uclamp_fork(struct task_struct *p)
{
enum uclamp_id clamp_id;
for_each_clamp_id(clamp_id)
p->uclamp[clamp_id].active = false; (1)
if (likely(!p->sched_reset_on_fork)) (2)
return;
for_each_clamp_id(clamp_id) {
unsigned int clamp_value = uclamp_none(clamp_id);
/* By default, RT tasks always get 100% boost */
if (unlikely(rt_task(p) && clamp_id == UCLAMP_MIN)) (3)
clamp_value = uclamp_none(UCLAMP_MAX);
uclamp_se_set(&p->uclamp_req[clamp_id], clamp_value, false); (4)
}
}
uclamp_fork()在sched_fork()函数中被调用。
(1) 新fork的task不被规划到任何bucket中,设置其uclamp::active=false。
(2) 一般新fork的task都不要求reset sched,此时返回即可。
(3) 如果新fork的task要求reset sched,则设置task的request se,task是RT时,task request se的UCLAMP_MIN和UCLAMP_MAX都设置value=1024,即RT task boost没有限制,获取100% boost。
(4) 其它类型task request se设置UCLAMP_MIN value=0,UCLAMP_MAX value=1024。
3. userspace设置task的uclamp- __setscheduler_uclamp()
__setscheduler_uclamp函数在__sched_setscheduler()函数中被调用。
static void __setscheduler_uclamp(struct task_struct *p,
const struct sched_attr *attr)
{
enum uclamp_id clamp_id;
/*
* On scheduling class change, reset to default clamps for tasks
* without a task-specific value.
*/
for_each_clamp_id(clamp_id) { (1)
struct uclamp_se *uc_se = &p->uclamp_req[clamp_id];
unsigned int clamp_value = uclamp_none(clamp_id);
/* Keep using defined clamps across class changes */
if (uc_se->user_defined)
continue;
/* By default, RT tasks always get 100% boost */
if (unlikely(rt_task(p) && clamp_id == UCLAMP_MIN))
clamp_value = uclamp_none(UCLAMP_MAX);
uclamp_se_set(uc_se, clamp_value, false);
}
if (likely(!(attr->sched_flags & SCHED_FLAG_UTIL_CLAMP)))
return;
if (attr->sched_flags & SCHED_FLAG_UTIL_CLAMP_MIN) { (2)
uclamp_se_set(&p->uclamp_req[UCLAMP_MIN],
attr->sched_util_min, true);
}
if (attr->sched_flags & SCHED_FLAG_UTIL_CLAMP_MAX) { (3)
uclamp_se_set(&p->uclamp_req[UCLAMP_MAX],
attr->sched_util_max, true);
}
}
__setscheduler_uclamp()函数提供了kernelspace和userspace设置task uclamp的方法。
(1) 设置task 默认的request se值,对RT,UCLAMP_MIN和UCLAMP_MAX 设置value=1024最大值,其它task设置UCLAMP_MIN value=0,UCLAMP_MAX value=1024.
(2) 根据attr参数中sched_flags=SCHED_FLAG_UTIL_CLAMP_MIN,设置task的request se的UCLAMP_MIN value值为attr::sched_util_min的值;
(3) 根据attr参数中sched_flags=SCHED_FLAG_UTIL_CLAMP_MAX,设置task的request se的UCLAMP_MAX value值为attr::sched_util_max的值;
4. uclamp_rq_inc_id()
static inline void uclamp_rq_inc_id(struct rq *rq, struct task_struct *p,
enum uclamp_id clamp_id)
{
struct uclamp_rq *uc_rq = &rq->uclamp[clamp_id];
struct uclamp_se *uc_se = &p->uclamp[clamp_id];
struct uclamp_bucket *bucket;
lockdep_assert_held(&rq->lock);
/* Update task effective clamp */
p->uclamp[clamp_id] = uclamp_eff_get(p, clamp_id); (1)
bucket = &uc_rq->bucket[uc_se->bucket_id]; (2)
bucket->tasks++;
uc_se->active = true;
uclamp_idle_reset(rq, clamp_id, uc_se->value); (3)
/*
* Local max aggregation: rq buckets always track the max
* "requested" clamp value of its RUNNABLE tasks.
*/
if (bucket->tasks == 1 || uc_se->value > bucket->value) (4)
bucket->value = uc_se->value;
if (uc_se->value > READ_ONCE(uc_rq->value)) (5)
WRITE_ONCE(uc_rq->value, uc_se->value);
}
enqueue_task()->uclamp_rq_inc()->uclamp_rq_inc_id() /*入队时规划task到rq bucket中 ,并更新uclamp_rq::value*/。
|cpu_cgrp_subsys::cpu_legacy_files::cpu_uclamp_min_write()/cpu_uclamp_max_write->cpu_uclamp_write()->| /*设置cgroup的uclamp*/
|sysctl_sched_uclamp_handler()->uclamp_update_root_tg()->| /*通过proc/sys/kernel/sched_util_clamp_min{max}设置root_task_group的uclamp*/
|->cpu_util_update_eff()->uclamp_update_active_tasks()->uclamp_update_active() ->uclamp_rq_inc_id()
(1) task::uclamp_req在受group和uclamp_default钳制后有效的request:
- 如果未配置CONFIG_UCLAMP_TASK_GROUP ,仅受uclamp_default钳制,
(2) 根据生效的uclam值规划task到对应的bucket(bucket->tasks++),设置task的生效uclamp::active=true。
(3) 通过UCLAMP_FLAG_IDLE判断rq是否是刚刚退出idle,如果刚刚退出idle,说明rq上当前只有这一个task,则设置rq::uclamp::value=task::uclamp:value
(4) 如果当前bucket只要当前一个task,或者当前task的task::uclamp:value>bucket::value,则更新bucket::value=task::uclamp::value,因为bucket::value始终是此bucket中所有task 生效clamp的最大值。
(5) 如果task::uclamp::value>rq::uclamp::value,则更新rq::uclamp::value,因为rq::uclamp::value始终代表rq上所有task uclamp的最大值。
5. uclamp_rq_dec_id()
static inline void uclamp_rq_dec_id(struct rq *rq, struct task_struct *p,
enum uclamp_id clamp_id)
{
struct uclamp_rq *uc_rq = &rq->uclamp[clamp_id];
struct uclamp_se *uc_se = &p->uclamp[clamp_id];
struct uclamp_bucket *bucket;
unsigned int bkt_clamp;
unsigned int rq_clamp;
lockdep_assert_held(&rq->lock);
bucket = &uc_rq->bucket[uc_se->bucket_id];
SCHED_WARN_ON(!bucket->tasks);
if (likely(bucket->tasks)) (1)
bucket->tasks--;
uc_se->active = false;
/*
* Keep "local max aggregation" simple and accept to (possibly)
* overboost some RUNNABLE tasks in the same bucket.
* The rq clamp bucket value is reset to its base value whenever
* there are no more RUNNABLE tasks refcounting it.
*/
if (likely(bucket->tasks)) (2)
return;
rq_clamp = READ_ONCE(uc_rq->value);
/*
* Defensive programming: this should never happen. If it happens,
* e.g. due to future modification, warn and fixup the expected value.
*/
SCHED_WARN_ON(bucket->value > rq_clamp); (3)
if (bucket->value >= rq_clamp) {
bkt_clamp = uclamp_rq_max_value(rq, clamp_id, uc_se->value);
WRITE_ONCE(uc_rq->value, bkt_clamp);
}
}
函数调用关系:
- dequeue_task()->uclamp_rq_dec()->uclamp_rq_dec_id()
/*把task从rq的bucket中解除规划*/ - |cpu_cgrp_subsys::cpu_legacy_files::cpu_uclamp_min_write()/cpu_uclamp_max_write->cpu_uclamp_write()->|
|sysctl_sched_uclamp_handler()->uclamp_update_root_tg()->|
|->cpu_util_update_eff()->uclamp_update_active_tasks()->uclamp_update_active()->uclamp_rq_dec_id()
(1) 从bucket中解除task的规划,并将task::uclamp::active=false,表示task没被规划到rq的bucket中。
(2) 如果从bucket中解除该task的规划后,bucket中还有其它task,直接返回。(此处没有更新bucket::value和rq::uclamp::value, comments中解释,简化更新同一个bucket的vaule值,对其它runnable task的over boot是可接受的。这种情况下,已经dequeue的task的uclamp对rq中的runnable taks的over boost影响,对功耗的影响尚待评估)。
(3) 对bucket::value>rq::uclamp::value极少出现的不正常的逻辑添加debug log,或者如果此时task对应的bucket::value=rq::rclamp::value, 更新rq::rclamp::value为当前buckets中的最大值(如果(2)中没更新bucket::value,此时bucket最大值仍可能是已经出队的task的task::uclamp::value,直到此bucket内没有task)。
6. uclamp_rq_util_with()
static __always_inline
unsigned long uclamp_rq_util_with(struct rq *rq, unsigned long util,
struct task_struct *p)
{
unsigned long min_util = READ_ONCE(rq->uclamp[UCLAMP_MIN].value);
unsigned long max_util = READ_ONCE(rq->uclamp[UCLAMP_MAX].value);
if (p) {
min_util = max(min_util, uclamp_eff_value(p, UCLAMP_MIN));
max_util = max(max_util, uclamp_eff_value(p, UCLAMP_MAX));
}
/*
* Since CPU's {min,max}_util clamps are MAX aggregated considering
* RUNNABLE tasks with _different_ clamps, we can end up with an
* inversion. Fix it now when the clamps are applied.
*/
if (unlikely(min_util >= max_util))
return min_util;
return clamp(util, min_util, max_util);
}函数调用关系:
|compute_energy()->|
|sugov_get_util()->|
|->schedutil_cpu_util()-> uclamp_rq_util_with()
此函数是uclamp和schedutil/energy的接口函数,通过此函数获得uclamp值。
7. 获取task有效的clamp值
kernel5.4/kernel/sched/core.c
unsigned long uclamp_eff_value(struct task_struct *p, enum uclamp_id clamp_id)
{
struct uclamp_se uc_eff;
/* Task currently refcounted: use back-annotated (effective) value */
if (p->uclamp[clamp_id].active) /*如果当前task已经被某个bucket引用,直接返回生效的uclam值*/
return (unsigned long)p->uclamp[clamp_id].value;
uc_eff = uclamp_eff_get(p, clamp_id); /*否则更新task的有效clamp值*/
return (unsigned long)uc_eff.value;
}
static inline struct uclamp_se
uclamp_eff_get(struct task_struct *p, enum uclamp_id clamp_id)
{
struct uclamp_se uc_req = uclamp_tg_restrict(p, clamp_id); /*更新group对task的clamp钳制*/
struct uclamp_se uc_max = uclamp_default[clamp_id];
/* System default restrictions always apply */
if (unlikely(uc_req.value > uc_max.value)) /*system(即root_task_group)的clamp总是生效*/
return uc_max;
return uc_req;
}
static inline struct uclamp_se
uclamp_tg_restrict(struct task_struct *p, enum uclamp_id clamp_id)
{
struct uclamp_se uc_req = p->uclamp_req[clamp_id];
#ifdef CONFIG_UCLAMP_TASK_GROUP
struct uclamp_se uc_max;
/*
* Tasks in autogroups or root task group will be
* restricted by system defaults.
*/
/*如果task在autogroup中或root_group中,则返回task的req,task的req会在uclamp_eff_get函数中受system clamp的钳制*/
if (task_group_is_autogroup(task_group(p)))
return uc_req;
if (task_group(p) == &root_task_group)
return uc_req;
uc_max = task_group(p)->uclamp[clamp_id];
/*如果task的req是非user_defined,直接返回group的uclamp;如果他说
的req是user_defined,则受group clamp的钳制*/
if (uc_req.value > uc_max.value || !uc_req.user_defined)
return uc_max;
#endif
return uc_req;
}
8. 修改group的clamp并update到group中的task
当向group暴露的系统节点echo值配置group的uclamp_min{max}时,在更新group clamp的同时,也更新group所属的tasks的clamp
/*dev/cpuctl/top-app/uclamp.min{max}写配置clamp值*/
static ssize_t cpu_uclamp_write(struct kernfs_open_file *of, char *buf,
size_t nbytes, loff_t off,
enum uclamp_id clamp_id)
{
struct uclamp_request req;
struct task_group *tg;
req = capacity_from_percent(buf); /*把buffer中"98.20"格式的百分数分别转化为percent="9820“,util=”1006”(98.20*1024),保存在uclamp_request中*/
if (req.ret)
return req.ret;
mutex_lock(&uclamp_mutex);
rcu_read_lock();
tg = css_tg(of_css(of));
if (tg->uclamp_req[clamp_id].value != req.util)
uclamp_se_set(&tg->uclamp_req[clamp_id], req.util, false); /*记录req util到group的uclamp_req.value*/
/*
* Because of not recoverable conversion rounding we keep track of the
* exact requested value
*/
tg->uclamp_pct[clamp_id] = req.percent; /*记录pct格式的req util到group的uclamp_pct*/
/* Update effective clamps to track the most restrictive value */
/*根据parent clamp限制更新group的clamp值,并应用到child group和其中的task*/
cpu_util_update_eff(of_css(of));
rcu_read_unlock();
mutex_unlock(&uclamp_mutex);
return nbytes;
}
static void cpu_util_update_eff(struct cgroup_subsys_state *css)
{
struct cgroup_subsys_state *top_css = css;
struct uclamp_se *uc_parent = NULL;
struct uclamp_se *uc_se = NULL;
unsigned int eff[UCLAMP_CNT];
enum uclamp_id clamp_id;
unsigned int clamps;
css_for_each_descendant_pre(css, top_css) { /*从当前css开始loop*/
uc_parent = css_tg(css)->parent
? css_tg(css)->parent->uclamp : NULL;
for_each_clamp_id(clamp_id) {
/* Assume effective clamps matches requested clamps */
eff[clamp_id] = css_tg(css)->uclamp_req[clamp_id].value;
/* Cap effective clamps with parent's effective clamps */
/*当前group的uclamp_req受parent的有效uclamp限制,限制后的的clamp记录在eff中*/
if (uc_parent &&
eff[clamp_id] > uc_parent[clamp_id].value) {
eff[clamp_id] = uc_parent[clamp_id].value;
}
}
/* Ensure protection is always capped by limit */
eff[UCLAMP_MIN] = min(eff[UCLAMP_MIN], eff[UCLAMP_MAX]);
/* Propagate most restrictive effective clamps */
clamps = 0x0;
uc_se = css_tg(css)->uclamp;
for_each_clamp_id(clamp_id) {
if (eff[clamp_id] == uc_se[clamp_id].value)
continue;
/*当前group的有效uclamp配置为eff*/
uc_se[clamp_id].value = eff[clamp_id];
uc_se[clamp_id].bucket_id = uclamp_bucket_id(eff[clamp_id]);
clamps |= (0x1 << clamp_id);
}
/*如果当前group的有效uclamp受:uclamp_req和父group的有效uclamp限制后没发生变化,则不对group所属的task uclamp进行更新,loop下一个子group*/
if (!clamps) {
css = css_rightmost_descendant(css);
continue;
}
/* Immediately update descendants RUNNABLE tasks */
/*如果当前group的有效uclamp发生了变化,则更新其中的所有task的有效clamp,task的bucket引用,更新rq的有效clamp*/
uclamp_update_active_tasks(css, clamps);
}
}
static inline void
uclamp_update_active_tasks(struct cgroup_subsys_state *css,
unsigned int clamps)
{
enum uclamp_id clamp_id;
struct css_task_iter it;
struct task_struct *p;
css_task_iter_start(css, 0, &it);
while ((p = css_task_iter_next(&it))) {
for_each_clamp_id(clamp_id) {
if ((0x1 << clamp_id) & clamps)
/*哪个clmap_id的uclamp发生了变化,则更新哪个clamp_id的clamp*/
uclamp_update_active(p, clamp_id);
}
}
css_task_iter_end(&it);
}
static inline void
uclamp_update_active(struct task_struct *p, enum uclamp_id clamp_id)
{
struct rq_flags rf;
struct rq *rq;
/*
* Lock the task and the rq where the task is (or was) queued.
*
* We might lock the (previous) rq of a !RUNNABLE task, but that's the
* price to pay to safely serialize util_{min,max} updates with
* enqueues, dequeues and migration operations.
* This is the same locking schema used by __set_cpus_allowed_ptr().
*/
rq = task_rq_lock(p, &rf);
/*
* Setting the clamp bucket is serialized by task_rq_lock().
* If the task is not yet RUNNABLE and its task_struct is not
* affecting a valid clamp bucket, the next time it's enqueued,
* it will already see the updated clamp bucket value.
*/
/*通过task 在buckekt中解引用和引用,更新task clamp的*/
if (p->uclamp[clamp_id].active) {
uclamp_rq_dec_id(rq, p, clamp_id);
uclamp_rq_inc_id(rq, p, clamp_id);
}
task_rq_unlock(rq, p, &rf);
}
9. sysctl接口
sysctl提供了/proc/sys/kernel/sched_uclamp_util_{min,max}接口,定义了系统默认的clamp范围,无条件限制所有task。
三. 参考资料
-
Patrick Bellasi's kernel:
http://www.linux-arm.org/git?p=linux-pb.git;a=summary
http://www.linux-arm.org/git?p=linux-pb.git;a=shortlog;h=refs/heads/lkml/utilclamp_v10 -
uclamp前生之SchedTune:http://retis.sssup.it/~luca/ospm-summit/2017/Downloads/OSPM_SchedTune.pdf
-
patch list:
base patch list:
af24bde sched/uclamp: Add uclamp support to energy_compute()
schedutil_cpu_util()在task placement和cpu调频计算cpu frequency时调用。
在EAS路径task placement时,加入了clamp util的影响。在compute_energy->schedutil_cpu_util(FREQUENCY_UTIL)->uclamp_rq_util_with(rq, util, p)中。compute_energy()在计算cpu的energy时,需要计算pd中所有cpu的energy util的和,以及pd中所有cpu frequency util的最大值,cpu的clamp util在计算pd frequency时生效。uclamp_rq_util_with()函数是uclamp在调度中使用的对外接口函数。
在 cpu调频通过schedutil_cpu_util()计算cpu频点时,对cfs和rt调度类加入clamp util的影响。
9d20ad7 sched/uclamp: Add uclamp_util_with()
修改前,uclamp_util()只是取rq上的rq->uclamp[].value,
修改后,cpu 的util考虑了将要调度到cpu上执行的task的 clamp util的影响;
982d9cd sched/cpufreq, sched/uclamp: Add clamps for FAIR and RT tasks
引入fair_sched_class.uclamp_enabled和rt_sched_class..uclamp_enabled,使能cfs和rt的uclamp
cpu上的上限{下限}值因为取自所有cpu上clamp task 上限{下限}值的最大值,存在上限值<下限值的情况,此时取cpu的max(上限值, 下限值)作为cpu的clamp util。
1a00d99 sched/uclamp: Set default clamps for RT tasks
设置RT task的默认clamp值:设置新fork的RT task的下限为1024,即100% boost;task的调度类通过__setscheduler_uclamp变为RT class,且userspace没有设置clamp值,则设置RT task的下限为1024,即100%bosot。(CFS task的默认clamp值是{0,1024},即不做clamp)
a87498a sched/uclamp: Reset uclamp values on RESET_ON_FORK
新fork的task如果父进程设置了sched_reset_on_fork,则fork的task需要设置default值:p->uclamp_req[clamp_id].value={0,1024}, user_defined=false
a509a7c sched/uclamp: Extend sched_setattr() to support utilization clamping
引入uclamp_se.user_defined,表示这是一个从userspace指定的clamp value
扩展sched_setattr,增加sched_attr{sched_util_min,sched_util_max}子集, sched_setattr->__sched_setscheduler->__setscheduler_uclamp通过系统调用设置task的uclamp。通过系统调用设置task的【sched_util_min】和【sched_util_max】,可以针对task特性影响task的placement和频点的选择。这两个值代表了分配给task的cpu带宽范围,比如sched_util_min=20%,表示task在大核最高频运行的时间配额最小是20%。如果大核最高频对应的capacity是1024,则task需要的最小util是1024*20%=204.8。
1d6362f sched/core: Allow sched_setattr() to use the current policy
扩展sched_setattr,引入SCHED_FLAG_KEEP_POLICY SCHED_FLAG,支持保持task policy的属性设置。通过此系统调用设置userspace指定给task的clamp。
e8f1417 sched/uclamp: Add system default clamps
引入/proc/sys/kernel/sched_uclamp_util_{min,max},配置系统对所有task的钳位值,默认不配置是{0,1024}
引入uclamp_se.active成员,表示task的uclamp_se.value生效了,即task被计数到对应的bucket中
引入task_struct{uclamp_req},表示从userspace设置的clamp值
e496187 sched/uclamp: Enforce last task's UCLAMP_MAX
当rq上最后一个taks A 在ts0 出队sleep,会移除cpu对task A util上限的钳位,idle cpu load以task A blocked util计算(PELT衰减,不再受上限钳位)。如果此时同cluster的其它cpu发起了freq update,那么计算得到的task A (not clamped and blocked) util可能会大于其running时受上限钳位的util,这种情况会造成cpu ilde后频率增加的问题。
通过定义UCLAMP_FLAG_IDLE记录cpu的idle状态,cpu在idle状态时,上限钳位不更新为默认的1024,而是更新为最后一个出队的task A的上限钳位值。task A的贡献给cpu的blocked util随着时间decay,会在ts1降到上限钳位值之下 ,在ts0和ts1间cpu频率受task A上限钳位值的影响,ts1之后则受task A实际的blocked util影响。
60daf9c sched/uclamp: Add bucket local max tracking
rq上的uclamp_rq.bucket.value被初始化为每个bucket的base值,当task入队时,如果task的钳位值【p->uclamp[clamp_id].value】大于rq的钳位值【rq->uclamp[clamp_id].value】,则把rq的钳位值更新为bucket的钳位值【rq->uclamp[clamp_id].value= rq->uclamp[clamp_id]->bucket[uc_se->bucket_id]】,即floor aggregation。这种情况会造成钳位后得到的rq钳位值【rq->uclamp[clamp_id].value】呈现柱状图样。bucket数越小,误差越大,需要更多的bucket数来提高不同task钳位值最终floor aggregation的精度。
修改后,bucket value取bucket中所有task value的最大值。如果task入队时,task的钳位值大于rq的钳位值,则把rq的钳位值更新为task的钳位值。此时每个bucket的value在有task refcounted时更新,不需要在初始化为每个bucket的base值。如果task需要钳位的值的数量有限,可以根据钳位值分布减小bucket数。
69842cb sched/uclamp: Add CPU's clamp buckets refcounting
android5.4 patch list:
15d93f6 UPSTREAM: sched/fair: Make EAS wakeup placement consider uclamp restrictions
d5c2a09 UPSTREAM: sched/fair: Make task_fits_capacity() consider uclamp restrictions
1356a58 UPSTREAM: sched/uclamp: Rename uclamp_util_with() into uclamp_rq_util_with()
fedb670 UPSTREAM: sched/uclamp: Make uclamp util helpers use and return UL values
6966eb9 BACKPORT: sched/uclamp: Remove uclamp_util()
1473e20 Revert "ANDROID: sched/fair: EAS: Add uclamp support to find_energy_efficient_cpu()"
c598c8a sched/uclamp: Fix overzealous type replacement
6e1ff07 sched/uclamp: Fix incorrect condition
0e00b6f ANDROID: sched: Introduce uclamp latency and boost wrapper
c28f9d3 ANDROID: sched/core: Add a latency-sensitive flag to uclamp
b61876e ANDROID: sched/fair: EAS: Add uclamp support to find_energy_efficient_cpu()
1251201 sched/core: Fix uclamp ABI bug, clean up and robustify sched_read_attr() ABI logic and code
0413d7f sched/uclamp: Always use 'enum uclamp_id' for clamp_id values
babbe17 sched/uclamp: Update CPU's refcount on TG's clamp changes
3eac870 sched/uclamp: Use TG's clamps to restrict TASK's clamps
7274a5c sched/uclamp: Propagate system defaults to the root group
0b60ba2dd3 sched/uclamp: Propagate parent clamps
2480c09 sched/uclamp: Extend CPU's cgroup controller
添加对task group的支持。
cgroup CPU bandwidth controller的缺点:只给gourp中的tasks分配了基于当前基线的带宽,并没考虑到cpu frequency和大小核的不同对cpu算力的影响。
引入了task_group。root rode不支持task group,所以dev/cpuctl/的root rode没有task group相关设置接口。root group中的tasks受/proc/sys/kernel/sched_uclamp_util_{min,max}接口的systemd wide clamp限制。子task group clamp设置有效的最大值小于parent group生效的clamp值。task group clamp的优先级,高于通过sched_setatt()系统调用从userspace指定task clamp的优先级。在uclam初始化init_uclamp(void)时,初始化root_task_group.uclamp_req[clamp_id] = uc_max,root_task_group.uclamp[clamp_id] = uc_max,表示上限及下限设置的范围都是0~1024。当向task group节点uclamp_min{max}配置uclamp、向system节点proc/sys/kernel/sched_uclamp_util_min{max}配置root group uclamp时,调用cpu_util_update_eff更新各子group的effective clamps及group中task的effective clamps。
uclamp task group hierarchy关系图如下: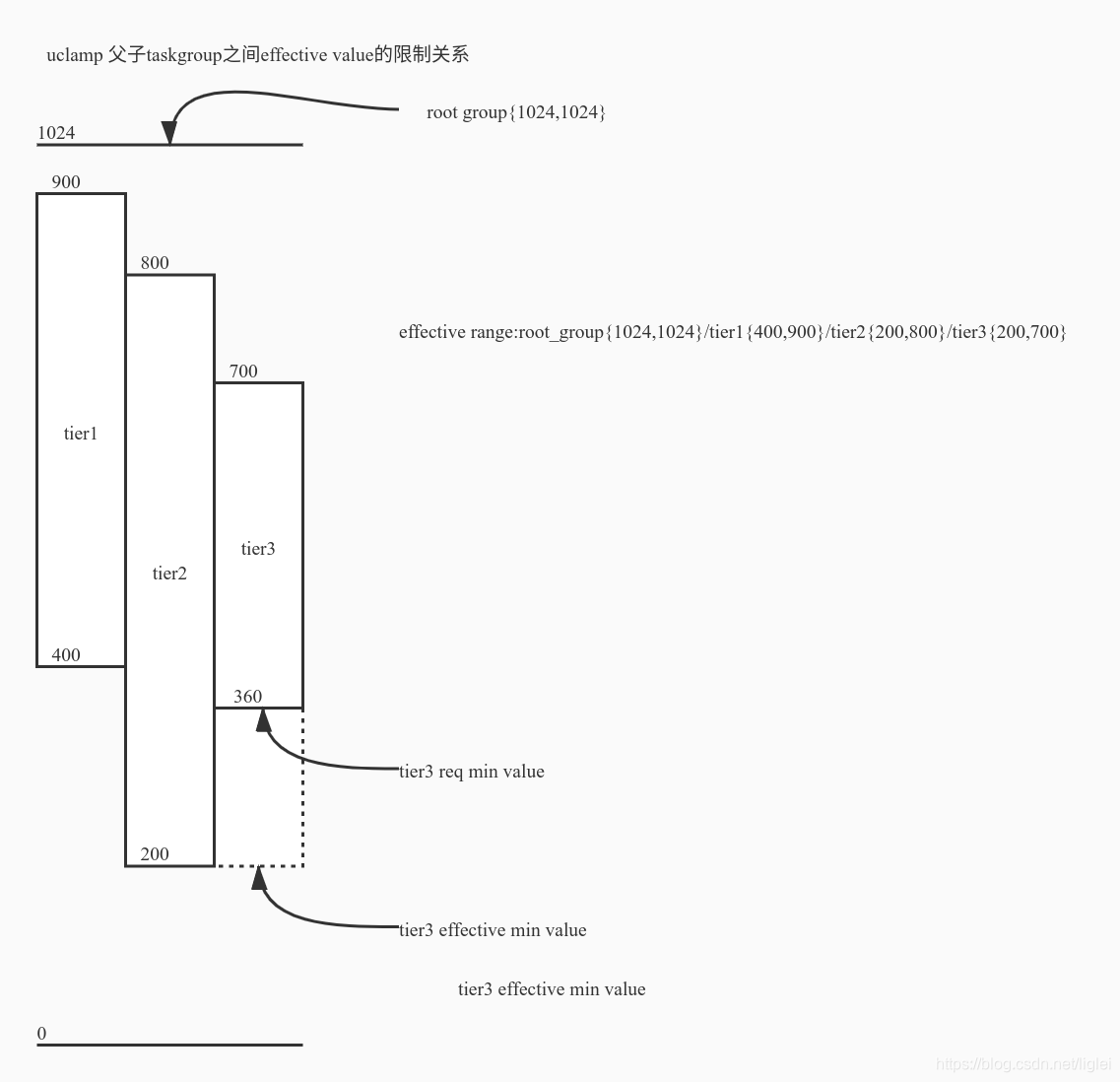
sched/uclamp: Add a new sysctl to control RT default boost value v1 [PATCH] sched/rt: Add a new sysctl to control uclamp_util_min - Qais Yousef v2 [PATCH 1/2] sched/uclamp: Add a new sysctl to control RT default boost value - Qais Yousef v3 https://lore.kernel.org/lkml/20200428164134.5588-1-qais.yousef@arm.com/ v4 https://lore.kernel.org/lkml/20200501114927.15248-1-qais.yousef@arm.com/ v5 https://lore.kernel.org/lkml/20200511154053.7822-1-qais.yousef@arm.com/ v6 [PATCH v6 0/2] sched/uclamp: new sysctl for default RT boost value - Qais Yousef v7 https://lore.kernel.org/lkml/20200716110347.19553-2-qais.yousef@arm.com/ final [tip: sched/core] sched/uclamp: Add a new sysctl to control RT default boost value - tip-bot2 for Qais Yousef

















 9801
9801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









