









冒泡排序
从小到大排序,比如有5个,先把五个里最小的移到最左边0位置。再把剩下的四个最小的移到1位置......
标准的做法是:与相邻的元素比较交换,如果一趟冒泡没有交换,说明顺序已经成型 ,不必再循环 break
| i | 0→ | 1→ | 2→ | 3→ | 4→ | 5→ | 6 |
| j | 0 | ←1 | ←2 | ←3 | ←4 | ←5 | ←6 |
void bubble_sort(int a[],int n)
{
int i,j;
for(i = 0;i < n-1; i++)
{
bool exchange = false;
for(j = n-1;j > i; j--)
{
if(a[j-1] > a[j])
{
exchange = true;
swap(a[j-1], a[j]);
}
}
if(exchange == false)
break;
}
} 选择排序
记住最小值的下标,最后再与最前面的交换
void select_sort1(int a[],int n)
{
int i,j;
for(i = 0; i < n-1; i++)
{
int min = i;
for(j = i+1; j < n; j++)
{
if(a[j] < a[min])
min = j;
}
if(min != i)
swap(a[i], a[min]);
}
}快速排序
快速排序由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
在c++中可以用函数qsort()可以直接为数组进行排序。
用 法:
void qsort(void *base, int nelem, int width, int (*fcmp)(const void *,const void *));
参数:
1 待排序数组首地址
2 数组中待排序元素数量
3 各元素的占用空间大小
4 指向函数的指针,用于确定排序的顺序

逻辑原理:
a[0] = a[3]; a[2] = a[3]; a[2] = key
#include <iostream>
using namespace std;
void Qsort(int a[], int low, int high)
{
if(low >= high)
{
return;
}
int first = low;
int last = high;
int key = a[first];/*用字表的第一个记录作为枢轴*/
while(first < last)
{
while(first < last && a[last] >= key)
{
--last;
}
a[first] = a[last];/*将比第一个小的移到低端*/
while(first < last && a[first] <= key)
{
++first;
}
a[last] = a[first];
/*将比第一个大的移到高端*/
}
a[first] = key;/*枢轴记录到位*/
Qsort(a, low, first-1);
Qsort(a, first+1, high);
}
int main()
{
int a[] = {57, 68, 59, 52, 72, 28, 96, 33, 24};
Qsort(a, 0, sizeof(a) / sizeof(a[0]) - 1);/*这里原文第三个参数要减1否则内存越界*/
for(int i = 0; i < sizeof(a) / sizeof(a[0]); i++)
{
cout << a[i] << "";
}
return 0;
}/*参考数据结构p274(清华大学出版社,严蔚敏)*/插入排序
将无序数组,插入到另外一个有序数组之中
适合于:
①数据量<1000
②数组基本有序
复杂度分析
● 插入排序的时间复杂度 就是判断比较次数有多少,而比较次数与 待排数组的初始顺序有关。 最好情况下,排序前对象已经按照要求的有序。比较次数(n−1) ; 移动次数(0)次。则对应的时间复杂度为O(n)。
● 最坏情况是数组逆序排序,第 i 趟时第 i 个对象必须与前面 i 个对象都做排序码比较,并且每做1次比较就要做1次数据移动,此时需要进行 (n +2)*(n-1) / 2次比较; 而记录的移动次数也达到最大值 (n+4)*(n-1)/2 次。 则对应的时间复杂度为
直接插入排序采用就地排序,空间复杂度为O(1).
一、直接插入排序
void sort(int *a,int n)
{
for(int i=1;i<n;i++)
{
int j=i-1,k=a[i];
while(j>=0 && a[j]>k)
{
a[j+1]=a[j];
j--;
}
a[j+1]=k;
}
}
二、递归插入排序
void sort(int x[],int n)
{
if(n==2)
{//递归终止条件。当数组中只有两个元素时,对这两个元素进行排序
if(x[0]>x[1])
{
int tmp=x[0];
x[0]=x[1];
x[1]=tmp;
}
}
else if(n==1)//如果数组中只有一个元素,就不用排序
return;
else
{
sort(x,n-1);
int i=n-1;
while((x[i]<x[i-1])&&(i>0))
{
int temp=x[i];
x[i]=x[i-1];
x[i-1]=temp;
i=i-1;
}
}
}
堆排序
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。如下图:
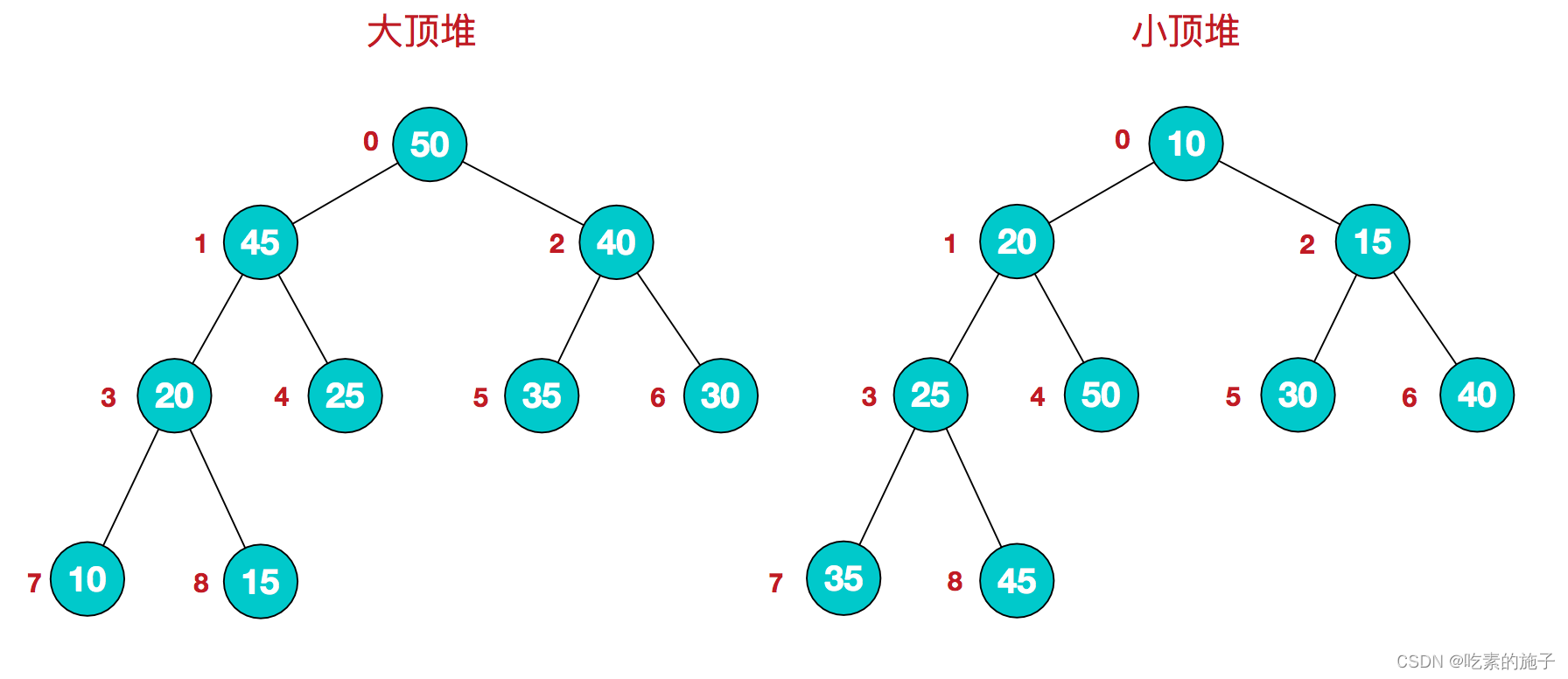
同时,我们对堆中的结点按层进行编号,将这种逻辑结构映射到数组中就是下面这个样子

该数组从逻辑上讲就是一个堆结构,我们用简单的公式来描述一下堆的定义就是:
大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]

算法分析:
(1)根据初始数组去构造初始堆(构建一个完全二叉树,保证所有的父结点都比它的孩子结点数值大)。
(2)每次交换第一个和最后一个元素,输出最后一个元素(最大值),然后把剩下元素重新调整为大根堆。
// 只是找到当前数据节点的位置(让当前根节点都比自己的两个孩子大)
void heap_siftdown(int a[],int n,int p) //调整算法
{
int i = p,j = i*2+1; //j是i的左子节点
int tmp = a[i]; //tmp是临时变量
while(j < n) //适用于多层树
{
if(j+1 < n && a[j] < a[j+1])
j++;
if(a[j] <= tmp) //如果当前根比两个孩子都大了,则break,tmp是虚拟的当前节点
break;
else
{
a[i] = a[j]; //将大孩子给当前根
i = j;j = j*2+1;
}
}
a[i] = tmp; //只为省写几行代码
}
void heap_sort1(int a[],int n)
{
int i;
for(i = (n-1)/2; i >= 0;i--) //(n-1)/2最右边有子孩子那个节点
heap_siftdown(a, n, i);
for(i = n-1;i >= 0; i--) //每一次将最大的换到末尾,再重排前面的剩下的
{
swap(a[i], a[0]);
heap_siftdown(a, i, 0); //自顶向下重排
}
}o(1), o(n), o(logn), o(nlogn) 时间复杂度介绍
在描述算法复杂度时,经常用到o(1), o(n), o(logn), o(nlogn)来表示对应算法的时间复杂度, 这里进行归纳一下它们代表的含义:
这是算法的时空复杂度的表示。不仅仅用于表示时间复杂度,也用于表示空间复杂度。
O后面的括号中有一个函数,指明某个算法的耗时/耗空间与数据增长量之间的关系。其中的n代表输入数据的量。
时间复杂度为O(n),就代表数据量增大几倍,耗时也增大几倍。比如常见的遍历算法。
时间复杂度O(n^2),就代表数据量增大n倍时,耗时增大n的平方倍,这是比线性更高的时间复杂度。比如冒泡排序,就是典型的O(n^2)的算法,对n个数排序,需要扫描n×n次。
O(logn),当数据增大n倍时,耗时增大logn倍(这里的log是以2为底的,比如,当数据增大256倍时,耗时只增大8倍,是比线性还要低的时间复杂度)。二分查找就是O(logn)的算法,每找一次排除一半的可能,256个数据中查找只要找8次就可以找到目标。
O(nlogn)同理,就是n乘以logn,当数据增大256倍时,耗时增大256*8=2048倍。这个复杂度高于线性低于平方。归并排序(快速排序也是)就是O(nlogn)的时间复杂度。
O(1)就是最低的时空复杂度了,也就是耗时/耗空间与输入数据大小无关,无论输入数据增大多少倍,耗时/耗空间都不变。 哈希算法就是典型的O(1)时间复杂度,无论数据规模多大,都可以在一次计算后找到目标(不考虑冲突的话)冲突的话很麻烦的,指向的value会做二次hash到另外一快存储区域
总之,
在平均情况下,快速排序最快;
在最好情况下,插入排序和冒泡排序最快;
在最坏情况下,堆排序和归并排序最快。
红黑树构建:O(nlogn)
插入:O(logn)















 1152
1152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









