






linux安装prometheus
一、什么是Prometheus
Prometheus(普罗米修斯)是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。
2012年成为社区开源项目,拥有非常活跃的开发人员和用户社区。
2016年由Google发起Linux基金会旗下的原生云基金会(Cloud Native Computing Foundation), 将Prometheus纳入其下第二大开源项目。
Prometheus目前在开源社区相当活跃。
Prometheus和Heapster(Heapster是K8S的一个子项目,用于获取集群的性能数据。)相比功能更完善、更全面。Prometheus性能也足够支撑上万台规模的集群。
二、Prometheus的特点
- 多维度数据模型。
- 灵活的查询语言。
- 不依赖分布式存储,单个服务器节点是自主的。
- 通过基于HTTP的pull方式采集时序数据。
- 可以通过中间网关进行时序列数据推送。
- 通过服务发现或者静态配置来发现目标服务对象。
- 支持多种多样的图表和界面展示,比如Grafana等。### 创建log文件
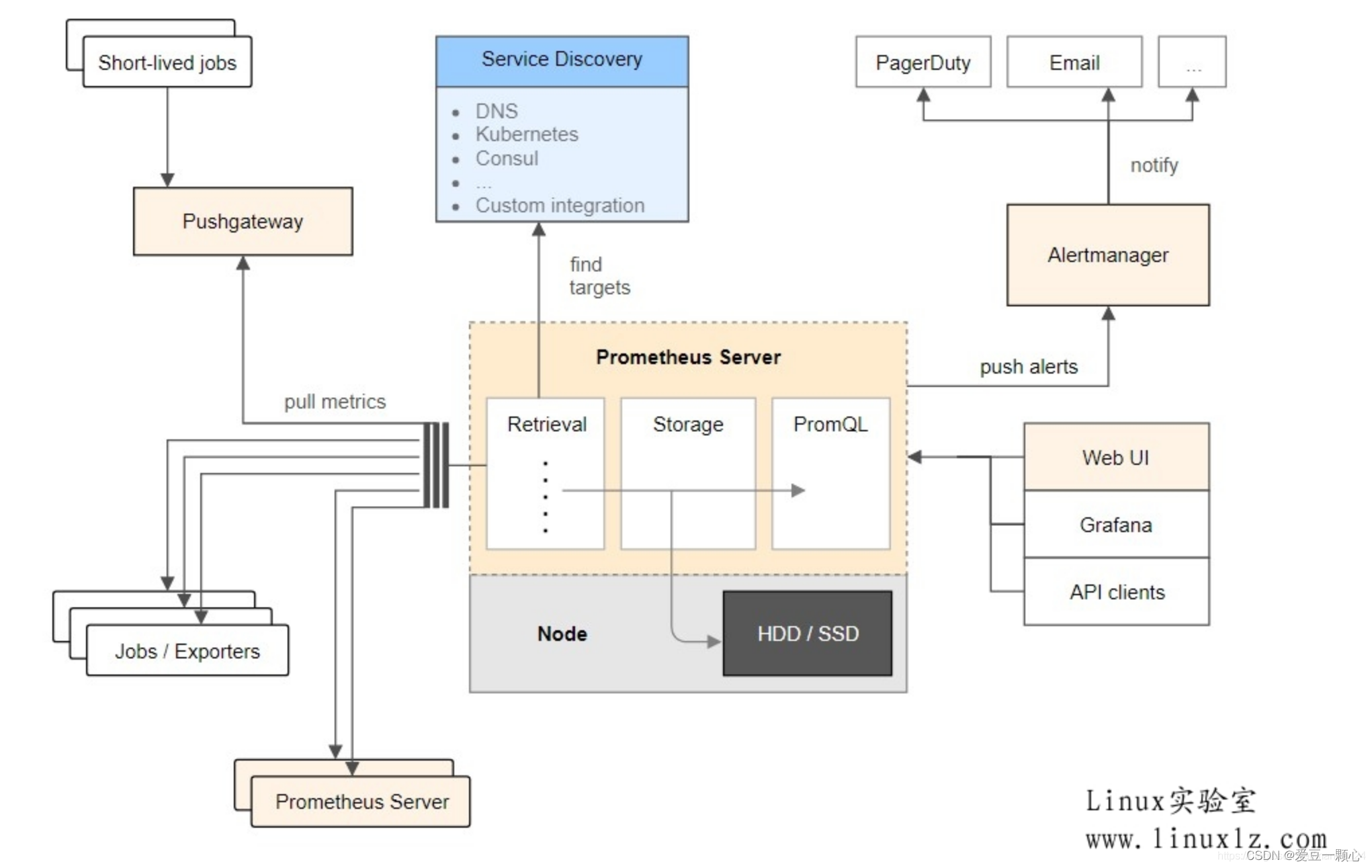
三、 基本原理
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
四、服务过程
- Prometheus Daemon负责定时去目标上抓取metrics(指标)数据,每个抓取目标需要暴露一个http服务的接口给它定时抓取。Prometheus支持通过配置文件、文本文件、Zookeeper、Consul、DNS SRV Lookup等方式指定抓取目标。Prometheus采用PULL的方式进行监控,即服务器可以直接通过目标PULL数据或者间接地通过中间网关来Push数据。
- Prometheus在本地存储抓取的所有数据,并通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中。
- Prometheus通过PromQL和其他API可视化地展示收集的数据。
- Prometheus支持很多方式的图表可视化,例如Grafana、自带的Promdash以及自身提供的模版引擎等等。Prometheus还提供HTTP API的查询方式,自定义所需要的输出。
- PushGateway支持Client主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
- Alertmanager是独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式。
五、三大套件
- Server 主要负责数据采集和存储,提供PromQL查询语言的支持。
- Alertmanager 警告管理器,用来进行报警。
- Push Gateway 支持临时性Job主动推送指标的中间网关。
六、下载Prometheus
1、官网下载地址:https://prometheus.io/download/
2、直接在linux服务器上wget方式下载
// 新建目录
mkdir -p /data/prometheus/
// 进入目标目录
cd /data/prometheus/
// 下载
wget -c https://github.com/prometheus/prometheus/releases/download/v2.28.1/prometheus-2.28.1.linux-amd64.tar.gz
// 解压
tar -vxzf prometheus-2.28.1.linux-amd64.tar.gz
// 移动到安装目录
mv prometheus-2.28.1.linux-amd64 /usr/local/prometheus
// 进入目录
cd /usr/local/prometheus
七、将Prometheus配置为系统服务
1、进入systemd目录
cd /usr/lib/systemd/system
2、创建文件
vim prometheus.service
# 添加如下内容
[Unit]
Description=https://prometheus.io
[Service]
Restart=on-failure
ExecStart=/root/prometheus/prometheus --config.file=/root/prometheus/prometheus.yml
[Install]
WantedBy=multi-user.target
3、生效系统文件
systemctl daemon-reload
4、启动服务停止服务
# 启动
systemctl start prometheus.service
# 停止
systemctl stop prometheus.service
八、启动Prometheus
# 进入解压后的文件夹
cd /data/prometheus/prometheus-2.28.1.linux-amd64
# 前台启动
./prometheus --config.file=prometheus.yml
# 后台启动prometheus,并且重定向输入日志到当前目录的prometheus.out
nohup ./prometheus --config.file=prometheus.yml >> /data/prometheus/prometheus-2.28.1.linux-amd64/prometheus.out 2>&1 &
//Mark 修改端口
./prometheus --config.file=prometheus.yml --web.listen-address=:9091
九、访问prometheus
http:192.168.0.102:9090,默认端口为 9090
![请添加图![
# 此片段指定的是prometheus的全局配置,比如采集间隔,抓取超时时间等。如果有内部单独设定,会覆盖这个参数。
global:
scrape_interval: 15s # 抓取间隔,默认继承global值(默认15s 全局每次数据收集的间隔)
evaluation_interval: 15s # 评估规则间隔(规则扫描时间间隔是15秒,默认不填写是1分钟)
# scrape_timeout 抓取超时时间,默认继承global值。
# 此片段指定告警配置,这里会设定alertmanager这个报警插件。
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']
# 此片段指定报警规则文件,按照设定参数进行扫描加载,用于自定义报警规则,其报警媒介和route路由由alertmanager插件实现。
rule_files:
- "rules/*.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# 此片段指定抓取配置。配置数据源,包含分组job_name以及具体target。又分为静态配置和服务发现。
scrape_configs:
- job_name: 'prometheus'
# metrics_path defaults to '/metrics' # 监控项访问的url路径
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090'] # 监控目标访问地址
- job_name: 'suyuan' # 任务目标名,可以理解成分组,每个分组包含具体的target组员。
scrape_interval: 30s # 这里如果单独设定的话,会覆盖global设定的参数,拉取时间间隔为30s
static_configs:
- targets: ['39.99.254.135:30101']
labels:
instance: 'bigdata(39.99.254.135:9000)'
- targets: ['39.99.254.135:30102']
labels:
instance: 'web(39.99.254.135:9999)'
- targets: ['39.99.254.135:30103']
labels:
instance: 'user(39.99.254.135:9003)'
告警配置 targets 和抓取配置 targets 的 localhost 最好替换成服务器的 ip,job_name 的名字对应的就是 grafana dashboard 的 job 的名称,instance 如果不通过 labels 单独指定,默认取的是 targets 的值,建议单独指定别名。
上述为静态规则,没有设置自动发现。这种情况下增加主机需要自行修改规则,通过 supervisor reload 对应任务,也是缺点:每次静态规则添加都要重启prometheus服务,不利于运维自动化。
prometheus支持服务发现(也是运维最佳实践经常采用的):
文件服务发现
基于文件的服务发现方式不需要依赖其他平台与第三方服务,用户只需将 要新的target信息以yaml或json文件格式添加到target文件中 ,prometheus会定期从指定文件中读取target信息并更新
好处:
(1)不需要一个一个的手工去添加到主配置文件,只需要提交到要加载目录里边的json或yaml文件就可以了;
(2)方便维护,且不需要每次都重启prometheus服务端。
配置更新
在更新完Prometheus的配置文件后,我们需要更新我们的配置到程序内存里,这里的更新方式有两种,第一种简单粗暴,就是重启Prometheus,第二种是动态更新的方式。如何实现动态的更新Prometheus配置。
步骤
第一步:首先要保证启动Prometheus的时候带上启动参数:–web.enable-lifecycle。
prometheus --config.file=/usr/local/etc/prometheus.yml --web.enable-lifecycle
第二步:去更新我们的Prometheus配置。
第三步:更新完配置后,我们可以通过POS请求的方式,动态更新配置。
curl -v --request POST 'http://localhost:9090/-/reload'
原理
Prometheus在web模块中,注册了一个handler。
if o.EnableLifecycle {
router.Post("/-/quit", h.quit)
router.Put("/-/quit", h.quit)
router.Post("/-/reload", h.reload) // reload配置
router.Put("/-/reload", h.reload)
}
通过h.reload这个handler方法实现:这个handler就是往一个channle中发送一个信号。
func (h *Handler) reload(w http.ResponseWriter, r *http.Request) {
rc := make(chan error)
h.reloadCh <- rc // 发送一个信号到channe了中
if err := <-rc; err != nil {
http.Error(w, fmt.Sprintf("failed to reload config: %s", err), http.StatusInternalServerError)
}
}
在main函数中会去监听这个channel,只要有监听到信号,就会做配置的reload,重新将新配置加载到内存中。
case rc := <-webHandler.Reload():
if err := reloadConfig(cfg.configFile, cfg.enableExpandExternalLabels, cfg.tsdb.EnableExemplarStorage, logger, noStepSubqueryInterval, reloaders...); err != nil {
level.Error(logger).Log("msg", "Error reloading config", "err", err)
rc <- err
} else {
rc <- nil
}















 1300
1300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









