







TensorFlow架构简介
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。它灵活的架构让可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究。
计算速度较快但是较麻烦,会话在c++中进行.
TensorFlow 1.0与2.0之间存在着区别。
mnist手写数据及简介
- 数据集由60000个训练样本和10000个测试样本组成
- 每个样本都是一张28 * 28像素的灰度手写数字图片
- 每个像素点是一个0-255的整数
- 训练集样本:用在对模型的训练中,使得模型对于数据的识别有自己的一套标准,从而可以对测试集的样本进行测试识别。
-测试集样本:对训练集所训练出来的模型进行测试,看模型是否合格。
第一部分—数据的读取
from tensorflow.examples.tutorials.mnist.input_data import read_data_sets
mnist= read_data_sets('./MNIST_data',one_hot=True) # one_hot读取数据时指定编码形式为one_hot(独热编码),one-hot编码是一种稀疏向量,一个向量中只有一个数为1,其他为0
在数据读取时,如果本地没有下载该数据,则计算机会自动联网下载,但由于是在Google上下载,很有可能会发生错误。
print(mnist.train.images[0].shape)
>>(784,) #每一张图片形状为784行的像素,则输入的神经元的个数为784
图片的可视化
import matplotlib.pyplot as plt
plt.imshow(mnist.train.images[0].reshape(28,28),cmap='gray')
plt.show()
知识点补充:
imshow()接收一张图像,只是画出该图,并不会立刻显示出来。
imshow后还可以进行其他draw操作,比如scatter散点等。
所有画完后使用plt.show()才能进行结果的显示。在这里,就将原来为784行的图片数据转换为了28*28的图片,并且呈灰色显示出来。
cmap=“gray” 对图片进行灰度处理,可以提高计算机计算的速率。
第二部分 定义计算图
定义神经元的输入 输出个数
input_size = 784
output_size = 10
定义模型的输入 输出
x = tf.placeholder(tf.float32,[None,input_size])#None 不知道输入多少个数据 使用一个占位符来定位
y = tf.placeholder(tf.float32,[None,output_size])
需要注意数据类型得相同,否则无法进行计算。
定义权重矩阵和阈值:Variable(变量)
w = tf.Variable(tf.random_normal(shape=(input_size,output_size),dtype=tf.float32)) #权重矩阵784*10 需要设置初始值
bias = tf.Variable(tf.zeros(output_size,dtype=tf.float32)) #阈值 长度为10
定义模型
y_predict=tf.nn.softmax(tf.matmul(x,w)-bias)
这是一个最简单的神经网络,只包含一层输入/出层和以层隐藏层。
定义损失函数
预测结果和真实结果之间的评价,常用的方法是交叉熵评估法。
loss=tf.reduce_mean(
-tf.reduce_sum(y * tf.log(y_predict),axis=1)
)# 按照行求和
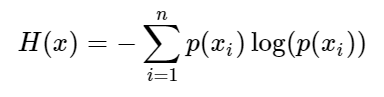
定义优化器
使得损失函数最小,常见的方法是梯度下降法和自适应法。
梯度方向是函数最大偏导数的方向,因此沿着与该方向相反的方向,必然可以达到函数的一个极小值点。
opt=tf.train.GradientDescentOptimizer(learning_rate=1)
其中learning_rate为学习速率,会影响损失函数的结果。
定义训练节点
定义优化器来使得损失函数最小
train_op = opt.minimize(loss)
第三部分 执行计算
启动会话
sess = tf.Session()
全局变量初始化
sess.run(tf.global_variables_initializer())
训练模型
由于训练集中的图片数据较多,则批处理的上传数据到模型中训练。
iter = 5001
all_cost = [] #记录损失函数 (理论上随着函数的训练,损失值应该是越来越小,稳定在相对稳定的一个值上面)
for i in range(iter):
x_batch,y_batch = mnist.train.next_batch(100) #批处理:分批次传入数据进行训练
t,cost = sess.run([train_op,loss],feed_dict={x:x_batch,y:y_batch})
all_cost.append(cost)
#定期打印结果
if i%100 == 0: #如果i 可以被100整除
print(f"第{i}次训练".center(50,'='))
print(f'损失值为:{cost}')
训练完毕后,绘制折线图,展示训练过程中损失值的变化情况,大概判断模型的好坏。
plt.plot(range(iter) ,all_cost)
plt.xlabel('Times') #训练次数
plt.ylabel('Loss') #损失值展示
plt.show()
模型测试
y_pre = sess.run(y_predict,feed_dict={x:mnist.test.images})
y_pre_labels = np.argmax(y_pre,axis=1) #返回最大值所在的下标,按照行取出
判断模型的正确率
y_real_labels = np.argmax(mnist.test.labels,axis=1)
print("最后一张图片的值为:",plt.imshow(mnist.test.images[9999].reshape(28,28),cmap='gray'))
print("模型预测的正确率:",(np.sum(y_real_labels == y_pre_labels)/10000)*100,'%')#如果相同的话则证明预测结果和真实结果相同
最后记得关闭会话哦!
sess.close()
完整代码
# 1 数据读取
from tensorflow.examples.tutorials.mnist.input_data import read_data_sets
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
mnist= read_data_sets('./MNIST_data',one_hot=True) #如果没有下载数据则会自己下载
# mnist.train.images.shape 训练集的数据
# mnist.train.labels.shape
# mnist.test.images.shape 测试集数据
#图片可视化
# plt.imshow(mnist.train.images[0].reshape(28,28),cmap='gray')
# plt.show()
# print(np.argmax(mnist.train.labels[0]))
#2 定义计算图
#2.1定义Tensor:y=softmax(wx-b)
#模型输入输出:placheolder
input_size = 784 #28*28 #输入神经元个数
output_size = 10 #输出神经元个数
#模型输入输出
x = tf.placeholder(tf.float32,[None,input_size])#None 不知道输入多少个数据 使用一个占位符来定位
y = tf.placeholder(tf.float32,[None,output_size])
#权重矩阵和阈值:Variable
w = tf.Variable(tf.random_normal(shape=(input_size,output_size),dtype=tf.float32)) #权重矩阵784*10 需要设置初始值
bias = tf.Variable(tf.zeros(output_size,dtype=tf.float32)) #阈值 长度为10
#2.2定义模型
y_predict=tf.nn.softmax(tf.matmul(x,w)-bias)
#2.3定义损失函数(预测结果和真实结果的评价)===>交叉熵的评估方法。loss function
loss=tf.reduce_mean(
-tf.reduce_sum(y * tf.log(y_predict),axis=1)
)# 按照行求和
#2.4定义优化器(使损失函数最小)
opt=tf.train.GradientDescentOptimizer(learning_rate=0.1) #梯度下降法 还有一个常用 自适应优化器
#2.5定义训练节点(定义优化器来使得损失函数最小)
train_op = opt.minimize(loss)
#3.执行计算
#3.1启动会话
sess = tf.Session()
#3.2全局变量初始化
sess.run(tf.global_variables_initializer())
#3.3训练模型
#训练集(数据有点多。不能一次交给模型处理,多次处理就会发生错误)使用批处理进行
iter = 5001
all_cost = [] #记录损失函数 (理论上随着函数的训练,损失值应该是越来越小,稳定在相对稳定的一个值上面)
for i in range(iter):
x_batch,y_batch = mnist.train.next_batch(100) #批处理:分批次传入数据进行训练
t,cost = sess.run([train_op,loss],feed_dict={x:x_batch,y:y_batch})
all_cost.append(cost)
#定期打印结果
if i%100 == 0: #如果i 可以被100整除
print(f"第{i}次训练".center(50,'='))
print(f'损失值为:{cost}')
# 训练完毕后,绘制折线图,展示训练过程中损失值的变化情况,大概判断模型的好坏。
plt.plot(range(iter) ,all_cost)
plt.xlabel('Times') #训练次数
plt.ylabel('Loss') #损失值展示
plt.show()
# 3.5 模型测试
mnist.test.images
mnist.test.labels
y_pre = sess.run(y_predict,feed_dict={x:mnist.test.images})
y_pre_labels = np.argmax(y_pre,axis=1) #返回最大值所在的下标,按照行取出
print("最后一张图的与预测值为:",y_pre_labels[9999]) #输出值
#模型的正确率
y_real_labels = np.argmax(mnist.test.labels,axis=1)
print("最后一张图片的值为:",plt.imshow(mnist.test.images[9999].reshape(28,28),cmap='gray'))
print("模型预测的正确率:",(np.sum(y_real_labels == y_pre_labels)/10000)*100,'%')#如果相同的话则证明预测结果和真实结果相同
#3.4关闭会话
sess.close()















 406
406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









