







一、什么是HashMap
hashMap是一个无序,不重复,无索引的双列集合,通过hashCode方法和equals方法保证键唯一
hashMap主要依靠数组、链表、红黑树的数据结构实现,当发生哈希碰撞时新加的元素会接在原来数组的元素后面形成一个链表,当链表长度大于等于8数组长度大于等于64时会将链表转化成红黑树来增加查询效率。
注:哈希碰撞即在不同对象不同属性的情况下计算出的哈希值相同(概率很小)
二、HashMap初始化


在我们new一个HashMap()时会初始化默认加载因子为0.75。
也可以在new的时候传入参数自定义初始容量和加载因子
三、HashMap.put

调用put后会将传入的key,value交给putVal方法,先计算出key哈希值。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//第一个if
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//第二个if
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//第三个if
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}从putVal源码中我们看到最外层有三条if分别的作用是:
第一个if:判断map的数组对象是否是null或者长度为0,如果是则进行resize()方法进行初始化,并将数组长度赋值给变量n。
第二个if:用传入key的hash值和变量n也就是数组长度-1进行&运算得出索引,判断该索引在数组中是否存在元素,如果为null则new一个节点,否则就是一系列操作。(一会再说)
第三个if:判断size是否大于门槛值threshold,如果大于则要进行resize()方法扩容。threshold在默认情况下是通过map总容量*0.75(默认加载因子)来得出的。
从中我们可以得出resize()方法在刚创建一个HashMap()其中还没有任何元素时有初始化的作用,在元素达到门槛值时又起到扩容的作用。具体看源码注释:
1、resize()源码:
final Node<K,V>[] resize() {
//老数据赋值给oldTab
Node<K,V>[] oldTab = table;
//老容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//老门槛值
int oldThr = threshold;
//初始化新容量,新门槛值
int newCap, newThr = 0;
if (oldCap > 0) {
//老容量大于最大值,扩容失败直接返回
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//在老容量乘2不大于最大值且老容量大于默认容量16
//将老容量乘2赋值给新容量
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
/*下面两种情况是初始化的情况
老门槛值大于0的情况是在Hashmap初始化时给一个特定容量,从构造函数可以看到
当我们空参构造时门槛值初始化是0,有参数时门槛值初始化是参数值的最小2次幂*/
else if (oldThr > 0) // initial capacity was placed in threshold
//直接把门槛值,也就是给出容量的最小2次幂付给新容量
newCap = oldThr;
else { // zero initial threshold signifies using defaults
//默认值初始化
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//这里是补足老门槛值大于0时,新门槛值赋值,赋值就是新容量*默认因子0.75
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//赋值给成员变量
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
//创建一个新容量大小的新表
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//将新表赋值给成员变量
table = newTab;
//下面开始扩容操作,如果老表是null则应该是初始化不需要扩容
if (oldTab != null) {
//遍历老表的内容
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//将老表中的内容赋值给e,清楚老表原来位置的元素
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//判断元素是否是单个元素,是的话直接赋值到新表中即可
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//判断元素是否是红黑树节点,是的话拆分树
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//如果以上两者都不是则是链表,以下是拆分链表操作
else { // preserve order
//初始化四个节点,因为要将一个链表拆分成两个所以头尾节点各两个
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
//初始化第三方next节点,用于临时存储下个节点
Node<K,V> next;
//dowhile遍历链表
do {
//把元素的下个节点赋值个next
next = e.next;
//拆分链表
if ((e.hash & oldCap) == 0) {
//这条判断用于确定头元素
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
//这条判断用于确定头元素
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//最后给两条新链表尾巴节点的next附上null
//并且确定两条链表的位置一个在j位置另一条在j+老容量的位置
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}在我们向HashMap中添加元素时会有三种情况:
2、添加元素时哈希值对应数组索引的元素为null:
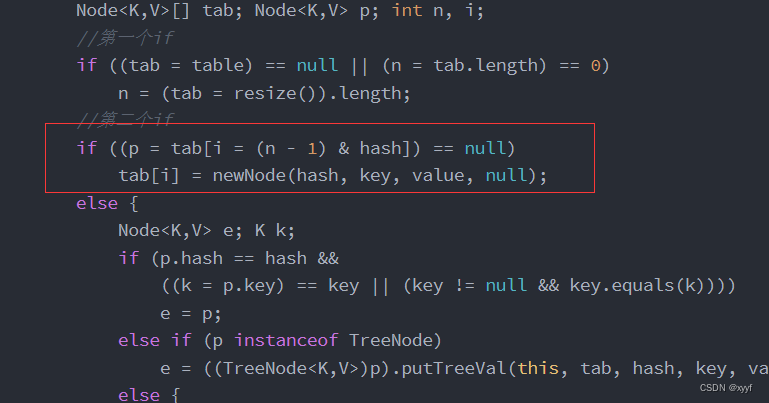
如果对应数组的元素为null则会进入第二if为true直接新建一个键值对将key,value传入,放在数组对应位置上。
3、添加元素时哈希值对应数组索引的元素不为null且键相同:
1、当相同键的元素是数组中的第一个元素:
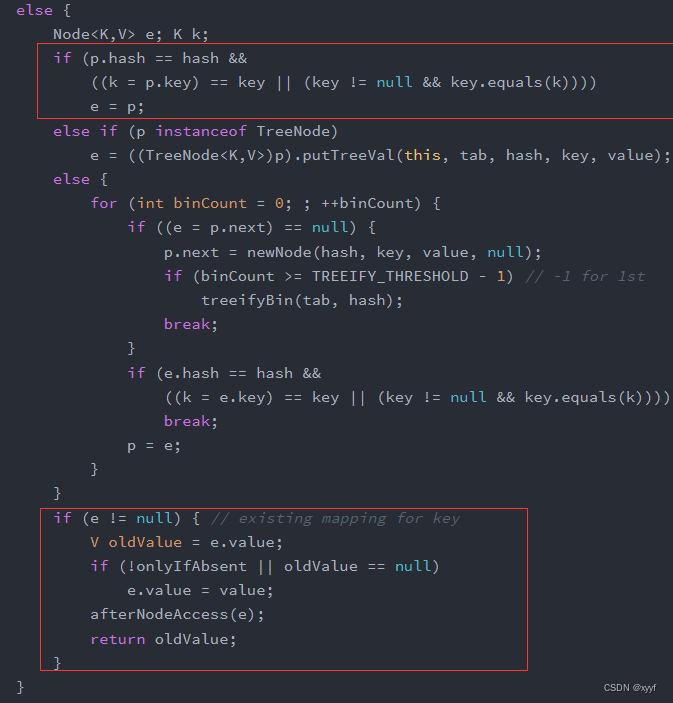
p为原来数组中的元素,如果相同键的元素是数组中的第一个元素则e=p,在下个if中e!=null,此时e就是原来数组的元素将e的值赋值给oldValue,如果开启onlyIfAbsent(是否覆盖值)或者oldValue没有值则将原来数组元素的值覆盖成新值并且返回老值。
2、当相同键的元素是数组链表非头节点的节点: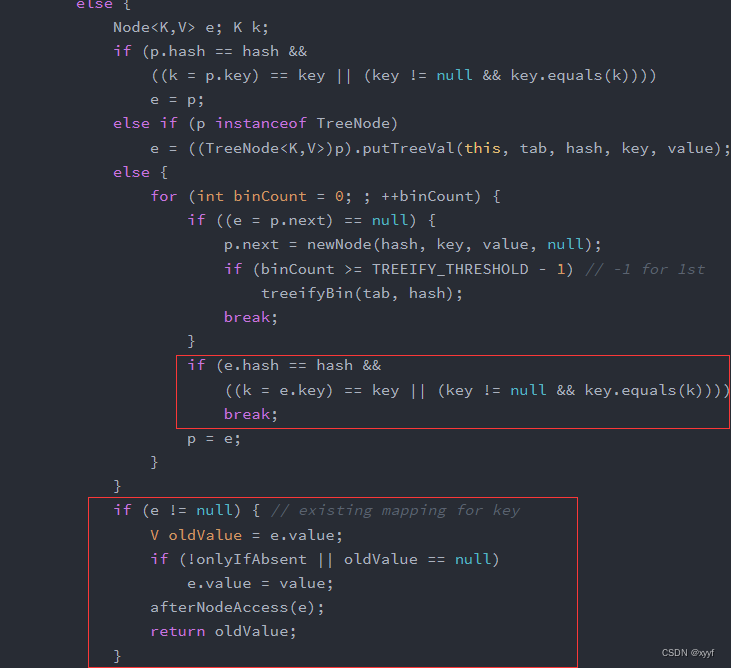
此时e=p.next(数组链表中节点的下个节点)
后续p=e按照这样的逻辑遍历链表
首先在遍历链表中判断e的hash值和要加入的hash值是否相同,如果相同再去判断键地址或者键值是否相同,相同就break。
3、如果是红黑树:
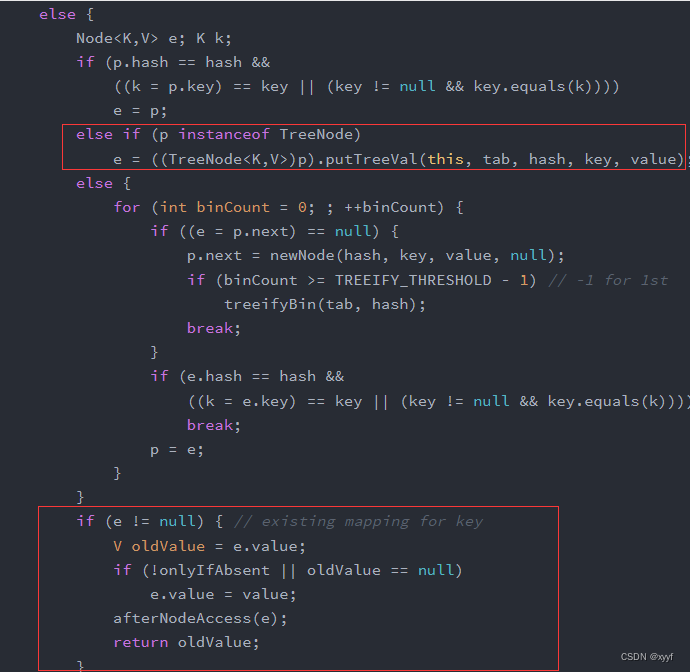
会通过putTreeVal方法来返回需要替换的老元素(putTreeVal此处省略)
4、添加元素时哈希值对应数组索引的元素不为null且键不相同(哈希碰撞):
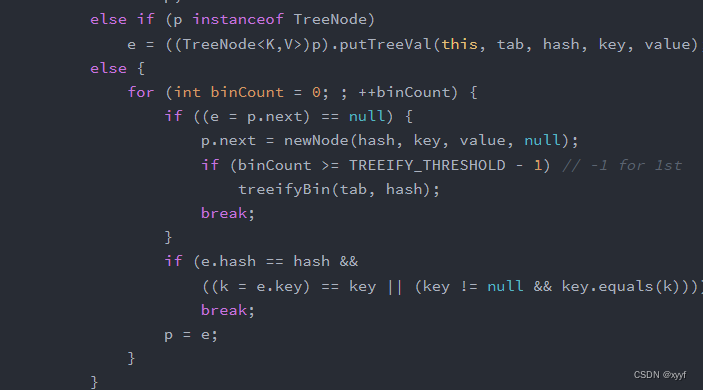
这种情况意味着需要将多个元素放在同一个数组索性下。
第一个else if判断是否数组元素是树节点如果是则按照红黑树的规则添加入红黑树中。
第二else是将元素添加到原数组链表的下方,具体为:
在遍历过程中,判断p(链表中的节点)的下一个元素是否为null,如果是则将新元素添加到null的位置。
当binCount(链表长度) >8时(binCount >= 8-1 binCount从0开始计算所以减一)则调用treeifyBin方法将链表转化成红黑树。
再下一个if是判断键是否重复的如果重复则跳出循环执行后面的覆盖操作。















 1192
1192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









