







YOLOv2由Joseph Redmon等人于2016年提出,论文名为:《YOLO9000: Better, Faster, Stronger》,论文见:https://arxiv.org/pdf/1612.08242.pdf ,项目网页:https://pjreddie.com/darknet/yolov2/ ,YOLO9000可以检测9000个目标类别。YOLOv2是对YOLOv1的改进。
以下内容主要来自论文:
1.Better:YOLOv1存在的缺点:与Fast R-CNN相比,YOLOv1存在大量定位错误(localization error);与基于候选区域(region proposal-based)的方法相比,YOLOv1的召回率(recall)相对较低。
(1).Batch Normalization:批量归一化可以显著提高收敛性(convergence),同时消除对其他形式正则化(regularization)的需要。通过在YOLOv1中的所有卷积层上添加批量归一化,可提高mAP。批量归一化还有助于规范(regularize)模型。通过批量归一化,我们可以从模型中删除dropout,而不会过度拟合。
(2).High Resolution Classifier:所有最先进的(state-of-the-art)检测方法都使用在ImageNet上预训练的分类器。最初的YOLOv1以224*224训练分类器网络,并将分辨率提高到448进行检测。这意味着网络必须同时切换到学习目标检测并调整到新的输入分辨率。对于YOLOv2,我们首先在ImageNet上以全(full)448*448分辨率微调分类网络10个epoch。这使得网络有时间调整其滤波器(filter),以便在更高分辨率的输入上更好地工作。然后我们在检测时微调生成的网络。这个高分辨率分类网络可提高mAP。
(3).Convolutional With Anchor Boxes:YOLOv1使用卷积特征提取器(convolutional feature extractor)顶部的全连接层直接预测边界框的坐标。Faster R-CNN不是直接预测坐标,而是使用精心挑选的先验(hand-picked priors)框来预测边界框。Faster R-CNN中的区域候选网络(RPN,Region Proposal Network)仅使用卷积层来预测锚框(anchor boxes)的偏移量和置信度。我们从YOLOv1中删除了全连接层,并使用锚框来预测边界框。首先,我们消除一个池化层,以使网络卷积层的输出具有更高分辨率。我们还缩小(shrink)网络以在416输入图像上运行,而不是448*448。我们这样做是因为我们希望特征图(feature map)中有奇数个位置,这样就有一个中心单元(a single center cell)。YOLOv1的卷积层将图像下采样32倍(a factor of 32),因此通过使用416的输入图像,我们得到13*13的输出特征图。当我们转向锚框时,我们还将类别预测机制与空间位置解耦(decouple),并预测每个锚框的类别和目标性(objectness,描述了某个图像区域是否可能包含一个目标的可能性)。在 YOLOv1之后,目标性预测(objectness prediction)仍然预测真实框和候选框的IOU,并且类别预测预测该类别在存在目标的情况下的条件概率。使用锚框,我们的准确性会略有下降。YOLOv1仅预测每张图像98个框,但使用锚框,我们的模型可以预测超过1000个框。使用锚框,虽然mAP有所下降,但召回率会增加。
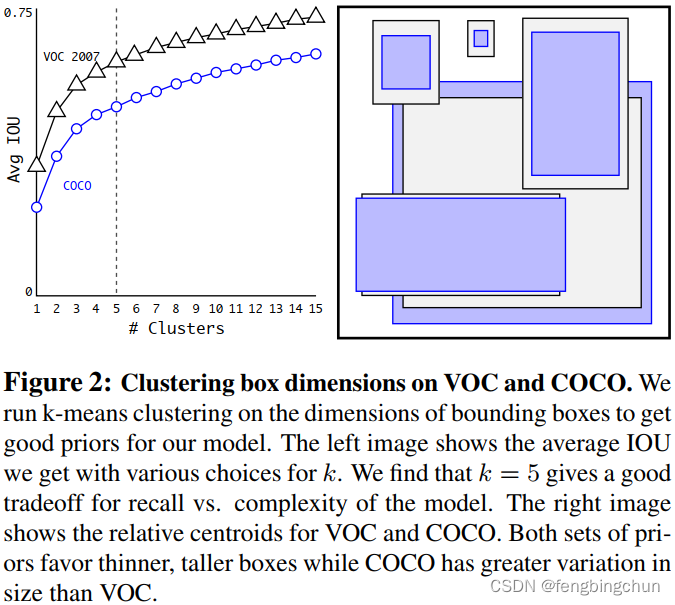
(4).Dimension Clusters:在将锚框与YOLOv1一起使用时,我们遇到了两个问题(issue)。首先,框尺寸(box dimension)是手工挑选的。网络可以学习适当地调整框,但是如果我们为网络选择更好的先验(prior)框,我们可以使网络更容易学习预测好的检测。我们不是手动选择先验框,而是在训练集边界框上运行k均值聚类(k-means clustering),以自动(automat-ically)找到好的先验框。如果我们使用带有欧氏距离的标准k均值,较大的框比较小的框会产生更多的错误。然而,我们真正想要的是能够获得好的IOU分数的先验框,该分数与框的大小无关。我们对不同的k值运行k均值,并绘制具有最接近质心(closest centroid)的平均IOU,如下图所示。我们选择k=5作为模型复杂性和高召回率(model complexity and high recall)之间的良好权衡(tradeoff)。簇质心(cluster centroid)与手工挑选的锚框有显着不同。短而宽的框较少,而高而薄的框较多。使用k-means来生成我们的边界框,以更好的表示开始模型,并使任务更容易学习。
(5).Direct location prediction:当将锚框与YOLOv1一起使用时,我们遇到第二个问题:模型不稳定,尤其是在早期迭代期间。大多数不稳定性来自于预测框的(x; y)定位。我们没有预测偏移量(offsets),而是遵循YOLOv1的方法并预测相对于网格单元位置(location)的位置坐标。这将真实框的值限制在0和1之间。我们使用逻辑激活(logistic activation)来将网络的预测限制在这个范围内。由于我们限制了位置预测,因此参数化(parametrization)更容易学习,从而使网络更加稳定。如下图所示,使用维度簇(dimension clusters)并直接预测边界框中心位置,与使用锚框的版本相比,YOLOv1提高了近5%。

(6).Fine-Grained Features:这个修改后的YOLOv1在13*13特征图上预测检测。虽然这对于大型目标来说已经足够了,但它可能会受益于更细粒度的特征(finer grained features)来定位较小的目标。Faster R-CNN和SSD都在网络中的各种特征图上运行其候选网络(proposal network)以获得一系列分辨率(a range of resolutions)。我们采用不同的方法,只需添加一个直通层(passthrough layer),以26*26分辨率引入较早层的特征。直通层通过将相邻特征堆叠到不同的通道(different channels)而不是空间位置(spatial location),将高分辨率特征(higher resolution features)与低分辨率特征连接起来(concatenate),类似于ResNet中的恒等映射(identity mapping)。这将26*26*512特征图变成了13*13*2048特征图,可以与原始特征连接。我们的检测器运行在这个扩展的特征图之上,以便它可以访问细粒度的特征。
(7).Multi-Scale Training:原始YOLOv1使用的输入分辨率为448*448。通过添加锚框,我们将分辨率更改为416×416。然而,由于我们的模型仅使用卷积层和池化层,因此可以动态调整大小(resized on the fly)。我们希望YOLOv2能够在不同大小的图像上运行,因此我们将其训练到模型中。我们不是固定(fixing)输入图像的大小,而是每隔几次迭代就改变网络。每10个批次(batches),我们的网络都会随机选择一个新的图像尺寸(image dimension size)。由于我们的模型按32倍(a factor of 32)下采样,因此我们从以下32的倍数中提取:{320, 352, ..., 608}。因此,最小的选项是320*320,最大的选项是608*608。我们将网络大小调整到该尺寸(dimension)并继续训练。这种机制(regime)迫使网络学会在各种输入维度上进行良好的预测。这意味着同一网络可以预测不同分辨率的检测。网络在较小尺寸下运行速度更快,因此YOLOv2可以在速度和准确性之间轻松权衡(tradeoff)。
2.Faster:大多数检测框架依赖VGG-16作为基本特征提取器(feature extractor)。VGG-16是一个强大、准确的分类网络,但它过于复杂。VGG-16的卷积层需要 306.9亿次浮点运算才能以224*224分辨率处理单个图像。YOLOv1框架使用基于Googlenet架构的自定义网络。该网络比VGG-16更快,前向传递仅使用85.2亿次操作。但其准确率比VGG-16稍差。
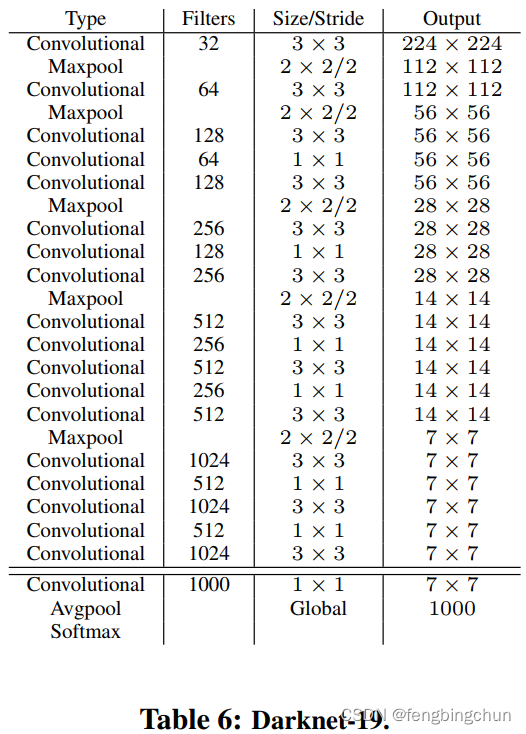
(1).Darknet-19:我们提出了一种新的分类模型作为YOLOv2的基础。我们的模型建立在网络设计的先前工作以及该领域的常识的基础上。与VGG模型类似,我们主要使用3*3滤波器,并在每个池化步骤后将通道数量加倍。在Network in Network(NIN)的工作之后,我们使用全局平均池化进行预测,并使用1*1滤波器来压缩3*3卷积之间的特征表示(feature representation)。我们使用批量归一化(batch normalization)来稳定训练,加速收敛,并对模型进行正则化。我们的最终模型称为Darknet-19,具有19个卷积层和5个最大池层。如下图所示:
(2).Training for classification:我们使用Darknet神经网络框架,在标准ImageNet 1000类分类数据集上训练网络160个轮次(epochs),使用随机梯度下降,起始学习率为0.1,多项式速率衰减(polynomial rate decay)为4次方,权重衰减(weight decay)为0.0005,动量(momentum)为0.9。在训练期间,我们使用标准数据增强技巧(augmentation tricks),包括随机裁剪、旋转、色调、饱和度和曝光偏移(random crops, rotations, and hue, saturation, and exposure shifts)。
(3).Training for detection:我们通过删除最后一个卷积层来修改此网络以进行检测,并添加三个带有1024个滤波器的3*3卷积层,每个卷积层后面跟着一个最终的1*1卷积层,其中包含我们检测所需的输出数量。对于VOC,我们预测5个框,每个框有5个坐标,每个框有20个类别,因此有125个过滤器。我们还从最后的 3*3*512层到倒数第二个卷积层添加了一个直通层(passthrough layer),以便我们的模型可以使用细粒度特征(fine grain features)。我们训练网络160轮次,起始学习率为0.001,在第60和90个轮次除以10。我们使用0.0005的权重衰减和0.9的动量。我们使用与YOLOv1和SSD类似的数据增强,包括随机裁剪、颜色偏移(color shifting)等。
3.Stronger:我们提出了一种对分类和检测数据进行联合训练的机制。我们的方法使用标记为检测的图像来学习特定于检测的信息,例如边界框坐标预测和目标性(objectness)以及如何对常见目标进行分类。它使用仅具有类别标签的图像来扩展它可以检测的类别数量。在训练期间,我们混合来自检测和分类数据集的图像。当我们的网络看到标记为检测的图像时,我们可以基于完整的YOLOv2损失函数进行反向传播。当它看到分类图像时,我们仅从架构的特定于分类的部分(classification-specific parts)反向传播损失。这种方法提出了一些挑战(challenges)。检测数据集只有常见的目标和通用标签,例如"狗"或"船"。分类数据集具有更广泛、更深层次的标签。ImageNet拥有一百多个品种的狗,如"Norfolk terrier", "Yorkshire terrier"。如果我们想在两个数据集上进行训练,我们需要一种连贯(coherent)的方法来合并这些标签。大多数分类方法都使用跨所有可能类别的softmax层来计算最终的概率分布(probability distribution)。使用softmax假设类别是互斥的(mutually exclusive)。这带来了组合数据集的问题,例如,你不希望使用此模型组合ImageNet和COCO,因为类"Norfolk terrier"和"dog"并不相互排斥。我们可以使用多标签模型来组合不假设互斥(does not assume mutual exclusion)的数据集。这种方法忽略了我们所知道的有关数据的所有结构,例如所有COCO类都是互斥的。
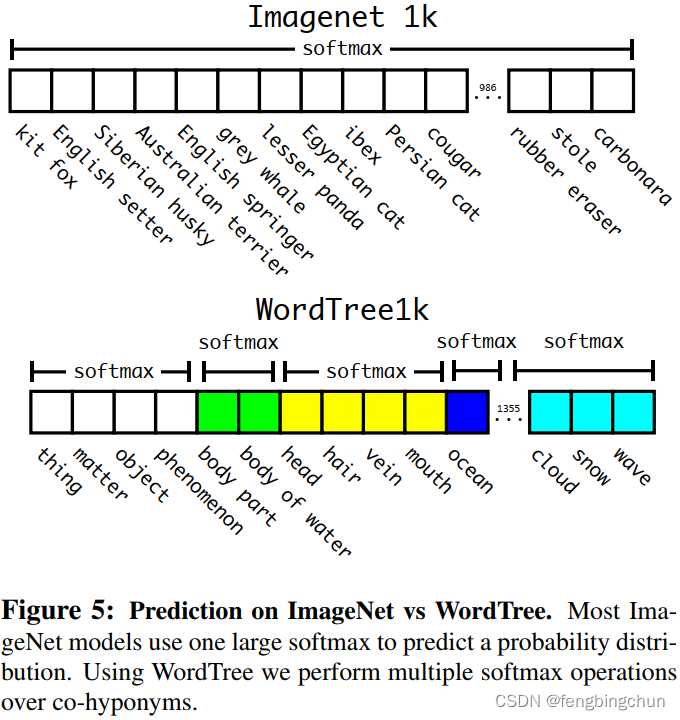
(1).Hierarchical classification:ImageNet标签取自WordNet,这是一个构建概念及其关联方式的(structures concepts and how they relate)语言数据库。在WordNet中,"Norfolk terrier" 和"Yorkshire terrier"都是"梗(terrier)"的下位词,"梗"是"猎犬"的一种,"狗"的一种,"犬"的一种,等等。大多数分类方法都假设标签采用扁平结构(flat structure),但是对于组合数据集,这种结构正是我们所需要的。WordNet的结构是有向图(directed graph),而不是树(tree),因为语言很复杂。例如,"狗"既是"犬科动物"的一种,又是"家养动物"的一种,它们都是WordNet中的同义词集(synsets)。我们没有使用完整的图结构,而是通过根据ImageNet中的概念构建层次树(hierarchical tree)来简化问题。为了构建这棵树,我们检查ImageNet中的视觉名词(visual nouns),并查看它们通过WordNet图到根节点(在本例中为"物理目标(physical object)")的路径。许多同义词集在图中只有一条路径,因此我们首先将所有这些路径添加到我们的树中。然后,我们迭代地(iteratively)检查我们留下的概念(the concepts we have left),并添加尽可能少地生长树的路径。因此,如果一个概念有两条到根的路径,其中一条路径会向我们的树添加三个边(three edges),而另一条路径只会添加一条边,那么我们会选择较短的路径。最终的结果是WordTree,一个视觉概念的层次模型(hierarchical model)。为了使用WordTree进行分类,我们在给定同义词集的情况下,预测该同义词集的每个下义词概率在每个节点的条件概率(we predict conditional probabilities at every node for the probability of each hyponym of that synset given that synset)。如果我们想计算特定节点(particular node)的绝对概率(absolute probability),我们只需沿着树到根节点(root node)的路径并乘以条件概率即可。出于分类目的,我们假设图像包含一个目标。
为了验证这种方法,我们在使用1000类ImageNet构建的WordTree上训练Darknet-19模型。为了构建WordTree1k,我们添加了所有中间节点,将标签空间从1000扩展到1369。在训练期间,我们将ground truth标签传播到树上,这样如果图像被标记为"Norfolk terrier",它也会被标记为 "狗" 和 "哺乳动物"等。为了计算条件概率,我们的模型预测了1369个值的向量,并且我们计算了作为同一概念的下位词(hyponyms)的所有系统集的softmax,如下图所示:
该配方也适用于检测。现在,我们不再假设每个图像都有一个目标,而是使用YOLOv2的目标预测器来给出物理目标(physical object)概率的值。检测器预测边界框和概率树(the tree of probabilities)。我们向下遍历树,在每次分割(split)时采用最高置信路径,直到达到某个阈值并预测该目标类别。
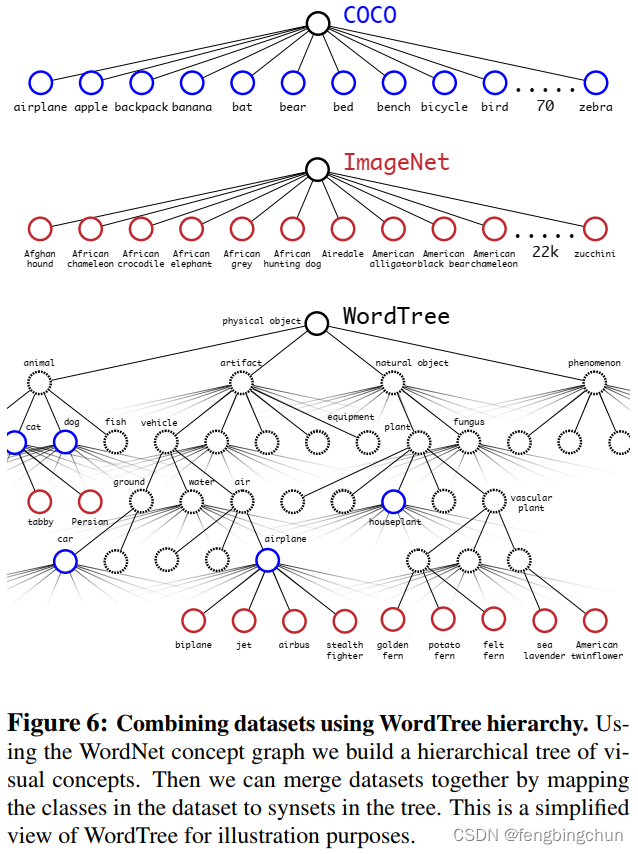
(2).Dataset combination with WordTree:我们可以使用WordTree以合理的方式(sensible fashion)将多个数据集组合在一起。我们只需将数据集中的类别映射到树中的同义词集。如下图所示:显示了使用WordTree组合来自ImageNet和COCO的标签的示例。WordNet极其多样化,因此我们可以在大多数数据集上使用这种技术。
(3).Joint classification and detection:现在我们可以使用WordTree组合数据集,我们可以在分类和检测上训练我们的联合模型(joint model)。我们想要训练一个超大规模的检测器,因此我们使用COCO检测数据集和完整ImageNet版本中的前9000个类别创建组合数据集。该数据集对应的WordTree有9418个类别。我们使用这个数据集训练YOLO9000。我们使用基本的YOLOv2架构,但只有3个先验框而不是5个先验框来限制输出大小。当我们的网络看到检测图像时,我们会像平常一样反向传播损失。对于分类损失,我们仅反向传播等于或高于标签相应级别的损失。
YOLOv2配置文件:https://github.com/pjreddie/darknet/blob/master/cfg/yolov2.cfg
GitHub:https://github.com/fengbingchun/NN_Test














 16万+
16万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









