







参考Caffe source中examples/cifar10目录下内容。
cifar10是一个用于普通物体识别的数据集,cifar10被分为10类,分别为airplane、automobile、bird、cat、deer、dog、frog、horse、ship、truck,关于cifar10的详细介绍可以参考: http://blog.csdn.net/fengbingchun/article/details/53560637
调整后的cifar10_quick_solver.prototxt内容如下:
# reduce the learning rate after 8 epochs (4000 iters) by a factor of 10
# The train/test net protocol buffer definition
net: "E:/GitCode/Caffe_Test/test_data/model/cifar10/cifar10_quick_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.001
momentum: 0.9
weight_decay: 0.004
# The learning rate policy
lr_policy: "fixed"
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 4000
# snapshot intermediate results
snapshot: 4000
snapshot_format: HDF5
snapshot_prefix: "E:/GitCode/Caffe_Test/test_data/model/cifar10/cifar10_quick"
# solver mode: CPU or GPU
#solver_mode: GPUname: "CIFAR10_quick"
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mean_file: "E:/GitCode/Caffe_Test/test_data/model/cifar10/mean.binaryproto"
}
data_param {
source: "E:/GitCode/Caffe_Test/test_data/cifar10/cifar10_train_lmdb"
batch_size: 100
backend: LMDB
}
}
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mean_file: "E:/GitCode/Caffe_Test/test_data/model/cifar10/mean.binaryproto"
}
data_param {
source: "E:/GitCode/Caffe_Test/test_data/cifar10/cifar10_test_lmdb"
batch_size: 100
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 5
stride: 1
weight_filler {
type: "gaussian"
std: 0.0001
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "pool1"
top: "pool1"
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 5
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: AVE
kernel_size: 3
stride: 2
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 64
pad: 2
kernel_size: 5
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3"
top: "pool3"
pooling_param {
pool: AVE
kernel_size: 3
stride: 2
}
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool3"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 64
weight_filler {
type: "gaussian"
std: 0.1
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10
weight_filler {
type: "gaussian"
std: 0.1
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
训练代码如下: 它既可以在CPU也可以在GPU模式下运行,分别对应的工程为Caffe_Test和Caffe_GPU_Test,在GPU模式下耗时较少。
#include "funset.hpp"
#include "common.hpp"
int cifar10_train()
{
#ifdef CPU_ONLY
caffe::Caffe::set_mode(caffe::Caffe::CPU);
#else
caffe::Caffe::set_mode(caffe::Caffe::GPU);
#endif
const std::string filename{ "E:/GitCode/Caffe_Test/test_data/model/cifar10/cifar10_quick_solver.prototxt" };
caffe::SolverParameter solver_param;
if (!caffe::ReadProtoFromTextFile(filename.c_str(), &solver_param)) {
fprintf(stderr, "parse solver.prototxt fail\n");
return -1;
}
cifar10_convert(); // convert cifar10 to LMDB
if (cifar10_compute_image_mean() != 0) { // compute cifar10 image mean, generate mean.binaryproto
fprintf(stderr, "compute cifar10 image mean fail\n");
return -1;
}
caffe::SGDSolver<float> solver(solver_param);
solver.Solve();
fprintf(stderr, "cifar10 train finish\n");
return 0;
}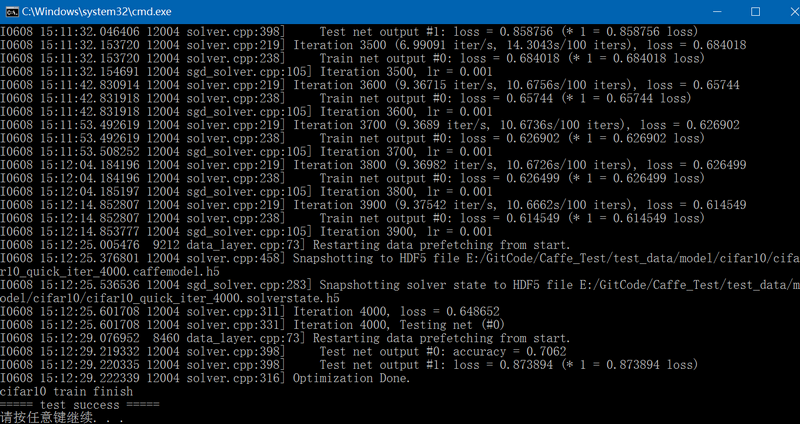
默认最大迭代次数为4000,此时accuracy为0.7062;如果设置最大迭代次数为10000,则此时accuracy约为0.72。















 634
634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









