






核心点:关于1.6w字,56个sklearn核心操作!!
整体涉及到56个函数的说明和使用~
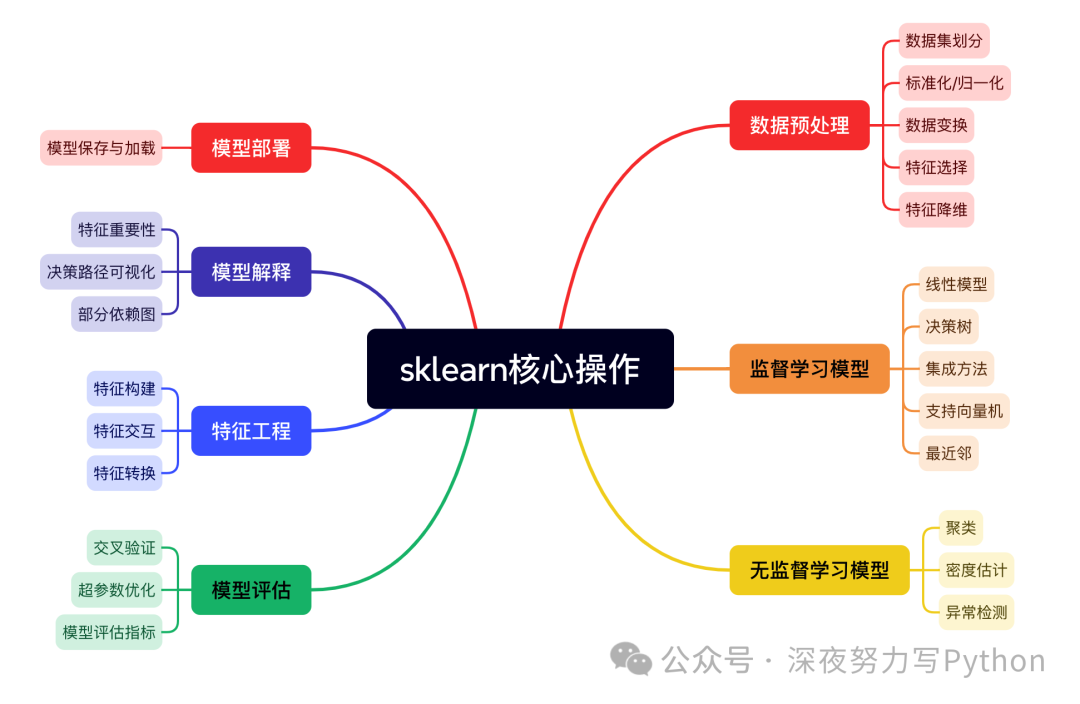
简单来说,scikit-learn 是一个非常非常常用的机器学习库,提供了许多用于数据预处理、模型选择、评估和部署的功能。
今天所有的内容建议初学者花一天时间实操一遍,具体咱们一起来看看~
数据预处理
数据集划分
train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)其中,X是特征数据,y是目标数据,test_size是测试集的比例(可以是0到1之间的值),random_state是随机种子,用于保证每次划分的结果一致。
使用train_test_split:
import numpy as np
from sklearn.model_selection import train_test_split
# 创建一个数据集
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 1, 0, 1])
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
print("训练集 X:\n", X_train)
print("测试集 X:\n", X_test)
print("训练集 y:\n", y_train)
print("测试集 y:\n", y_test)这个示例创建了一个特征矩阵X和目标向量y,然后使用train_test_split函数将数据集划分为训练集和测试集。
标准化/归一化
StandardScaler
用于标准化特征数据,使其具有标准正态分布(均值为0,方差为1)。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)其中,fit_transform方法用于计算训练集的均值和标准差,并进行标准化转换。transform方法用于在测试集上应用相同的转换。
使用StandardScaler:
import numpy as np
from sklearn.preprocessing import StandardScaler
# 创建一个特征矩阵
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]], dtype=np.float64)
# 创建一个StandardScaler对象并进行标准化转换
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print("原始数据 X:\n", X)
print("标准化后的数据 X_scaled:\n", X_scaled)
print("均值:", scaler.mean_)
print("标准差:", scaler.scale_)创建了一个特征矩阵X,然后使用StandardScaler进行标准化转换,并输出了转换后的数据以及均值和标准差。
MinMaxScaler
用于将特征数据缩放到给定的最小值和最大值之间,默认情况下,最小值为0,最大值为1。
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)fit_transform方法用于计算训练集的最小值和最大值,并进行缩放转换。transform方法用于在测试集上应用相同的缩放。
import numpy as np
from sklearn.preprocessing import MinMaxScaler
# 创建一个特征矩阵
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]], dtype=np.float64)
# 创建一个MinMaxScaler对象并进行缩放转换
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
print("原始数据 X:\n", X)
print("缩放后的数据 X_scaled:\n", X_scaled)
print("最小值:", scaler.data_min_)
print("最大值:", scaler.data_max_)代码中,创建了一个特征矩阵X,然后使用MinMaxScaler进行缩放转换,并输出了转换后的数据以及最小值和最大值。
RobustScaler
用于缩放特征数据,使其对异常值具有更好的鲁棒性。与StandardScaler和MinMaxScaler不同,RobustScaler使用中位数和四分位数范围进行缩放。
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)fit_transform方法用于计算训练集的中位数和四分位数范围,并进行缩放转换。transform方法用于在测试集上应用相同的转换。
import numpy as np
from sklearn.preprocessing import RobustScaler
# 创建一个特征矩阵
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]], dtype=np.float64)
# 添加一个异常值
X[0, 0] = 1000
# 创建一个RobustScaler对象并进行缩放转换
scaler = RobustScaler()
X_scaled = scaler.fit_transform(X)
print("原始数据 X:\n", X)
print("缩放后的数据 X_scaled:\n", X_scaled)
print("中位数:", scaler.center_)
print("四分位数范围:", scaler.scale_)代码中,创建了一个特征矩阵X,其中包含一个异常值,然后使用RobustScaler进行缩放转换,并输出了转换后的数据以及中位数和四分位数范围。
数据变换
FunctionTransformer
对数据应用自定义的函数转换。
from sklearn.preprocessing import FunctionTransformer
# 定义自定义函数
def custom_func(X):
return X + 10 # 举例:将数据中的每个元素都加上10
# 创建FunctionTransformer对象并进行转换
transformer = FunctionTransformer(func=custom_func)
X_transformed = transformer.fit_transform(X)fit_transform方法用于对数据进行转换,可以传入自定义的函数。代码中,定义了一个将数据中的每个元素加上10的函数custom_func,然后使用FunctionTransformer进行转换。
import numpy as np
from sklearn.preprocessing import FunctionTransformer
# 创建一个特征矩阵
X = np.array([[1, 2], [3, 4], [5, 6]])
# 定义自定义函数
def custom_func(X):
return X + 10
# 创建FunctionTransformer对象并进行转换
transformer = FunctionTransformer(func=custom_func)
X_transformed = transformer.fit_transform(X)
print("原始数据 X:\n", X)
print("转换后的数据 X_transformed:\n", X_transformed)这个示例创建了一个特征矩阵X,然后使用FunctionTransformer将每个元素加上10进行转换。
PowerTransformer
用于对数据进行幂变换,使其更符合高斯分布。PowerTransformer提供了两种幂变换方法:Yeo-Johnson变换和Box-Cox变换。
默认情况下,PowerTransformer使用Yeo-Johnson变换。
from sklearn.preprocessing import PowerTransformer
scaler = PowerTransformer(method='yeo-johnson')
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)fit_transform方法用于计算变换参数并进行变换。对于Yeo-Johnson变换,数据必须严格大于0;对于Box-Cox变换,数据必须严格大于0。
如果数据中存在非正数值,可以使用StandardScaler或RobustScaler等方法先进行缩放。
import numpy as np
from sklearn.preprocessing import PowerTransformer
# 创建一个特征矩阵
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]], dtype=np.float64)
# 创建一个PowerTransformer对象并进行幂变换
scaler = PowerTransformer(method='yeo-johnson')
X_scaled = scaler.fit_transform(X)
print("原始数据 X:\n", X)
print("幂变换后的数据 X_scaled:\n", X_scaled)代码中,创建了一个特征矩阵X,然后使用PowerTransformer进行幂变换,并输出了转换后的数据。
特征选择
SelectKBest
用于选择与目标变量最相关的特征。SelectKBest基于给定的评分函数选择前k个最佳特征。常用的评分函数包括f_classif(用于分类问题的方差分析法)、mutual_info_classif(用于分类问题的互信息法)、f_regression(用于回归问题的方差分析法)等。
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_classif
selector = SelectKBest(score_func=f_classif, k=2)
X_train_selected = selector.fit_transform(X_train, y_train)
X_test_selected = selector.transform(X_test)其中,score_func指定了评分函数,k指定了要选择的特征数量。
import numpy as np
from sklearn.datasets import make_classification
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_classif
# 创建一个分类数据集
X, y = make_classification(n_samples=100, n_features=4, n_informative=2, random_state=0)
# 使用SelectKBest选择最佳特征
selector = SelectKBest(score_func=f_classif, k=2)
X_selected = selector.fit_transform(X, y)
print("原始数据 X:\n", X[:5])
print("选择的最佳特征 X_selected:\n", X_selected[:5])代码中,创建了一个分类数据集X,然后使用SelectKBest选择了最佳的2个特征,并输出了选择后的特征数据。
SelectPercentile
接下来是SelectPercentile,它也用于特征选择,但是与SelectKBest不同的是,SelectPercentile选择的是按分位数排名的特征而不是固定数量的特征。同样,它也需要指定评分函数。
from sklearn.feature_selection import SelectPercentile
from sklearn.feature_selection import f_classif
selector = SelectPercentile(score_func=f_classif, percentile=50)
X_train_selected = selector.fit_transform(X_train, y_train)
X_test_selected = selector.transform(X_test)其中,percentile指定了要选择的特征的百分比。
使用SelectPercentile:
import numpy as np
from sklearn.datasets import make_classification
from sklearn.feature_selection import SelectPercentile
from sklearn.feature_selection import f_classif
# 创建一个分类数据集
X, y = make_classification(n_samples=100, n_features=4, n_informative=2, random_state=0)
# 使用SelectPercentile选择最佳特征
selector = SelectPercentile(score_func=f_classif, percentile=50)
X_selected = selector.fit_transform(X, y)
print("原始数据 X:\n", X[:5])
print("选择的最佳特征 X_selected:\n", X_selected[:5])示例中,创建了一个分类数据集X,使用SelectPercentile选择了最佳的50%特征,并输出了选择后的特征数据。
RFE (Recursive Feature Elimination)
一种递归特征消除方法,用于选择特征的子集。它通过反复训练模型并消除最不重要的特征来进行特征选择。
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
estimator = LogisticRegression()
selector = RFE(estimator, n_features_to_select=2, step=1)
X_train_selected = selector.fit_transform(X_train, y_train)
X_test_selected = selector.transform(X_test)其中,estimator是用于训练的基础模型,n_features_to_select是要选择的特征数量,step是每次迭代中要移除的特征数量。
import numpy as np
from sklearn.datasets import make_classification
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
# 创建一个分类数据集
X, y = make_classification(n_samples=100, n_features=4, n_informative=2, random_state=0)
# 使用RFE选择最佳特征
estimator = LogisticRegression()
selector = RFE(estimator, n_features_to_select=2, step=1)
X_selected = selector.fit_transform(X, y)
print("原始数据 X:\n", X[:5])
print("选择的最佳特征 X_selected:\n", X_selected[:5])代码中,创建了一个分类数据集X,然后使用RFE选择了最佳的2个特征,并输出了选择后的特征数据。
特征降维
PCA (Principal Component Analysis)
用于将高维数据转换为低维数据,同时保留最大的方差。PCA通过找到数据中的主成分(即方差最大的方向)来实现降维。
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)其中,n_components指定了要保留的主成分数量。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 使用PCA进行降维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
print("原始数据 X 的形状:", X.shape)
print("降维后的数据 X_pca 的形状:", X_pca.shape)这个示例加载了鸢尾花数据集,并使用PCA将数据降至二维,并输出了降维后的数据形状。
TruncatedSVD
一种用于稀疏矩阵的降维技术,类似于PCA,但适用于大型稀疏矩阵。TruncatedSVD通过截断奇异值分解来实现降维。
from sklearn.decomposition import TruncatedSVD
svd = TruncatedSVD(n_components=2)
X_train_svd = svd.fit_transform(X_train)
X_test_svd = svd.transform(X_test)其中,n_components指定了要保留的成分数量。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.decomposition import TruncatedSVD
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 使用TruncatedSVD进行降维
svd = TruncatedSVD(n_components=2)
X_svd = svd.fit_transform(X)
print("原始数据 X 的形状:", X.shape)
print("降维后的数据 X_svd 的形状:", X_svd.shape)这个示例加载了鸢尾花数据集,并使用TruncatedSVD将数据降至二维,并输出了降维后的数据形状。
FactorAnalysis
一种因子分析方法,用于降低数据的维度并发现潜在的因子结构。FactorAnalysis假设观测数据是由潜在因子和特殊噪声组成的。
from sklearn.decomposition import FactorAnalysis
fa = FactorAnalysis(n_components=2)
X_train_fa = fa.fit_transform(X_train)
X_test_fa = fa.transform(X_test)其中,n_components指定了要保留的潜在因子数量。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.decomposition import FactorAnalysis
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 使用FactorAnalysis进行降维
fa = FactorAnalysis(n_components=2)
X_fa = fa.fit_transform(X)
print("原始数据 X 的形状:", X.shape)
print("降维后的数据 X_fa 的形状:", X_fa.shape)代码中,加载了鸢尾花数据集,并使用FactorAnalysis将数据降至二维,并输出了降维后的数据形状。
监督学习模型
线性模型
LinearRegression
LinearRegression模型通过拟合特征和目标之间的线性关系来进行预测。
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,X_train是训练集的特征数据,y_train是训练集的目标数据,X_test是测试集的特征数据,y_test是测试集的目标数据。fit方法用于训练模型,predict方法用于进行预测。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# 创建一个数据集
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用LinearRegression进行拟合和预测
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("真实值 y_test:", y_test)
print("预测值 y_pred:", y_pred)代码中,创建了一个数据集X和y,然后使用LinearRegression进行拟合和预测,并输出了真实值和预测值。
LogisticRegression
LogisticRegression模型使用逻辑函数(logistic function)将线性模型的输出映射到[0, 1]之间,表示样本属于某一类的概率。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,X_train是训练集的特征数据,y_train是训练集的目标数据,X_test是测试集的特征数据,y_test是测试集的目标数据。fit方法用于训练模型,predict方法用于进行分类预测。
使用LogisticRegression进行分类预测:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# 创建一个二分类数据集
X = np.array([[1], [2], [3], [4], [5], [6]])
y = np.array([0, 0, 0, 1, 1, 1])
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用LogisticRegression进行拟合和预测
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("真实值 y_test:", y_test)
print("预测值 y_pred:", y_pred)代码中,创建了一个二分类数据集X和y,然后使用LogisticRegression进行拟合和预测,并输出了真实值和预测值。
Ridge
一种用于回归问题的线性模型,与普通的线性回归相比,Ridge模型通过添加L2正则化项来限制模型参数的大小,从而减少模型的过拟合。
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,alpha是正则化参数,控制正则化的强度。较大的alpha值表示更强的正则化。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
# 创建一个数据集
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用Ridge进行拟合和预测
model = Ridge(alpha=1.0)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("真实值 y_test:", y_test)
print("预测值 y_pred:", y_pred)创建了一个数据集X和y,然后使用Ridge进行拟合和预测,并输出了真实值和预测值。
Lasso
用于回归问题的线性模型,与普通的线性回归相比,Lasso模型通过添加L1正则化项来限制模型参数的大小,从而可以实现特征选择(即将一些特征的权重调整为0)。
from sklearn.linear_model import Lasso
model = Lasso(alpha=1.0)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,alpha是正则化参数,控制正则化的强度。较大的alpha值表示更强的正则化。
使用Lasso进行回归预测:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Lasso
# 创建一个数据集
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用Lasso进行拟合和预测
model = Lasso(alpha=1.0)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("真实值 y_test:", y_test)
print("预测值 y_pred:", y_pred)创建了一个数据集X和y,然后使用Lasso进行拟合和预测,并输出了真实值和预测值。
ElasticNet
结合了L1和L2正则化的线性模型,用于回归问题。ElasticNet通过添加L1和L2正则化项来限制模型参数的大小,并可以实现特征选择。
from sklearn.linear_model import ElasticNet
model = ElasticNet(alpha=1.0, l1_ratio=0.5)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,alpha是总的正则化参数,l1_ratio是L1正则化项在总正则化中的比例。
使用ElasticNet进行回归预测:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
# 创建一个数据集
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用ElasticNet进行拟合和预测
model = ElasticNet(alpha=1.0, l1_ratio=0.5)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("真实值 y_test:", y_test)
print("预测值 y_pred:", y_pred)代码中,创建了一个数据集X和y,然后使用ElasticNet进行拟合和预测,并输出了真实值和预测值。
决策树
DecisionTreeClassifier
基于树结构的分类模型,用于解决分类问题。决策树通过对数据集进行递归划分,使得每个叶节点都包含一个类别标签,从而构建一个分类模型。
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,X_train是训练集的特征数据,y_train是训练集的目标数据,X_test是测试集的特征数据,y_test是测试集的目标数据。fit方法用于训练模型,predict方法用于进行分类预测。
使用DecisionTreeClassifier进行分类预测:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用DecisionTreeClassifier进行拟合和预测
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 计算模型准确率
accuracy = accuracy_score(y_test, y_pred)
print("模型准确率:", accuracy)代码中,加载了鸢尾花数据集,并使用DecisionTreeClassifier进行拟合和预测,并计算了模型的准确率。
DecisionTreeRegressor
基于树结构的回归模型,用于解决回归问题。与分类树类似,决策树回归模型通过对数据集进行递归划分,使得每个叶节点都包含一个目标值,从而构建一个回归模型。使用方法与分类树相似:
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,X_train是训练集的特征数据,y_train是训练集的目标数据,X_test是测试集的特征数据,y_test是测试集的目标数据。fit方法用于训练模型,predict方法用于进行回归预测。
使用DecisionTreeRegressor进行回归预测:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error
# 创建一个数据集
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用DecisionTreeRegressor进行拟合和预测
model = DecisionTreeRegressor()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("均方误差:", mse)代码中,创建了一个数据集X和y,然后使用DecisionTreeRegressor进行拟合和预测,并计算了均方误差。
集成方法
RandomForestClassifier
一种集成学习方法,通过构建多个决策树来提高分类性能。随机森林通过在每棵树的训练过程中引入随机性(如随机选择特征和样本),减少了模型的方差,从而提高了泛化能力。
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,n_estimators指定了森林中树的数量,random_state是随机种子,用于控制每次运行时随机性的一致性。
使用RandomForestClassifier进行分类预测:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用RandomForestClassifier进行拟合和预测
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 计算模型准确率
accuracy = accuracy_score(y_test, y_pred)
print("模型准确率:", accuracy)代码中,加载了鸢尾花数据集,并使用RandomForestClassifier进行拟合和预测,并计算了模型的准确率。
RandomForestRegressor
一种集成学习方法,通过构建多个决策树来提高回归性能。随机森林通过在每棵树的训练过程中引入随机性(如随机选择特征和样本),减少了模型的方差,从而提高了泛化能力。使用方法与分类器相似:
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,n_estimators指定了森林中树的数量,random_state是随机种子,用于控制每次运行时随机性的一致性。
使用RandomForestRegressor进行回归预测:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# 创建一个数据集
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用RandomForestRegressor进行拟合和预测
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("均方误差:", mse)代码中,创建了一个数据集X和y,然后使用RandomForestRegressor进行拟合和预测,并计算了均方误差。
GradientBoostingClassifier
一种集成学习方法,通过构建多个弱分类器(通常是决策树),然后组合它们来提高分类性能。梯度提升分类器通过迭代地训练新的模型来纠正前序模型的错误,从而逐步提高模型性能。
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,n_estimators指定了要构建的树的数量,learning_rate是每个树的贡献缩放因子,random_state是随机种子,用于控制每次运行时随机性的一致性。
使用GradientBoostingClassifier进行分类预测:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用GradientBoostingClassifier进行拟合和预测
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 计算模型准确率
accuracy = accuracy_score(y_test, y_pred)
print("模型准确率:", accuracy)代码中,加载了鸢尾花数据集,并使用GradientBoostingClassifier进行拟合和预测,并计算了模型的准确率。
GradientBoostingRegressor
一种集成学习方法,通过构建多个弱回归器(通常是决策树),然后组合它们来提高回归性能。梯度提升回归器通过迭代地训练新的模型来纠正前序模型的错误,从而逐步提高模型性能。
from sklearn.ensemble import GradientBoostingRegressor
model = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,n_estimators指定了要构建的树的数量,learning_rate是每个树的贡献缩放因子,random_state是随机种子,用于控制每次运行时随机性的一致性。
使用GradientBoostingRegressor进行回归预测:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
# 创建一个数据集
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用GradientBoostingRegressor进行拟合和预测
model = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("均方误差:", mse)代码中,创建了一个数据集X和y,然后使用GradientBoostingRegressor进行拟合和预测,并计算了均方误差。
AdaBoostClassifier
一种集成学习方法,通过组合多个弱分类器(通常是决策树)来构建一个强分类器。AdaBoost通过对每个样本调整权重,使得在前一个分类器中被错误分类的样本在后续分类器中得到更多关注,从而提高整体模型的性能。
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,n_estimators指定了要构建的弱分类器的数量,random_state是随机种子,用于控制每次运行时随机性的一致性。
使用AdaBoostClassifier进行分类预测:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用AdaBoostClassifier进行拟合和预测
model = AdaBoostClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 计算模型准确率
accuracy = accuracy_score(y_test, y_pred)
print("模型准确率:", accuracy)这个示例加载了鸢尾花数据集,并使用AdaBoostClassifier进行拟合和预测,并计算了模型的准确率。
AdaBoostRegressor
一种集成学习方法,通过组合多个弱回归器(通常是决策树)来构建一个强回归器。AdaBoost通过对每个样本调整权重,使得在前一个回归器中预测错误的样本在后续回归器中得到更多关注,从而提高整体模型的性能。
from sklearn.ensemble import AdaBoostRegressor
model = AdaBoostRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,n_estimators指定了要构建的弱回归器的数量,random_state是随机种子,用于控制每次运行时随机性的一致性。
使用AdaBoostRegressor进行回归预测:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostRegressor
from sklearn.metrics import mean_squared_error
# 创建一个数据集
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用AdaBoostRegressor进行拟合和预测
model = AdaBoostRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("均方误差:", mse)代码中,创建了一个数据集X和y,然后使用AdaBoostRegressor进行拟合和预测,并计算了均方误差。
支持向量机
SVC
支持向量机(Support Vector Classifier)的缩写,用于解决分类问题。支持向量机通过在特征空间中找到最佳的超平面来实现分类。在实际应用中,通常使用核函数来将数据映射到高维空间,以处理线性不可分的情况。
from sklearn.svm import SVC
model = SVC(kernel='rbf', C=1.0, gamma='scale', random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,kernel指定了核函数的类型,常用的有线性核(linear)、多项式核(poly)、高斯核(rbf)等;C是正则化参数,控制模型的复杂度;gamma是核函数的系数。
使用SVC进行分类预测:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用SVC进行拟合和预测
model = SVC(kernel='rbf', C=1.0, gamma='scale', random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 计算模型准确率
accuracy = accuracy_score(y_test, y_pred)
print("模型准确率:", accuracy)这个示例加载了鸢尾花数据集,并使用SVC进行拟合和预测,并计算了模型的准确率。
SVR
支持向量机(Support Vector Regressor)的缩写,用于解决回归问题。与分类问题类似,支持向量机回归通过在特征空间中找到最佳的超平面来实现回归。
同样地,支持向量机回归也可以使用核函数处理线性不可分的情况。
from sklearn.svm import SVR
model = SVR(kernel='rbf', C=1.0, gamma='scale')
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,kernel指定了核函数的类型,常用的有线性核(linear)、多项式核(poly)、高斯核(rbf)等;C是正则化参数,控制模型的复杂度;gamma是核函数的系数。
使用SVR进行回归预测:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
# 创建一个数据集
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用SVR进行拟合和预测
model = SVR(kernel='rbf', C=1.0, gamma='scale')
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("均方误差:", mse)这个示例创建了一个数据集X和y,然后使用SVR进行拟合和预测,并计算了均方误差。
最近邻
KNeighborsClassifier
一种基于邻居的分类模型,通过将每个样本的类别预测为其最近邻居的类别来实现分类。
KNeighborsClassifier需要指定一个参数n_neighbors,表示要考虑的最近邻居的数量。
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=5)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,n_neighbors是一个超参数,需要根据数据集的特点进行调优。
使用KNeighborsClassifier进行分类预测:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用KNeighborsClassifier进行拟合和预测
model = KNeighborsClassifier(n_neighbors=5)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 计算模型准确率
accuracy = accuracy_score(y_test, y_pred)
print("模型准确率:", accuracy)代码中,加载了鸢尾花数据集,并使用KNeighborsClassifier进行拟合和预测,并计算了模型的准确率。
KNeighborsRegressor
一种基于K近邻的回归模型,通过将每个样本的目标值预测为其最近邻的平均值来实现回归。KNeighborsRegressor也需要指定一个参数n_neighbors,表示要考虑的最近邻的数量。
from sklearn.neighbors import KNeighborsRegressor
model = KNeighborsRegressor(n_neighbors=5)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)其中,n_neighbors是一个超参数,需要根据数据集的特点进行调优。
使用KNeighborsRegressor进行回归预测:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_squared_error
# 创建一个数据集
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用KNeighborsRegressor进行拟合和预测
model = KNeighborsRegressor(n_neighbors=5)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("均方误差:", mse)这个示例创建了一个数据集X和y,然后使用KNeighborsRegressor进行拟合和预测,并计算了均方误差。
无监督学习模型
聚类
KMeans
一种聚类算法,用于将数据集分成不同的组(簇),使得同一组内的数据点彼此更加相似,而不同组之间的数据点更加不同。KMeans需要指定一个参数n_clusters,表示要分成的簇的数量。
from sklearn.cluster import KMeans
model = KMeans(n_clusters=3, random_state=42)
model.fit(X)
y_pred = model.predict(X)其中,n_clusters是一个超参数,需要根据数据集的特点进行调优。
使用KMeans进行聚类:
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 创建一个数据集
X = np.array([[1, 2], [5, 8], [1.5, 1.8], [8, 8], [1, 0.6], [9, 11]])
# 使用KMeans进行聚类
model = KMeans(n_clusters=2, random_state=42)
y_pred = model.fit_predict(X)
# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='viridis')
plt.show()这个示例创建了一个二维数据集X,然后使用KMeans进行聚类,并使用散点图将聚类结果可视化出来。
AgglomerativeClustering
一种层次聚类算法,通过将数据点逐渐合并为越来越大的簇来构建聚类。AgglomerativeClustering的主要思想是将每个数据点视为一个簇,然后逐渐合并相似的簇,直到达到预定的簇的数量。
from sklearn.cluster import AgglomerativeClustering
model = AgglomerativeClustering(n_clusters=3)
y_pred = model.fit_predict(X)其中,n_clusters是要分成的簇的数量。
使用AgglomerativeClustering进行聚类:
import numpy as np
from sklearn.cluster import AgglomerativeClustering
import matplotlib.pyplot as plt
# 创建一个数据集
X = np.array([[1, 2], [5, 8], [1.5, 1.8], [8, 8], [1, 0.6], [9, 11]])
# 使用AgglomerativeClustering进行聚类
model = AgglomerativeClustering(n_clusters=2)
y_pred = model.fit_predict(X)
# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='viridis')
plt.show()这个示例创建了一个二维数据集X,然后使用AgglomerativeClustering进行聚类,并使用散点图将聚类结果可视化。
DBSCAN
一种密度聚类算法,能够将具有足够高密度的区域划分为簇,并能够识别噪声点。DBSCAN需要指定两个参数:eps(ε)和min_samples。eps是一个距离阈值,表示两个样本之间的最大距离,min_samples是一个整数,表示一个簇中所需的最小样本数。
from sklearn.cluster import DBSCAN
model = DBSCAN(eps=0.3, min_samples=10)
y_pred = model.fit_predict(X)其中,eps和min_samples是需要根据数据集的特点进行调优的参数。
使用DBSCAN进行聚类:
import numpy as np
from sklearn.cluster import DBSCAN
import matplotlib.pyplot as plt
# 创建一个数据集
X = np.array([[1, 2], [5, 8], [1.5, 1.8], [8, 8], [1, 0.6], [9, 11]])
# 使用DBSCAN进行聚类
model = DBSCAN(eps=2, min_samples=2)
y_pred = model.fit_predict(X)
# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='viridis')
plt.show()这个示例创建了一个二维数据集X,然后使用DBSCAN进行聚类,并使用散点图将聚类结果可视化出来。
密度估计
KernelDensity
用于估计数据的概率密度函数。Kernel Density Estimation(KDE)是一种非参数统计方法,它通过在每个数据点周围放置一个核函数并将它们加和来估计概率密度。KernelDensity可以用于生成新的样本,异常检测等应用。
from sklearn.neighbors import KernelDensity
model = KernelDensity(bandwidth=0.5, kernel='gaussian')
model.fit(X)其中,bandwidth是核密度估计的带宽参数,kernel是核函数的类型,常用的有高斯核(gaussian)等。
使用KernelDensity进行概率密度估计:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KernelDensity
# 创建一个数据集
np.random.seed(0)
X = np.concatenate((np.random.normal(0, 1, 1000), np.random.normal(4, 1, 1000)))[:, np.newaxis]
# 使用KernelDensity进行概率密度估计
model = KernelDensity(bandwidth=0.5, kernel='gaussian')
model.fit(X)
# 生成新的样本
new_samples = model.sample(1000)
# 绘制原始数据和估计的概率密度函数
plt.hist(X, bins=50, density=True, alpha=0.5, color='blue')
plt.hist(new_samples, bins=50, density=True, alpha=0.5, color='red')
plt.show()这个示例创建了一个包含两个高斯分布的简单数据集X,然后使用KernelDensity进行概率密度估计,并生成了新的样本。最后,使用直方图将原始数据和估计的概率密度函数可视化出来。
异常检测
IsolationForest
一种用于检测异常值的算法。Isolation Forest通过随机选择特征和随机选择切割值来构建一棵孤立树(Isolation Tree),并通过计算样本在树中的深度来识别异常值。由于异常值通常比正常值更容易被隔离,因此Isolation Forest能够有效地检测异常值。
from sklearn.ensemble import IsolationForest
model = IsolationForest(contamination=0.1, random_state=42)
model.fit(X)
y_pred = model.predict(X)其中,contamination是一个参数,表示数据中异常样本的比例。
使用IsolationForest进行异常值检测:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
# 创建一个数据集
np.random.seed(42)
X = 0.3 * np.random.randn(100, 2)
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
X = np.vstack([X, X_outliers])
# 使用IsolationForest进行异常值检测
model = IsolationForest(contamination=0.1, random_state=42)
y_pred = model.fit_predict(X)
# 可视化异常值检测结果
plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='viridis')
plt.show()这个示例创建了一个包含正常值和异常值的简单数据集X,然后使用IsolationForest进行异常值检测,并使用散点图将异常值检测结果可视化出来。
OneClassSVM
一种支持向量机算法的变体,用于检测数据中的异常值。与传统的支持向量机不同,OneClassSVM的目标是找到一个超平面,将数据点分为两个部分:正常值和异常值。
from sklearn.svm import OneClassSVM
model = OneClassSVM(nu=0.1, kernel='rbf', gamma='scale')
model.fit(X)
y_pred = model.predict(X)其中,nu是一个参数,表示异常值的比例;kernel是核函数的类型,常用的有高斯核(rbf);gamma是核函数的系数。
使用OneClassSVM进行异常值检测:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import OneClassSVM
# 创建一个数据集
np.random.seed(42)
X = 0.3 * np.random.randn(100, 2)
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
X = np.vstack([X, X_outliers])
# 使用OneClassSVM进行异常值检测
model = OneClassSVM(nu=0.1, kernel='rbf', gamma='scale')
y_pred = model.fit_predict(X)
# 可视化异常值检测结果
plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='viridis')
plt.show()代码中,创建了一个包含正常值和异常值的简单数据集X,然后使用OneClassSVM进行异常值检测,并使用散点图将异常值检测结果可视化出来。
模型评估
交叉验证
cross_val_score
用于评估模型性能的函数,通常与交叉验证一起使用。交叉验证是一种用于评估模型性能的统计学方法,它将数据集分成训练集和测试集,然后多次训练和测试模型,最终得到模型性能的评估指标。cross_val_score可以帮助我们轻松地进行交叉验证并计算评估指标,如准确率、精确度、召回率等。
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')其中,model是要评估的模型,X是特征数据,y是目标数据,cv是交叉验证的折数,scoring是评估指标,可以是accuracy、precision、recall等。
使用cross_val_score进行交叉验证评估模型的准确率:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 创建一个Logistic回归模型
model = LogisticRegression()
# 使用交叉验证评估模型的准确率
scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')
print("准确率:", scores.mean())这个示例加载了鸢尾花数据集,并使用cross_val_score对LogisticRegression模型进行交叉验证评估,最后打印出模型的平均准确率。
StratifiedKFold
一种用于分层抽样的交叉验证方法。在分层抽样中,每个折(fold)中的样本类别比例与整个数据集中的类别比例相同。StratifiedKFold通过保持类别比例来确保在每个折中都有足够的样本来代表每个类别,从而更准确地评估模型性能。
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5, random_state=42, shuffle=True)
for train_index, test_index in skf.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 在这里训练和评估模型其中,n_splits是折数,random_state用于控制随机性,shuffle表示是否在划分前对数据进行洗牌。
使用StratifiedKFold进行分层交叉验证:
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 创建一个Logistic回归模型
model = LogisticRegression()
# 使用StratifiedKFold进行分层交叉验证
skf = StratifiedKFold(n_splits=5, random_state=42, shuffle=True)
for train_index, test_index in skf.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)代码中,加载了鸢尾花数据集,并使用StratifiedKFold对LogisticRegression模型进行分层交叉验证,并打印每个折的准确率。
RepeatedKFold
一种重复的K折交叉验证方法,即对数据集进行K折交叉验证,重复多次并对每次重复进行不同的随机抽样。这种方法可以帮助减少由于随机性引起的误差,从而更可靠地评估模型的性能。
from sklearn.model_selection import RepeatedKFold
rkf = RepeatedKFold(n_splits=5, n_repeats=3, random_state=42)
for train_index, test_index in rkf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 在这里训练和评估模型其中,n_splits是折数,n_repeats是重复次数,random_state用于控制随机性。
使用RepeatedKFold进行重复的K折交叉验证:
from sklearn.datasets import load_iris
from sklearn.model_selection import RepeatedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 创建一个Logistic回归模型
model = LogisticRegression()
# 使用RepeatedKFold进行重复的K折交叉验证
rkf = RepeatedKFold(n_splits=5, n_repeats=3, random_state=42)
for train_index, test_index in rkf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)这个示例加载了鸢尾花数据集,并使用RepeatedKFold对LogisticRegression模型进行重复的K折交叉验证,并打印每个折的准确率。
超参数优化
GridSearchCV
GridSearchCV是一种用于超参数调优的方法,通过在指定的参数网格中搜索最佳参数组合来改善模型性能。
GridSearchCV使用交叉验证来评估每个参数组合的性能,并返回具有最佳性能的参数组合。
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 5, 10, 20],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
model = RandomForestClassifier(random_state=42)
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X, y)
best_params = grid_search.best_params_
best_score = grid_search.best_score_其中,param_grid是参数网格,包含了要调优的参数及其可能的取值;cv是交叉验证的折数;scoring是评估指标,这里使用准确率(accuracy)。
使用GridSearchCV对RandomForestClassifier模型进行超参数调优:
from sklearn.datasets import load_iris
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 定义参数网格
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 5, 10, 20],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# 创建一个RandomForestClassifier模型
model = RandomForestClassifier(random_state=42)
# 使用GridSearchCV进行超参数调优
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X, y)
best_params = grid_search.best_params_
best_score = grid_search.best_score_
print("最佳参数:", best_params)
print("最佳准确率:", best_score)代码中,加载了鸢尾花数据集,并使用GridSearchCV对RandomForestClassifier模型进行超参数调优,并打印出最佳参数和最佳准确率。
RandomizedSearchCV
与GridSearchCV类似,也用于超参数调优,但不同之处在于RandomizedSearchCV在参数搜索过程中不是遍历所有可能的参数组合,而是根据指定的参数分布进行随机采样。这样做的好处是可以更快地找到较好的参数组合,尤其是当参数空间非常大时。
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestClassifier
from scipy.stats import randint
param_dist = {
'n_estimators': randint(50, 200),
'max_depth': [None, 5, 10, 20],
'min_samples_split': randint(2, 10),
'min_samples_leaf': randint(1, 5)
}
model = RandomForestClassifier(random_state=42)
random_search = RandomizedSearchCV(estimator=model, param_distributions=param_dist, n_iter=10, cv=5, scoring='accuracy', random_state=42)
random_search.fit(X, y)
best_params = random_search.best_params_
best_score = random_search.best_score_其中,param_dist是参数分布,用于指定每个参数的可能取值范围或分布;n_iter是随机搜索的迭代次数。
使用RandomizedSearchCV对RandomForestClassifier模型进行超参数调优:
from sklearn.datasets import load_iris
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestClassifier
from scipy.stats import randint
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 定义参数分布
param_dist = {
'n_estimators': randint(50, 200),
'max_depth': [None, 5, 10, 20],
'min_samples_split': randint(2, 10),
'min_samples_leaf': randint(1, 5)
}
# 创建一个RandomForestClassifier模型
model = RandomForestClassifier(random_state=42)
# 使用RandomizedSearchCV进行超参数调优
random_search = RandomizedSearchCV(estimator=model, param_distributions=param_dist, n_iter=10, cv=5, scoring='accuracy', random_state=42)
random_search.fit(X, y)
best_params = random_search.best_params_
best_score = random_search.best_score_
print("最佳参数:", best_params)
print("最佳准确率:", best_score)代码中,加载了鸢尾花数据集,并使用RandomizedSearchCV对RandomForestClassifier模型进行超参数调优,并打印出最佳参数和最佳准确率。
模型评估指标
accuracy_score
用于计算分类模型预测准确率的函数。准确率是指模型正确预测的样本数占总样本数的比例。
from sklearn.metrics import accuracy_score
y_true = [0, 1, 0, 1]
y_pred = [0, 1, 1, 0]
accuracy = accuracy_score(y_true, y_pred)
print("准确率:", accuracy)其中,y_true是真实的标签,y_pred是模型预测的标签。
使用accuracy_score计算分类模型的预测准确率:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建一个Logistic回归模型
model = LogisticRegression()
# 在训练集上训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)代码中,加载了鸢尾花数据集,并使用LogisticRegression模型进行训练和预测,并使用accuracy_score计算模型在测试集上的预测准确率。
precision_score
用于计算分类模型的精确率的函数。精确率是指在所有被分类器判断为正例的样本中,确实为正例的样本数占比。精确率可以帮助我们理解模型在预测为正例的样本中的表现。
from sklearn.metrics import precision_score
y_true = [0, 1, 0, 1]
y_pred = [0, 1, 1, 0]
precision = precision_score(y_true, y_pred)
print("精确率:", precision)其中,y_true是真实的标签,y_pred是模型预测的标签。
使用precision_score计算分类模型的精确率:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import precision_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建一个Logistic回归模型
model = LogisticRegression()
# 在训练集上训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算精确率
precision = precision_score(y_test, y_pred, average='weighted')
print("精确率:", precision)代码中,加载了鸢尾花数据集,并使用LogisticRegression模型进行训练和预测,并使用precision_score计算模型在测试集上的精确率。
recall_score
用于计算分类模型的召回率的函数。召回率是指在所有实际为正例的样本中,被分类器判断为正例的样本数占比。召回率可以帮助我们理解模型对正例样本的识别能力。
from sklearn.metrics import recall_score
y_true = [0, 1, 0, 1]
y_pred = [0, 1, 1, 0]
recall = recall_score(y_true, y_pred)
print("召回率:", recall)其中,y_true是真实的标签,y_pred是模型预测的标签。
使用recall_score计算分类模型的召回率:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import recall_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建一个Logistic回归模型
model = LogisticRegression()
# 在训练集上训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算召回率
recall = recall_score(y_test, y_pred, average='weighted')
print("召回率:", recall)代码中,加载了鸢尾花数据集,并使用LogisticRegression模型进行训练和预测,并使用recall_score计算模型在测试集上的召回率。
f1_score
精确率(precision)和召回率(recall)的调和平均数,用于综合评估分类模型的性能。F1值越高,表示模型在精确率和召回率之间取得了更好的平衡。
from sklearn.metrics import f1_score
y_true = [0, 1, 0, 1]
y_pred = [0, 1, 1, 0]
f1 = f1_score(y_true, y_pred)
print("F1值:", f1)其中,y_true是真实的标签,y_pred是模型预测的标签。
使用f1_score计算分类模型的F1值:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import f1_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建一个Logistic回归模型
model = LogisticRegression()
# 在训练集上训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算F1值
f1 = f1_score(y_test, y_pred, average='weighted')
print("F1值:", f1)代码中,加载了鸢尾花数据集,并使用LogisticRegression模型进行训练和预测,并使用f1_score计算模型在测试集上的F1值。
roc_auc_score
用于评估二分类模型性能的指标,特别适用于不平衡数据集。ROC曲线是以假阳率(FPR)为横轴,真阳率(TPR,即召回率)为纵轴绘制的曲线,而AUC(Area Under Curve)则是ROC曲线下的面积,用于表示模型的性能。ROC曲线下的面积越大,说明模型性能越好。
from sklearn.metrics import roc_auc_score
y_true = [0, 1, 0, 1]
y_pred_proba = [0.1, 0.9, 0.2, 0.8] # 预测为正例的概率
roc_auc = roc_auc_score(y_true, y_pred_proba)
print("ROC AUC值:", roc_auc)其中,y_true是真实的标签,y_pred_proba是模型预测的正例概率。
使用roc_auc_score计算二分类模型的ROC AUC值:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
# 加载鸢尾花数据集,为了演示二分类问题,只选择两个类别
iris = load_iris()
X = iris.data
y = iris.target
X, y = X[y != 2], y[y != 2]
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建一个Logistic回归模型
model = LogisticRegression()
# 在训练集上训练模型
model.fit(X_train, y_train)
# 在测试集上获取正例的预测概率
y_pred_proba = model.predict_proba(X_test)[:, 1]
# 计算ROC AUC值
roc_auc = roc_auc_score(y_test, y_pred_proba)
print("ROC AUC值:", roc_auc)代码中,加载了鸢尾花数据集,并使用LogisticRegression模型进行训练和预测,并使用roc_auc_score计算模型在测试集上的ROC AUC值。
mean_squared_error
用于评估回归模型预测结果的均方误差(Mean Squared Error,MSE)。均方误差是预测值与真实值之差的平方的均值,用于衡量模型预测结果的精度,MSE越小,表示模型拟合效果越好。
from sklearn.metrics import mean_squared_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
mse = mean_squared_error(y_true, y_pred)
print("均方误差:", mse)其中,y_true是真实的目标值,y_pred是模型预测的目标值。
使用mean_squared_error计算回归模型的均方误差:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 加载波士顿房价数据集
boston = load_boston()
X = boston.data
y = boston.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建一个线性回归模型
model = LinearRegression()
# 在训练集上训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("均方误差:", mse)代码中,加载了波士顿房价数据集,并使用线性回归模型进行训练和预测,并使用mean_squared_error计算模型在测试集上的均方误差。
r2_score
用于评估回归模型拟合优度的指标,也称为决定系数(Coefficient of Determination)。R²值可以理解为模型对因变量变化的解释程度,取值范围在0到1之间,越接近1表示模型拟合得越好。
from sklearn.metrics import r2_score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
r2 = r2_score(y_true, y_pred)
print("R²值:", r2)其中,y_true是真实的目标值,y_pred是模型预测的目标值。
使用r2_score计算回归模型的R²值:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
# 加载波士顿房价数据集
boston = load_boston()
X = boston.data
y = boston.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建一个线性回归模型
model = LinearRegression()
# 在训练集上训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算R²值
r2 = r2_score(y_test, y_pred)
print("R²值:", r2)这个示例加载了波士顿房价数据集,并使用线性回归模型进行训练和预测,并使用r2_score计算模型在测试集上的R²值。
特征工程
特征构建
PolynomialFeatures
用于生成原始特征的多项式组合的转换器,可以用于多项式回归。例如,对于输入特征 [a, b],PolynomialFeatures 可以生成 [1, a, b, a^2, ab, b^2]。这种转换可以让线性模型拟合非线性关系。
from sklearn.preprocessing import PolynomialFeatures
X = [[1, 2], [3, 4], [5, 6]]
poly = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly.fit_transform(X)
print(X_poly)这里的 degree 参数指定生成的多项式的最高次数,include_bias 参数用于指定是否包含截距(常数项)。
使用PolynomialFeatures将输入特征转换为多项式特征:
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
# 创建一些输入特征
X = np.array([[1, 2], [3, 4], [5, 6]])
# 创建一个PolynomialFeatures对象,将输入特征转换为二次多项式特征
poly = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly.fit_transform(X)
print("原始特征:\n", X)
print("多项式特征:\n", X_poly)这个示例创建了一个二维的输入特征数组 X,然后使用PolynomialFeatures将输入特征转换为二次多项式特征。
KBinsDiscretizer
用于将连续特征按照指定的区间数进行分箱(离散化)的转换器。分箱后,每个特征将被转换为一个多维离散特征,表示每个样本所属的箱子。这种转换可以帮助处理某些模型对连续特征的偏好,同时也可以减少数据中的噪声。
from sklearn.preprocessing import KBinsDiscretizer
X = [[-2, 1, -4, -1],
[-1, 2, -3, -0.5],
[ 0, 3, -2, 0.5],
[ 1, 4, -1, 2]]
# 创建一个KBinsDiscretizer对象,将特征分为3个区间
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')
X_discrete = est.fit_transform(X)
print(X_discrete)其中,n_bins指定了每个特征的分箱数,encode参数用于指定编码方式(ordinal表示使用整数编码),strategy参数指定了分箱的策略(uniform表示等宽分箱)。
使用KBinsDiscretizer将输入特征进行分箱:
import numpy as np
from sklearn.preprocessing import KBinsDiscretizer
# 创建一些连续特征
X = np.array([[1, -1, 2],
[2, 0, 0],
[0, 1, -1]])
# 创建一个KBinsDiscretizer对象,将特征分为3个区间
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')
X_discrete = est.fit_transform(X)
print("原始特征:\n", X)
print("分箱后的特征:\n", X_discrete)这个示例创建了一个二维的输入特征数组 X,然后使用KBinsDiscretizer将输入特征进行等宽分箱,分为3个区间。
特征交互
FeatureUnion
用于将多个特征处理流水线并行地合并为单个流水线的转换器。FeatureUnion可以将每个流水线生成的特征合并为一个特征集,常用于将不同类型的特征处理方法(如文本特征处理和数值特征处理)结合起来。
from sklearn.pipeline import FeatureUnion
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 假设有两个特征处理流水线:PCA和StandardScaler
pca = PCA(n_components=2)
scaler = StandardScaler()
# 创建FeatureUnion对象,合并两个特征处理流水线
combined_features = FeatureUnion([("pca", pca), ("scaler", scaler)])
# 使用合并后的特征处理流水线进行特征处理
X_features = combined_features.fit_transform(X)
print(X_features)使用FeatureUnion将两个特征处理流水线合并:
import numpy as np
from sklearn.pipeline import FeatureUnion
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 创建一些示例数据
X = np.array([[0, 1], [2, 3], [4, 5]])
# 创建两个特征处理流水线:PCA和StandardScaler
pca = PCA(n_components=1)
scaler = StandardScaler()
# 创建FeatureUnion对象,合并两个特征处理流水线
combined_features = FeatureUnion([("pca", pca), ("scaler", scaler)])
# 使用合并后的特征处理流水线进行特征处理
X_features = combined_features.fit_transform(X)
print("原始特征:\n", X)
print("合并后的特征:\n", X_features)代码中,创建了一个二维的输入特征数组 X,然后使用FeatureUnion将PCA和StandardScaler两个特征处理流水线合并,并将两个流水线生成的特征合并为一个特征集。
特征转换
FunctionTransformer
一个用于对数据集应用自定义转换函数的转换器。FunctionTransformer可以将任意函数应用于数据集的每个样本,例如用于特征工程或数据预处理。
from sklearn.preprocessing import FunctionTransformer
# 自定义转换函数,这里示例函数将每个元素取对数
def custom_func(X):
import numpy as np
return np.log1p(X)
# 创建FunctionTransformer对象,将自定义函数应用于数据集
transformer = FunctionTransformer(custom_func)
# 使用FunctionTransformer对象对数据集进行转换
X_transformed = transformer.fit_transform(X)
print(X_transformed)使用FunctionTransformer将对数转换应用于数据集的每个元素:
import numpy as np
from sklearn.preprocessing import FunctionTransformer
# 创建一些示例数据
X = np.array([[1, 2], [3, 4], [5, 6]])
# 自定义转换函数,这里示例函数将每个元素取对数
def custom_func(X):
return np.log1p(X)
# 创建FunctionTransformer对象,将自定义函数应用于数据集
transformer = FunctionTransformer(custom_func)
# 使用FunctionTransformer对象对数据集进行转换
X_transformed = transformer.fit_transform(X)
print("原始数据:\n", X)
print("转换后的数据:\n", X_transformed)代码中,创建了一个二维的输入特征数组 X,然后使用FunctionTransformer将对数转换应用于数据集的每个元素。
QuantileTransformer
用于将特征转换为服从均匀或正态分布的转换器。QuantileTransformer通过对每个特征的分位数进行映射来实现这一转换,可以有效地使数据归一化,并减少受异常值影响的影响。
from sklearn.preprocessing import QuantileTransformer
# 创建QuantileTransformer对象,将数据转换为服从均匀分布的形式
transformer = QuantileTransformer(output_distribution='uniform')
# 使用QuantileTransformer对象对数据进行转换
X_transformed = transformer.fit_transform(X)
print(X_transformed)使用QuantileTransformer将数据转换为服从均匀分布的形式:
import numpy as np
from sklearn.preprocessing import QuantileTransformer
# 创建一些示例数据
X = np.array([[1, 2], [3, 4], [5, 6]])
# 创建QuantileTransformer对象,将数据转换为服从均匀分布的形式
transformer = QuantileTransformer(output_distribution='uniform')
# 使用QuantileTransformer对象对数据进行转换
X_transformed = transformer.fit_transform(X)
print("原始数据:\n", X)
print("转换后的数据:\n", X_transformed)这个示例创建了一个二维的输入特征数组 X,然后使用QuantileTransformer将数据转换为服从均匀分布的形式。
模型解释
特征重要性
feature_importances_
feature_importances_ 是一些机器学习模型(如决策树、随机森林等)中的属性,用于表示每个特征对模型预测的重要性。对于决策树和随机森林等模型,feature_importances_ 属性可以帮助我们理解模型是如何做出预测的,以及哪些特征对预测的贡献最大。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 创建随机森林分类器
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X, y)
# 获取特征重要性
importances = clf.feature_importances_
# 将特征重要性可视化
plt.figure()
plt.bar(range(X.shape[1]), importances)
plt.xticks(range(X.shape[1]), ['sepal length', 'sepal width', 'petal length', 'petal width'], rotation=45)
plt.xlabel('Feature')
plt.ylabel('Importance')
plt.title('Feature Importances')
plt.show()这个示例使用随机森林模型训练了鸢尾花数据集,并使用 feature_importances_ 属性获取了特征的重要性,然后通过条形图展示了特征重要性。
决策路径可视化
plot_tree
plot_tree 是用于绘制决策树模型的函数,可以帮助我们可视化决策树的结构。plot_tree 函数通常与决策树模型(如 DecisionTreeClassifier 或 DecisionTreeRegressor)一起使用。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 创建决策树分类器
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X, y)
# 绘制决策树
plt.figure(figsize=(20, 10))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()这个示例使用 DecisionTreeClassifier 训练了鸢尾花数据集,并使用 plot_tree 函数绘制了决策树的结构图。在图中,每个节点表示一个特征或一个决策,箭头表示决策的方向,颜色表示节点所属的类别或决策路径的不纯度程度。
部分依赖图
plot_partial_dependence
plot_partial_dependence 是用于绘制偏依赖图的函数,可以帮助我们理解特征与模型预测之间的关系。偏依赖图显示了特征对模型预测的影响,可以帮助我们识别特征与预测之间的非线性关系。
from sklearn.datasets import load_boston
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.inspection import plot_partial_dependence
import matplotlib.pyplot as plt
# 加载波士顿房价数据集
boston = load_boston()
X = boston.data
y = boston.target
# 创建梯度提升回归模型
model = GradientBoostingRegressor()
# 绘制偏依赖图
plt.figure(figsize=(12, 6))
plot_partial_dependence(model, X, features=[5, 12], feature_names=boston.feature_names)
plt.subplots_adjust(top=0.9) # 调整子图之间的间距
plt.suptitle('Partial Dependence Plot') # 设置总标题
plt.show()这个示例使用 GradientBoostingRegressor 训练了波士顿房价数据集,并使用 plot_partial_dependence函数绘制了两个特征(第5个和第12个特征)的偏依赖图。偏依赖图显示了特征与预测之间的关系,可以帮助我们理解模型是如何利用这些特征进行预测的。
模型部署
模型保存与加载
joblib.dump
joblib.dump 是用于将 Python 对象保存到磁盘的函数,通常用于保存训练好的模型以备后续使用。与 Python 的内置 pickle 模块相比,joblib.dump 在处理大型 NumPy 数组时更有效率。
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from joblib import dump
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 创建随机森林分类器
clf = RandomForestClassifier(random_state=42)
clf.fit(X, y)
# 保存模型到文件
dump(clf, 'random_forest_model.joblib')这个示例使用 RandomForestClassifier 训练了鸢尾花数据集,并使用 joblib.dump 将训练好的模型保存到文件 random_forest_model.joblib。保存模型后,可以使用 joblib.load 函数重新加载模型:
from joblib import load
# 加载模型
clf = load('random_forest_model.joblib')
# 使用模型进行预测
y_pred = clf.predict(X)这样可以方便地在以后的时间加载模型并使用它进行预测。
最后
喜欢本文的朋友可以收藏、点赞、转发起来!

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)















 552
552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









