






大型语言模型(LLMs)时代协作策略是一个新兴研究领域,协作策略可以分为三种主要方法:合并(Merging)、集成(Ensemble)和合作(Cooperation)。
每个模型都有其独特的优势,这种多样性促进了这些模型之间的合作研究
尽管LLMs通过ICL和指令跟随在各种任务上表现出强大的多样性,但不同的LLMs在训练语料库和模型架构上的差异导致它们在不同任务上有不同的优势和劣势,有效的协作可以发挥它们的综合潜力。
对大型语言模型(LLM)协作的主要分类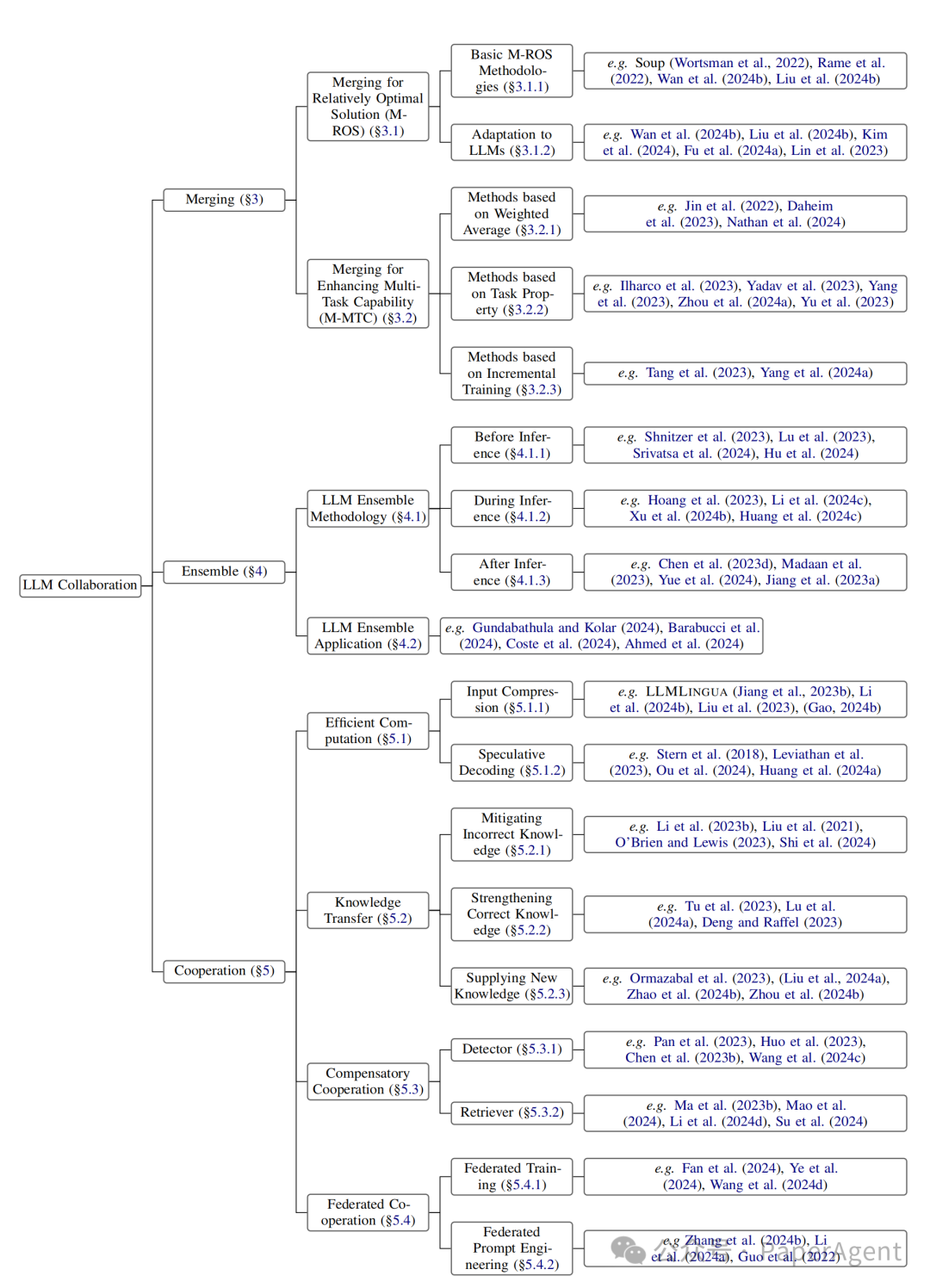
LLMs协作方法的分类:
合并(Merging):在参数空间中整合多个LLMs,创建一个统一的、更强大的模型。
集成(Ensemble):结合不同模型的输出以获得一致的结果。
合作(Cooperation):利用不同LLMs的多样化能力来实现特定目标,如高效计算或知识转移。
不同协作策略的示意图,图中的每种动物代表一个不同的大型语言模型(LLM)
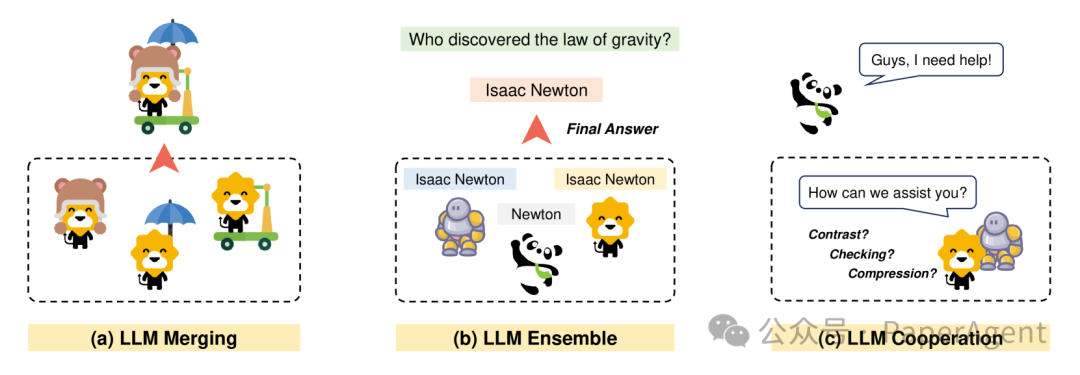
合并(Merging)方法
合并策略旨在通过在参数空间中整合多个模型来创建一个统一的、更强大的模型:
合并的目的:合并方法旨在解决单一模型可能存在的限制,如信息缺失、陷入局部最优或缺乏多任务能力。
合并为相对最优解(M-ROS):
描述了深度学习模型在训练过程中可能无法达到精确最优解的现象。
提出了通过合并多个模型的参数来获得更好的相对最优解的方法,包括简单平均和加权平均两种方法。
基本M-ROS方法:
简单平均:将多个微调模型的参数以相等的系数进行平均,以创建一个更强的模型。
加权平均:根据模型的重要性或质量分配不同的系数,以实现更好的合并。
合并以增强多任务能力(M-MTC):
通过合并具有不同能力的模型来构建具有多任务能力的统一模型的尝试。
介绍了基于加权平均、基于任务属性和基于增量训练的方法来解决模型参数空间中的分歧问题。
基于任务属性的合并方法:
定义了任务向量τt,这是一个指定预训练模型参数空间中方向的向量,该方向的移动可以提高特定任务的性能。
解决参数冲突的方法,包括参数冲突解决、减少参数方法和工具包(Toolkit)。
基于增量训练的方法:
提出了通过增量学习技术来恢复原始性能的方法,如寻找模型参数空间中的共享低维子空间以最小化任务干扰。
合并方法的局限性:
当前模型合并方法仅适用于具有相同架构和参数空间的模型,对于参数不兼容的模型,如LLaMA和QWen,当前的合并技术是无效的。
集成(Ensemble)方法
集成方法是一种通过结合多个模型的输出来提高整体性能的策略,探讨了在推理前、推理中和推理后进行集成的不同方法,以及它们如何影响推理速度、集成粒度和面临的限制。
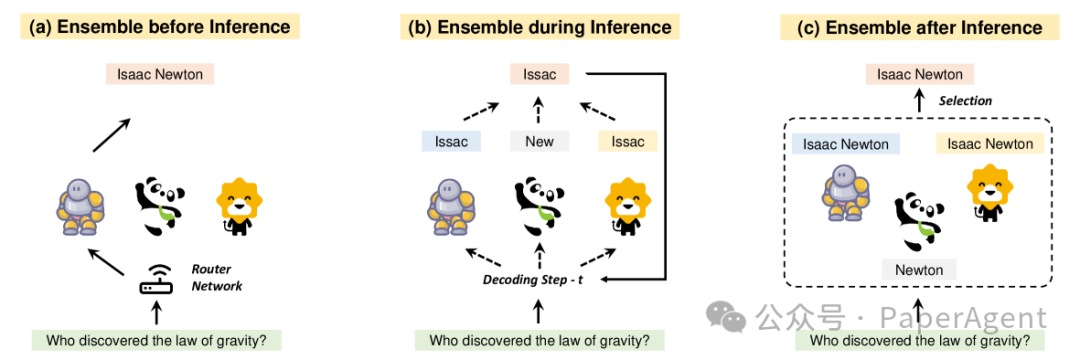
在推理之前(a)、推理期间(b)和推理之后(c)的大型语言模型(LLM)集成方法的示意图。
集成学习的重要性:与传统的分类任务不同,LLMs通常通过文本生成来解决各种任务,因此它们的输出更加灵活和自然。这要求为LLMs设计特定的集成方法。
LLM集成方法论:
根据集成发生的时间点,将集成方法分为三类:推理前(Before Inference)、推理中(During Inference)和推理后(After Inference)。
推理前的集成(Before Inference):
这类方法在推理前选择最适合特定输入样本的LLM,例如通过训练外部路由器来选择最优的LLM。
推理中的集成(During Inference):
在推理期间,LLMs自回归地生成令牌。这类方法在每个解码步骤中执行集成,以减少早期错误随时间累积的影响。
推理后的集成(After Inference):
这类方法在推理后结合生成的输出,例如构建LLM级联以减少仅使用大型LLMs的推理成本,或者从多个LLMs生成的候选中选择最佳输出。
推理速度:
集成方法通常会降低推理速度,尤其是在推理期间和推理后的集成方法。
集成粒度:
推理前和推理后的集成方法通常在示例级别工作,提供粗粒度集成;而推理中的集成方法在令牌级别工作,提供细粒度集成。
合作(Cooperation)方法
在大型语言模型(LLMs)的时代,协作策略不仅仅局限于简单的合并或集成。越来越多的研究正专注于通过LLMs之间的合作来解决各种问题或特定任务的更广泛方法,根据目标可以分为不同合作策略:
高效计算:通过输入压缩和推测性解码来加速模型推理。
大型语言模型(LLMs)与压缩模块合作进行输入压缩
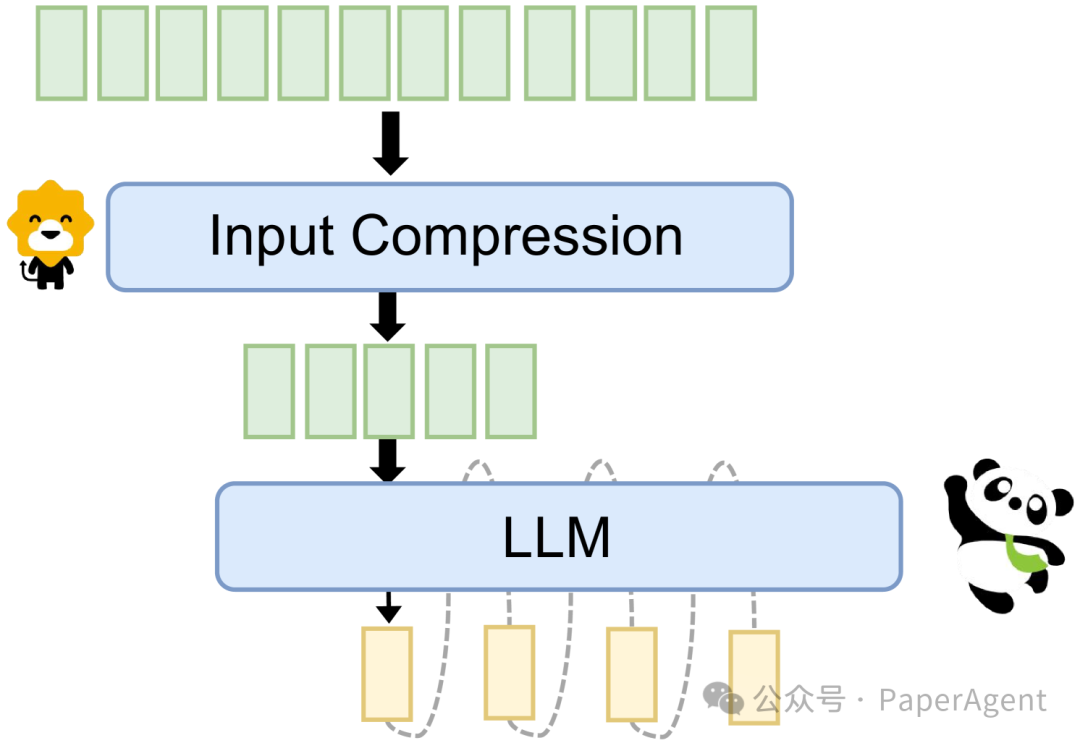
大型语言模型(LLMs)与草稿生成器合作进行推测性解码
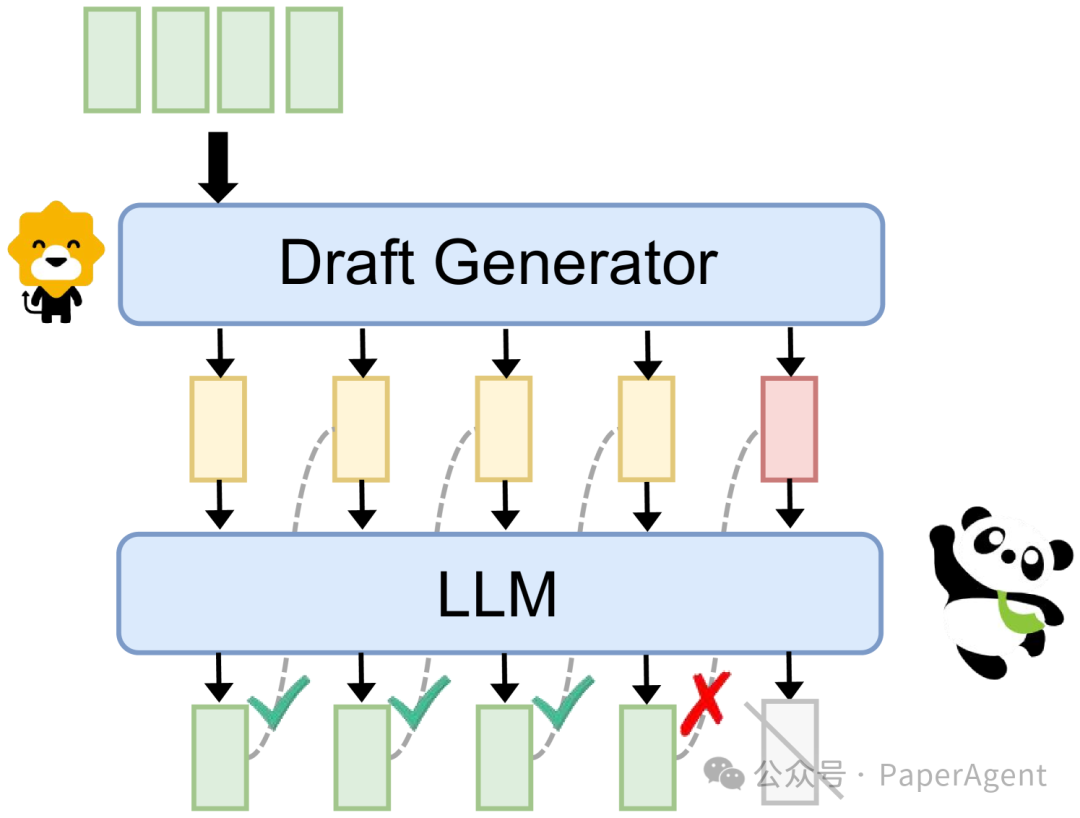
知识转移:通过合作在推理阶段转移知识,而不是涉及训练。
知识转移的重要性:由于直接训练大型模型获取新知识既困难又成本高昂,因此通过合作转移知识或能力成为一个重要的研究方向。
知识转移的方法:
几种主要的方法,包括减少错误知识(Mitigating Incorrect Knowledge)、加强正确知识(Strengthening Correct Knowledge)和提供新知识(Supplying New Knowledge)。
减少错误知识:
LLMs在生成文本时可能出现的幻觉(hallucinations)和偏见(bias)问题,并提出了对比解码(Contrastive Decoding, CD)等方法来减少这些问题。
加强正确知识:
如何通过额外的模型来增强解码输出的忠实度,例如使用属性控制文本生成(attribute-controlled text generation)和验证方法来提高输出与输入或指令的一致性。
提供新知识:
观察到输出逻辑的变化反映了LLMs能力的变化,并提出了调整输出逻辑来为大型模型提供从小模型中提取的新能力的方法。
补偿性合作:引入额外的控制器来补偿LLMs的不足,如检测器和检索器。


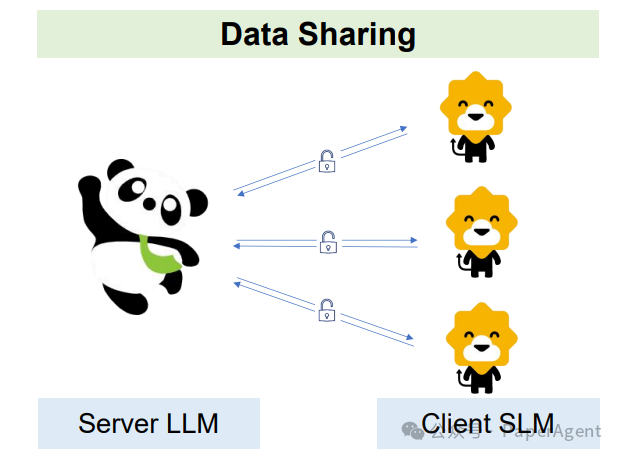
联邦合作:通过联邦学习和联邦提示工程来保护用户隐私并有效执行命令。
大型语言模型(LLMs)在联邦学习中与客户端模型合作
https://arxiv.org/abs/2407.06089
Merge, Ensemble, and Cooperate! A Survey on Collaborative Strategies in the Era of Large Language Models来源 | PaperAgent

















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









