







2021SC@SDUSC
文章目录
0、前言
本次博文主要记录在本周所看的关于深度学习自注意力机制(self-attention)、qkv部分的内容、以及深度学习中关于梯度的有关内容
1、深度学习的自注意力机制Self-Attention
1.1 自注意力机制的基本概念

对于自注意力机制来说,Q、K、V,即query、key、value三个矩阵均来自同一个输入,首先要计算Q与K之间的点乘,然后为了防止其结果过大,会除以一个尺度标度根号dk,其中dk为一个qurey和key向量的纬度。再利用Softmax操作将其结果归一化为概率分布,然后再乘以矩阵V就得到权重求和的表示。该操作可以表示为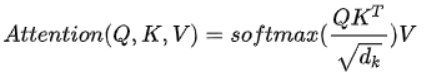
attention可以将qurey和key-value键值对的一组集合到输出,其中qurey、keys、values和输出都是向量,其中query和keys的维度均为dk,values的维度为dv,输出被计算为values的加权和,其中分配给每个value的权重由query与对应key的相似性函数计算得来。这种attention的形式被称为“Scaled Dot-Product Attention”。
1.2 qkv获得方式
*
- 将运算输出到z

2.2 自注意力机制代码分析
2.2.1 数据分析

flags

2.2.2 部分代码分析
def real_env_step_increment(hparams):
"""Real env step increment."""
return int(math.ceil(
hparams.num_real_env_frames / hparams.epochs
))
定义真实环境步长增量
def setup_directories(base_dir, subdirs):
"""Setup directories."""
base_dir = os.path.expanduser(base_dir)
tf.gfile.MakeDirs(base_dir)
all_dirs = {}
for subdir in subdirs:
if isinstance(subdir, six.string_types):
subdir_tuple = (subdir,)
else:
subdir_tuple = subdir
dir_name = os.path.join(base_dir, *subdir_tuple)
tf.gfile.MakeDirs(dir_name)
all_dirs[subdir] = dir_name
return all_dirs
设置目录
def make_relative_timing_fn():
start_time = time.time()
def format_relative_time():
time_delta = time.time() - start_time
return str(datetime.timedelta(seconds=time_delta))
def log_relative_time():
tf.logging.info("Timing: %s", format_relative_time())
return log_relative_time
创建一个函数,记录自创建以来的时间。
def random_rollout_subsequences(rollouts, num_subsequences, subsequence_length):
def choose_subsequence():
rollout = random.choice(rollouts)
try:
from_index = random.randrange(len(rollout) - subsequence_length + 1)
except ValueError:
return choose_subsequence()
return rollout[from_index:(from_index + subsequence_length)]
return [choose_subsequence() for _ in range(num_subsequences)]
从一组 rollout 中选择给定长度的随机帧序列
列车监督
def train_supervised(problem, model_name, hparams, data_dir, output_dir,
train_steps, eval_steps, local_eval_frequency=None,
schedule="continuous_train_and_eval"):
"""Train supervised."""
if local_eval_frequency is None:
local_eval_frequency = FLAGS.local_eval_frequency
exp_fn = trainer_lib.create_experiment_fn(
model_name, problem, data_dir, train_steps, eval_steps,
min_eval_frequency=local_eval_frequency
)
run_config = trainer_lib.create_run_config(model_name, model_dir=output_dir)
exp = exp_fn(run_config, hparams)
getattr(exp, schedule)()
从未解析的参数列表中设置 hparams 覆盖:
def set_hparams_from_args(args):
"""Set hparams overrides from unparsed args list."""
if not args:
return
hp_prefix = "--hp_"
tf.logging.info("Found unparsed command-line arguments. Checking if any "
"start with %s and interpreting those as hparams "
"settings.", hp_prefix)
pairs = []
i = 0
while i < len(args):
arg = args[i]
if arg.startswith(hp_prefix):
pairs.append((arg[len(hp_prefix):], args[i+1]))
i += 2
else:
tf.logging.warn("Found unknown flag: %s", arg)
i += 1
as_hparams = ",".join(["%s=%s" % (key, val) for key, val in pairs])
if FLAGS.hparams:
as_hparams = "," + as_hparams
FLAGS.hparams += as_hparams
2、全连接层
2.1 全连接层的定义与作用
- 全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。卷积层、激活函数和池化层等操作时将原始数据映射到隐层特征空间,而全连接层则起到将学到的“分布式特在实际使用中,全连接层可由卷积操作实现:对前一层时全连接的全连接层可以转化为卷积核为1*1的卷积;而前层是卷积层的全连接层可以转化为卷积核为hw的全局卷积,hw分别为前层卷积结果的高和宽。全连接最重要、最核心的就是矩阵的权重,我们通过深度学习对这一层的权重进行反复训练得到最好的权重矩阵W。
- 只用一层fully connected layer有时候没办法解决非线性问题,而如果有两层以上的fully connected layer就可以很好地解决非线性问题了。
2.2 部分代码分析
一个全连接的 NN 层。
n_units: int 层中的神经元数量
input_shape: tuple 层的预期输入形状。
对于密集层,单个指定输入特征数量的数字。如果是网络中的第一层,则必须指定。
class Dense(Layer):
"""A fully-connected NN layer.
Parameters:
-----------
n_units: int
The number of neurons in the layer.
input_shape: tuple
The expected input shape of the layer. For dense layers a single digit specifying
the number of features of the input. Must be specified if it is the first layer in
the network.
"""
def __init__(self, n_units, input_shape=None):
self.layer_input = None
self.input_shape = input_shape
self.n_units = n_units
self.trainable = True
self.W = None
self.w0 = None
def initialize(self, optimizer):
# Initialize the weights
limit = 1 / math.sqrt(self.input_shape[0])
self.W = np.random.uniform(-limit, limit, (self.input_shape[0], self.n_units))
self.w0 = np.zeros((1, self.n_units))
# Weight optimizers
self.W_opt = copy.copy(optimizer)
self.w0_opt = copy.copy(optimizer)
def parameters(self):
return np.prod(self.W.shape) + np.prod(self.w0.shape)
def forward_pass(self, X, training=True):
self.layer_input = X
return X.dot(self.W) + self.w0
def backward_pass(self, accum_grad):
# Save weights used during forwards pass
W = self.W
if self.trainable:
# Calculate gradient w.r.t layer weights
grad_w = self.layer_input.T.dot(accum_grad)
grad_w0 = np.sum(accum_grad, axis=0, keepdims=True)
# Update the layer weights
self.W = self.W_opt.update(self.W, grad_w)
self.w0 = self.w0_opt.update(self.w0, grad_w0)
# Return accumulated gradient for next layer
# Calculated based on the weights used during the forward pass
accum_grad = accum_grad.dot(W.T)
return accum_grad
def output_shape(self):
return (self.n_units, )
3、总结
- self-attention是transformer和bert、gpt的基础,掌握self-attention是学习深度学习算法的必经之路
- 深度神经网络模型一般都把全连接层作为最后一层用来做分类器,全连接层其实就是矩阵乘法,我们要学习的参数只有W一个。















 7098
7098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









