







 本文深入探讨微码与汇编语言的区别,解释为何高级语言编译成汇编而非直接转换为机器码,以及微码如何修正CPU硬件错误。通过理解微码和汇编的作用,揭示了CPU设计的灵活性和复杂性。
本文深入探讨微码与汇编语言的区别,解释为何高级语言编译成汇编而非直接转换为机器码,以及微码如何修正CPU硬件错误。通过理解微码和汇编的作用,揭示了CPU设计的灵活性和复杂性。
目录
1.微码和汇编语言的区别
微码:micrcode/ucode
微代码和汇编都是低级语言,但是微码比汇编更底层。微码和汇编都和硬件有着紧密的联系,但是对于同一产品系列的不同代产品来说,汇编可以完全相同,微代码可能有着巨大的区别,因为微代码是完全依赖于芯片内部的硬件连接。
对于同样一句C语言,在不同的处理器上会生成不同的汇编语言。每一条汇编语言的执行时间也许是一个或者两个时钟周期,甚至更多。微代码和汇编的关系,就像C 与汇编的关系,也就是说一条汇编也许会生成一条或多条微代码。所谓微代码,或者微指令,是处理器内部最小的操作原语,控制着诸如门电路(gates)开关等专门动作,和组成一条指令的微操作的序列。例如,对于一个加法"ADD"的简单动作,微代码可以决定接受哪两个寄存器或总线为输入,输出到什么总线或者寄存器里,标志寄存器要保存还是丢弃,根据条件进行跳转或者直接执行下一条微代码。一个内部只有8位宽的数据总线完全可以支持32位整数的汇编操作,就是因为有微代码。
微代码原来只是用来开发计算机的逻辑控制。古老的CPU往往都是“硬连线”,每个机器指令(加法,移动)都是由电路实现,虽然有着高性能的优点,但随着指令复杂度的增长,也带来了研发和DEBUG的困难,以及电路的复杂性。微代码的出现让CPU的设计者可以通过写一个微程序的方式来实现一条机器指令,而不是设计电路来实现它。在将来的开发设计过程中,微代码可以很容易地改变,硬件电路却不可更改,否则带来的将是巨大的商业损失。这种灵活的CPU设计导致了今天日益复杂的指令集。
微代码一般存储在处理器的 ROM,也就是芯片在工厂里生成的时候就被固化在里面的微程序。它实现了一系列底层硬件操作,而用户只要知道它外部的汇编接口和引脚情况以及寄存器即可,至于内部细节,对不起,这是商业机密。微代码也可以存储在处理器的RAM里,一般是一些非核心内容,或者升级更新指令集,更多的是一些勘误,也就是纠正 ROM里的代码错误。这也是为什么INTEL的芯片会有微代码升级的内容。这些都是BOOT LOADER,也就是PC BIOS的任务。
巧妙地运用微代码可以实现算法的优化和加速,较少访问内存的次数。因为对底层硬件的了解,可以在同一时钟周期做尽量多的并行的硬件操作,从而加快程序的执行。一个处理器 的核心往往是加法器和乘法器,两者是独立的部件,如果能在同一时钟周期同时操作加法和乘法,岂不是大大加快了执行速度吗?
2.汇编程序的编译过程
用汇编语言编写的源程序不能直接在其目标计算机上执行,必须通过翻译或汇编将其转换为可执行代码.
汇编-链接-执行周期:
- 编程者用文本编辑器(text editor)创建并编写一个文本文件,称之为源文件.
- 汇编器读取源文件,并生成目标文件(obj),即对程序的机器语言翻译.或者,它也会生成列表文件.
- 链接器读取并检查目标文件,以便发现该程序是否包含了任何对链接库中过程的调用.链接器从链接库中复制任何被请求的过程, 将它们与目标文件组合,以生成可执行文件.
- 操作系统加载程序将执行文件读入内存,CPU到该程序的起始地址,开始执行
3.编译的过程
1)简述编译程序与翻译程序、汇编程序的联系与区别。
翻译程序指把高级语言源程序翻译成机器语言源程序(目标代码)的软件。翻译程序有两种:一种是编译程序,它将高级语言源程序一次性全部翻译成目标程序,每次执行程序时,只要执行目标程序。另一种是解释程序,它的执行过程是翻译一句执行一句,并且不会生成目标程序。
编译程序是先完整编译后运行的程序,如C、C++等;解释程序是一句一句翻译且边翻译边执行的程序,如JavaScript、Python等。如图

汇编程序也是一种语言翻译程序,它把汇编语言源程序翻译成机器语言程序。
编译程序与汇编程序的区别:如果源语言是诸如C、C++、Java等“高级语言”,而目标语言是诸如汇编语言或机器语言之类的“低级语言”,这样的一个翻译程序称为编译程序。如果源语言是汇编语言,而目标语言是机器语言,这样的一个翻译程序称为汇编程序。
2)编译过程包括哪几个主要阶段及每个阶段的主要功能。
编译阶段也常常划分为两大步骤,分析步骤和综合步骤 分析步骤和综合步骤 分析步骤是指对源程序的分析 -线性分析(词法分析或扫描) -层次分析(语法分析) -语义分析 综合步骤是指后端的工作,为目标程序的生成而进行的综合。
3)简述解释程序与编译程序的区别。
编译程序能生成目标程序,而解释程序不能。编译程序是整体编译完了,再一次性执行。而解释程序是一边解释,一边执行。 解释一句后就提交计算机执行一句,并不形成目标程序。就像外语翻译中的“口译”一样,说一句翻一句,不产生全文的翻译文本。编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快。而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的。这是因为计算机不能直接认识并执行我们写的语句,它只能认识机器语言(是二进制的形式)。
编译器就是将"一种语言(通常为高级语言)"翻译为"另一种语言(通常为低级语言)"的程序。一个现代编译器的主要工作流程:源代码 (source code) → 预处理器 (preprocessor) → 编译器 (compiler) → 目标代码 (object code) → 链接器 (Linker) → 可执行程序 (executables)
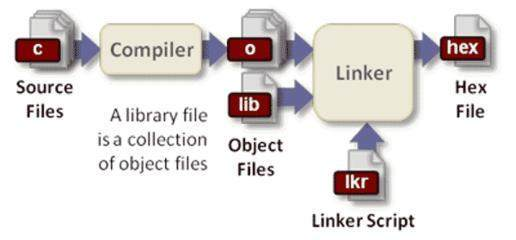
GCC(GNU Compiler Collection,GNU编译器集合),是一套由 GNU 开发的编程语言编译器。GCC 原名为 GNU C 语言编译器(GNU C Compiler),因为它原本只能处理 C语言。GCC 很快地扩展,变得可处理 C++。之后也变得可处理 Fortran、Pascal、Objective-C、Java, 以及 Ada与其他语言。本篇将以gcc编译器来讲述编译的全部过程。
编译过程
预处理(预处理器):预处理中会展开以#起始的行,试图解释为预处理指令(preprocessing directive) ,其中ISO C/C++要求支持的包括#if/#ifdef/#ifndef/#else/#elif/#endif(条件编译)、#define(宏定义)、#include(源文件包含)、#line(行控制)、#error(错误指令)、#pragma(和实现相关的杂注)以及单独的#(空指令)。将注释用空格替换(注意是替换不是删除)。
- 使用指令:gcc -E -o a.i a.c将a.c源文件预处理生成a.i文件,-E表示gcc的预处理参数
- 编译(编译器):将a.c文件或是a.i文件编译成为汇编语言的文件。
- gcc -S -o a.s a.c
- 汇编(汇编器):将a.c文件或是a.s文件汇编成为目标代码文件。
- gcc -c -o a.o a.c
- 链接(链接器):将a.c文件编译成为a.exe(linux中是a.out)文件,或是将a.o文件链接成为a.exe文件。
- gcc -o a.exe a.c或是 gcc -o a.exe a.o b.o c.o
链接的重要性
链接分为动态链接和静态链接。
静态链接:静态链接是由链接器在链接时将库的内容加入到可执行程序中的做法。链接器是一个独立程序,将一个或多个库或目标文件(先前由编译器或汇编器生成)链接到一块生成可执行程序。优点:① 代码装载速度快,执行速度略比动态链接库快;② 只需保证在开发者的计算机中有正确的.LIB文件,在以二进制形式发布程序时不需考虑在用户的计算机上.LIB文件是否存在及版本问题,可避免DLL地狱等问题。缺点:使用静态链接生成的可执行文件体积较大,包含相同的公共代码,造成浪费;动态链接:动态链接英文是Dynamic Linking需要解决空间浪费和更新困难这两个问题最简单的办法就是把程序的模块相互划分开来,形成独立的文件,而不再将他们静态的链接在一起。简单地讲,就是不对那些组成程序的目标文件进行链接,等到程序要运行时才进行链接。也就是说,把链接这个过程推迟到了运行时再进行,这就是动态链接(Dynamic Linking)的基本思想。优点:①更加节省内存并减少页面交换;② DLL文件与EXE文件独立,只要输出接口不变(即名称、参数、返回值类型和调用约定不变),更换DLL文件不会对EXE文件造成任何影响,因而极大地提高了可维护性和可扩展性;③不同编程语言编写的程序只要按照函数调用约定就可以调用同一个DLL函数;④适用于大规模的软件开发,使开发过程独立、耦合度小,便于不同开发者和开发组织之间进行开发和测试。缺点:使用动态链接库的应用程序不是自完备的,它依赖的DLL模块也要存在,如果使用载入时动态链接,程序启动时发现DLL不存在,系统将终止程序并给出错误信息。而使用运行时动态链接,系统不会终止,但由于DLL中的导出函数不可用,程序会加载失败;速度比静态链接慢。当某个模块更新后,如果新模块与旧的模块不兼容,那么那些需要该模块才能运行的软件,统统死掉。这在早期Windows中很常见。
高级语言为什么不直接编译成机器码,而编译成汇编代码?
1.一般的编译器,是先将高级语言转换成汇编语言(中间代码),然后在汇编的基础上优化生成OBJ目标代码,最后Link成可执行文件。
2.高级语言为什么不直接编译成机器码,而编译成汇编代码?
1)其中有一个好处是方便优化和调试,因为编译器也是工具,也是机器,毕竟是机器生成的程序,不可以非常完美的,而汇编是机器指令的助记 符,一个汇编指令就对应一条机器指令(特殊指令除外),调试起来肯定会比机器指令方便的方便,这样优化起来也方便。
2)高级语言只需要编译成汇编代码就可以了,汇编代码到机器码的转换是由硬件实现即可,有必要用软件实现这样分层可以有效地减弱编译器编写的复杂性,提高了效率.就像网络通 讯的实现需要分成很多层一样,主要目的就是为了从人脑可分析的粒度来减弱复杂性。
3)如果把高级语言的源代码直接编译成机器码的话,那要做高级语言到机器码之间的映射,如果这样做的话,每个写编译器的都必须熟练机 器码。这个不是在做重复劳动么?
代理服务器
简洁的说,当我们上网时,我们是和服务端建立了连接(利用我们和对方的IP地址),网络信息直接从服务端传递给了我们客户端。但是我国不允许我们在国内访问某些网站,于是我们可以使用代理服务器。原理就是当我们要访问某个特殊的网站时,我们可以先和代理服务器建立连接,再使用代理服务器访问那个网站,于是服务端的网络信息就传递给了代理服务器,然后代理服务器在把网络信息传递给我们客户端。这样就解决了不能访问某些网站的问题了。
有很多有静态编译到机器码的语言都是动态类型的啊。
(注意这里避开了“编译型语言”的说法。语言自身并没有编译型、解释型的区别,而是其实现可以用编译器或解释器的做法。)
汇编的重要性,或者编译的重要性不光是在于动态编译/静态编译需要花的时间,更重要的是,最终将高级语言/汇编语言翻译成不同的微码,由于微码的不同可能带来了性能的不一样,更甚者,一个汇编语言,由于解释不一样会翻译成不同的微码组合,也可能是带来性能的不一样
Microcode是什么?它为什么能修正CPU硬件错误?
现代CPU的指令解码器(Instruction Decode Unit ,IDU)大致分成两种:硬件指令解码器和微码指令解码器。
硬件指令解码器是完全由硬件连线(hardwired)完成的机器代码解码(是将机器码解码,例如下面的LOAD_A,是让硬件逻辑去识别是什么指令,然后相应标志位置1)。它是最原始的解码器,由有限状态机驱动,解码速度十分快。它现在还在很多精简指令CPU(RISC)中发挥作用。
以下的解码过程,是由控制单元(Control Unit)进行解码,控制单元也是由逻辑门组成的。比如控制单元要检查操作码是否为LOAD A,就需要以下电路,如果返回1,说明操作码就是LOAD A(所以对于指令表中的操作码,都需要对应的电路进行判断)。
控制单元检查操作码是否为LOAD A
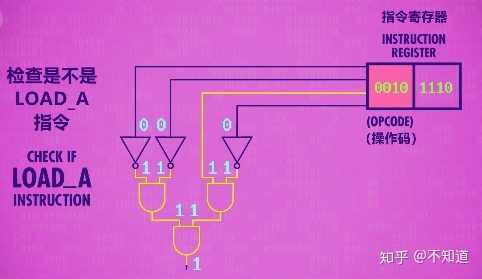
我们现在普遍使用的电脑X86 CPU,采用的是复杂指令集(CISC),指令很多,而且长短不一。如果所有的指令全部采用硬件解码,那将是一个不可能完成的任务。所以一条机器指令,将被拆解成数个类似RISC的精简微操作:微码,Micro-Ops,Microcode。而这些Micro-Ops,则可以完全被硬件执行。如下面这个例子:

那么每个X86指令会被分解成多少个micro-ops呢?这和该指令的复杂程度相关,很简单的指令甚至只有一个micro-ops,一般3个左右,复杂的可以4个以上。
这么做除了能化繁为简外,它的输出Micro-Ops作为可以执行的最小单位,可以被调度器Scheduler放入Pipeline中来提高指令的并行性:
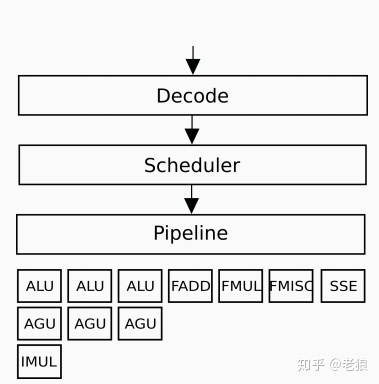
然后才会进入ALU,IMUL等等逻辑运算单元。它们基本是由逻辑门搭出来的。
一条机器指令,经过重重解码,才会流到逻辑运算单元。而这个decode的过程,让曾经泾渭分明的RISC和CISC两种CPU架构的界限变得模糊了起来。RISC CPU加入了越来越多的指令,很多CPU也不再仅仅是硬件指令解码,而对部分指令采取了微码解码方式。而CISC CPU因为加入了Micro-Ops,而在decode后端显示出了RISC的特性。从这个意义上来讲,以ARM为代表的RISC CPU和以X86为代表的CISCCPU在指令集层次很大程度融合了。
Microcode如何打补丁
既然一条指令会被解码成microcode/Micro-Ops,如果转换后的microcode出了问题,打个补丁就行了呗。原始的microcode映射是从一个ROM中来的:
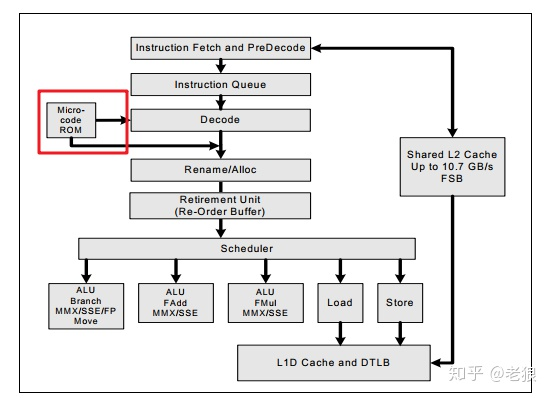
新设计了一块相对比较小的SRAM,它用来在该ROM上打补丁:

Patch的过程需要Microcode解码器硬件支持,基本是向量替换的方式。具体细节Intel和AMD并不同,而且是商业机密。

















 6127
6127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









