






1.PLSA模型
在讲解LDA模型之前,与LDA模型最为接近的便是下面要阐述的这个pLSA模型,给pLSA加上贝叶斯框架,便是LDA。
1.1什么是pLSA模型
我们假定一篇文档只由一个主题生成,可实际中,一篇文章往往有多个主题,只是这多个主题各自在文档中出现的概率大小不一样。比如介绍一个国家的文档中,往往会分别从教育、经济、交通等多个主题进行介绍。
假设你要写M篇文档,由于一篇文档由各个不同的词组成,所以你需要确定每篇文档里每个位置上的词。
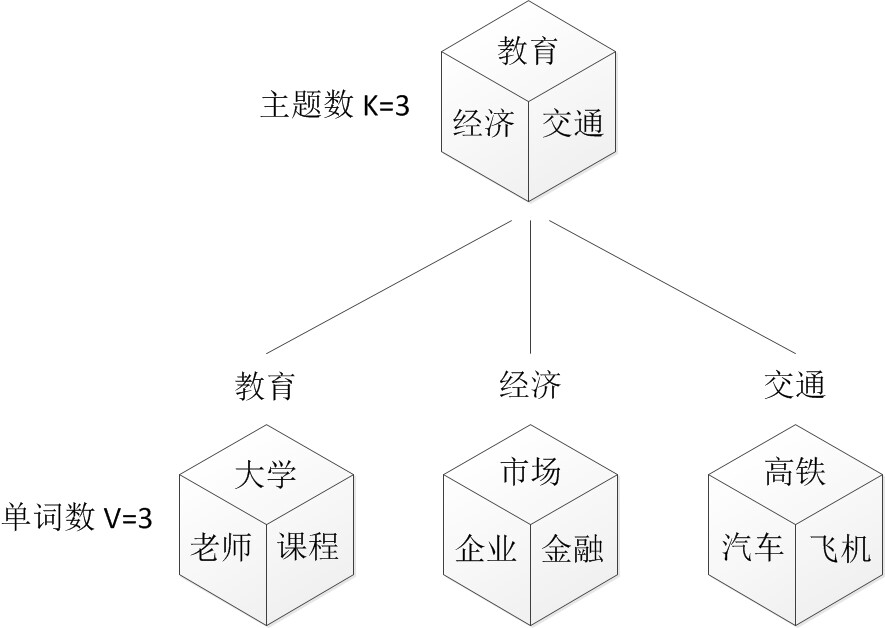
再假定你一共有K个可选的主题,有V个可选的词,咱们来玩一个扔骰子的游戏。
- 1. 假设你每写一篇文档会制作一颗K面的“文档-主题”骰子(扔此骰子能得到K个主题中的任意一个),和K个V面的“主题-词项” 骰子(每个骰子对应一个主题,K个骰子对应之前的K个主题,且骰子的每一面对应要选择的词项,V个面对应着V个可选的词)。
- 比如可令K=3,即制作1个含有3个主题的“文档-主题”骰子,这3个主题可以是:教育、经济、交通。然后令V = 3,制作3个有着3面的“主题-词项”骰子,其中,教育主题骰子的3个面上的词可以是:大学、老师、课程,经济主题骰子的3个面上的词可以是:市场、企业、金融,交通主题骰子的3个面上的词可以是:高铁、汽车、飞机。
- 2. 每写一个词,先扔该“文档-主题”骰子选择主题,得到主题的结果后,使用和主题结果对应的那颗“主题-词项”骰子,扔该骰子选择要写的词。
- 先扔“文档-主题”的骰子,假设(以一定的概率)得到的主题是教育,所以下一步便是扔教育主题筛子,(以一定的概率)得到教育主题筛子对应的某个词:大学。
- 上面这个投骰子产生词的过程简化下便是:“先以一定的概率选取主题,再以一定的概率选取词”。事实上,一开始可供选择的主题有3个:教育、经济、交通,那为何偏偏选取教育这个主题呢?其实是随机选取的,只是这个随机遵循一定的概率分布。比如可能选取教育主题的概率是0.5,选取经济主题的概率是0.3,选取交通主题的概率是0.2,那么这3个主题的概率分布便是{教育:0.5,经济:0.3,交通:0.2},我们把各个主题z在文档d中出现的概率分布称之为主题分布,且是一个多项分布。
- 同样的,从主题分布中随机抽取出教育主题后,依然面对着3个词:大学、老师、课程,这3个词都可能被选中,但它们被选中的概率也是不一样的。比如大学这个词被选中的概率是0.5,老师这个词被选中的概率是0.3,课程被选中的概率是0.2,那么这3个词的概率分布便是{大学:0.5,老师:0.3,课程:0.2},我们把各个词语w在主题z下出现的概率分布称之为词分布,这个词分布也是一个多项分布。
- 所以,选主题和选词都是两个随机的过程,先从主题分布{教育:0.5,经济:0.3,交通:0.2}中抽取出主题:教育,然后从该主题对应的词分布{大学:0.5,老师:0.3,课程:0.2}中抽取出词:大学。
- 3. 最后,你不停的重复扔“文档-主题”骰子和”主题-词项“骰子,重复N次(产生N个词),完成一篇文档,重复这产生一篇文档的方法M次,则完成M篇文档。
- 先扔“文档-主题”的骰子,假设(以一定的概率)得到的主题是教育,所以下一步便是扔教育主题筛子,(以一定的概率)得到教育主题筛子对应的某个词:大学。
反过来,既然文档已经产生,那么如何 根据已经产生好的文档反推其主题呢?这个利用看到的文档推断其隐藏的主题(分布)的过程(其实也就是产生文档的逆过程),便是主题建模的目的:自动地发现文档集中的主题(分布)。(通过EM算法或者Gibbs采样算法求解)
2.LDA模型
LDA就是在pLSA的基础上加层贝叶斯框架,即LDA就是pLSA的贝叶斯版本
2.1 pLSA跟LDA的对比:生成文档与参数估计
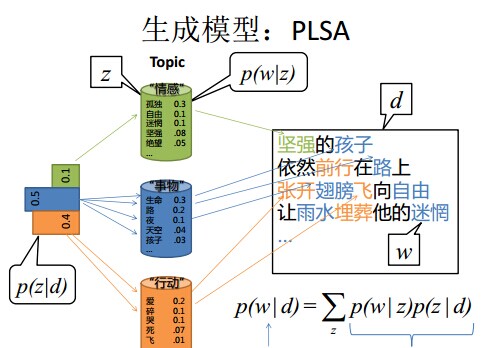
在pLSA模型中,我们按照如下的步骤得到“文档-词项”的生成模型:
- 按照概率
选择一篇文档
- 选定文档
后,确定文章的主题分布
- 从主题分布中按照概率
选择一个隐含的主题类别
- 选定
后,确定主题下的词分布
- 从词分布中按照概率
选择一个词
”
下面,咱们对比之前所述的LDA模型中一篇文档生成的方式是怎样的:
- 按照先验概率
- 从狄利克雷分布(即Dirichlet分布)
中取样生成文档
,换言之,主题分布
- 从主题的多项式分布
- 从狄利克雷分布(即Dirichlet分布)
中取样生成主题
对应的词语分布
,换言之,词语分布
- 从词语的多项式分布
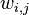
从上面两个过程可以看出,LDA在PLSA的基础上,为主题分布和词分布分别加了两个Dirichlet先验。
继续拿之前讲解PLSA的例子进行具体说明。如前所述,在PLSA中,选主题和选词都是两个随机的过程,先从主题分布{教育:0.5,经济:0.3,交通:0.2}中抽取出主题:教育,然后从该主题对应的词分布{大学:0.5,老师:0.3,课程:0.2}中抽取出词:大学。
而在LDA中,选主题和选词依然都是两个随机的过程,依然可能是先从主题分布{教育:0.5,经济:0.3,交通:0.2}中抽取出主题:教育,然后再从该主题对应的词分布{大学:0.5,老师:0.3,课程:0.2}中抽取出词:大学。
那PLSA跟LDA的区别在于什么地方呢?区别就在于:
- PLSA中,主题分布和词分布是唯一确定的,能明确的指出主题分布可能就是{教育:0.5,经济:0.3,交通:0.2},词分布可能就是{大学:0.5,老师:0.3,课程:0.2}。
- 但在LDA中,主题分布和词分布不再唯一确定不变,即无法确切给出。例如主题分布可能是{教育:0.5,经济:0.3,交通:0.2},也可能是{教育:0.6,经济:0.2,交通:0.2},到底是哪个我们不再确定(即不知道),因为它是随机的可变化的。但再怎么变化,也依然服从一定的分布,即主题分布跟词分布由Dirichlet先验随机确定。
pLSA中,主题分布和词分布确定后,以一定的概率(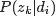
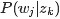
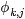
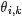
- 文档d产生主题z的概率,主题z产生单词w的概率都是两个固定的值。
- 举个文档d产生主题z的例子。给定一篇文档d,主题分布是一定的,比如{ P(zi|d), i = 1,2,3 }可能就是{0.4,0.5,0.1},表示z1、z2、z3,这3个主题被文档d选中的概率都是个固定的值:P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,如下图
但在贝叶斯框架下的LDA中,我们不再认为主题分布(各个主题在文档中出现的概率分布)和词分布(各个词语在某个主题下出现的概率分布)是唯一确定的(而是随机变量),而是有很多种可能。但一篇文档总得对应一个主题分布和一个词分布吧,怎么办呢?LDA为它们弄了两个Dirichlet先验参数,这个Dirichlet先验为某篇文档随机抽取出某个主题分布和词分布。
- 文档d产生主题z(准确的说,其实是Dirichlet先验为文档d生成主题分布Θ,然后根据主题分布Θ产生主题z)的概率,主题z产生单词w的概率都不再是某两个确定的值,而是随机变量。
- 还是举文档d具体产生主题z的例子。给定一篇文档d,现在有多个主题z1、z2、z3,它们的主题分布{ P(zi|d), i = 1,2,3 }可能是{0.4,0.5,0.1},也可能是{0.2,0.2,0.6},即这些主题被d选中的概率都不再认为是确定的值,可能是P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,也有可能是P(z1|d) = 0.2、P(z2|d) = 0.2、P(z3|d) = 0.6等等,而主题分布到底是哪个取值集合我们不确定(为什么?这就是贝叶斯派的核心思想,把未知参数当作是随机变量,不再认为是某一个确定的值),但其先验分布是dirichlet 分布,所以可以从无穷多个主题分布中按照dirichlet 先验随机抽取出某个主题分布出来。如下图所示
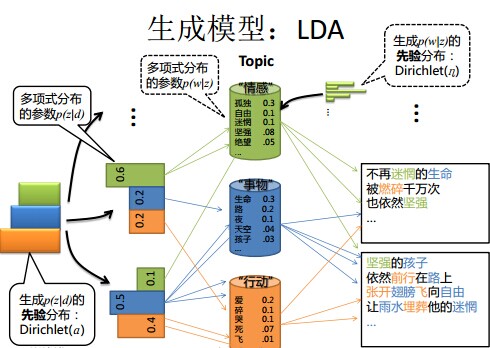
换言之,LDA在pLSA的基础上给这两参数( 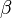
综上,LDA只是pLSA的贝叶斯版本,文档生成后,两者都要根据文档去推断其主题分布和词语分布(即两者本质都是为了估计给定文档生成主题,给定主题生成词语的概率),只是用的参数推断方法不同,在pLSA中用极大似然估计的思想去推断两未知的固定参数,而LDA则把这两参数弄成随机变量,且加入dirichlet先验。
















 1665
1665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









