







1. ClickHouse 简介

1.1 什么是 ClickHouse
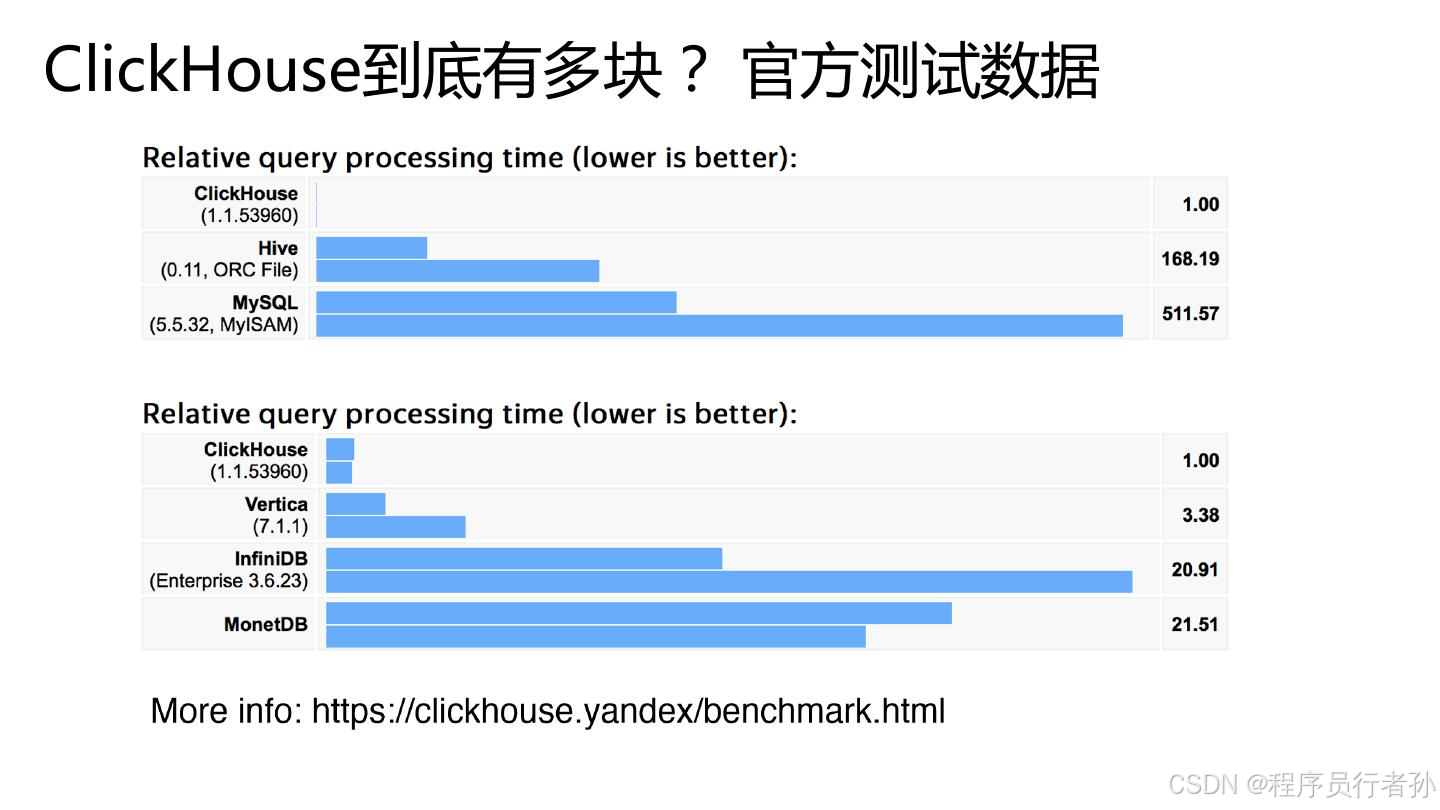
先来看看性能对比,会发现mysql弱爆了~
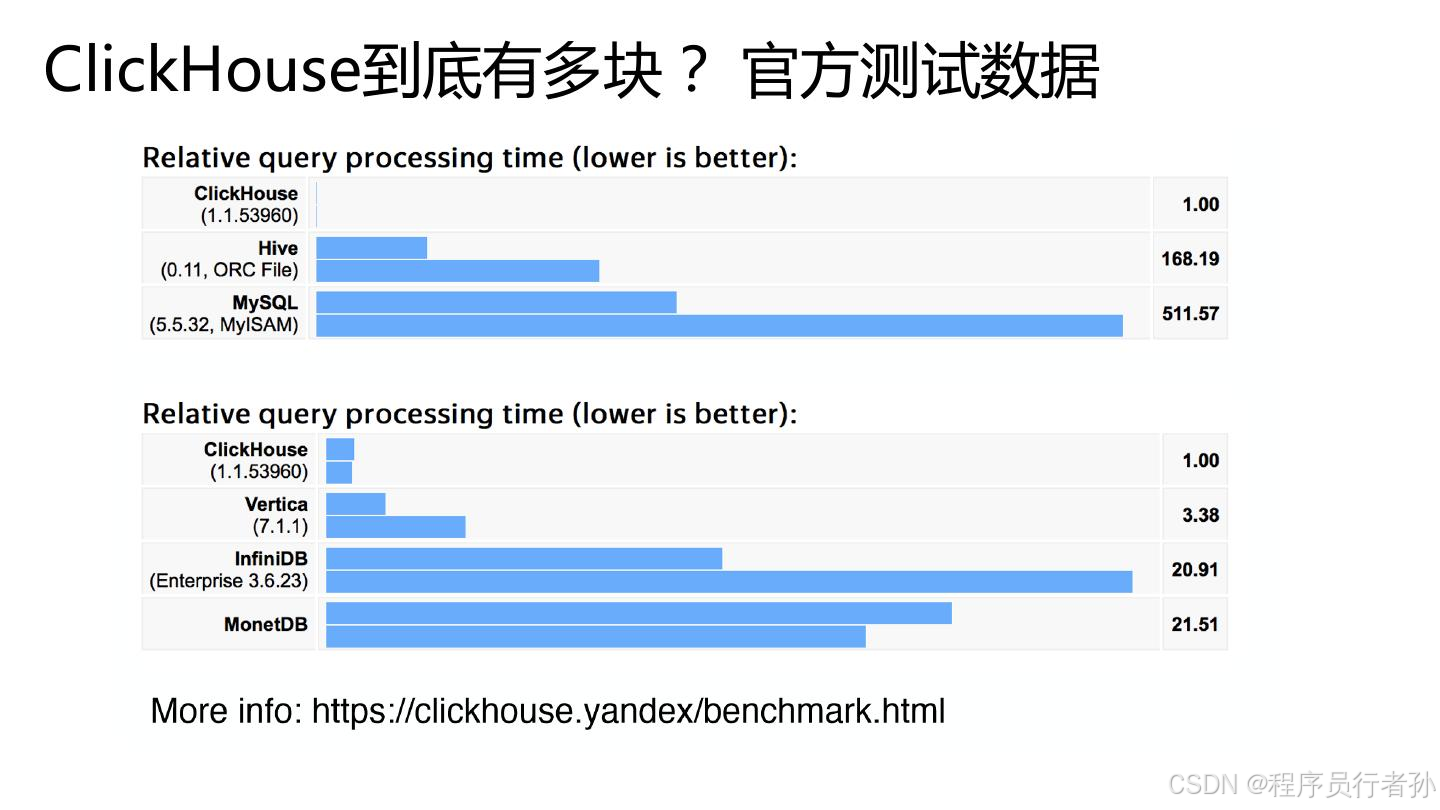
ClickHouse是一款高性能的列式数据库管理系统(DBMS),主要用于在线分析处理(OLAP)。由俄罗斯搜索引擎公司Yandex基于自身大规模数据聚合和分析的需求而开发,并在2016年开源。ClickHouse以其卓越的查询性能在大数据领域迅速获得了广泛的关注和应用。
ClickHouse支持SQL查询语言,能够在实时生成分析数据报告的同时,保持对大数据量级的快速响应。它采用C++语言编写,以列式存储为核心,优化了数据的压缩和读取效率,特别适合于读取大量行但仅需少数列的场景。
1.2 ClickHouse 的特点
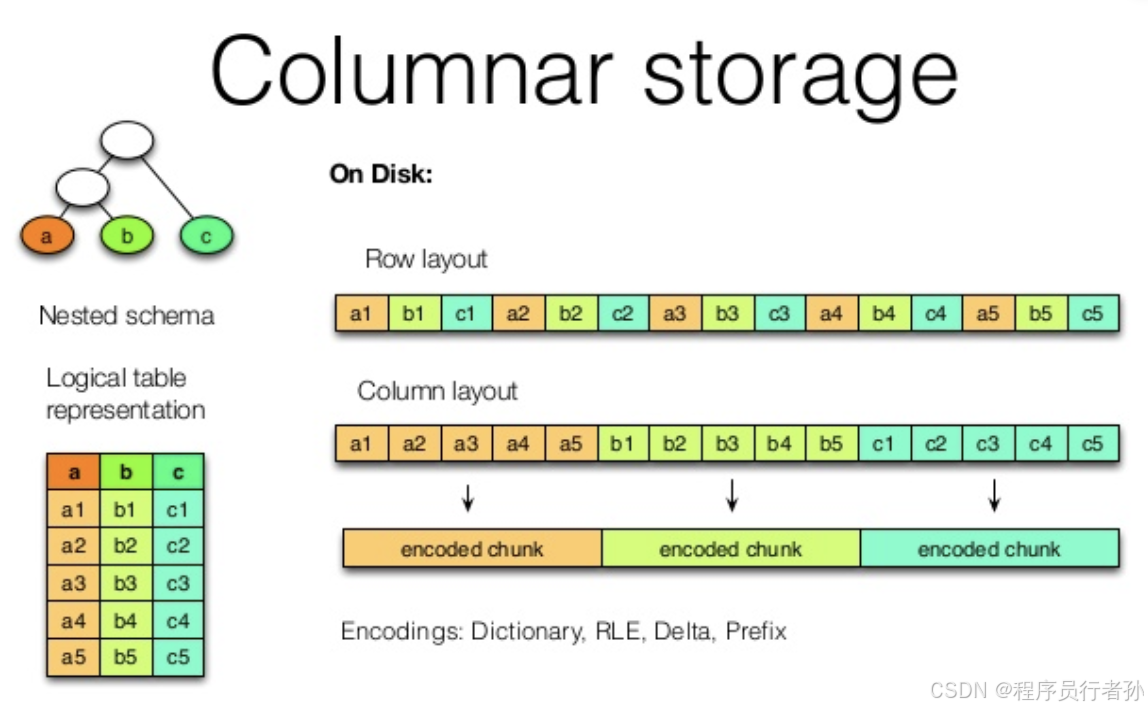
ClickHouse的设计理念和实现细节赋予了其独特的性能优势,以下是ClickHouse的几个核心特点:
-
列式存储:ClickHouse将数据按列存储,这样可以只读取查询所需的列,减少I/O消耗,提高查询效率。
-
数据压缩:ClickHouse提供了多种压缩算法,针对不同数据类型优化,大幅度减少了存储空间和I/O传输数据量。
-
向量化查询执行:ClickHouse利用现代CPU的SIMD指令集,通过向量化查询执行引擎,提高了数据处理的并行度和效率。
-
实时数据更新:ClickHouse支持实时数据写入和更新,无需锁定整个表,即可进行数据的持续写入。
-
索引和主键:ClickHouse允许定义主键,通过主键对数据进行排序,加速了特定值或范围的查找。
-
分布式处理:ClickHouse支持跨多个服务器的分布式查询处理,提高了查询的并行性和扩展性。
-
近似计算:ClickHouse提供了多种近似计算函数,允许在可接受的精度损失下加速查询。
-
多核心并行处理:ClickHouse能够充分利用服务器上的多核心资源,实现查询的并行处理。
-
支持SQL:ClickHouse支持大部分SQL标准,使得从其他SQL数据库迁移到ClickHouse变得容易。
-
自适应连接算法:ClickHouse支持自定义JOIN操作,根据数据大小自动选择最佳的连接算法。
代码分析部分:
-- 创建一个简单的表
CREATE TABLE example_table
(
`date` Date,
`event_date` Date,
`timestamp` DateTime,
`int` Int32,
`float` Float32,
`decimal` Decimal32(2),
`str` String,
`arr` Array(Int32),
`tuple` Tuple(Int16, String)
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(date)
ORDER BY (int, float);
-- 插入数据
INSERT INTO example_table VALUES
('2024-01-01', '2024-01-01', now(), 42, 3.14, 10.0, 'Hello, world', [1, 2], (1, 'example'));
-- 查询数据
SELECT *
FROM example_table
WHERE int = 42;
以上代码展示了如何在ClickHouse中创建表、插入数据和查询数据。MergeTree是ClickHouse中常用的存储引擎,支持数据的自动合并和排序。PARTITION BY和ORDER BY子句定义了数据的分区和排序策略,这对于优化查询性能至关重要。
2. ClickHouse 架构原理
2.1 列式存储
ClickHouse的列式存储是其核心特性之一,这一设计使得数据存储和查询更加高效。在列式存储中,数据不是按行存储,而是按列存储,即表中的每个字段(列)都有自己独立的存储空间。
-
数据读取优化:在OLAP场景中,查询通常只需要读取表中的少数几个列。列式存储允许ClickHouse仅读取查询所需的列,而不是整行数据,从而显著减少I/O消耗和提高查询效率。据统计,与行式存储相比,列式存储可以减少20倍的I/O消耗。
-
数据压缩:由于列式存储中相同类型的数据被连续存储,这使得数据压缩更加高效。ClickHouse提供了多种压缩算法,如LZ4、ZSTD等,这些算法能够针对列数据的特点进行优化,进一步降低存储空间和I/O传输数据量。在Yandex.Metrica的生产环境中,数据总体的压缩比可以达到8:1。
-
存储结构:ClickHouse中的数据文件和索引文件是分开存储的。每个列的数据被存储在单独的文件中,而主键索引则用于快速定位数据。这种设计使得数据插入和查询更加高效,尤其是在大规模数据集上。
2.2 MPP 架构
ClickHouse采用MPP(Massively Parallel Processing)架构,这是一种分布式处理架构,允许ClickHouse在多个节点上并行处理查询。

-
无共享架构:ClickHouse的MPP架构是一种无共享(Share-Nothing)架构,每个节点独立处理自己的数据,节点之间通过高速网络互联。这种架构使得ClickHouse能够线性扩展,理论上可以无限扩展节点数量。
-
分布式查询处理:在MPP架构下,ClickHouse能够将查询任务分解为多个子任务,并在多个节点上并行执行。每个节点完成自己的子任务后,结果被汇总到发起查询的节点上。这种设计使得ClickHouse在处理大规模数据集时能够实现快速响应。
-
容错和高可用:ClickHouse的MPP架构提供了容错和高可用性。即使某个节点发生故障,其他节点仍然可以继续处理查询,从而保证服务的连续性。
2.3 向量化查询执行
ClickHouse的向量化查询执行是其高性能的关键因素之一。通过利用现代CPU的SIMD指令集,ClickHouse能够一次性处理数据列的多个值,而不是逐行处理。
-
SIMD指令集:ClickHouse利用CPU的SIMD(Single Instruction Multiple Data)指令集,通过向量化执行引擎,可以一次性对多个数据进行操作,大大提高了数据处理的并行度和效率。
-
查询性能提升:向量化查询执行通常能够带来数倍的性能提升。例如,在处理聚合查询时,ClickHouse可以一次性处理整个数据列,而不是对每一行单独执行聚合函数,这显著减少了函数调用次数和CPU Cache miss。
-
代码生成:ClickHouse还支持运行时代码生成,为特定的查询动态生成优化的代码。这种方法可以进一步优化查询性能,尤其是在复杂的查询场景下。
以上分析展示了ClickHouse的架构原理,包括其列式存储、MPP架构和向量化查询执行,这些特性共同为ClickHouse的高性能和高效率提供了坚实的基础。
3. ClickHouse 核心技术
3.1 MergeTree 家族
ClickHouse的核心技术之一是其MergeTree家族的存储引擎,这些引擎被设计用于处理大规模数据集,并且支持高效的数据插入和查询操作。
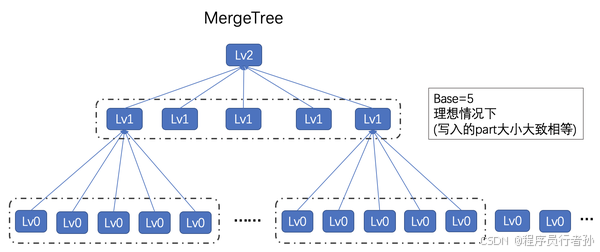
-
MergeTree:基础存储引擎,按主键排序数据,支持数据分区,允许数据片段的自动合并,优化存储并提高查询效率。MergeTree不保留数据的删除标记,而是通过数据合并来物理删除过期或无用的数据。
CREATE TABLE simple_merge_tree ( `date` Date, `value` Int32 ) ENGINE = MergeTree() PARTITION BY toYYYYMM(date) ORDER BY value; -
ReplacingMergeTree:在MergeTree的基础上增加了数据去重的功能,通过版本控制来处理数据更新和删除操作。当新数据与旧数据的主键冲突时,旧数据会被新数据替换。
CREATE TABLE replacing_merge_tree ( `date` Date, `value` Int32 ) ENGINE = ReplacingMergeTree() PARTITION BY toYYYYMM(date) ORDER BY value; -
SummingMergeTree:适用于需要对数据进行实时聚合的场景,如财务数据的累计求和。它会将具有相同主键的数据行合并,并计算它们的总和。
CREATE TABLE summing_merge_tree ( `date` Date, `value` Int32 ) ENGINE = SummingMergeTree() PARTITION BY toYYYYMM(date) ORDER BY value; -
AggregatingMergeTree:与SummingMergeTree类似,但适用于预先聚合的数据模型。它允许在数据写入时就进行聚合,减少了查询时的计算量。
CREATE TABLE aggregating_merge_tree ( `date` Date, `value` Int32 ) ENGINE = AggregatingMergeTree() PARTITION BY toYYYYMM(date) ORDER BY value; -
CollapsingMergeTree:用于处理事件的时间序列数据,如用户行为日志。它能够在数据合并时折叠掉连续的重复事件。
CREATE TABLE collapsing_merge_tree ( `date` Date, `value` Int32 ) ENGINE = CollapsingMergeTree() PARTITION BY toYYYYMM(date) ORDER BY value; -
VersionedCollapsingMergeTree:是CollapsingMergeTree的扩展,支持版本控制,能够在数据合并时处理更复杂的逻辑。
CREATE TABLE versioned_collapsing_merge_tree ( `date` Date, `value` Int32 ) ENGINE = VersionedCollapsingMergeTree() PARTITION BY toYYYYMM(date) ORDER BY value; -
GraphiteMergeTree:专为Graphite监控数据设计,支持Graphite的数据格式和聚合规则。
CREATE TABLE graphite_merge_tree ( `date` Date, `value` Int32 ) ENGINE = GraphiteMergeTree() PARTITION BY toYYYYMM(date) ORDER BY value;
3.2 数据压缩
ClickHouse通过数据压缩技术显著减少了存储空间的需求和I/O传输数据量,提高了查询效率。
-
压缩算法:ClickHouse支持多种压缩算法,包括LZ4、ZSTD、LZ4HC等,用户可以根据数据特性和查询需求选择合适的压缩算法。
CREATE TABLE compression_example ( `date` Date, `value` Int32 ) ENGINE = MergeTree() PARTITION BY toYYYYMM(date) ORDER BY value SETTINGS storage_compression_method = 'zstd'; -
压缩效果:根据Yandex的测试,使用LZ4压缩算法时,数据压缩比可以达到8:1,显著减少了存储成本。
3.3 索引与分区
索引和分区是ClickHouse提高查询性能的两个关键技术。
-
索引:ClickHouse使用稀疏索引,通过主键对数据进行排序,加速了特定值或范围的查找。索引以索引粒度(index_granularity)为单位,ClickHouse默认值是8192,意味着每8192行数据会有一个索引标记。
CREATE TABLE index_example ( `date` Date, `value` Int32 ) ENGINE = MergeTree() PARTITION BY toYYYYMM(date) ORDER BY value SETTINGS index_granularity = 8192; -
分区:ClickHouse允许对数据进行水平分区,通常根据时间字段进行分区,如按月、按日。查询时,ClickHouse可以跳过非相关的分区,减少数据扫描量。
CREATE TABLE partition_example ( `date` Date, `value` Int32 ) ENGINE = MergeTree() PARTITION BY toYYYYMM(date) ORDER BY value; -
查询优化:通过索引和分区,ClickHouse可以显著减少查询时需要扫描的数据量,提高查询性能。例如,查询特定日期范围的数据时,ClickHouse只需扫描相关的分区,而不是整个表。
4. ClickHouse 应用场景
4.1 适用场景分析
ClickHouse因其卓越的性能和独特的设计,适用于多种数据处理场景,以下是几个主要的应用场景:
-
大规模数据聚合:ClickHouse的列式存储和向量化查询执行使其在处理大规模数据聚合时表现出色。例如,在网络流量分析和金融交易数据汇总中,ClickHouse能够快速生成实时分析报告。
-
实时分析和监控:由于ClickHouse支持实时数据更新和低延迟查询,它非常适合用于实时分析和监控系统。例如,它可以用于监控云服务的性能指标,快速发现和响应潜在问题。
-
商业智能(BI):ClickHouse的高压缩率和快速查询能力使其成为商业智能平台的理想选择。企业可以利用ClickHouse进行复杂的数据分析,以支持决策制定。
-
日志分析:ClickHouse常用于日志数据的分析,能够处理和分析大量的日志数据,帮助企业从中提取有价值的信息。
-
物联网(IoT):在IoT场景中,ClickHouse可以处理来自传感器和设备的大量时序数据,支持设备监控和性能分析。
-
数据仓库:ClickHouse可以作为数据仓库的存储和分析引擎,提供高效的数据查询和报表生成功能。
4.2 性能测试与对比
为了评估ClickHouse的性能,我们可以通过一系列的性能测试和与其他数据库系统的对比来展示其优势。
-
单表查询性能:在单表查询测试中,ClickHouse展现出了极高的吞吐量。例如,在处理含有44个字段的大表时,ClickHouse的查询速度远远超过Amazon Redshift等其他OLAP数据库。
-
数据写入性能:ClickHouse的写入性能同样出色。在最佳情况下,使用tab-separated格式写入MergeTree表的速度可以达到50到200MB/s,这意味着每秒可以写入数十万行数据。
感谢看官老爷们看到这里,简历投递后如同石沉大海般毫无回音而感到失落?来这里看看
祝大家学习顺利~
如有任何错误,恳请批评指正~~



















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











