







吃瓜学习第二天(第三章)
学习书籍:西瓜书、南瓜书
学习视频:https://www.bilibili.com/video/BV1Mh411e7VU?p=3
3 线性模型
文章架构,1、线性模型基本形式 ,2、线性回归公式推导,3、线性回归代码
3.1 基本形式
机器学习三要素:
-
模型:根据具体问题,确定假设空间 (即 y = k x + b y=kx+b y=kx+b还是 y = k x 2 + b y=kx^2+b y=kx2+b,归根到底就是拟合方式)
-
策略:根据评价标准,确定选取最优模型的策略(通常会产出一个“损失函数”)
-
算法:求解损失函数,确定最优模型
线性模型:
f
(
x
)
=
w
T
x
+
b
f(x)=w^Tx+b
f(x)=wTx+b
3.2 线性回归
目的:学得一个线性模型,尽可能的准确地预测实值输出标记,即求得w,b
公式推导: 线性回归的最小二乘估计和极大似然估计
3.2.1 最小二乘估计
最小二乘法:基于均方误差最小化来进行模型求解的方法
目的:试图找到一条直线,使得所有样本到直线上的欧式距离之和最小,即 a r g m i n E ( w , b ) arg min E(w,b) argminE(w,b)
公式:
E
(
w
,
b
)
=
∑
i
=
1
m
(
y
i
−
f
(
x
i
)
)
2
=
∑
i
=
1
m
(
(
y
i
−
(
w
x
i
+
b
)
)
2
=
∑
i
=
1
m
(
y
i
−
w
x
i
−
b
)
2
E(w,b) = \sum_{i=1}^{ m }{(y_i − f(x_i))^2} \\ = \sum_{i=1}^{ m }{((y_i − (wx_i + b))^2 }\\ = \sum_{i=1}^{ m }{(y_i − wx_i − b)^2 }
E(w,b)=i=1∑m(yi−f(xi))2=i=1∑m((yi−(wxi+b))2=i=1∑m(yi−wxi−b)2
3.2.2极大似然估计
一、极大似然估计概念:
-
用途:估计概率分布的参数值 ,即求未知参数θ
-
方法:对于离散型(连续型)随机变量X,假设其概率质量函数为P(x;θ)(概率密度
函数为p(x; θ)),其中θ为待估计的参数值(可以有多个)。现有 x 1 , x 2 , x 3 , . . . , x n x_1, x_2, x_3, ..., x_n x1,x2,x3,...,xn是
来自X的n个独立同分布的样本,它们的联合概率为
-
公式:
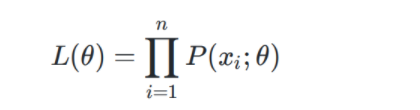
式中,其中 x 1 , x 2 , x 3 , . . . , x n x_1, x_2, x_3, ..., x_n x1,x2,x3,...,xn是已知量,θ是未知量,L(θ)为样本的似然函数;目的:即找到L(θ)最大时的θ
-
如何求解θ:
第一步,写出随机变量的概率密度函数(X服从某个正态分布,X~N( μ , σ 2 \mu,\sigma^2 μ,σ2)):
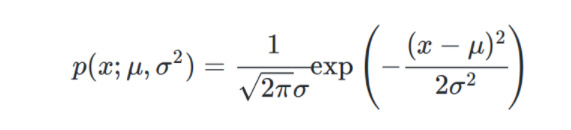
第二步,写出似然函数 :
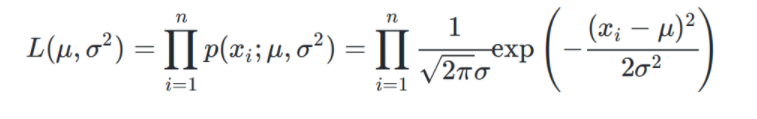
第三步,求出使得似然函数最大的 μ , σ 2 \mu,\sigma^2 μ,σ2 :为了便于求解,引入对数似然函数 l n L ( μ , σ 2 ) lnL(\mu,\sigma^2) lnL(μ,σ2):

二、线性回归带入极大似然估计: -
第一步,假设线性回归模型:
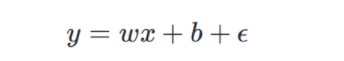
其中 为不受控制的随机误差,通常假设其服从均值为0的正态分布~N( 0 , σ 2 0,\sigma^2 0,σ2) -
第二步,写出概率密度函数:
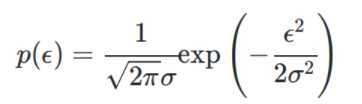
等价替换:
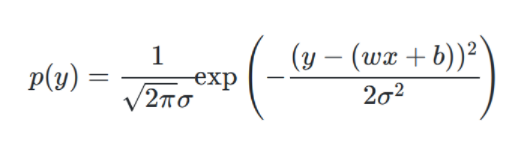
-
第三步,代入,并求出误差公式(损失函数):

-
第四步,求解:
求解 和 其本质上是一个多元函数求最值(点)的问题,更具体点是凸函数求最值的问题
1.证明上式是凸函数:
-
如果 Hessian(海塞)矩阵是半正定的,则是凸函数。
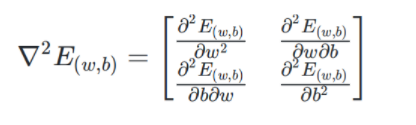
若实对称矩阵的所有顺序主子式均为非负,则该矩阵为半正定矩阵。
2.利用凸函数的思路求解:

-















 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









