






目录
因为这两天做课题需要用到微博中的帖子、用户评论等数据,怎么办呢?自己又是个菜鸡,写个数据采集的代码还不够功夫的,并且还很容易被封![]() ,于是便想有没有专门采集微博数据的项目,别说还真找到了个,WeiboSpider,经过一番研究,终于顺利采到数据,心里别提多感激这个项目的大佬了,要不然关数据都不知道够我折腾多久...下面就详细介绍我用WeiboSpider项目的数据采集的过程。
,于是便想有没有专门采集微博数据的项目,别说还真找到了个,WeiboSpider,经过一番研究,终于顺利采到数据,心里别提多感激这个项目的大佬了,要不然关数据都不知道够我折腾多久...下面就详细介绍我用WeiboSpider项目的数据采集的过程。
一、WeiboSpider运行环境的配置
1.conda安装虚拟环境
conda create -n weibo python=3.9.0 -y创建名为weibo的虚拟环境,指定python的版本为3.9.0
2.激活weibo环境
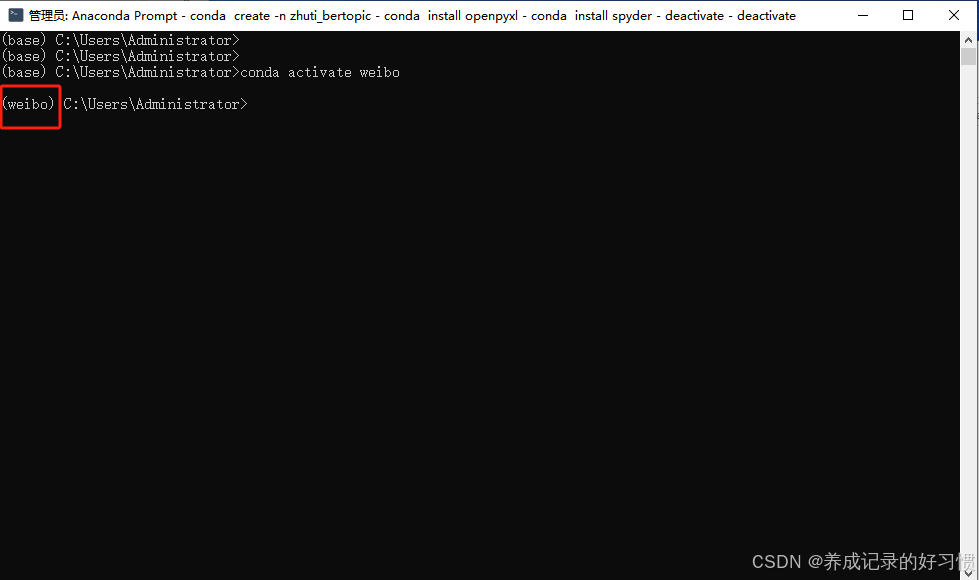
conda activate weibo激活后,conda的cmd命令提示符前面的括号中的名称会由base变为weibo:
3.conda命令安装Scrapy和依赖
conda install scrapy -c conda-forge安装过程可能比较缓慢,稍微等一等,并且此时的scrapy版本为2.11.2
需要注意:最好使用conda命令安装,使用pip命令可能会出现依赖不兼容的错误!
4.再安装python-dateutil模块
pip install python-dateutil -i https://pypi.tuna.tsinghua.edu.cn/simple我这儿 conda install python-dateutil 安不上,就用了pip命令。
经过以上过程后,环境便配置完毕!接下来就利用WeiboSpider项目进行数据采集!
二、用WeiboSpider采集微博数据
1.下载WeiboSpider到本地
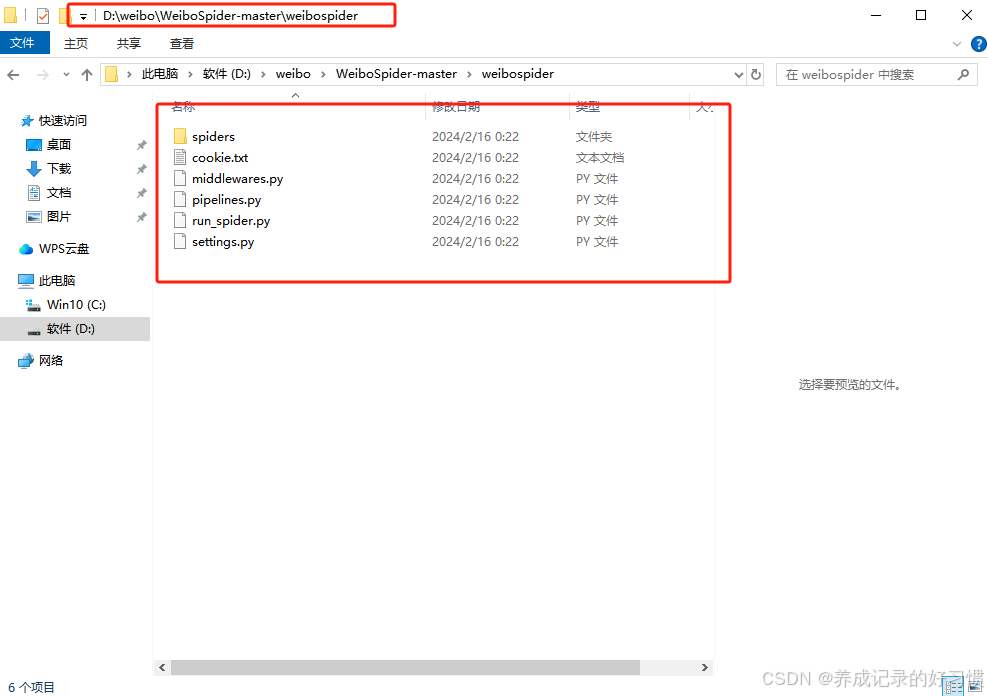
WeiboSpider项目的镜像网址:https://gitcode.com/gh_mirrors/weibo/WeiboSpider/overview,下载解压后项目文件夹的路径及文件概况如下:
2.填写cookie
去weibo官网首页用F12找一下cookie,填写到cookie.txt文档中。
3.修改采集参数
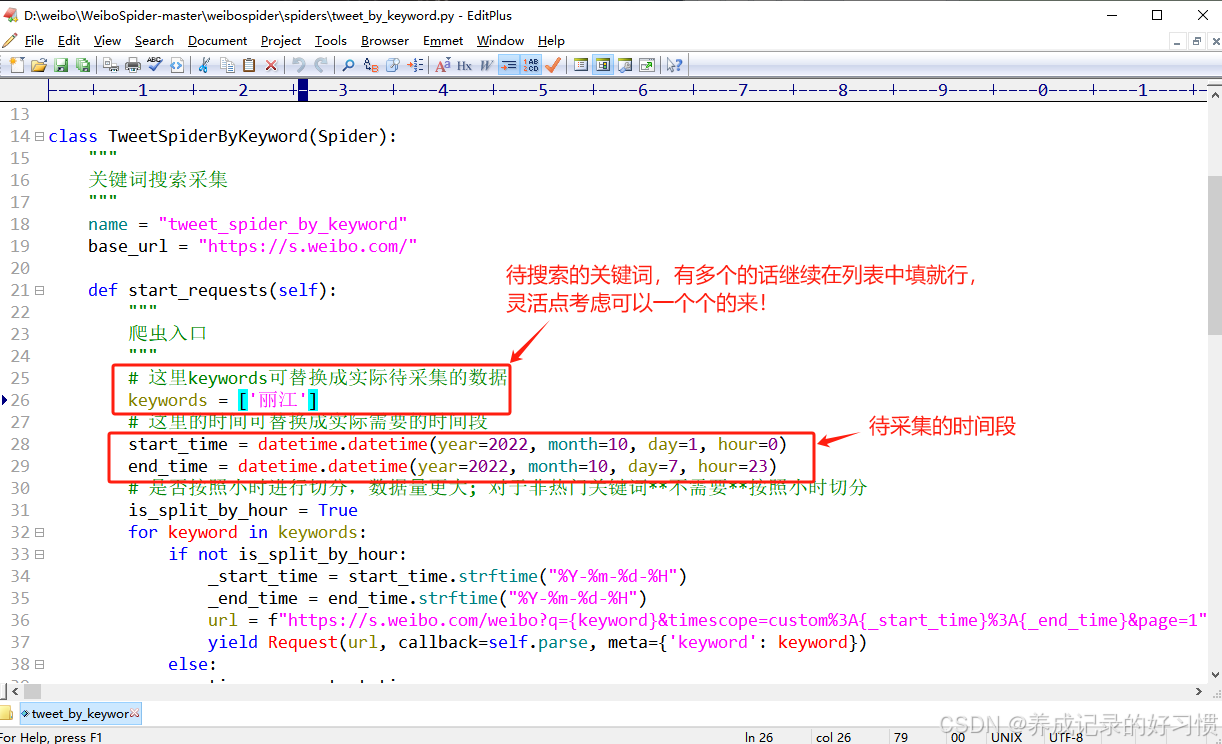
打开spiders文件夹下的tweet_by_keyword.py文件,按照需求修改即可,修改这两个参数就行。
4.进入项目路径,运行程序
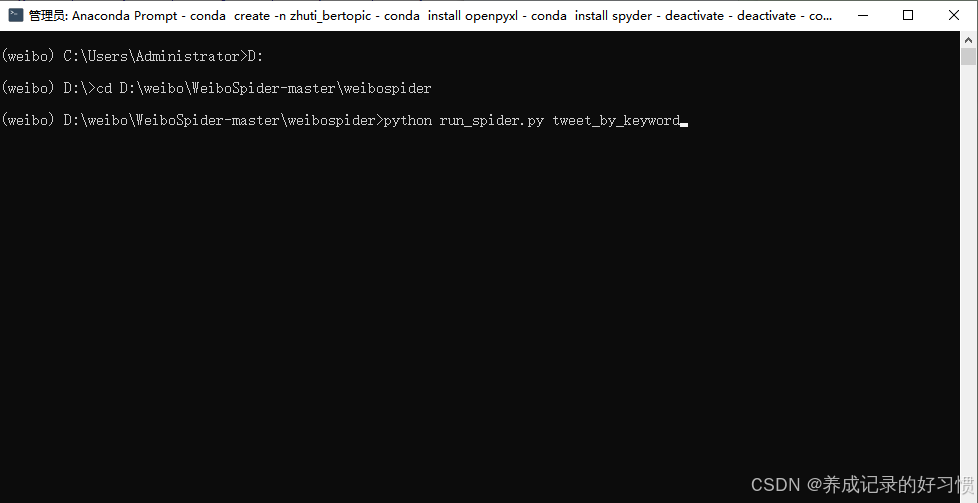
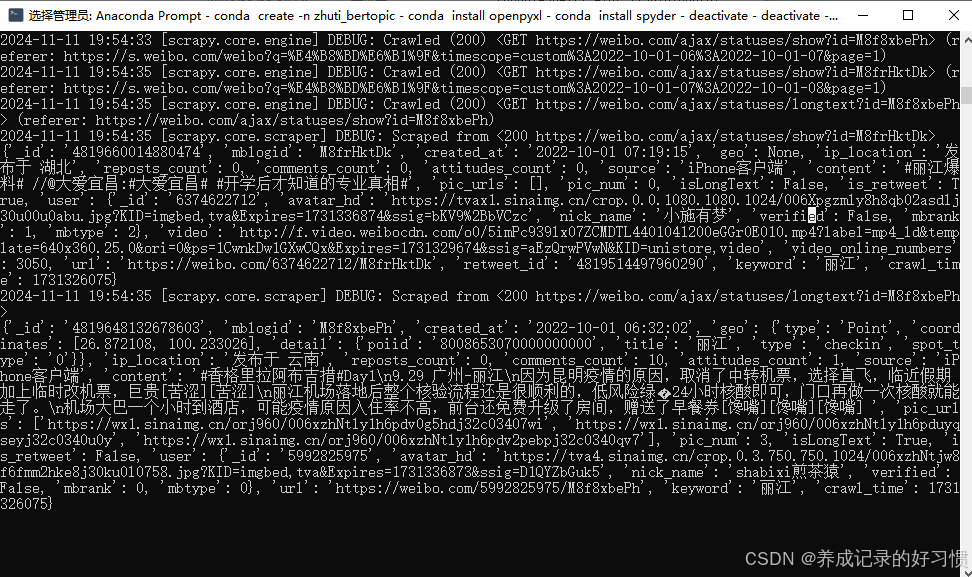
在conda的cmd中跳转到weibospider的文件夹中,然后执行命令python run_spider.py tweet_by_keyword,如下图所示:
出现下图所示的采集信息表示程序正常运行,完工,坐等数据即可~
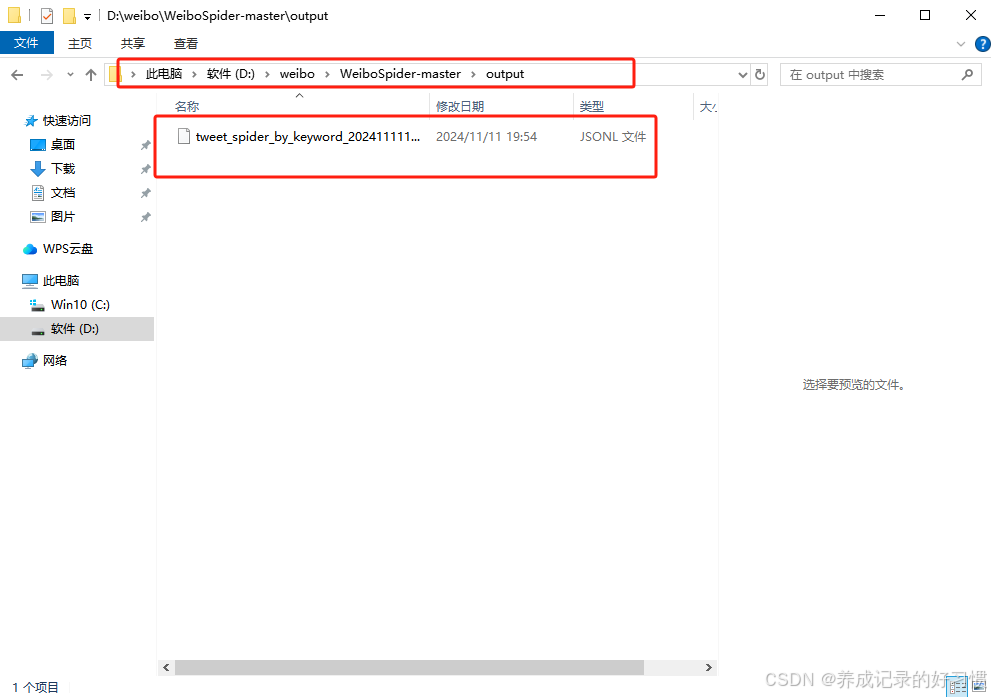
采集的数据最终存储在output文件夹下的json文件中,这个文件夹和文件都是程序自动创建,不用手动添加!
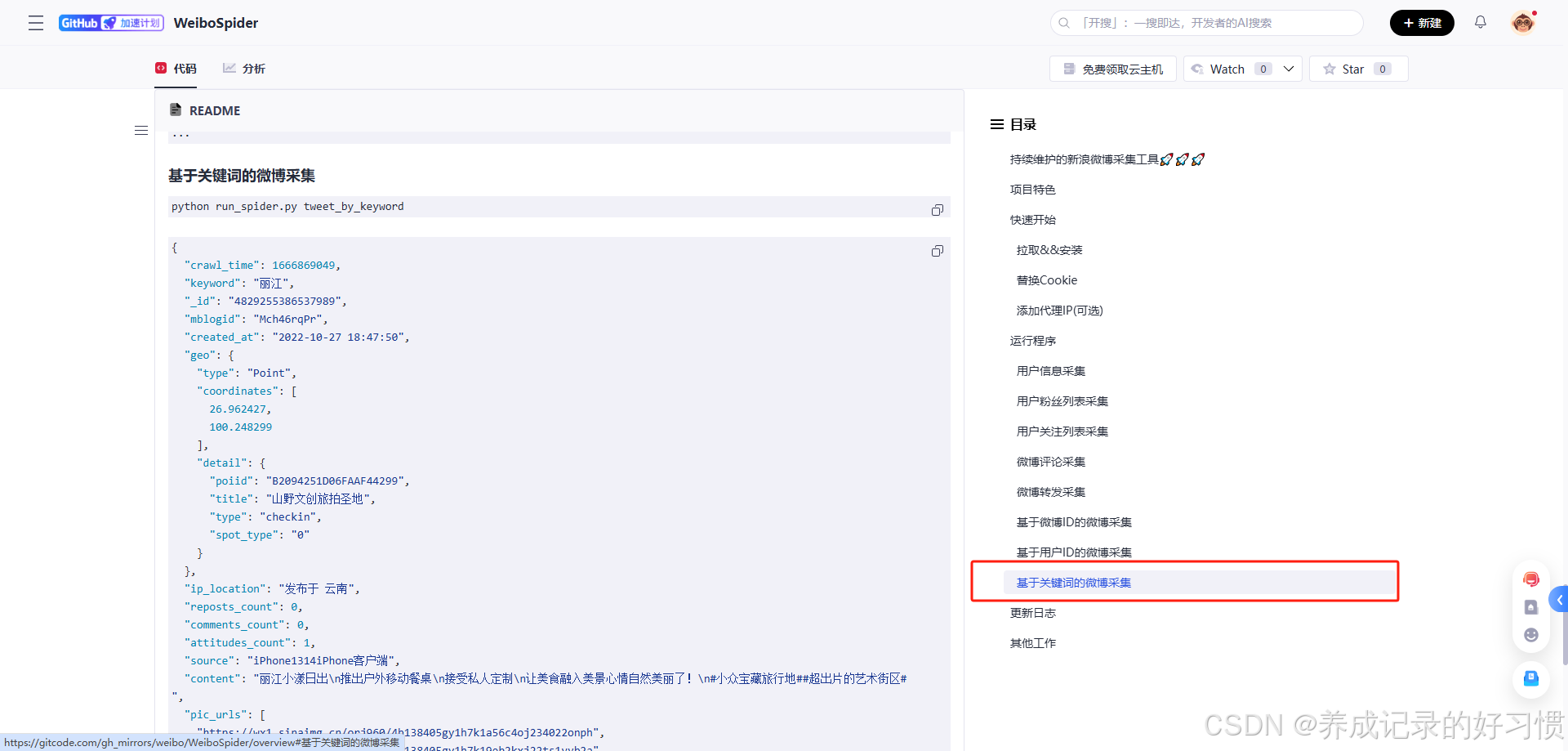
最后,我采集的是根据微博的关键词搜索返回的微博,对应原项目也就是“基于关键词的微博采集”这一条,想采集评论、用户信息等数据,也可以参照原项目网址修改对应参数即可!

















 2628
2628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









