







代码
1. 话题榜
import requests
import pandas as pd
import urllib
from urllib import parse
headers = {
'authority': 'weibo.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'client-version': 'v2.44.64',
'referer': 'https://weibo.com/newlogin?tabtype=topic&gid=&openLoginLayer=0&url=',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'server-version': 'v2024.02.19.1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
'x-requested-with': 'XMLHttpRequest',
'x-xsrf-token': 'HOU1s1Hak41bvvQjYsR86Oar',
}
def get_page_resp(num):
params = {
'sid': 'v_weibopro',
'category': 'all',
'page': f'{num}',
'count': '10',
}
response = requests.get('https://weibo.com/ajax/statuses/topic_band', params=params, headers=headers)
return response
def process_resp(response):
statuses = response.json()['data']['statuses']
if statuses:
_df = pd.DataFrame([[statuse['topic'], statuse['summary'], statuse['read'], statuse['mention'], f"https://s.weibo.com/weibo?q=%23{urllib.parse.quote(statuse['topic'])}%23"] for statuse in statuses], columns=['topic', 'summary', 'read', 'mention', 'href'])
return _df
else:
return
if __name__ == '__main__':
df_list = []
num = 1
while num:
resp = get_page_resp(num)
_df = process_resp(resp)
if isinstance(_df, pd.DataFrame):
df_list.append(_df)
num += 1
else:
num = 0
df = pd.concat(df_list).reset_index(drop=True)
print(df)
df.to_csv('话题榜.csv')
2. 热搜榜
import requests
import urllib
import pandas as pd
import numpy as np
def get_hot():
headers = {
'authority': 'weibo.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'client-version': 'v2.44.64',
'referer': 'https://weibo.com/newlogin?tabtype=search&gid=&openLoginLayer=0&url=',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'server-version': 'v2024.02.19.1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
'x-requested-with': 'XMLHttpRequest',
'x-xsrf-token': 'HOU1s1Hak41bvvQjYsR86Oar',
}
response = requests.get('https://weibo.com/ajax/side/hotSearch', headers=headers)
df = pd.DataFrame(response.json()['data']['realtime'])
df['url'] = df['word'].map(lambda x: 'https://s.weibo.com/weibo?q=' + urllib.parse.quote(x))
df['onboard_time'] = pd.to_datetime(df['onboard_time'], unit='s')
gov_name = response.json()['data']['hotgov']['name']
gov_url = response.json()['data']['hotgov']['url']
df = df[['word_scheme', 'word', 'star_name', 'realpos', 'label_name', 'onboard_time', 'url', 'raw_hot']]
gov_info = [gov_name, gov_name[1:-1], {}, 0, '顶', np.nan, gov_url, np.nan]
df = pd.DataFrame(np.insert(df.values, 0, gov_info, axis=0), columns=df.columns)
return df
if __name__ == '__main__':
df = get_hot()
df.to_csv('热搜榜.csv')
3. 文娱榜和要闻榜
这里需要更换cookies
import requests
import pandas as pd
import urllib
# 跟换为自己的cookies
def get_entertainment_and_news():
headers = {
'authority': 'weibo.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'client-version': 'v2.44.75',
# 跟换为自己的cookies
'cookie': 'SINAGLOBAL=1278126679099.0298.1694199077980; UOR=,,localhost:8888; _s_tentry=localhost:8888; Apache=6414703468275.693.1710132397752; XSRF-TOKEN=4A9SIIBq9XqCDDTlkpxBLz76; ULV=1710132397782:20:1:1:6414703468275.693.1710132397752:1708482016120; login_sid_t=b637e1846742b4dd85dfe4d86c2c9413; cross_origin_proto=SSL; wb_view_log=1920*10801; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFARU4r6-VQ2BMDorVsYLdC5JpX5o275NHD95Qce0eX1KefehMXWs4DqcjMi--NiK.Xi-2Ri--ciKnRi-zNSoe0Sh.0SK5NS5tt; ALF=1712724726; SSOLoginState=1710132727; SCF=ApDYB6ZQHU_wHU8ItPHSso29Xu0ZRSkOOiFTBeXETNm74LTwE3TL5gaw4A4raSthpN-_7ynDOKXDUkiKc1jk720.; SUB=_2A25I6v2nDeRhGeBN6FYY8yvMzDiIHXVrhn9vrDV8PUNbktAGLXb1kW9NRGsSAV5UnWQYNJKU-WfqLNcAf0YTSxtn; WBPSESS=LZz_sqga1OZFrPjFnk-WNlnL5lU4G2v_-YZmcP-p0RFdJenqKjvGkmGWkRfJEjOjxH0yfYfrC4xwEi4ExzfXLO84Lg-HDSQgWx5p8cnO_TnE_Gna1RnTgtIpZu7xWJpq8fJ35LrwI2KAkj4nnVzB_A==',
'referer': 'https://weibo.com/hot/entertainment',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'server-version': 'v2024.03.06.1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
'x-requested-with': 'XMLHttpRequest',
'x-xsrf-token': '4A9SIIBq9XqCDDTlkpxBLz76',
}
response_entertainment = requests.get('https://weibo.com/ajax/statuses/entertainment', headers=headers)
response_news = requests.get('https://weibo.com/ajax/statuses/news', headers=headers)
df_entertainment = pd.DataFrame(response_entertainment.json()['data']['band_list'])
df_entertainment['url'] = df_entertainment['word'].map(
lambda x: 'https://s.weibo.com/weibo?q=' + '%23' + urllib.parse.quote(x) + '%23')
df_news = pd.DataFrame(response_news.json()['data']['band_list'])
df_news['url'] = df_news['topic'].map(
lambda x: 'https://s.weibo.com/weibo?q=' + '%23' + urllib.parse.quote(x) + '%23')
return df_entertainment, df_news
if __name__ == '__main__':
df_entertainment, df_news = get_entertainment_and_news()
df_entertainment.to_csv('文娱榜.csv')
df_news.to_csv('要闻榜.csv')
过程
1. 话题榜
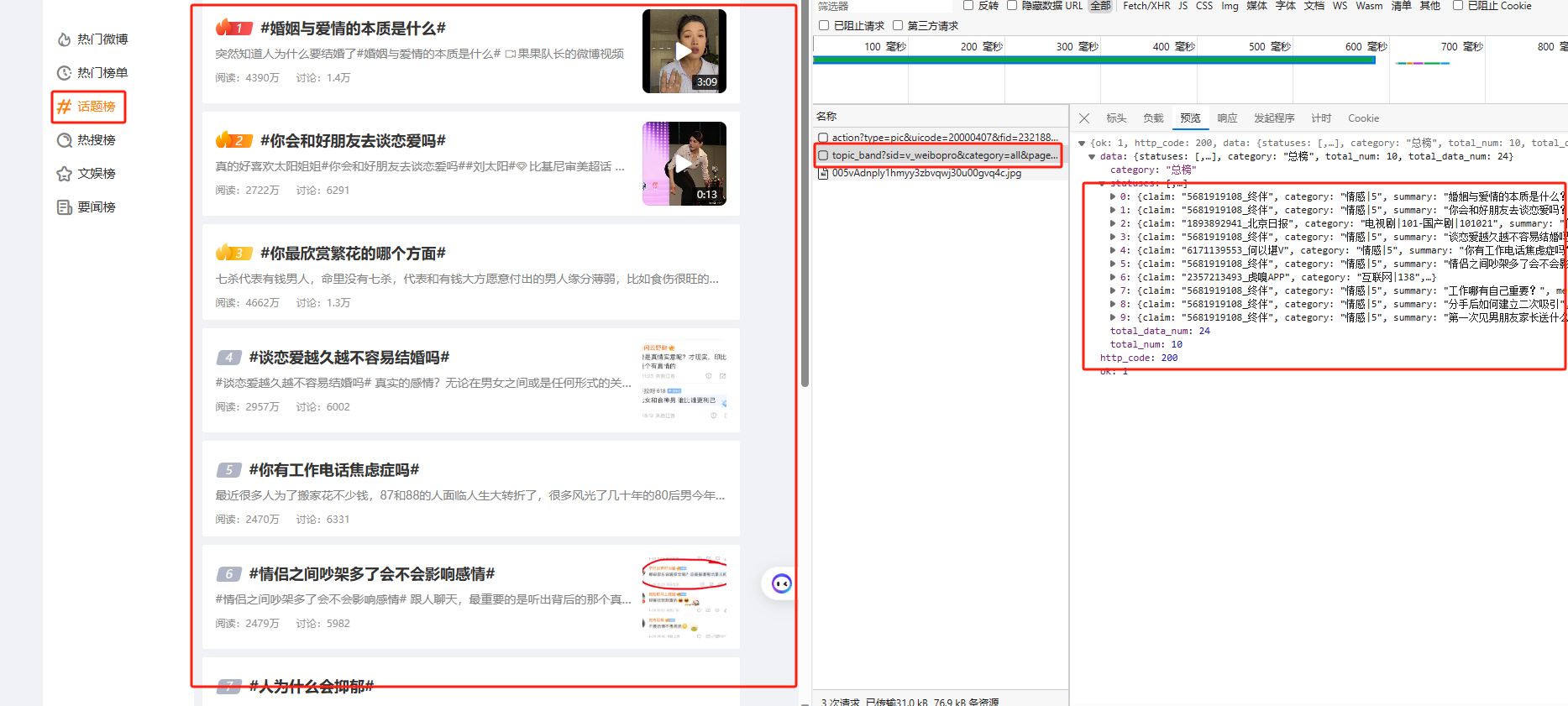
从F12中可以得到所有数据在右侧请求中,解析可以得到参数如下:
- sid: 这个值为 v_weibopro 是固定的
- category: 这个值为 all 是固定的
- page: 这个值为页码,每一页10个,从第一页开始计算
- count: 这个值为 10 是固定的,修改无效
所有的数据存储在['data']['statuses']下,进行解析,代码如下:
statuses = response.json()['data']['statuses']
if statuses:
_df = pd.DataFrame([[statuse['topic'], statuse['summary'], statuse['read'], statuse['mention'], f"https://s.weibo.com/weibo?q=%23{urllib.parse.quote(statuse['topic'])}%23"] for statuse in statuses], columns=['topic', 'summary', 'read', 'mention', 'href'])
return _df
else:
return 0
可以获得所有结果:

2. 热搜榜
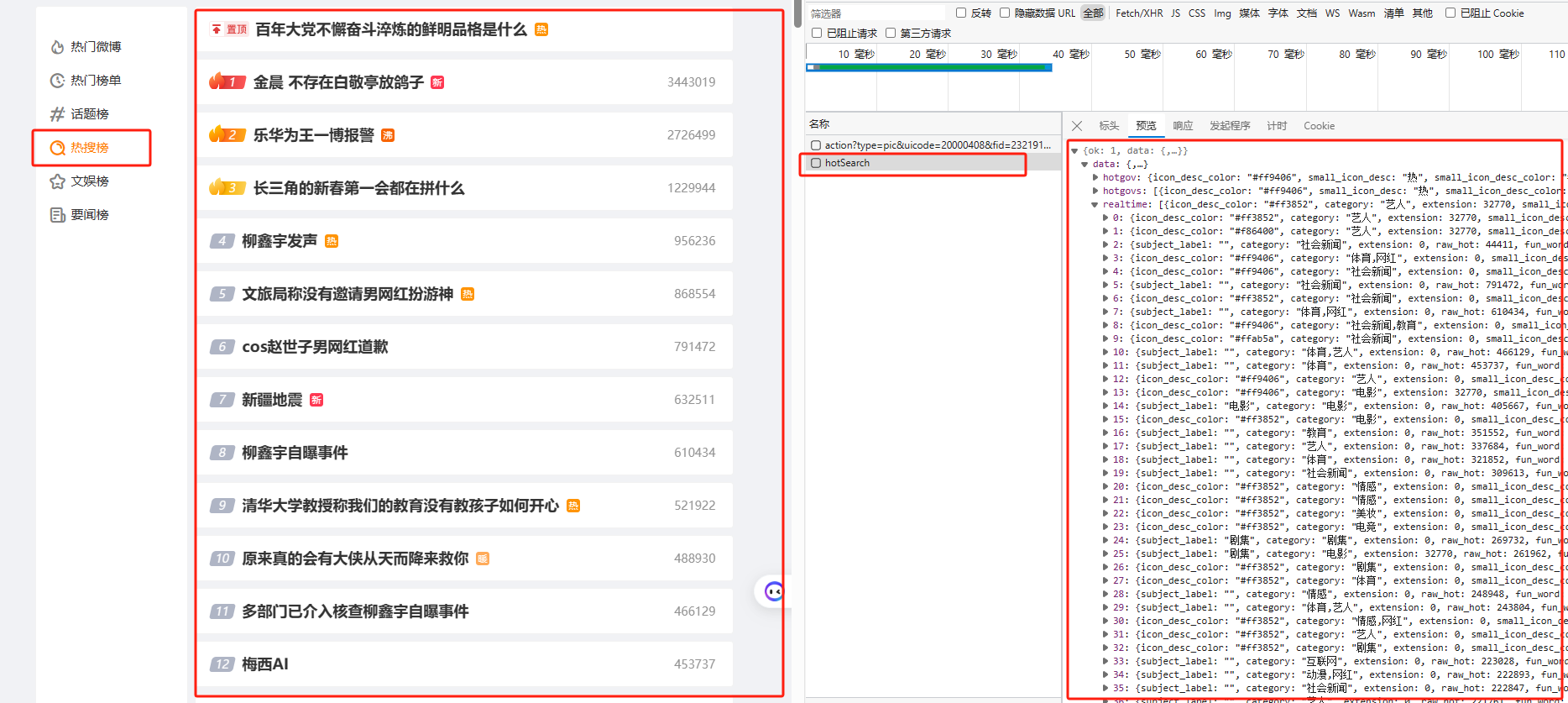
从F12中发现,这个请求是Get型的请求,什么参数都不需要,估计微博是直接放弃了
直接将得到的数据进行处理,
df = pd.DataFrame(response.json()['data']['realtime'])
df['url'] = df['word'].map(lambda x: 'https://s.weibo.com/weibo?q=' + urllib.parse.quote(x))
df['onboard_time'] = pd.to_datetime(df['onboard_time'], unit='s')
gov_name = response.json()['data']['hotgov']['name']
gov_url = response.json()['data']['hotgov']['url']
df = df[['word_scheme', 'word', 'star_name', 'realpos', 'label_name', 'onboard_time', 'url', 'raw_hot']]
gov_info = [gov_name, gov_name[1:-1], {}, 0, '顶', np.nan, gov_url, np.nan]
df = pd.DataFrame(np.insert(df.values, 0, gov_info, axis=0), columns=df.columns)
得到:
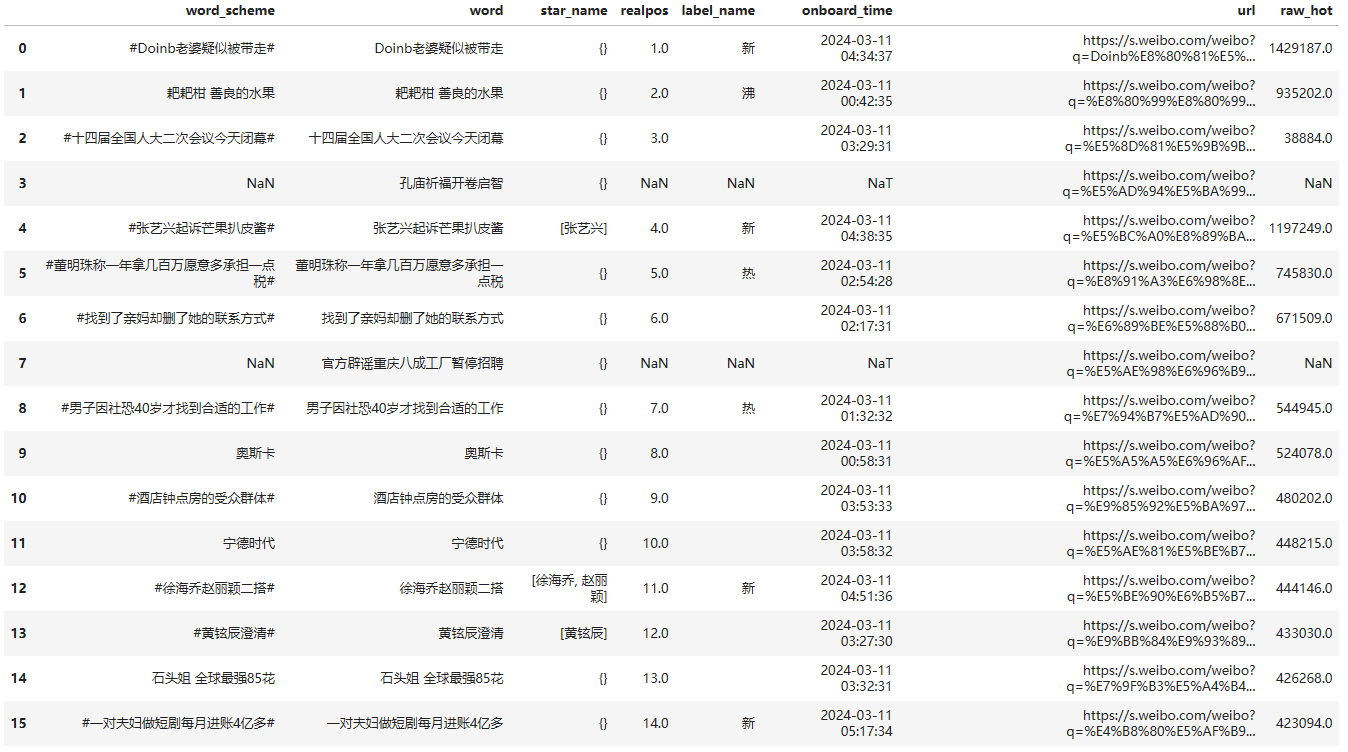
3. 文娱榜和要闻榜

这里从F12中可以发现,文娱榜和要闻榜 直接一个请求就可以获取,但是在解析的过程中,发现还是需要cookie的,所以这里需要自己获取cookies;
在response中发现数据无需要清理,直接在表格中获取一下自己需要的参数即可,在这里还是把url添加一下,有的人根本不看前文怎么获取的;
response_entertainment = requests.get('https://weibo.com/ajax/statuses/entertainment', headers=headers)
response_news = requests.get('https://weibo.com/ajax/statuses/news', headers=headers)
df_entertainment = pd.DataFrame(response_entertainment.json()['data']['band_list'])
df_entertainment['url'] = df_entertainment['word'].map(lambda x: 'https://s.weibo.com/weibo?q=' + '%23' + urllib.parse.quote(x) + '%23')
df_news = pd.DataFrame(response_news.json()['data']['band_list'])
df_news['url'] = df_news['topic'].map(lambda x: 'https://s.weibo.com/weibo?q=' + '%23' + urllib.parse.quote(x) + '%23')
得到文娱榜如下:
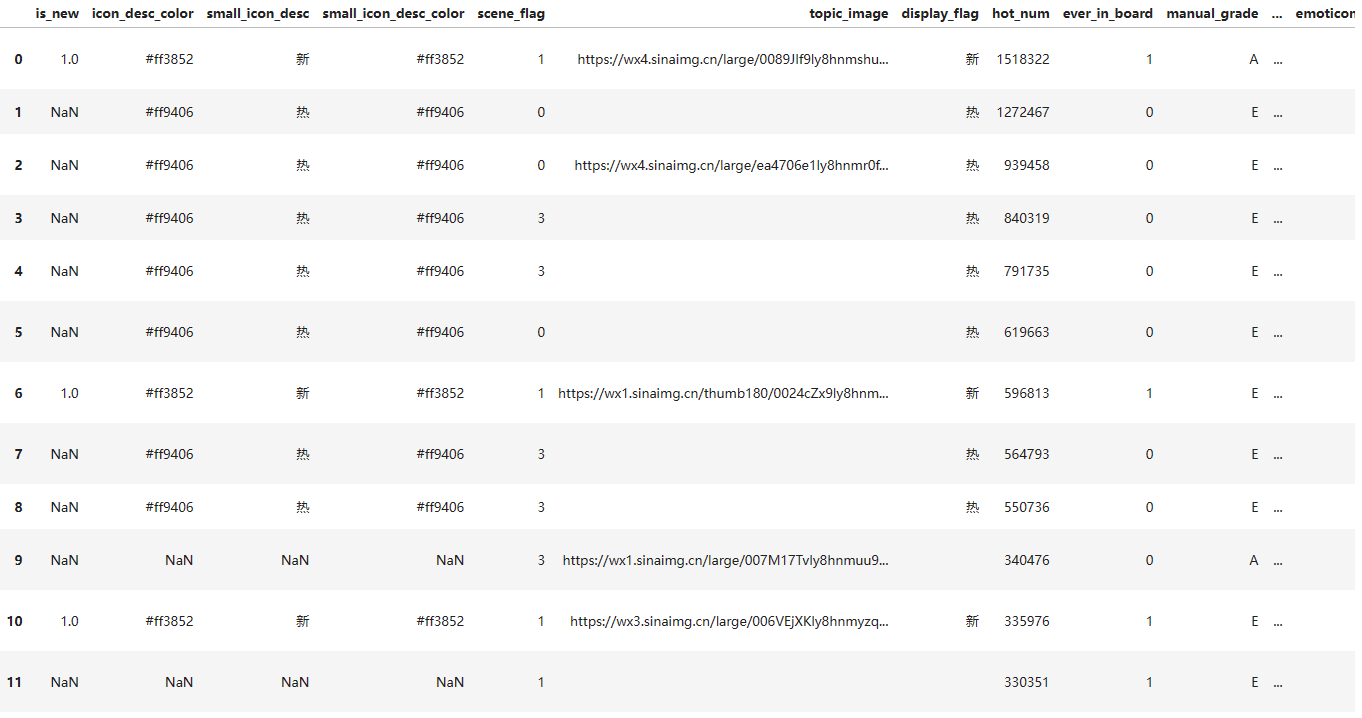
得到要闻榜如下:


















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









