







1 前言
层次分析法(Analytic Hierarchy Process, AHP)是一种定性与定量相结合的决策分析方法,由美国运筹学家萨蒂(Thomas L. Saaty)在20世纪70年代提出。AHP通过构建层次结构和判断矩阵,系统地分析复杂问题中各因素的重要性,并以量化的方式得出权重和优先级。
在科研领域,AHP因其逻辑严谨、操作简便以及对主观判断的科学量化而受到广泛关注,特别是在评价类研究中发挥了重要作用。它被广泛应用于论文中的多维指标评价,如政策效果评估、模型优劣比较、方案选择等,能够帮助研究者清晰地呈现指标权重分布和综合评价结果。
2 层次分析法的实施步骤
AHP的实施步骤包括以下五个关键阶段,每一阶段都对最终结果至关重要。以下将详细说明每个步骤的原理并结合具体示例展开说明。
(1) 建立层次结构模型
将复杂问题分解为目标、准则和备选方案三个层次的结构模型:
- 目标层:核心问题或决策目标。
- 准则层:用于评估备选方案的重要指标。
- 方案层:需要进行评价或排序的备选方案。
假设我们需要选择一台笔记本电脑,目标是找到性价比最高的型号,需要综合考虑以下因素:性能、便携性、价格、品牌等,具体的评价体系如下:
- 目标层:选择最合适的笔记本电脑。
- 准则层:性能、便携性、价格、品牌。
- 方案层:品牌A笔记本、品牌B笔记本、品牌C笔记本。
(2) 构造判断矩阵
在每个层次内,对同一层次的所有元素两两比较重要性,使用Saaty的1-9标度法生成判断矩阵,其中1-9标度在矩阵中的含义如下表所示:
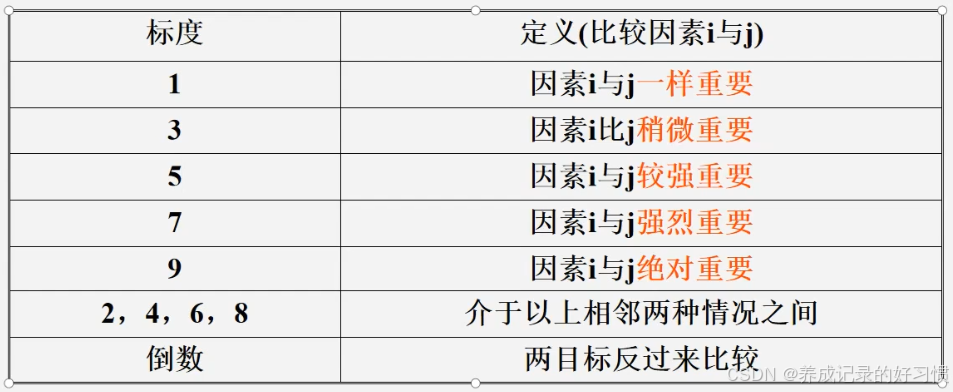
判断矩阵为正互反矩阵,具有以下性质:
- 对角线元素为1,
=1,即某个元素自己与自己比较重要性;
- 任意两个元素
和
满足
。
现在对“价格、性能、品牌、售后服务”四个准则的重要性进行两两比较,假设判断标准如下:
- 品牌比价格较强重要(
),售后服务比价格较强重要(
);
- 品牌比性能稍微重要(
),性能比价格稍微重要(
);
- 售后服务比性能稍微重要(
),售后服务与品牌同等重要(
)。
构造判断矩阵A如下:

(3) 计算特征向量并进行层次单排序
计算判断矩阵的最大特征值及其对应特征向量W,特征向量的归一化结果即为各准则的相对权重。注意:判断矩阵A的特征向量W的解法并非按照线代中的方法,在这儿很简单,就先将判断矩阵A按列归一化后,按行求和再取平均值。
现在计算判断矩阵A的以及特征向量W,具体步骤如下:
-
对判断矩阵 A 的每列进行求和,得到每列的和:[14 7.333 2.533 2.533]
-
将矩阵归一化(每个元素除以所在列的总和),得到归一化矩阵:
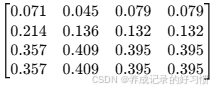
-
对归一化矩阵的每行求平均值,得到权重向量W:[0.0687 0.1535 0.3889 0.3889]
算出来判断矩阵A的特征向量W后,特征值的计算就是根据AW=
W反推出来的:
-
计算判断矩阵A与权重向量W的乘积,得到一个新向量:

-
将新向量中每个元素除以对应的权重向量的元素,求和后再取平均得到特征值
:
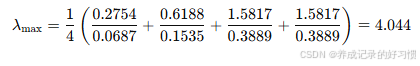
(4) 一致性检验
在AHP中,判断矩阵的构造基于决策者的主观判断,因此需要通过一致性检验来验证判断矩阵的逻辑合理性,一致性检验的步骤如下:
-
计算一致性指标 (CI):一致性指标衡量判断矩阵的一致性偏差,其公式为:
,其中,
-
计算一致性比率 (CR):一致性比率是判断一致性的最终标准,其公式为:
,其中,RI是随机一致性指标,其值由判断矩阵的阶数n决定,RI的值查表即可(Saaty提供的表格),常见的随机一致性指标RI值如下:
-
一致性判断:
- 若 CR<0.1,判断矩阵具有满意的一致性;
- 若 CR≥0.1,判断矩阵一致性较差,需要重新调整判断矩阵。
对于上面示例中的判断矩阵A,CI、CR均可算得结果,分别为0.0147、0.0163,因为 CR=0.0163<0.1,故判断矩阵A具有满意的一致性,无需调整。
(5) 层次总排序与指标权重计算
通过判断矩阵 A 计算得到W=[0.0687 0.1535 0.3889 0.3889],分别对应:价格(0.0687)、性能(0.1535)、品牌(0.3889)、售后服务(0.3889),剩余的准则层这四个指标分别对品牌A、品牌B、品牌C笔记本的评价指标权重再分别构造判断矩阵,按上述流程计算即可。
3 Python代码实现
下面的程序,实现了本实例中判断矩阵A应用AHP,输出权重向量W、特征值,以及一致性检验中的CI、RI、CR的数值:
import numpy as np
# Step 1: 定义判断矩阵 A
A = np.array([
[1, 1/3, 1/5, 1/5],
[3, 1, 1/3, 1/3],
[5, 3, 1, 1],
[5, 3, 1, 1]
])
# Step 2: 按列计算每列的和
column_sums = A.sum(axis=0)
# Step 3: 对矩阵进行按列归一化
normalized_matrix = A / column_sums
# Step 4: 计算权重向量 W(归一化矩阵每行的平均值)
weight_vector = normalized_matrix.mean(axis=1)
# Step 5: 计算最大特征值 λ_max
Aw = np.dot(A, weight_vector) # 计算 A·W
lambda_max = np.mean(Aw / weight_vector) # 用 λ = (A·W)/W 求 λ_max 的近似值
# Step 6: 一致性检验
n = A.shape[0] # 判断矩阵的阶数
CI = (lambda_max - n) / (n - 1) # 一致性指标 CI
RI_list = [0, 0, 0.58, 0.9, 1.12, 1.24, 1.32, 1.41, 1.45, 1.49] # RI 标准值表
RI = RI_list[n-1] # 查表得到 RI 的值
CR = CI / RI # 一致性比率 CR
# 输出结果
print("判断矩阵 A:")
print(A)
print("\n权重向量 W:", weight_vector)
print("最大特征值 λ_max:", lambda_max)
print("一致性指标 CI:", CI)
print("随机一致性指标 RI:", RI)
print("一致性比率 CR:", CR)
# 判断一致性
if CR < 0.1:
print("\n判断矩阵一致性通过,无需调整。")
else:
print("\n判断矩阵一致性较差,需要调整判断矩阵。")

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









