







1 模糊综合评价方法介绍
(1)模糊概念
模糊逻辑起源于Zadeh教授在1965年提出的模糊集合理论,用以处理非黑即白的二值逻辑难以描述的模糊性问题。在现实世界中,许多事物和现象无法用精确的值描述,而是介于“完全是”与“完全不是”之间的模糊状态,例如什么是秃子?(脱口而答)没有头发的是秃子,那有一根头发的呢,三根的呢?这个时候我们需要一个指标来代替严格的“是”与“不是”,描述“中间状态”,这个指标就是隶属度,可以看做概率,取值范围(0,1),使用隶属度就可以描述有三根头发隶属秃子的概率。
(2)模糊综合评价方法简介
模糊综合评价是一种基于模糊数学原理的多指标评价方法,旨在解决现实中由于模糊性和不确定性而难以进行精确量化的问题。其核心思想是利用隶属度的概念将复杂系统中的“中间状态”具体化,通过对各个评价指标赋予不同的权重,并结合模糊运算对模糊隶属关系进行综合计算,得出评价对象的整体结果。
在评价“某人是否秃子”这一问题时,传统二值逻辑就简单认为“有头发则不是秃头,无头发则是秃头”,但模糊综合评价允许我们通过隶属度来刻画头发数量与“秃头”概念之间的连续变化关系(如三根头发与“秃头”的隶属度可能为0.9995)。类似地,在多指标评价场景中,模糊综合评价方法能灵活地处理复杂系统中“部分符合”或“部分关联”的情况,例如学生综合素质评估。
2 模糊综合评价方法的步骤
(1)确定评价对象的因素集和权重
评价对象的因素集就是评价指标的集合,记为 ,权重向量就是评价指标对应的权重,记为
,可以用层次分析法确定,层次分析法可以看这篇文章。
示例:以学生学习成绩评价为例,因素集为 U={知识掌握,实践能力,创新能力},对应权重 W={0.5,0.3,0.2},所示说U就是指标集,W就是各指标对应的权重,这点很好理解。
(2)确定评价对象的评语集
评语集就是评价者对被评价对象可能做出的各种总的评价结果组成的评语等级的集合,记为。
示例:对学生学习成绩评价的评语集V={优秀,良好,一般,不及格},V就是一些评语词的集合,一般评语也就划分为3~5个等级。
(3)进行单因素模糊评价
单因素模糊评价:单独从一个因素出发进行评价,以确定评价对象对评价集合V的隶属程度。
对每个评价指标(i=1,2,...,n),从单因素来看被评价对象对评价集合V中各等级的隶属度,进而得到模糊关系矩阵R:

示例:某学生对“知识掌握”的评价隶属度为 [0.7,0.2,0.1,0],具体的数字是怎么来的?
简单的方法直接统计打分,让10位同学对该同学进行评价,有7位同学认为该同学对“知识掌握”的评价等级为优秀,有2位同学认为该同学对“知识掌握”的评价等级为良好,有1位同学认为该同学对“知识掌握”的评价等级为一般,那评价结果就是[7 2 1 0],归一化后就是[0.7 0.2 0.1 0],也就是该同学在“知识掌握”的评级指标上有0.7的概率隶属于优秀、有0.2的概率隶属于良好、有0.1的概率隶属于一般、有0的概率隶属于不及格。
其余评价指标同理类推,假设他对“实践能力”的评价隶属度为 [0.8,0.1,0.1,0],“创新能力”的评价隶属度为 [0.6,0.2,0.1,0.1],模糊关系矩阵R如下:
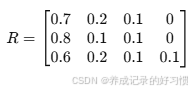
(4)隶属矩阵和指标权重的模糊合成
将模糊矩阵R与评价指标权重向量W进行模糊合成,得到综合评价的结果向量B。
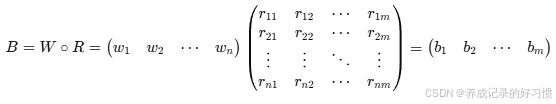
结果向量B的计算并不是简单的矩阵向量的乘法,而是模糊合成算子,模糊合成算子有四种,常用的就是加权平均型的,简单说仍然是矩阵向量的乘法,多了一点:计算的某个大于1的就取1,即按照加权平均型的算出的B不可能出现大于1的值。
示例:将上面示例中的权重向量W与模糊矩阵R代入计算,计算过程如下:

(5)综合评价结果判断
根据模糊综合评价的结果向量 B,确定评价结果,通常取隶属度最大的对应评语。
示例:该同学的学习成绩在 [优秀,良好,一般,不及格] 的隶属度分别为0.71、0.17、0.10、0.02,很明显这位同学最终的评价结果为优秀。
3 Python代码实现
下面的程序,实现了示例中模糊关系矩阵R,与指标权重向量W进行模糊合成后,输出结果向量B以及评价结果:
# -*- coding: utf-8 -*-
"""
Created on Wed Dec 4 14:02:35 2024
@author: Administrator
"""
import numpy as np
# 1. 确定评价对象的因素集U和权重向量W
U = ["知识掌握", "实践能力", "创新能力"]
W = np.array([0.5, 0.3, 0.2]) # 权重向量
# 2. 确定评价对象的评语集
evaluations = ["优秀", "良好", "一般", "差"]
# 3. 进行单因素模糊评价
# 模糊关系矩阵R表示每个评价因素对评语集的隶属度
R = np.array([
[0.7, 0.2, 0.1, 0.0], # 对应"知识掌握"的隶属度
[0.8, 0.1, 0.1, 0.0], # 对应"实践能力"的隶属度
[0.6, 0.2, 0.1, 0.1] # 对应"创新能力"的隶属度
])
# 4. 隶属矩阵和指标权重的模糊合成
# 使用加权平均法进行模糊合成
B = np.dot(W, R) # 计算综合隶属度向量B
# 5. 综合评价结果判断
# 根据隶属度向量B,确定最终评价结果
max_index = np.argmax(B) # 找到隶属度最大的评语对应索引
final_evaluation = evaluations[max_index] # 最终评价结果
# 输出结果
print("综合隶属度向量 B:", B)
















 2009
2009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









