






RAG相关
什么是检索增强生成?
检索增强生成是用从其他地方检索到的附加信息来补充用户输入到聊天 GPT 等大型语言模型(LLM)的过程。然后,LLM 可以使用该信息来增强其生成的响应。其主要是解决时效性和幻觉等问题。
下图显示了它在实践中的工作原理:


我们平台的处理链路和RAG的思想是很类似,那么我们就可以借鉴一些RAG的经验和研究成果。
在几年前,也有将RAG用于模型微调的一些研究,但是其核心还是通过将问题在搜索引擎中搜索实现的。
FaceBook的检索增强生成方法,更好地胜任知识密集型任务丨NeurIPS 2020 | 论文频道 | 领研网
Benchmarking Large Language Models in Retrieval-Augmented Generation(论文)
https://arxiv.org/pdf/2309.01431.pdf
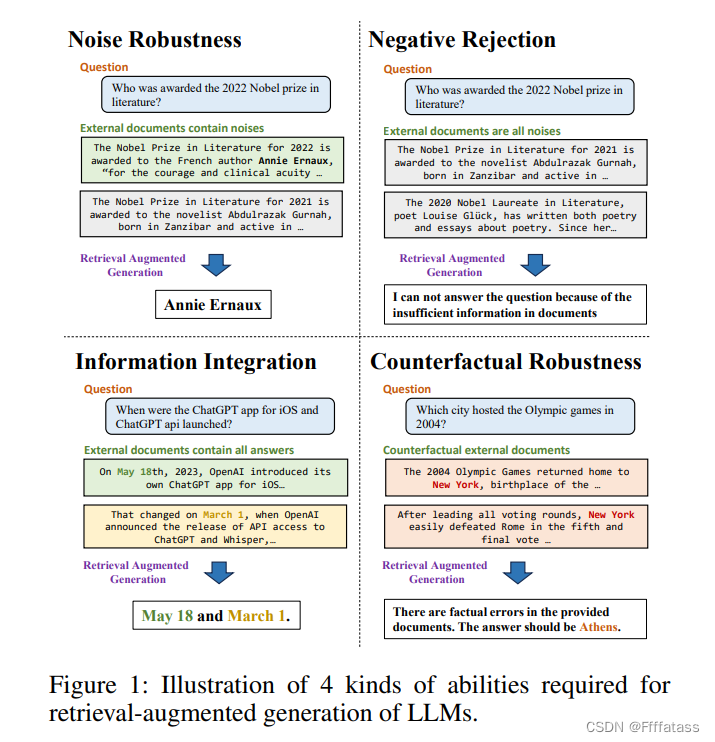
这篇论文主要就是研究我们在使用RAG技术处理数据实时性和幻觉问题时,面临的一些挑战。当我们将检索到的上下文交给LLM时,模型本身在处理”噪音鲁棒性“,”负面拒绝“,”信息整合“,”反事实鲁棒性“四个方面存在一定的差异。
首先就是”噪音鲁棒性“,论文中的结论是:

可以看到在噪音比是0.8的时候,LLM回答的准确度都有一个较大的下滑。但是噪音比0.6时就会好很多。那在我们平台中我认为值得考虑的一点优化就是可以尝试将TOP K中的K值从5调整到3。
论文作者也对LLM不准确回答做了原因的分析,主要有三个原因:

1、当处理外部文档时,模型在确定正确答案时经常面临一个困难,即问题相关的信息与答案相关的信息相距甚远。这种情况在互联网上经常遇到,因为长篇文本很常见。在这种情况下,问题的信息通常最初出现在文档的开头,并随后使用代词进行引用。在表2中,问题信息("2022年卡塔尔公开赛")只在开头提到一次,与答案文本 "Anett Kontaveit" 相距甚远。这种情况可能导致语言模型依赖于其他文档中的信息,并产生错误的印象,即产生错觉。---知识库文章和工具描述等应该突出重点,提炼精华
2、证据的不确定性。在备受期待的事件之前,例如新款苹果产品发布或奥斯卡颁奖公告,往往会有大量的猜测性信息在互联网上流传。尽管相关文档明确表明这些内容是不确定或猜测性的,它们仍然会对语言模型的检索增强生成产生影响。在表2中,当噪声比例增加时,错误文档的内容都是关于某些人对耳机名称("Apple Reality Pro")的预测。即使相关文档中存在正确答案("Vision Pro"),模型仍可能被不确定的证据误导。---知识库文章的过滤,只录入确定性的知识
3、概念混淆。外部文档中的概念可能与问题中的概念相似,但又有所不同。这可能导致语言模型混淆,并生成错误的答案。在表2中,模型的答案集中在"汽车收入"这个概念上。---主要是模型能力不够,尽量减少给模型噪音
其次在”负面拒绝“这一方面,测试的所有LLM表现都不算好
我们想看下论文作者测试过程中使用的提示词:(我们系统中的提示词也是一个可以优化的点)

所以当LLM明确可以识别出上下文中不包含正确答案时,它会直接回复”文档信息不足“。那这个拒绝率最好的结果时Qwen的31%和8.67%。当LLM不能直接回复”文档信息不足“时,作者将答案放到chatGPT中,让其判断是否有拒绝回答的意思,这时最好的拒绝率是ChatGPT的45%和43%。也算不上好。
原因分析:

通过比较Rej和Rej*,我们发现LLMs未能严格遵循指示,他们经常产生不可预测的回答,这使得难以将它们用作状态触发器(例如用于识别拒绝)。我们在表4中进行了案例研究。第一个错误是由于证据的不确定性。尽管文档只提到与"Adam McKay"的联系,并没有明确说明他是电影的导演,但模型仍然得出他担任这个角色的结论。第二个错误是由于概念混淆。答案中提供的信息涉及到"2018年冬奥会",而问题中提到的是"2022年奥运会"。与直接回答相比,检索增强生成对负面拒绝提出了更大的挑战,因为它呈现了可能误导LLMs并导致错误回答的相关文档。在未来的发展中,LLMs必须增强其准确匹配问题与适当文档的能力,这一点至关重要。---主要还是模型的原因,但是在我们系统中文本相似性检索和阈值合理的设置也是很重要的

”信息整合“测试结果

可以看到LLM本身的信息整合效果就不算强,在加入一定的噪音后,效果会进一步下降。
原因分析:

1、合并错误(总数的28%)。模型有时会将两个子问题的答案合并在一起,导致错误。它错误地使用一个问题的答案来回答这两个问题。在这种情况下,模型将忽略与一个子问题相关的任何文档。例如,在表6中,它错误地表示D组既是法国的世界杯分组,也是德国的世界杯分组,而事实上,德国实际上被分配到E组。
2、忽略错误(总数的28%)。有时,模型可能会忽略一个子问题,只回答另一个子问题。当模型对问题缺乏完全理解,并未意识到它由多个子问题组成时,就会发生这种错误。因此,为了生成答案,模型只考虑一个子问题的相关文档,而忽视了另一个子问题提出的问题。例如,在表6中,模型只提供了2022年超级碗的最有价值球员(MVP)的答案,并未考虑2023年。
3、错位错误(总数的6%)。有时,模型会错误地将一个子问题的文档误认为另一个子问题的文档,导致答案错位。例如,在表6中,第三个答案存在两个错误:一个是忽略错误,一个是错位错误。首先,模型只提到了2023年(第95届)奥斯卡金像奖的最佳影片,完全忽视了2022年的奖项。此外,它错误地说“CODA”是2023年的最佳影片,而实际上它是在2022年被评为最佳影片。
上述错误主要是由于对复杂问题的理解有限,阻碍了有效利用来自不同子问题的信息的能力。关键在于提高模型的推理能力。一种可能的解决方案是使用链式思维方法来分解复杂问题。然而,这些方法会减慢推理速度,并且无法提供及时的响应。---在我们系统中,或许必要的时候还是要使用langchain agent?
最后一个,也是我认为我们大概率不会遇到的问题。”反事实鲁棒性“
”反事实鲁棒性“主要是指当检索到的文章和事实不符时,大模型可以有效的识别,并且不以此作答。但是这种问题主要出现在开放性检索的系统中,例如互联网上大量的假新闻等。而RAG的目的本来就是以检索到的内容让LLM作答,如果检索到的内容就是与事实不符,那它也很难处理。---就我们系统而言,只需要录入知识库时不要随意录入知识有误的文章即可。
其他的RAG优化方式
LangChain 多向量检索器(MultiVector Retriever)

该检索器的优化思想是,先将文章分成大文本块L1、L2...,
一、将大文本块分成更小的文本块L1.C1、L1.C2..L2.C1....存入向量库
二、用LLM将大文本块进行总结,总结的内容L1.S、L2.S...存入向量库
三、用LLM为大文本块生成几个问题,将问题L1.Q1、L1.Q2存入向量库
四、通过相似性检索来查找前面三步最相关的内容,返回其关联的大文本块,将大文本块作为上下文交给LLM。---相比于我们现在采用的直接相似性索引大文本的方式,理论上这种方式准确度应该会高一些,可以尝试优化
向量分块的优化:
1、每个向量存在冗余,假设以句子为分割,可以保存该句和其上下两句。以此来优化信息丢失和代指的问题。
2、分块的大小经验值在300-500 token左右,但是具体数值需要根据数据等进行测试后确定。
TOP K优化:
1、在相似性检索后,进行一次重排名(Embedding模型的Reranking)。排除不相关内容。
Embedding 相关
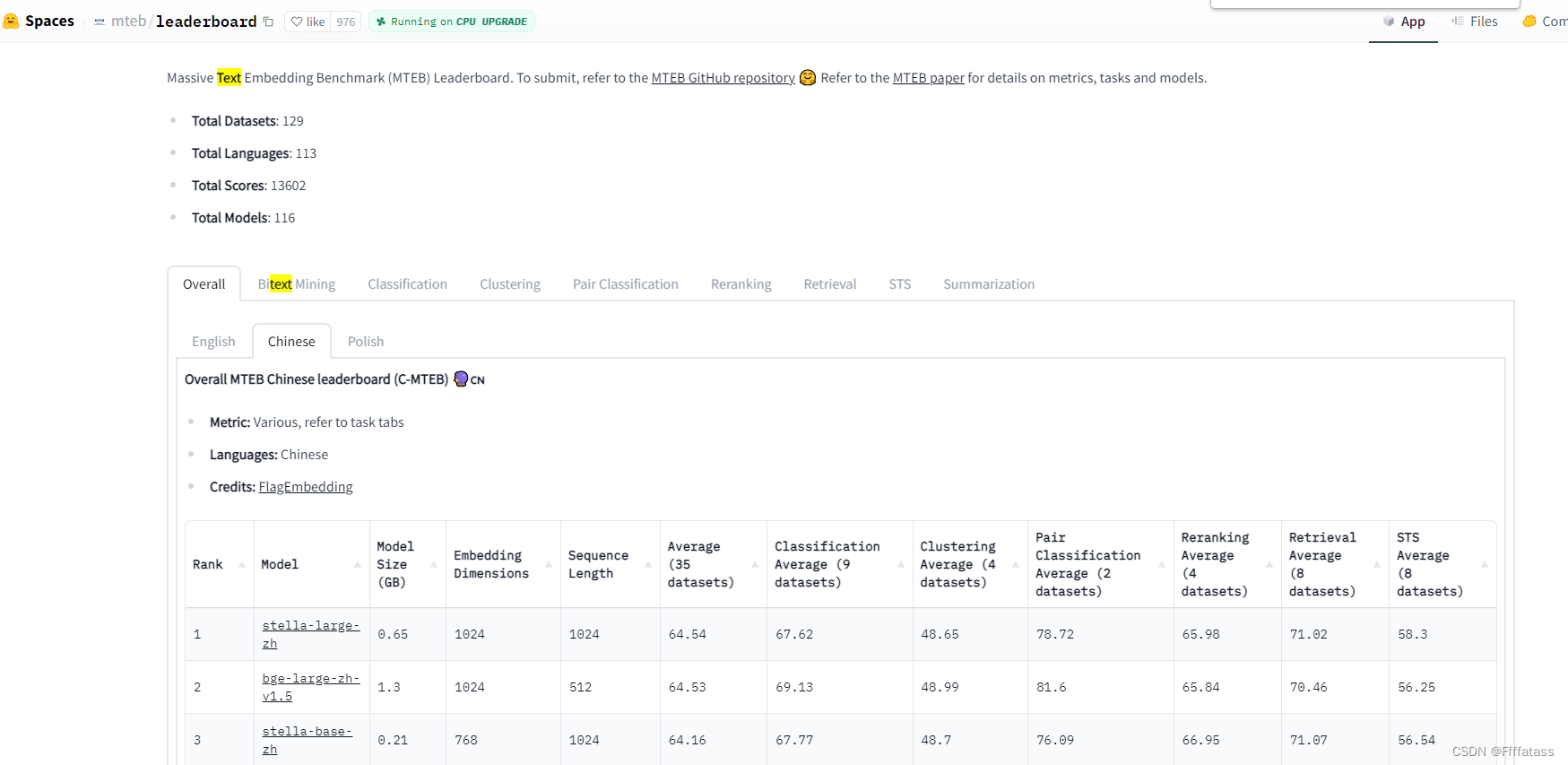
https://huggingface.co/spaces/mteb/leaderboard
是一个衡量不同模型Embedding算法的排名。模型选择时,我们可以参考榜单中我们关注的项目得分。如果榜单中没有我们想要的模型,也可以自己通过其GitHub提供的方式自行测试。
其理论基础来自于:https://arxiv.org/pdf/2210.07316.pdf
向量索引和向量数据库
现在使用的是ES提供的向量数据存储,其搜索方式是script_score。这种方式有一定的性能问题,ES在8.0版本也和其他向量库一样都采用了基于ANN算法的搜索方式。

现在的es作为向量数据库的优点是可以维护更少的服务,减轻业务的运维压力和学习成本,但是也存在以下问题:
1、暴力计算的方式在数据量变大之后存在性能损耗大的问题,极端情况下可能会拖慢其他业务,导致所有使用同一个es的业务收到牵连
2、现在的使用方式通过关键字匹配再进行向量相似性搜索会丢失一定的结果
3、当我去除关键字匹配,只使用向量匹配时,横向与其他向量库对比时,发现效果还是不好。(也印证了系统从最早的只有相似性匹配修改为加入关键字匹配)

我们现在搜索向量库的方式有点简单粗暴,举个例子:
当我发送一个问题:”今年,有哪些SolarWinds相关的漏洞“
我们现在的做法是会把这句话拆分成单词”今年“、”有“、”哪些“、”SolarWinds“、”相关“、”漏洞“,(实际系统是把今年这个词去掉了)然后把这些词拿到content做关键字匹配。但是我们的CVE元数据格式是这样的:

这种方式肯定是匹配不上用户的时间条件的。
相对温和的做法是将时间作为条件在元数据的date上做过滤,再把过滤后的结果做向量做相似性搜索。我们的做法就暴力在稀疏检索和稠密检索直接放到一个属性中,这种结合方式很难达到1+1>1的效果。而更好的做法应该是稀疏检索查询元数据时应该根据不能的条件在不同的属性上做过滤。稀疏检索和稠密检索结合也是业界常用的一种办法,它在术语匹配方面就有很好的效果,很多向量数据库提供的查询方法本来就融合了这两种方式,但是其都有一个较为完整的处理逻辑。


如果切换向量数据库有以下的优缺点
优点:
1、使用ANN近邻搜索,开销可控
2、与业务存储分离开
3、更多向量相关功能,例如:推荐、总结等能力
缺点:
1、运维、学习成本
2、系统复杂度提升














 1228
1228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









