







 本文综述了RAG(Retrieval-AugmentedGeneration)技术的发展,从NaiveRAG的基本架构到AdvancedRAG的预检索和后检索阶段,以及ModularRAG的模块化增强。文章强调了RAG在处理大语言模型问题中的挑战和优化策略,如噪声过滤、上下文整合等。
本文综述了RAG(Retrieval-AugmentedGeneration)技术的发展,从NaiveRAG的基本架构到AdvancedRAG的预检索和后检索阶段,以及ModularRAG的模块化增强。文章强调了RAG在处理大语言模型问题中的挑战和优化策略,如噪声过滤、上下文整合等。
论文链接:https://arxiv.org/pdf/2312.10997.pdf
GitHub链接:https://github.com/Tongji-KGLLM/RAG-Survey
不管看啥,看survey最能get全,今天咱们读一篇文献综述,然后我就要去写自己的研究框架了。希望这篇文章能给我力量!Power!!!YesYes,依旧还是关于RAG的内容。目前大语言模型的弊端已经人尽皆知,幻想就别提了,永远过时的知识储备,不透明没法溯源的推理过程,让人没头脑。于是呼风唤雨使出来了一堆新方案,Retrieval-Augmented Generation (RAG) 就是其中之一。复旦和同济大学的朋友们围绕RAG整了一篇survey,这篇综述主要分析了RAG的范式及其演变,RAG的主要技术(检索、生成和增强),测评RAG模型的指标和benchmark,测评框架。大概就是这些,接下来不细致得展开一下!
RAG,简明扼要得说就是在LLM要根据query生成answer前,咱们在外部数据上retrieve一下根据得到的相关信息,反哺给LLM,如下图示例:
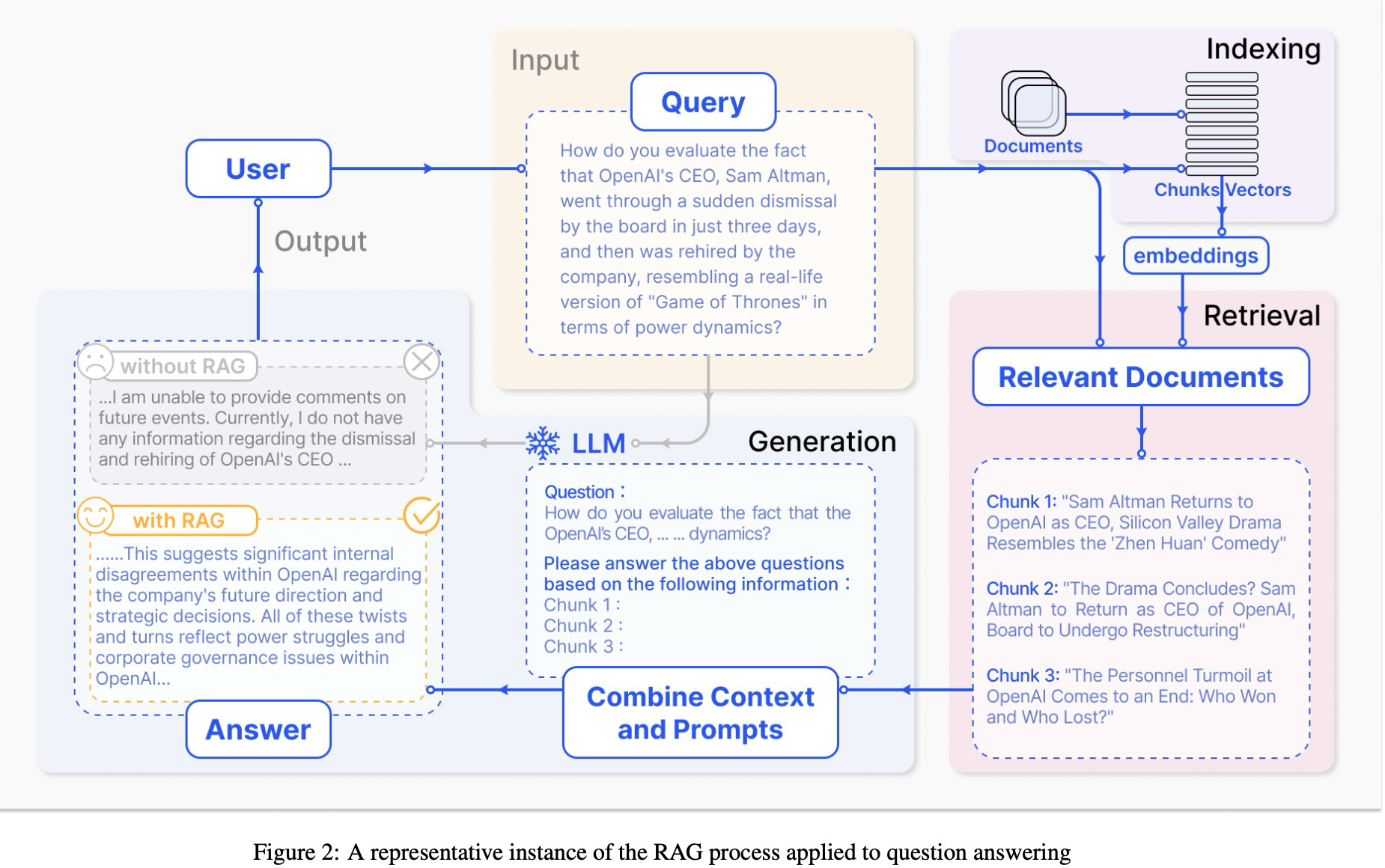
这个过程其实并不简单呢,因为我们需要保证咱们检索出来的这些信息能够有效得让大语言模型get到,这样LLM才不会一直幻想,无根无据的那种感觉。文章画了一个很棒棒的树图,描述了RAG发挥作用在三个阶段(pre-training,fine-tuning和inference)的相关模型。我想大家都知道,比如咱们老早之前总会在领域数据上去训练bert模型,然后把这个模型加载作为自己网络模型的输入,这个可以算是最早期在Pre-training阶段的尝试。chatgpt以后,随着越来越多的优秀LLM问世,RAG在pre-training,fine-tuning和inference都开始有更多方案。作者按照RAG范式的演变过程,把其分成了三类:
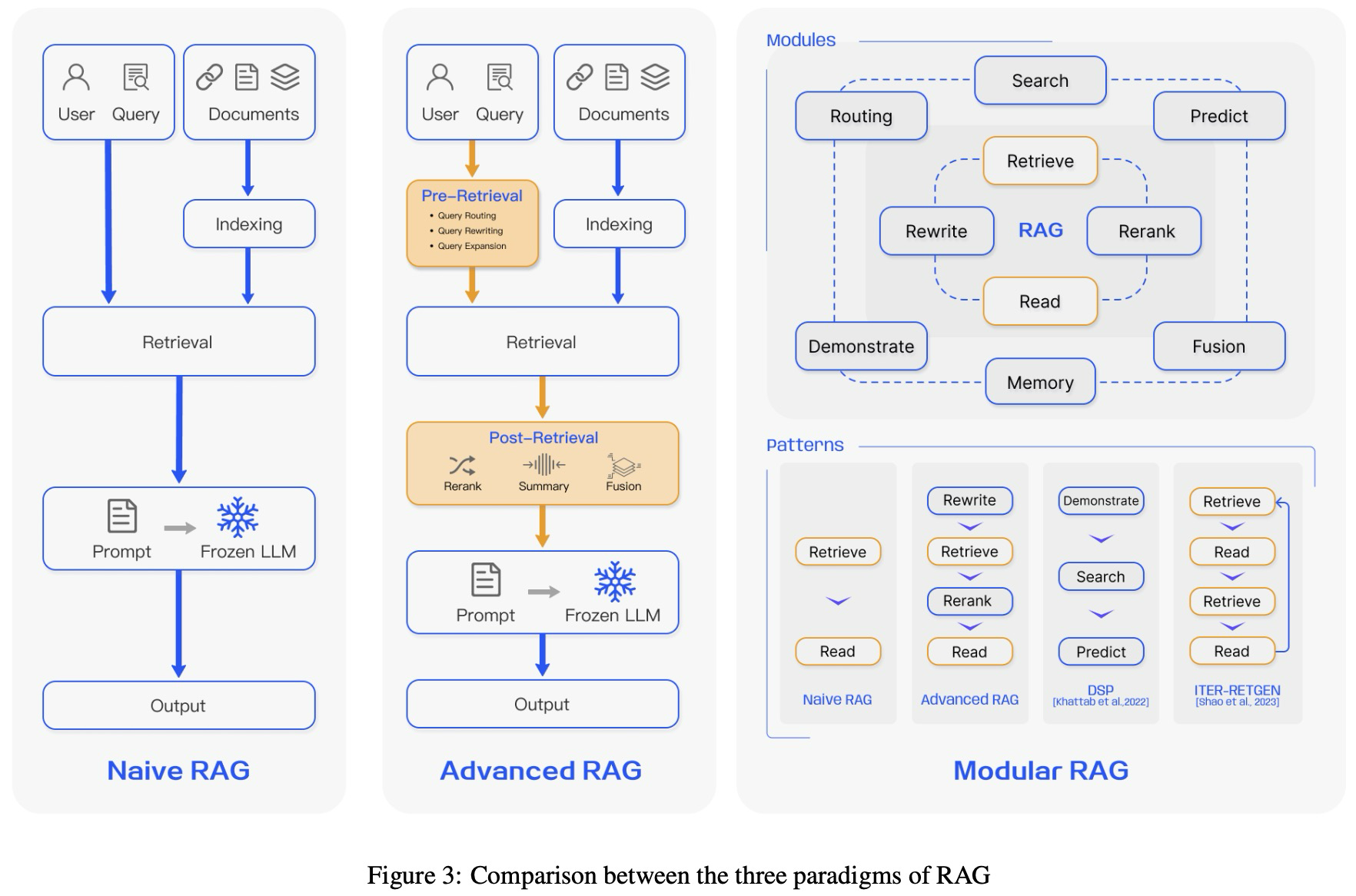
- Naive RAG
也可被称为retrieve-read框架。第一步是做Indexing,为了能够match上语言模型的上下文限制,首先需要把外部干净的数据进行分割(chunking),然后这些chunks会被向量化(embedding),然后把text chunks和对应的vector embedding当作key-value这么存储起来,以用于检索。第二步是做retrieval,用同样的embedding模型,我们对用户的query向量化,根据相似度得到TopK个最相似的text chunks。第三步是做Generation,得到相似的chunks后,这些内容将和用户之前的query一起通过一些模版啥的合并成一个prompt,拿去问大模型,大模型直接给出答案即可。这里,LLM需要根据其固有的参数知识,对所给信息进行响应。如果进行多轮对话,历史对话记录需不断集成到咱们的prompt里。Naive RAG的弊端,在于检索到的chunks可能质量不好;或者LLM没法习得所提供的信息,生成的答案与上下文无关;如果检索到多个包含相似信息的段落,生成结果可能也会重复,且没有办法提供综合的结果(比如一个问题需要结合ABC三个文章,但是返回了A1A2A3,于是LLM围绕A来回答,没考虑到B和C)。
- Advanced RAG
主要是围绕Naive RAG来做了一些升级,这里有了两个新阶段:pre-retrieval和post-retrieval。第一个pre-retrieval阶段的策略主要有,enhancing data granularity, optimizing index structures, adding metadata, alignment optimization, and mixed retrieval. Enchance data granularity,大概意思就是旨在提高外部数据,我们需要indexing的对象的标准化、一致性、准确性丰富上下文,因此可以做的有删除不相关的信息,消除实体或术语的歧义,确认事实的准确性,维护上下文以及更新过时的文章。Optimizing index structures则是调整chunks的大小/长短来得到更相关的上下文,我们可以在多个不同的数据里检索,或者利用图结构来发现有关联的节点。adding metadata可以将比如日期或者一些其他有用的attribute加入,以用于信息的过滤,或者利用元数据来进行一些信息的合并,以提高检索效率。alignment就是对齐文档之间的差异啦。那retrieval阶段可以做什么呢?因为我们之前主要是通过query的embedding来找相似的chunks,所以embedding这件事就很重要,这一阶段就主要围绕embedding模型的优化。Fine-tuning Embedding,可以利用领域数据微调embedding模型来提高找到relevant chunks的效果(特别是在专业领域有很多术语的时候);可以利用语言模型基于chunks生成问题,然后将问题-chunk对拿去做微调。Dynamic Embedding,利用上下文来做embedding,提到了Open AI的embedding工具(https://platform.openai.com/docs/guides/embeddings)。最后我们看下Post-Retrieval Process阶段,检索后我们需要把检索到的结果重新和用户query合并然后作为LLM的输入,这里会遇到比如context window limit这样的问题。如果一次把所有相关的文章都喂过去,很显然就会超出limit,或者带来noise,掩盖了关键信息。Re-Ranking,对检索到的结果进行重排序,LlamaIndex,Langchain或者HayStack都已经有这种技术了,还有那种看diversity的ranker,或者把最相关的放在context开头和结尾,或者把语义相似度算的更好一点。不得不说,又回到了传统NLP的感觉。就好像雕刻,大榔头敲一敲的时候,小榔头接着打磨打磨。Prompt Compression,由于检索结果中的噪音数据会严重影响RAG的效果,所以还有一套策略就是希望可以压缩不相关的信息,高亮相关信息。比如通过计算prompt的互信息和困惑度,来估计重要程度。或者用summarization的方式来增强关键信息的展现。
- Modular RAG
花花操作太多了,其主要目的就是通过各种方法来增强各个功能模块。Search Module,相比于retrieval,search更像是做个SQL查询,特定场景下直接搜索数据。Memory Module,利用LLM的记忆能力来引导检索,比如识别与当前输入最相似的记忆。Fusion,扩展用户query,拿着本身的query和扩展query去检索,重排,生成新的结果。Routing,这一步就是为查询选择action,比如搜索对象是啥,你是搜向量存储数据库,还是图数据,还是关系数据库,搜索完了以后需不需要合并一起或者怎么返回。Predict,旨在解决检索结果中的噪音信息和冗余信息,可由LLM来处理。Task Adapter,具体任务具体分析,围绕任务场景来个性化retriever。
看完RAG的演化,我们再看看RAG Pipeline的优化。Hybrid Search,检索可以用关键词、语义、向量等等来尽可能得到context-rich information。Recursive Retrieval and Query Engine,通过smaller chunks获得关键信息,通过larger chunks获得更多上下文信息。其他的还有StepBack-prompt,Sub-Queries,Hypothetical Document Embeddings。
话说回来,这篇文章后面还讲了很多东西,但是我看不下去了。。。我甚至看到了两段看起来不同但好像是在讲一件事情的描述。。。(就不放大图了不是什么好事,P9,原文作者要不要粗来看看update一下子)。

和

好的,读完了这篇文章,大概学到了RAG有很多细节问题,似乎回到了传统NLP的场景🤔。















 1490
1490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









