







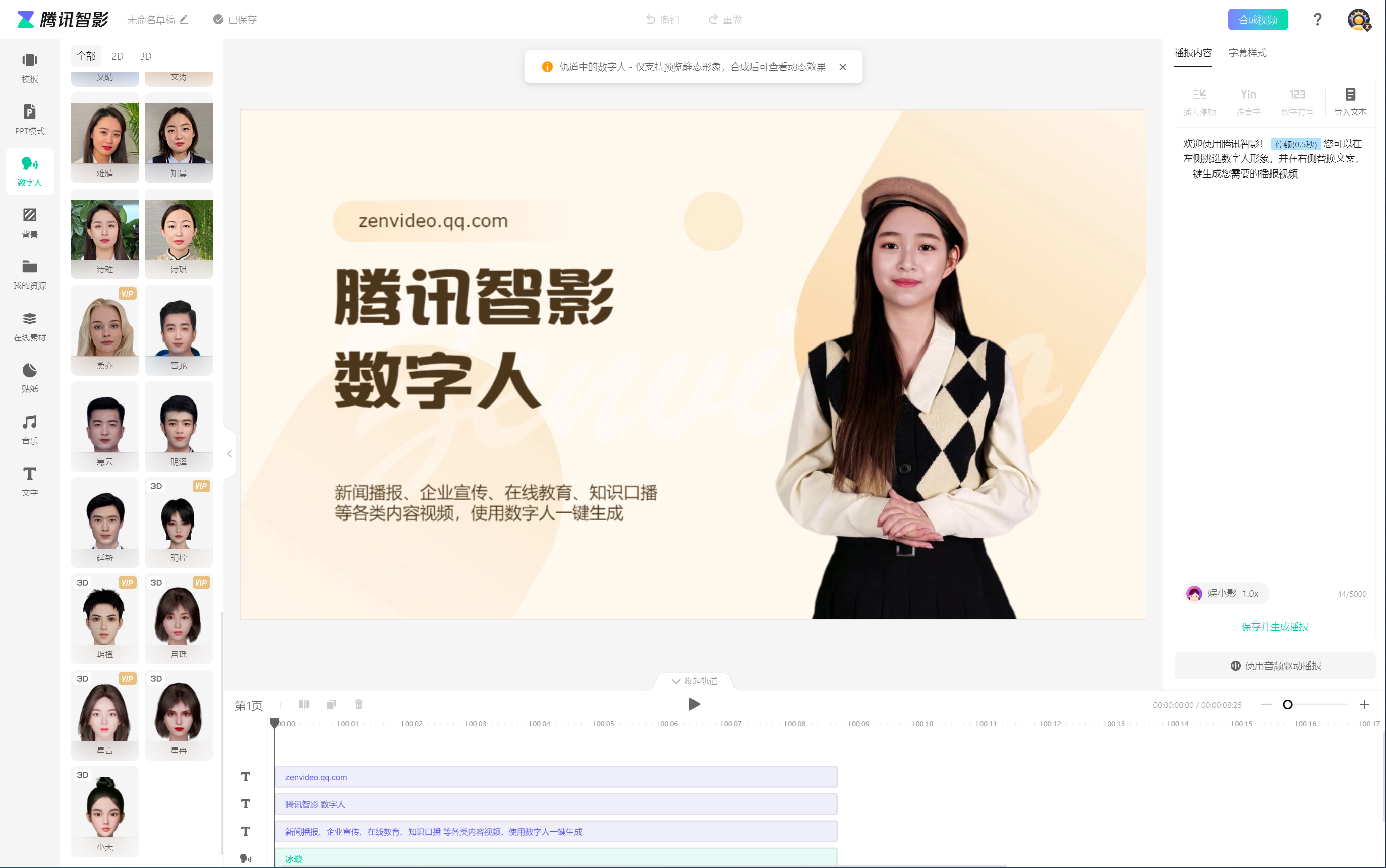
腾讯智影数字人工具
腾讯智影数字人的形象风格多样,包括写实、卡通等,可以满足不同年龄层观众的喜好。同时,腾讯智影数字人也提供了灵活的驱动方案,可以通过文本或配音直接生成视频,并支持数字人做出与视频一样的动作和表情。
MR虚拟直播
- MR直播实例(混合现实直播)高品质企业直播
- 企业年会直播来个虚拟舞台场景如何?
- MR直播(混合现实直播)做一场高品质企业培训
- MR场景直播-帮助企业高效开展更有意思的员工培训
- 企业多会场视频直播(主会场、分会场直播)实例效果
- 虚拟直播(虚拟场景直播)要怎么做?
无延迟直播
- 无延时直播/超低延时直播画面同步性测试(实测组图)
- 搞定企业视频直播:硬件设备、直播网络环境和设备连接说明
- 无延时/无延迟视频直播实例效果案例
- OBS无延迟视频直播完整教程(组图)
- 毫秒级超低延时直播产品实测(PRTC直播/webRTC直播)
视频加密与安全
- 企业培训视频如何防止被下载和盗用?
- 在线教育机构视频加密防下载和防盗用的方法有哪些可以借鉴
- 上新:视频加密功能增加防录屏(随机水印)功能
- 两种实现视频倍速播放的方法(视频播放器倍速1.5x/2x)
- 教育培训机构教学课程内容视频加密是如何做的?

















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









