







1. 推荐的种类
a) 朋友推荐,这叫社会化推荐,通过社交网络搞定。比如你女朋友like的零食,通过人人网推荐给你,你想不买都不行。
b) 推荐和自己喜欢的物品某种属性一致的物品,这叫基于内容的推荐。比如我喜欢宁浩的电影,以前在豆瓣上like了疯狂的石头,然后很快豆瓣就开始给我推荐《无人区》,我一看,比石头还好---好吧,夹带私货了。
c) 把人和人喜欢的物品总和起来考虑,要么推荐和我相似的用户喜欢的物品,要么推荐和我喜欢的物品类似的物品,这叫协同过滤
2. 协同过滤
2.1 基于用户的协同过滤算法(UserCF)
基于用户的协同过滤算法主要包括两个步骤。
(1) 找到和目标用户兴趣相似的用户集合。
(2) 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
比如下面的用户行为记录

如何计算用户兴趣相似度?余弦相似度公式:
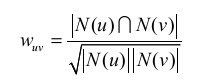
比如用户A对物品{a, b, d}有过行为,用户B对物品{a, c}有过行为,利用余弦相似度公式计算用户A和用户B的兴趣相似度为:
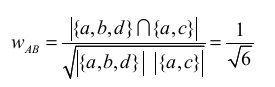
这个是余弦相似度的简化版,实际情况远没有这么简单。
这里有个关于余弦相似性的文章:http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
如果要一个一个计算余弦相似度,复杂性太,为了简化运算,可以建立物品-用户倒排表:
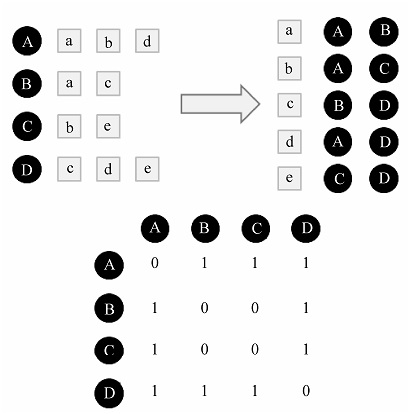
由此,可以较为简单的算出
W AC =1/√(3*2)
W AD =1/√(3*3)
得到兴趣相似度后,UserCF算法会给用户推荐和她兴趣最相近的K个用户喜欢的物品。如下公式度量了UserCF算法中用户u对物品i的感兴趣程度:
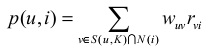
其中,S(u, K)包含和用户u兴趣最接近的K个用户,N(i)是对物品i有过行为的用户集合,Wuv 是用户u和v的兴趣相似度,rvi 代表用户v对物品i的兴趣。在不存在打分系统的情况下,兴趣就意味着买或不买,也就是1。
例子:
计算用户A对物品c的兴趣,取K=3。那么,S(u, K)就是B,C,D;N(c)就是和c发生过关系的用户集合,就是B和D,那么
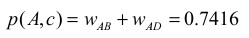
2.2 基于物品的协同过滤算法
基于物品的协同过滤算法主要分为两步。
(1) 计算物品之间的相似度。
(2) 根据物品的相似度和用户之前买过的物品给用户生成推荐列表。
如何计算物品的相似度?可以认为,如果喜欢某物品的用户大多也喜欢另一个物品,那这两个物品可以认为相似。比如啤酒和尿布的故事,这俩物品看起来毫无关系,但没准它们其实是相似的,下面进入小故事:
在一家超市中,人们发现了一个特别有趣的现象:尿布与啤酒这两种风马牛不相及的商品居然摆在一起。但这一奇怪的举措居然使尿布和啤酒的销量大幅增加了。这可不是一个笑话,而是一直被商家所津津乐道的发生在美国沃尔玛连锁超市的真实案例。原来,美国的妇女通常在家照顾孩子,所以她们经常会嘱咐丈夫在下班回家的路上为孩子买尿布,而丈夫在买尿布的同时又会顺手购买自己爱喝的啤酒。这个发现为商家带来了大量的利润。
用公式来表示物品i和j之间的相似性就是:

其中N(i)指买物品i的用户列表,而|N(i)|指这个列表的长度。
同样为了简化计算,列出用户-物品倒排列表。
ItemCF通过如下公式计算用户u对一个物品j的兴趣:
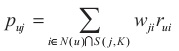
这里就是先列出和物品j相似的K个物品,如果该物品u买过,则叠加相似性。 也可认为是1。
下面是一个例子
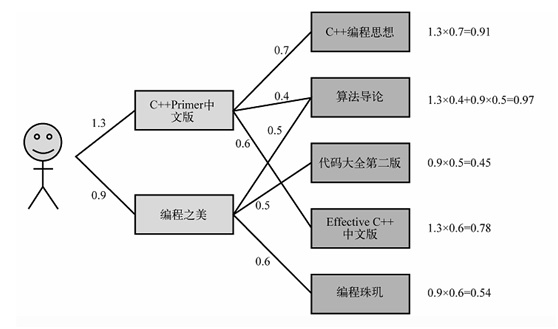
用户买过《C++ Primer中文版》和《编程之美》两本书。然后ItemCF计算用户对《算法导论》的兴趣值。那么查看这本书和《C++ Primer中文版》的相似度为0.4,而且这本书和《编程之美》的相似度是0.5。考虑到用户对《C++ Primer中文版》的兴趣度是1.3,对《编程之美》的兴趣度是0.9,那么用户对《算法导论》的兴趣度就是1.3 ×0.4 + 0.9×0.5 = 0.97。
2.3 基于图的推荐算法
二分图又称作二部图,是图论中的一种特殊模型。设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。用户行为很容易用二分图表示,因此很多图的算法都可以用到推荐系统中。
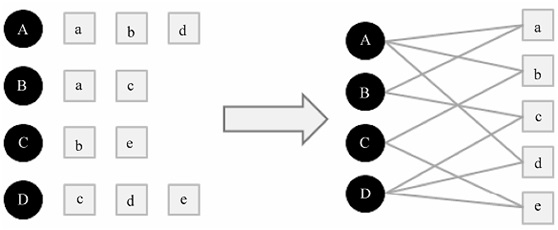
如果将个性化推荐算法放到二分图模型上,那么给用户推荐物品的任务就可以转化为度量用户顶点(如A)和与该节点没有边直接相连的物品节点(如e)在图上的相关性。
度量图中两个顶点之间相关性的方法很多,但一般来说图中顶点的相关性主要取决于下面3个因素:
1. 点之间的路径数;
2. 两个顶点之间路径的长度;
3. 两个顶点之间的路径经过的顶点。
而相关性高的一对顶点一般具有如下特征:
1. 点之间有很多路径相连;
2. 连接两个顶点之间的路径长度都比较短;
3. 连接两个顶点之间的路径不会经过出度比较大的顶点。
举一个简单的例子,如上图所示,用户A和物品c、e没有边相连,但是用户A和物品c有两条长度为3的路径相连,用户A和物品e有两条长度为3的路径相连。那么,顶点A与e之间的相关性要高于顶点A与c,因而物品e在用户A的推荐列表中应该排在物品c之前,因为顶点A与e之间有两条路径——(A, b, C, e)和(A, d, D, e)。其中,(A, b, C, e)路径经过的顶点的出度为(3, 2, 2, 2),而(A, d, D, e)路径经过的顶点的出度为(3, 2, 3, 2)。因此,(A, d, D, e)经过了一个出度比较大的顶点D,所以(A, d, D, e)对顶点A与e之间相关性的贡献要小于(A, b, C, e)。
根据上面三个要素,研究人员设计了很多算法,比如和PageRank算法十分类似的基于随机游走的PersonalRank算法。关于PageRank算法,我有另一篇博客介绍它的原理
http://blog.csdn.net/ffmpeg4976/article/details/44540313
下面看PersonalRank:
假设要给用户A行个性化推荐,可以从用户A应的节点开始在用户物品二分图上进行随
机游走。游走到任何一个节点时,首先按照概率a定是继续游走,还是停止这次游走并从A节点开始重新游走。如果决定继续游走,那么就从当前节点指向的节点中按照均匀分布随机选择一个节点作为游走下次经过的节点。这样,经过很多次迭代后,每个节点被访问到的概率会收敛到一个数,也包括物品节点。我们就按照这个概率去对物品节点排序并进行推荐。
公式
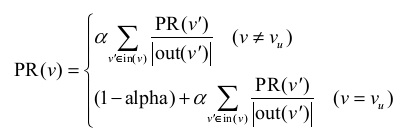
上面公式里的alpha就是a,不要confuse。
比如:
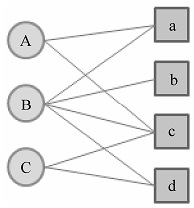
每个顶点的访问概率在9次迭代之后就基本上收敛了。在这个例子中,用户A没有对物品b、d有过行为。在最后的迭代结果中,d的访问概率大于b,因此优先给A推荐的物品就是d。
注:本文可以看做是《推荐系统实践》的笔记和阐释,这是本好书,向作者致敬。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









