







匹配样本的程序主要来自于下面这篇文献:
Brandt, L., et al. (2012). "Creative accounting or creative destruction? Firm-level productivity growth in Chinese manufacturing."Journal of Development Economic 97(2): 339-351.
作者公开了自己的代码,下载链接地址:http://feb.kuleuven.be/public/n07057/China/
其中一部分就是匹配样本,这里算是记录了自己对作者程序的注解。
clear all
set more off
global PATH "/Volumes/TOSHIBA EXT/Projects/NBS/China Industry Business Performance Data/Match Over Years"
cd "$PATH"
******************************************************************************
* Part 1
* Befor run this do-file, orignial_1998.dta ~ original_2007 must be already
* generated. Whic means that do-files 1998.do ~ 2007.do have already been
* runned.
*
* Generate a id variable (id_in_source) for further combining data set
* after match over years.
*
* Only keep match variables and id_in_source for the next steps
*****************************************************************************
forvalues i = 1998/2007{
disp "File `i'"
use `"../original_`i'.dta"',clear
* gen id_in_source = _n
if `i'==2003{
gen town = address
}
gen cic = cic_adj
replace cic = real(industry_code) if cic == .
/*
if year <2003{
gen cic = cic_adj
}
else{
gen cic = cic03
}
*/
if year<2004{
gen revenue = sales_revenue
}
else{
gen revenue = operating_revenue
}
gen profit = total_profit
if year ==1999 | year == 2002{
gen employment = staff
}
keep id_in_source firm_id firm_name legal_person town province ///
telephone zip product1 founding_year cic region_code revenue ///
employment profit
destring founding_year revenue employment profit,replace force
tostring cic,replace format(%04.0f)
rename firm_id id
rename firm_name name
rename founding_year bdat
rename region_code dq
rename product1 product1_
rename telephone phone
foreach var of varlist *{
rename `var' `var'`i'
}
compress
saveold m`i'.dta,replace
}
第二部分,跨期匹配样本。
forval i =1998/2007{
use m`i'.dta,clear
replace id`i' = strupper(id`i')
compress
saveold m`i'.10.dta,replace
}
forval i =1998/2007{
use m`i'.10.dta,clear
des,short
}2.使用循环,匹配连续两年之间的数据。loca i 代表当年年份,local j=i+1 代表未来一年。
Step 10. 根据法人代码 firm_id 匹配。
*deal with duplicates of IDs (There are a few firms that have same IDs)
disp "Step 10 "
use m`i'.10.dta,clear
bysort id`i': keep if _N>1
compress
saveold duplicates_ID`i'.dta,replace
use m`i'.10.dta,clear
bysort id`i': drop if _N>1
rename id`i' id
sort id
keep *`i' id
compress
saveold match`i'.1.dta,replace
use m`j'.10.dta,clear
bysort id`j': keep if _N>1
compress
saveold duplicates_ID`j'.dta,replace
use m`j'.10.dta,clear
bysort id`j': drop if _N>1
rename id`j' id
keep *`j' id
sort id
compress
saveold match`j'.1.dta,replace
use match`i'.1.dta,clear
merge 1:1 id using match`j'.1.dta
keep if _m==3
gen id`i' = id
rename id id`j'
drop _merge
gen match_method_`i'_`j'="ID"
gen match_status_`i'_`j'="3"
compress
saveold matched_by_ID`i'_`j'.dta,replace
匹配后生成三类文件:
duplicates_ID`i'.dta; duplicates_ID`j'.dta - 同一年内,多个企业共用同一id的企业文件;
match`i'.1.dta; match`j'.1.dta - 不存在多个企业共用同一id的企业文件,用于 连续两年之间的merge
matched_by_ID`i'_`j'.dta - match`i'.1.dta和 match`j'.1.dta merge之后 _m == 3 即利用id匹配成功的记录;
*另外 step10之后可以注意到没有匹配成功的记录并不包括在上述三类文件中,在后续合并步骤中这些记录还会被重新匹配。
Step20 利用 firmname 继续匹配Step10中未匹配的记录。
**step20: match by firm names**
*match those unmatched firms in previous step by firm names*
disp "Step 20 "
use match`i'.1.dta,clear
merge 1:1 id using match`j'.1.dta
keep if _m==1
rename id id`i'
append using duplicates_ID`i'.dta
bysort name`i': keep if _N>1
keep *`i'
compress
saveold duplicates_name`i'.dta,replace
use match`i'.1.dta,clear
merge 1:1 id using match`j'.1.dta
keep if _m==1
rename id id`i'
append using duplicates_ID`i'.dta
bysort name`i': drop if _N>1
rename name`i' name
sort name
keep *`i' name
compress
saveold unmatched_by_ID`i'.dta,replace
use match`i'.1.dta,clear
merge 1:1 id using match`j'.1.dta
keep if _m==2
rename id id`j'
append using duplicates_ID`j'.dta
bysort name`j': keep if _N>1
keep *`j'
compress
saveold duplicates_name`j'.dta,replace
use match`i'.1.dta,clear
merge 1:1 id using match`j'.1.dta
keep if _m==2
rename id id`j'
append using duplicates_ID`j'.dta
bysort name`j': drop if _N>1
rename name`j' name
sort name
keep *`j' name
compress
saveold unmatched_by_ID`j'.dta,replace
use unmatched_by_ID`i'.dta,clear
merge 1:1 name using unmatched_by_ID`j'.dta
keep if _m==3
gen name`i' = name
rename name name`j'
drop _m
gen match_method_`i'_`j'="firm name"
gen match_status_`i'_`j'="3"
compress
saveold matched_by_name`i'_`j'.dta,replace
匹配之后生成三类文件
duplicates_name`i'.dta - Step10中合并失败_m==1的文件+duplicates_ID`i'.dta中的文件 append在一起之后,存在多个企业共享“企业名称”字段的记录。
duplicates_name`j'.dta - Step10中合并失败_m==2的文件+duplicates_ID`j'.dta中的文件 append在一起之后,存在多个企业共享“企业名称”字段的记录。
unmatched_by_ID`i'.dta - Step10中合并失败_m==1且不存在共享“企业名称”字段的记录,用于按照firm_name merge.
unmatched_by_ID`i'.dta - Step10中合并失败_m==2且不存在共享“企业名称”字段的记录,用于按照firm_name merge.
matched_by_name`i'_`j'.dta unmatched_by_ID`i'.dta 和 unmatched_by_ID`j'.dta merge 之后匹配成功的记录,即按照firm_name匹配成功。
*另外 step10之后可以注意到没有匹配成功的记录并不包括在上述三类文件中,也就是既不能按照id也不能按照name匹配成功的记录,在后续合并步骤中这些记录还会被重新匹配。
Step30 利用 法人 legal person 继续匹配Step10中未匹配的记录。
思路与Step10一致,同样生成了三类文件。
disp "Step 30 "
use unmatched_by_ID`i'.dta,clear
merge 1:1 name using unmatched_by_ID`j'.dta
keep if _m == 1
rename name name`i'
append using duplicates_name`i'.dta
replace legal_person`i' = "." if legal_person`i' == ""
gen code1 = legal_person`i' + substr(dq`i',1,4)
bysort code1: keep if _N>1
keep *`i'
compress
saveold duplicates_code1_`i'.dta,replace
use unmatched_by_ID`i'.dta,clear
merge 1:1 name using unmatched_by_ID`j'.dta
keep if _m == 1
rename name name`i'
append using duplicates_name`i'.dta
replace legal_person`i' = "." if legal_person`i' == ""
gen code1 = legal_person`i' + substr(dq`i',1,4)
bysort code1: drop if _N>1
sort code1
keep code1 *`i'
compress
saveold unmatched_by_ID_and_name`i'.dta,replace
use unmatched_by_ID`i'.dta,clear
merge 1:1 name using unmatched_by_ID`j'.dta
keep if _m == 2
rename name name`j'
append using duplicates_name`j'.dta
* replace legal_person`j' = "." if legal_person`j' == ""
gen code1 = legal_person`j' + substr(dq`j',1,4)
bysort code1: keep if _N>1
keep *`j'
compress
saveold duplicates_code1_`j'.dta,replace
use unmatched_by_ID`i'.dta,clear
merge 1:1 name using unmatched_by_ID`j'.dta
keep if _m == 2
rename name name`j'
append using duplicates_name`j'.dta
* replace legal_person`j' = "." if legal_person`j' == ""
gen code1 = legal_person`j' + substr(dq`j',1,4)
bysort code1: drop if _N>1
sort code1
keep code1 *`j'
compress
saveold unmatched_by_ID_and_name`j'.dta,replace
use unmatched_by_ID_and_name`i'.dta,clear
disp _N
merge 1:1 code1 using unmatched_by_ID_and_name`j'.dta
keep if _m==3
drop _m code1
gen match_method_`i'_`j' = "legal_person"
gen match_status_`i'_`j' = "3"
compress
saveold matched_by_legalperson`i'_`j'.dta,replace
matched_by_legalperson`i'_`j'.dta
matched_by_phone`i'_`j'.dta
matched_by_code3_`i'_`j'.dta
unmatched_by_ID_and_name_and_legalperson_and_phone_and_code2`i'.dta
unmatched_by_ID_and_name_and_legalperson_and_phone_and_code2`j'.dta
将这六个文件合并,就得到了所有连续两年匹配后的样本
disp "Step 60 "
use matched_by_ID`i'_`j'.dta,clear
append using matched_by_name`i'_`j'.dta
append using matched_by_legalperson`i'_`j'.dta
append using matched_by_phone`i'_`j'.dta
append using matched_by_code3_`i'_`j'.dta
append using unmatched_by_ID_and_name_and_legalperson_and_phone_and_code2`i'.dta
append using unmatched_by_ID_and_name_and_legalperson_and_phone_and_code2`j'.dta
compress
saveold m`i'-m`j'.dta,replace
匹配后的效果以m1998-m1999.dta为例:
这里只用开头的文件作为检查是不合适的,应该同时使用m2006-m2007.dta作为检查。

对比 Brandet(2012)中每年记录数目的表格:

可以验证合并过程没有问题,根据图1,1998年-1999年匹配的有140653条,未匹配成功1998年的共有24465条,相加刚好是165118条;其他年份的数据经检验后也是如此。至此,连续两年的跨期合并执行结束。
**Step 70: Create a three-year balanced sample
disp "Step 70 "
use m`i'-m`j'.dta,clear
keep if match_status_`i'_`j' == "1"
keep *`i'
compress
saveold unmatched`i'.10.dta,replace
use m`i'-m`j'.dta,clear
drop if match_status_`i'_`j' == "1"
gen code = id`j'+string(revenue`j')+string(employment`j')+string(profit`j')+province`j'
sort code
compress
saveold m`i'-m`j'.10.dta,replace
use m`j'-m`k'.dta,clear
keep if match_status_`j'_`k' == "2"
keep *`k'
compress
saveold unmatched`k'.10.dta,replace
use m`j'-m`k'.dta,clear
drop if match_status_`j'_`k' == "2"
gen code = id`j'+string(revenue`j')+string(employment`j')+string(profit`j')+province`j'
sort code
compress
saveold m`j'-m`k'.10.dta,replace
use m`i'-m`j'.10.dta,clear
merge 1:1 code using m`j'-m`k'.10.dta
drop _m code
keep if match_status_`i'_`j'=="3" & match_status_`j'_`k'=="3"
gen match_status_`i'_`k'="3"
gen match_method_`i'_`k'="`j'"
compress
saveold balanced.m`i'-m`j'-m`k'.dta,replace
执行之后生成了如下几类文件
unmatched`i'.10.dta - 来自于 m`i'-m`j'.dta 中,未成功匹配且仅在year i 中的记录。
m`i'-m`j'.10.dta - 来自于 m`i'-m`j'.dta中,包括成功匹配的和仅在year j中的记录。
unmatched`k'.10.dta - 来自于m`j'-m`k'.dta中,未成功匹配且仅在year k中的记录
m`j'-m`k'.10.dta - 来自于m`j'-m`k'.dta中,包括成功匹配和仅在year j中的记录
balanced.m`i'-m`j'-m`k'.dta - m`i'-m`j'.10.dta和m`j'-m`k'.10.dta merge之后,两边都match的记录,即连续三年均出现的记录。
Step 80. 生成未成功匹配的文件,用于后续的匹配。
Step 70 生成了连续三年的平衡面板数据,但还有部分记录未能match起来,这一部分就是提取出这部分数据以便用于进一步的匹配。
**Step 80: Creat files for unmatched `i' firms and `k' firms**
disp "Step 80"
use m`i'-m`j'.10.dta,clear
merge 1:1 code using m`j'-m`k'.10.dta
drop _m code
drop if match_status_`i'_`j'=="3" & match_status_`j'_`k'=="3"
drop if id`i'==""
gen code = id`i'+string(revenue`i')+string(employment`i')+string(profit`i')+province`i'
sort code
compress
saveold unmatched`i'.15.dta,replace
use unmatched`i'.15.dta,clear
keep *`i'
append using unmatched`i'.10.dta
compress
saveold unmatched`i'.20.dta,replace
use m`i'-m`j'.10.dta,clear
merge 1:1 code using m`j'-m`k'.10.dta
drop _m code
drop if match_status_`i'_`j'=="3" & match_status_`j'_`k'=="3"
drop if id`k'== ""
gen code = id`k'+string(revenue`k')+string(employment`k')+string(profit`k')+province`k'
sort code
compress
saveold unmatched`k'.15.dta,replace
use unmatched`k'.15.dta,clear
keep *`k'
append using unmatched`k'.10.dta
compress
saveold unmatched`k'.20.dta,replace
use m`i'-m`j'.10.dta,clear
merge 1:1 code using m`j'-m`k'.10.dta
drop _m code
drop if match_status_`i'_`j'=="3" & match_status_`j'_`k'=="3"
gen code = id`j'+string(revenue`j')+string(employment`j')+string(profit`j')+province`j'
sort code
compress
saveold unmatched`j'.15.dta,replace
生成的各个文件的含义
unmatched`i'.15.dta - m`i'-m`j'.10.dta和m`j'-m`k'.10.dta merge之后不在平衡面板中且仅仅来自于year i的记录。
unmatched`i'.20.dta - unmatched`i'.15.dta 与 unmatched`i'.10.dta append起来的记录,其中 10.dta 是由Step70生成,表示 m`i'-m`j'.dta 中仅仅来自于year i 的记录。二者合并之后得到的就是目前为止所有来自于i的未能匹配的记录。
unmatched`k'.15.dta - 同unmatched`i'.15.dta
unmatched`k'.20.dta - 同unmatched`i'.20.dta
unmatched`j'.15.dta - m`i'-m`j'.10.dta和m`j'-m`k'.10.dta merge之后 不在平衡面板中所有记录(与 以i, k为下表的同类文件相比,由于这次merge肯定是完全merge,因此所有都是“无法按照j进行match的记录”,但显然这样存在一定的重叠。后续在合并的时候会对这里的重叠部分进行处理)
Step90 对Step80中得到的未匹配数据(即不在三年平衡面板中的记录:ummatched`i'.20.dta,unmatched`k'.20.dta)进行再一次匹配,运用 firm_id 和firm_name 进行匹配。
匹配思路与构建两年平衡面板时对应的处理思路是完全一样的:先确定有否duplicates的现象,区分后分别merge
**Step 90: Match `i' firms and `k' firms by firm ID and name**
*ID*
disp "Step 90"
use unmatched`i'.20.dta,clear
bysort id`i': keep if _N>1
compress
saveold duplicates_ID`i'.dta,replace
use unmatched`i'.20.dta,clear
bysort id`i': drop if _N>1
rename id`i' id
keep *`i' id
sort id
compress
saveold match`i'.1.dta,replace
use unmatched`k'.20.dta,clear
bysort id`k': keep if _N>1
compress
saveold duplicates_ID`k'.dta,replace
use unmatched`k'.20.dta,clear
bysort id`k': drop if _N>1
rename id`k' id
keep *`k' id
sort id
compress
saveold match`k'.1.dta,replace
use match`i'.1.dta,clear
merge 1:1 id using match`k'.1.dta
keep if _m==3
gen id`i'=id
rename id id`k'
drop _m
gen match_method_`i'_`k'="`j'"
gen match_status_`i'_`k'="3"
compress
saveold matched_by_ID`i'_`k'.dta,replace
*name*
use match`i'.1.dta, clear
merge 1:1 id using match`k'.1.dta
keep if _merge==1
rename id id`i'
append using duplicates_ID`i'.dta
bysort name`i': keep if _N>1
keep *`i'
compress
saveold duplicates_name`i'.dta, replace
use match`i'.1.dta, clear
merge 1:1 id using match`k'.1.dta
keep if _merge==1
rename id id`i'
append using duplicates_ID`i'.dta
bysort name`i': drop if _N>1
rename name`i' name
sort name
keep name *`i'
compress
saveold unmatched_by_ID`i'.dta, replace
use match`i'.1.dta, clear
merge 1:1 id using match`k'.1.dta
keep if _merge==2
rename id id`k'
append using duplicates_ID`k'.dta
bysort name`k': keep if _N>1
keep *`k'
compress
saveold duplicates_name`k'.dta, replace
use match`i'.1.dta, clear
merge 1:1 id using match`k'.1.dta
keep if _merge==2
rename id id`k'
append using duplicates_ID`k'.dta
bysort name`k': drop if _N>1
rename name`k' name
sort name
keep name *`k'
compress
saveold unmatched_by_ID`k'.dta, replace
use unmatched_by_ID`i'.dta, clear
merge 1:1 name using unmatched_by_ID`k'.dta
keep if _merge==3
gen name`i'=name
rename name name`k'
drop _merge
gen match_method_`i'_`k'="firm name"
gen match_status_`i'_`k'="3"
compress
saveold matched_by_name`i'_`k'.dta, replace
use unmatched_by_ID`i'.dta, clear
merge 1:1 name using unmatched_by_ID`k'.dta
keep if _merge==1
rename name name`i'
keep *`i'
append using duplicates_name`i'.dta
gen match_method_`i'_`k'=""
gen match_status_`i'_`k'="1"
compress
saveold unmatched_by_ID_and_name_`i'.dta, replace
use unmatched_by_ID`i'.dta, clear
merge 1:1 name using unmatched_by_ID`k'.dta
keep if _merge==2
rename name name`k'
keep *`k'
append using duplicates_name`k'.dta
gen match_method_`i'_`k'=""
gen match_status_`i'_`k'="2"
compress
saveold unmatched_by_ID_and_name_`k'.dta, replace执行之后得到了如下几个文件:
matched_by_ID`i'_`k'.dta, clear
matched_by_name`i'_`k'.dta
unmatched_by_ID_and_name_`i'.dta
unmatched_by_ID_and_name_`k'.dta
文件含义从名字上就已经很清楚。
Step 100 合并所有文件,处理冲突问题,生成连续三年的非平衡面板
**step 100: merge the files**
disp "Step 100"
use matched_by_ID`i'_`k'.dta, clear
append using matched_by_name`i'_`k'.dta
append using unmatched_by_ID_and_name_`i'.dta
append using unmatched_by_ID_and_name_`k'.dta
compress
saveold m`i'-m`k'.dta, replace
use m`i'-m`k'.dta, clear
gen code = id`i'+string(revenue`i')+string(employment`i')+string(profit`i')+province`i'
sort code
*drop if code == "..."
merge code using unmatched`i'.15.dta
drop code _merge
sort id`i'
compress
compress
saveold m`i'-m`k'.05.dta, replace
*deal with disagreement (_merge==5 if "update" is used)*
use m`i'-m`k'.05.dta, clear
gen code = id`k'+string(revenue`k')+string(employment`k')+string(profit`k')+province`k'
sort code
merge code using unmatched`k'.15.dta, update
keep if _merge==5
drop *`k'
drop code _merge
sort id`i'
compress
compress
saveold m`i'-m`k'.disagree.dta, replace
use m`i'-m`k'.05.dta, clear
merge id`i' using m`i'-m`k'.disagree.dta
drop if _merge==3
drop _merge
append using m`i'-m`k'.disagree.dta
gen code = id`k'+string(revenue`k')+string(employment`k')+string(profit`k')+province`k'
sort code
merge code using unmatched`k'.15.dta, update
drop code _merge
gen code = id`j'+string(revenue`j')+string(employment`j')+string(profit`j')+province`j'
sort code
merge code using unmatched`j'.15.dta, update
drop code _merge
compress
saveold m`i'-m`k'.dta.10.dta, replace
use m`i'-m`k'.dta.10.dta, clear
append using balanced.m`i'-m`j'-m`k'.dta
drop match_status_`i'_`j'
drop match_status_`j'_`k'
drop match_status_`i'_`k'
drop match_method_`i'_`j'
drop match_method_`j'_`k'
drop match_method_`i'_`k'
gen match_status_`i'_`j'_`k'="`i'-`j'-`k'" if id`i'!=""&id`j'!=""&id`k'!=""
replace match_status_`i'_`j'_`k'="`i'-`j' only" if id`i'!=""&id`j'!=""&id`k'==""
replace match_status_`i'_`j'_`k'="`j'-`k' only" if id`i'==""&id`j'!=""&id`k'!=""
replace match_status_`i'_`j'_`k'="`i'-`k' only" if id`i'!=""&id`j'==""&id`k'!=""
replace match_status_`i'_`j'_`k'="`i' no match" if id`i'!=""&id`j'==""&id`k'==""
replace match_status_`i'_`j'_`k'="`j' no match" if id`i'==""&id`j'!=""&id`k'==""
replace match_status_`i'_`j'_`k'="`k' no match" if id`i'==""&id`j'==""&id`k'!=""
compress
saveold unbalanced.`i'-`j'-`k'.dta, replace
执行完了之后 以unbalanced.1998-1999-2000.dta,检查匹配状况:
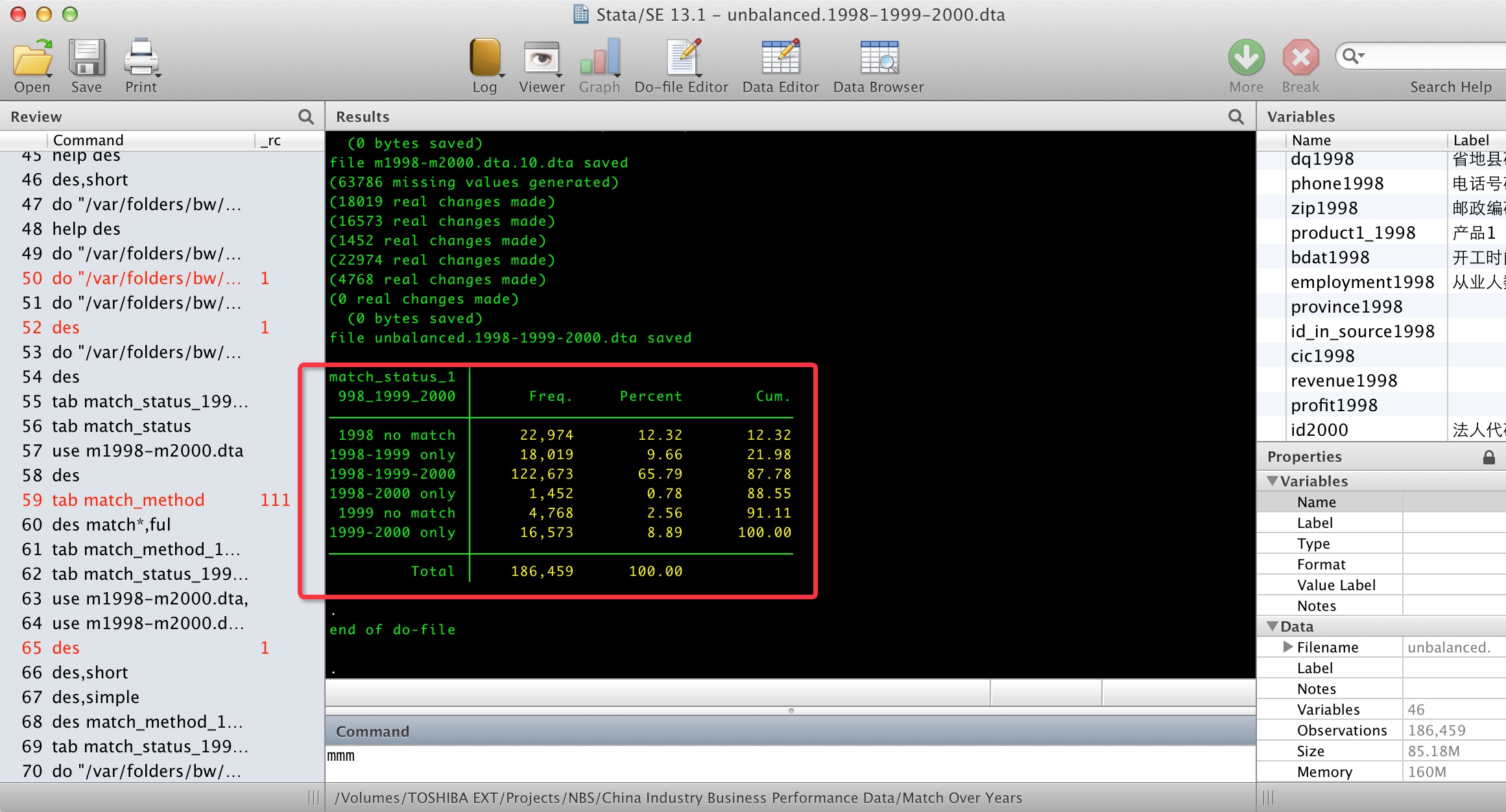
可以验证合并过程没有问题
*最初只用了unbalanced.1998-1999-2000.dta作为检查对象,没有用unbalanced.2005-2006-2007.dta 同时做检查,导致有一个小错误没有发现,所有检查应注意至少检测所有的情况。
第三部分,生成10年的非平衡面板。
首先,将1998-1999-2000的非平衡面板保存为test1.dta
use unbalanced.1998-1999-2000.dta, clear
tab match_status_1998_1999_2000
gen code=id2000+string(revenue2000)+string(employment2000)+string(profit2000)
sort code
save test1.dta, replace
Step 110. 将2011年的数据合并进来
**step 110: add 2001 from 1999-2000-2001**
use unbalanced.1999-2000-2001.dta, clear
tab match_status_1999_2000_2001
keep if match_status_1999_2000_2001=="1999-2000-2001"|match_status_1999_2000_2001=="2000-2001 only"
gen code=id2000+string(revenue2000)+string(employment2000)+string(profit2000)
sort code
save test2.dta, replace
use test1.dta, clear
merge code using test2.dta
tab _merge
drop _merge code
gen code=id1999+string(revenue1999)+string(employment1999)+string(profit1999)
sort code
save test3.dta, replace
use unbalanced.1999-2000-2001.dta, clear
tab match_status_1999_2000_2001
keep if match_status_1999_2000_2001=="1999-2001 only"
gen code=id1999+string(revenue1999)+string(employment1999)+string(profit1999)
sort code
save test4.dta, replace
use test3.dta, clear
merge code using test4.dta, update
tab _merge
drop code _merge
save test5.dta, replace
use test3.dta, clear
merge code using test4.dta, update replace
keep if _merge==5
keep id2001 bdat2001 cic2001 dq2001 e_HMT2001 e_collective2001 e_foreign2001 e_individual2001 e_legal_person2001 e_state2001 employment2001 export2001 fa_net2001 fa_original2001 a_dep2001 c_dep2001 input2001 name2001 new_product2001 output2001 profit2001 revenue2001 type2001 va2001 wage2001 legal_person2001 phone2001 product1_2001 street2001 town2001 village2001 zip2001
save test6.dta, replace
use unbalanced.1999-2000-2001.dta, clear
keep if match_status_1999_2000_2001=="2001 no match"
display _N
save test7.dta, replace
use test5.dta, clear
append using test6.dta
dis _N
append using test7.dta
dis _N
gen code=id2001+string(revenue2001)+string(employment2001)+string(profit2001)
sort code
save test1.dta, replace思路如下:
从 1999-2000-2001中挑选出 以2000年为合并基准的记录,保存为test2.dta
将test1.dta和test2.dta 依据 code2000 merge起来,存为test3
从 1999-2000-2001中挑选出 以1999年为合并基准的记录,保存为test4.dta
将test3.dta和test4.dta依据code1999 merge起来,存为test5.
将test3.dta和test4.dta依据code1999 merge起来,取值存在冲突的记录,存为test6. test3.dta和test4.dta中公共的部分是var2000-var2002。如果merge的时候这部分公共变量有不同,说明不是同一条,应作为两条数据处理。
将2001年未能匹配的记录存为test7.dta
append test5.dta, test6.dta, test7.dta。
随后,通过Step120将2002将2002合并进来,。。。,直到顺次将2007也合并进来,就得到了这样一个非平衡面板。
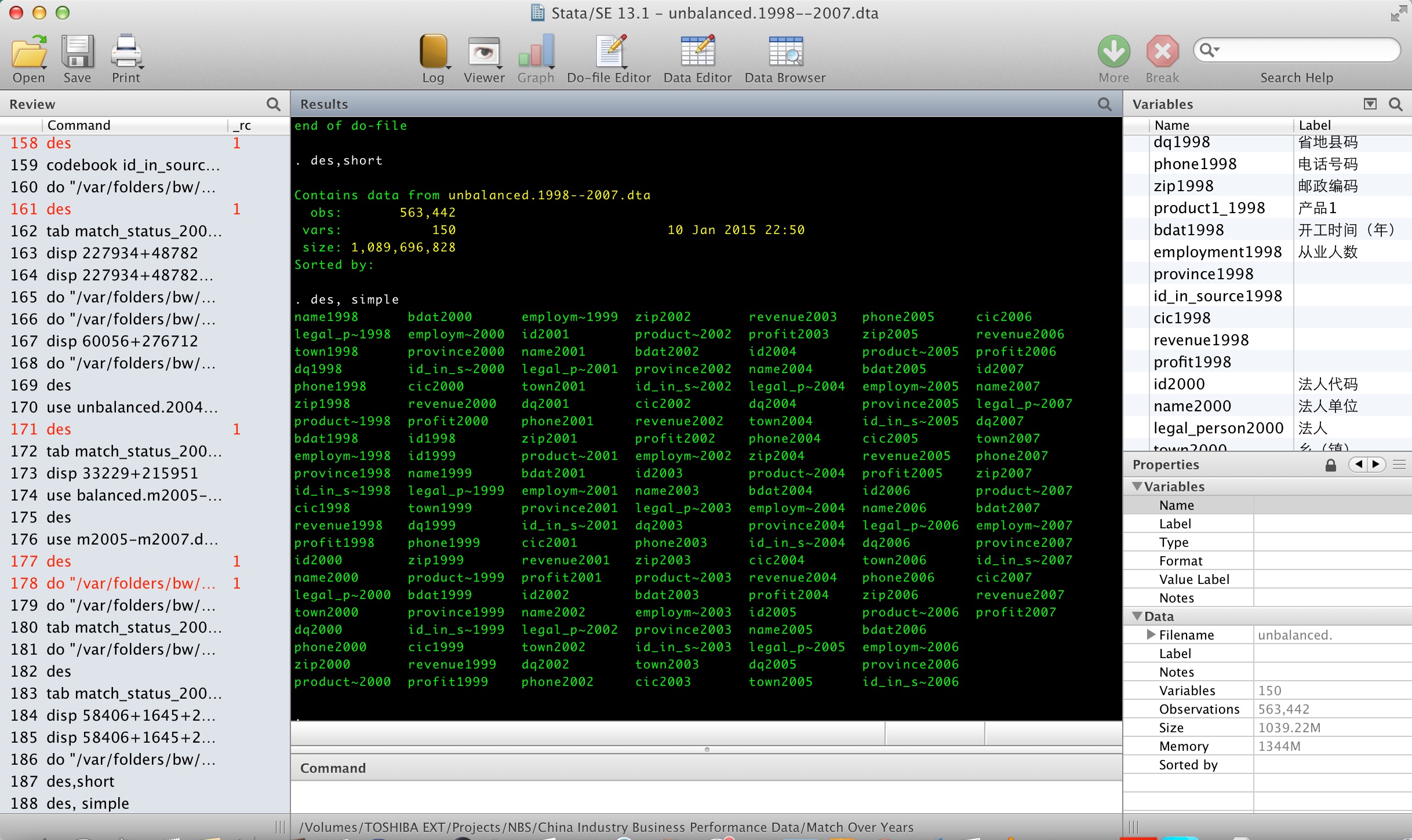
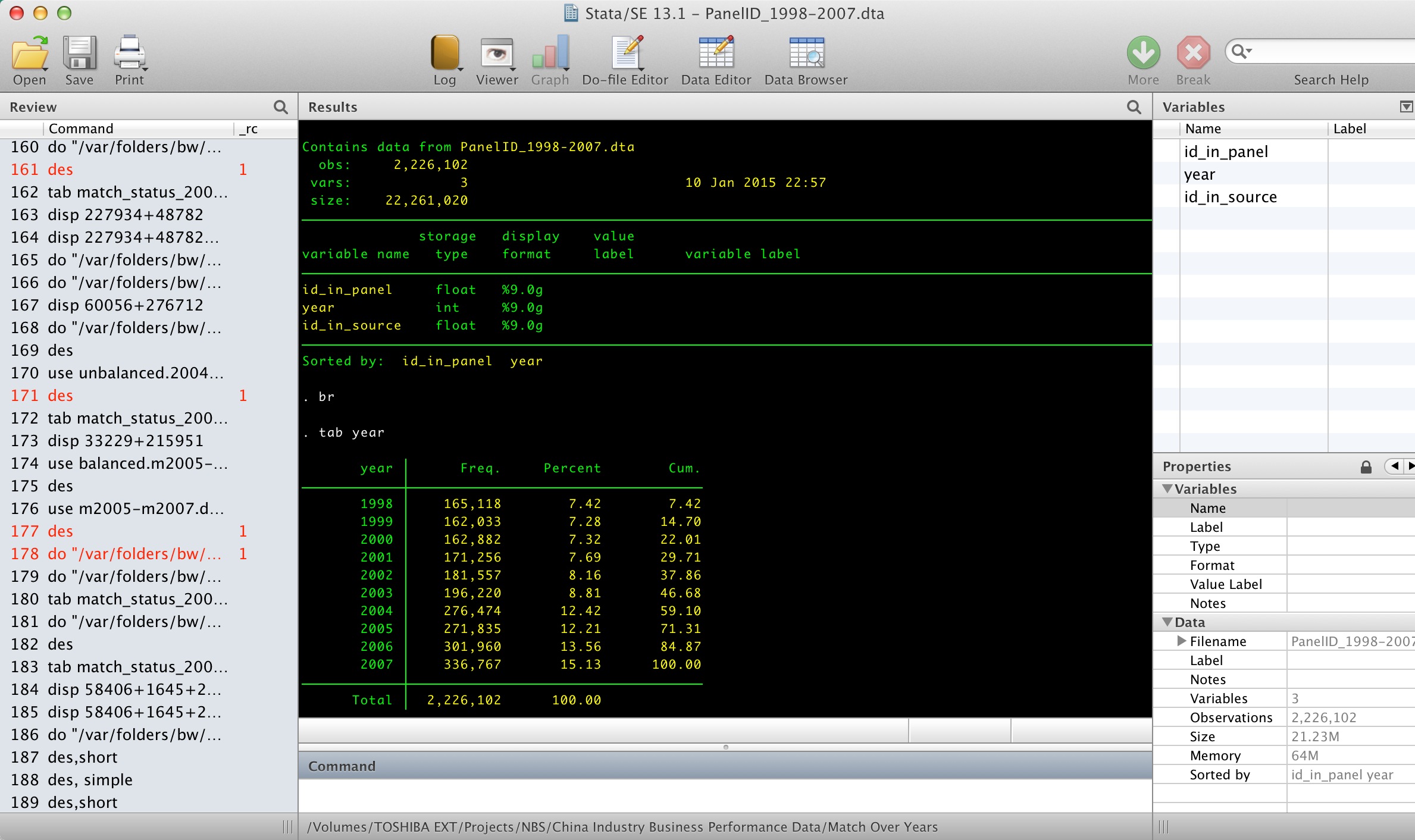
最后,通过下面的代码,得到面板和原始数据的对应关系
use "unbalanced.1998--2007.dta",clear
keep id_in_source*
gen id_in_panel=_n
reshape long id_in_source, i(id_in_panel) j(year)
drop if id_in_source == .
sort id_in_panel year
saveold "PanelID_1998-2007.dta",replace
*由于数据库来源的问题,我使用的数据与Brandt(2012)的数据在某些年份上存在一定的误差。(主要是2004年,所用的数据来自于全国经济普查,这同时也导致了很多关键指标的缺失等问题)
至此,匹配程序处理完毕,完整版程序见另一篇博文: 工业企业数据库处理代码完整版本——2.匹配样本 。















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









