






原文链接:FaceNet:A Unified Embedding for Face Recognition and Clustering
首先可以看一下最终的效果,数字表示两张图片经过Facenet提取的特征之间的欧式距离,可以直接表示两张图片的差异:

从图中可以看出,若取阈值为1.1,可以很轻易的区分出两张照片是不是同一个人。
网络结构:

上图是文章中所采用的网络结构,其中,前半部分就是一个普通的卷积神经网络,但是与一般的深度学习架构不一样,Facenet没有使用Softmax作为损失函数,而是先接了一个l2**嵌入**(Embedding)层。
所谓嵌入,可以理解为一种映射关系,即将特征从原来的特征空间中映射到一个新的特征空间,新的特征就可以称为原来特征的一种嵌入。
这里的映射关系是将卷积神经网络末端全连接层输出的特征映射到一个超球面上,也就是使其特征的二范数归一化,然后再以Triplet Loss为监督信号,获得网络的损失与梯度。
Triplet Loss也正是这篇文章的特点所在,接下来我们重点介绍一下。
Triplet Loss
什么是Triplet Loss呢?顾名思义,也就是根据三张图片组成的三元组(Triplet)计算而来的损失(Loss)。
其中,三元组由Anchor(A),Negative(N),Positive(P)组成,任意一张图片都可以作为一个基点(A),然后与它属于同一人的图片就是它的P,与它不属于同一人的图片就是它的N。
Triplet Loss的学习目标可以形象的表示如下图:
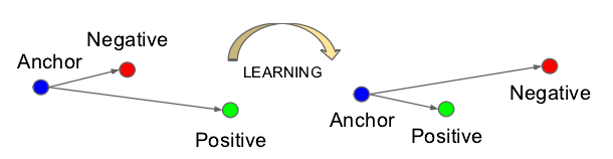
网络没经过学习之前,A和P的欧式距离可能很大,A和N的欧式距离可能很小,如上图左边,在网络的学习过程中,A和P的欧式距离会逐渐减小,而A和N的距离会逐渐拉大。
也就是说,网络会直接学习特征间的可分性:同一类的特征之间的距离要尽可能的小,而不同类之间的特征距离要尽可能的大。
意思就是说通过学习,使得类间的距离要大于类内的距离。
损失函数为:
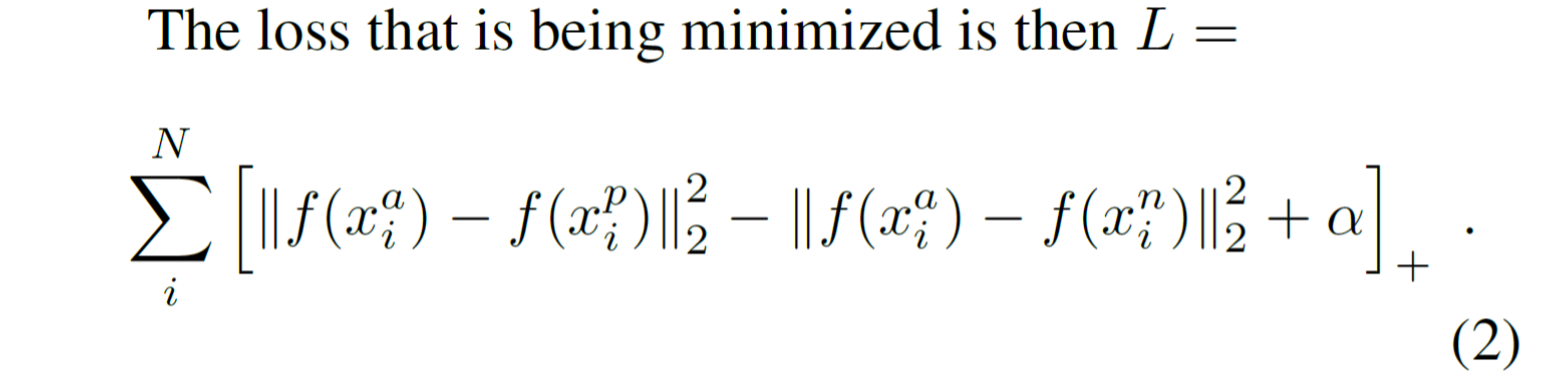
其中,左边的二范数表示类内距离,右边的二范数表示类间距离,α是一个常量。优化过程就是使用梯度下降法使得损失函数不断下降,即类内距离不断下降,类间距离不断提升。
提出了这样一种损失函数之后,实践过程中,还有一个难题需要解决,也就是从训练集里选择适合训练的三元组。
选择最佳的三元组
理论上说,为了保证网络训练的效果最好,我们要选择hard positive
以及hard negative
来作为我们的三元组
但是实际上是这样做会有问题:如果选择最Hard的三元组会造成局部极值,网络可能无法收敛至最优值。
因此google大佬们的做法是在mini-batch中挑选所有的 positive 图像对,因为这样可以使得训练的过程更加稳固。对于Negetive的挑选,大佬们使用了semi-hard的Negetive,也就是满足a到n的距离大于a到p的距离的Negative,而不去选择那些过难的Negetive。
CNN结构
文中尝试了两个CNN结构,其参数如下:
网络1:Zeiler&Fergus architecture
网络2: GoogLeNet
实验
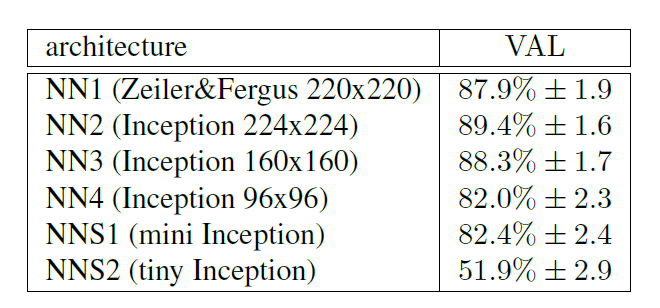
1. 不同的网络配置下的VAL(validation rate)。
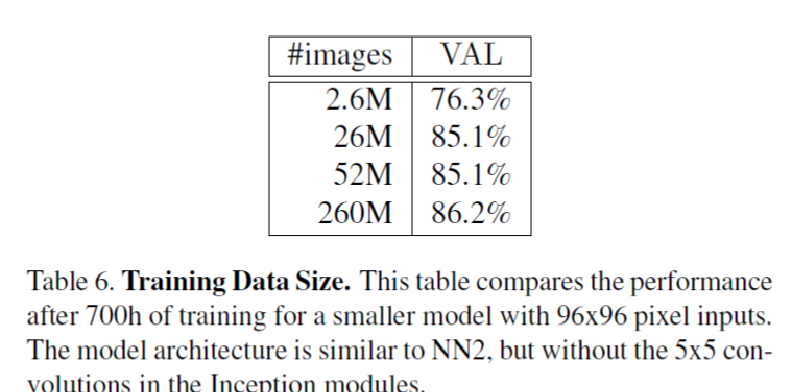
2. 不同的训练图像数据集的大小。
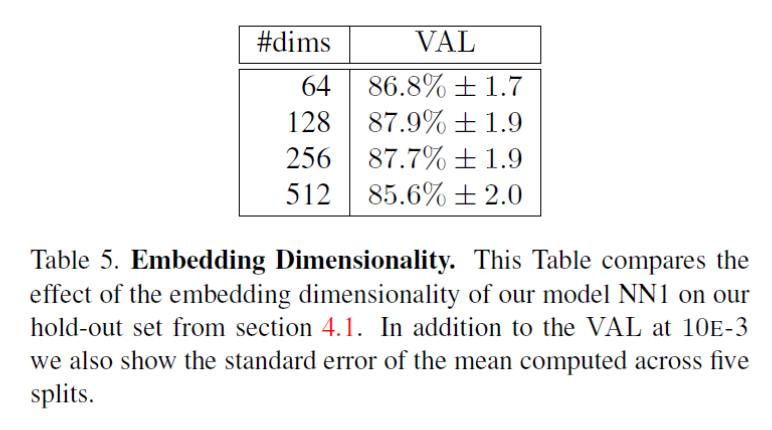
3. 嵌入层特征的维度对VAL的影响:
4. 不同的图像质量下的VAL:
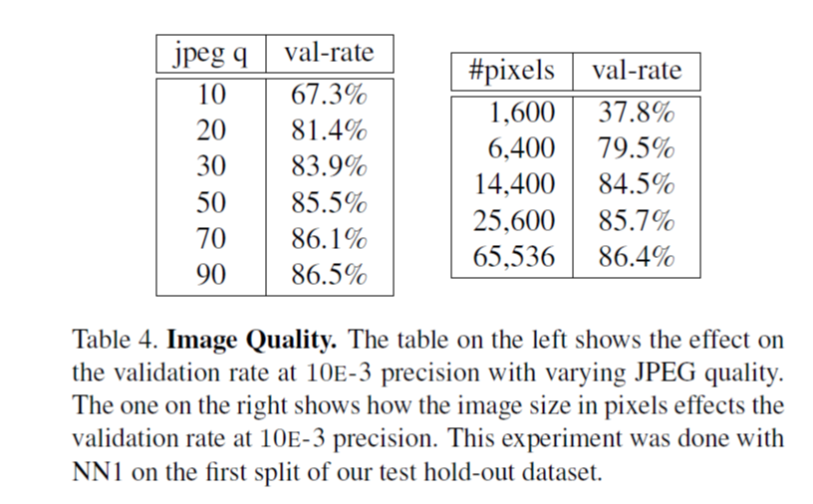
左边图表示jpeg图像的质量q对VAL的影响,显然质量越高,VAL越高,右边图表示图像的大小对VAL的影响。
LFW得分
在LFW上达到了98.87% +-0.15的验证准确率
如果预先使用更好的人脸检测算法来对齐人脸,最高可以达到99.63% +-0.09 的验证准确率。

















 3504
3504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









