







 本文详细介绍了如何在天翼云环境中安装NVIDIAA10显卡的驱动程序、CUDA开发套件、PyTorch框架,以及容器化和cuDNN优化,最后涉及制作私有镜像并分享给其他用户。作者强调了天翼云在智算服务方面的挑战与改进需求。
本文详细介绍了如何在天翼云环境中安装NVIDIAA10显卡的驱动程序、CUDA开发套件、PyTorch框架,以及容器化和cuDNN优化,最后涉及制作私有镜像并分享给其他用户。作者强调了天翼云在智算服务方面的挑战与改进需求。
一、英伟达环境安装主要流程
1、下载安装对应系统版本nVidia驱动程序安装验证
2、CUDA开发套件安装验证
3、深度学习框架安装验证MiniConda3+PyTorch
4、容器化CUDA环境安装验证
5、cuDNN深度学习优化驱动安装+CNN训练验证
6、制作天翼云主机私有镜像
7、分享镜像给其他用户,实现天翼云A10显卡英伟达驱动环境共享
二、详细安装步骤
一)下载安装对应系统版本nVidia驱动程序安装验证

dpkg -i nvidia-driver-local-repo-ubuntu2004-535.129.03_1.0-1_amd64.deb
apt-get install nvidia-driver-535
测试显卡,检查显卡是否正确安装
nvidia-smi
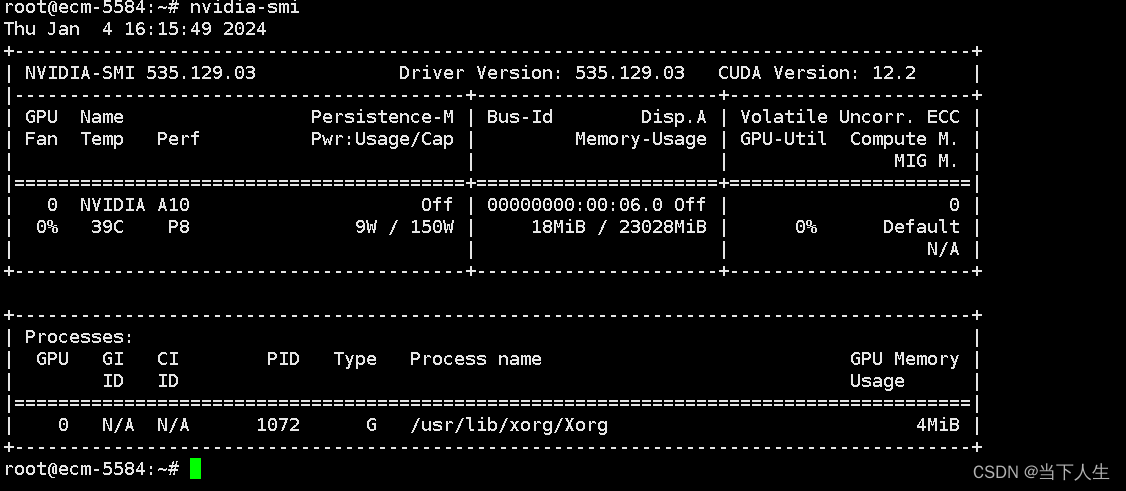
这个命令会显示 NVIDIA A10 显卡的状态和驱动程序版本,如图所示当前的版本是535.129.03,cuda版本为12.2,GPU型号为nvidia A10,显存有24G
2) CUDA开发套件安装验证
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda-repo-ubuntu2004-12-2-local_12.2.0-535.54.03-1_amd64.deb
dpkg -i cuda-repo-ubuntu2004-12-2-local_12.2.0-535.54.03-1_amd64.deb
cp /var/cuda-repo-ubuntu2004-12-2-local/cuda-*-keyring.gpg /usr/share/keyrings/
apt-get update
apt-get -y install cuda
设置环境变量
在 .bashrc 文件中设置环境变量:
echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
验证安装效果
nvcc --version
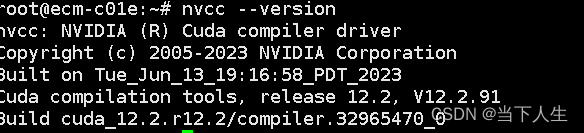
3)深度学习框架安装验证 PyTorch
下载安装miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
./Miniconda3-latest-Linux-x86_64.sh
更改pip安装源到国内,你懂的
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
访问 PyTorch 的 官方安装向导,选择合适的配置获取安装命令。通常,您需要选择操作系统、包管理器(在这里是 Pip)、Python 版本、CUDA 版本(这应该与您安装的 CUDA 版本匹配)
pip install torch torchvision torchaudio
运行一些简单的测试来确认 PyTorch 是否正确安装,并且是否能够使用 CUDA
vi test.py
import torch
# 打印 PyTorch 版本
print(torch.__version__)
# 确认 PyTorch 是否能检测到 CUDA
print(torch.cuda.is_available())
# 打印 CUDA 版本
print(torch.version.cuda)
# 获取默认 CUDA 设备的名称
print(torch.cuda.get_device_name(0))
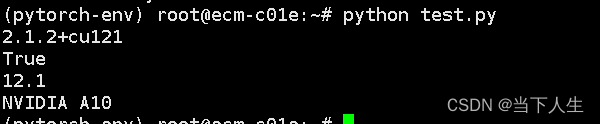
如果 torch.cuda.is_available() 返回 True 并且 CUDA 版本正确无误,那么 PyTorch 就已经成功安装,并且配置为使用您的 NVIDIA GPU。
每次在新的终端会话中工作时,如果您创建了 Python 虚拟环境,您需要先激活虚拟环境(使用 source pytorch-env/bin/activate)
4)容器化CUDA环境安装验证
第一步:docker安装
sudo apt update sudo apt install apt-transport-https ca-certificates
curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu focal stable"
sudo apt update
sudo apt install docker-ce
第二步:安装nVidia支持
安装 NVIDIA Container Toolkit,这允许 Docker 使用 GPU:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt update sudo apt install nvidia-docker2
第三步重启docker,验证安装
systemctl restart docker
docker run --rm --gpus all nvidia/cuda:12.0.1-base-ubuntu20.04 nvidia-smi
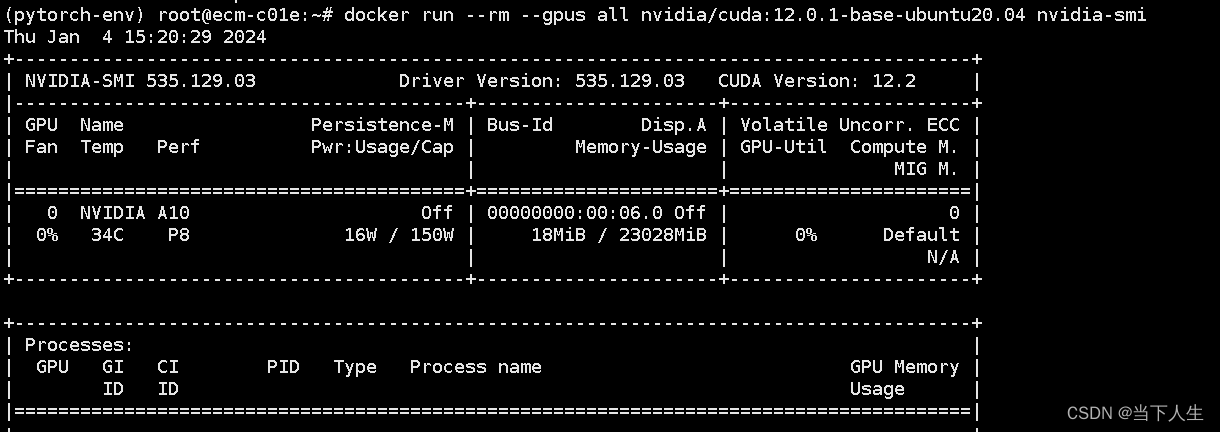
第四步使用docker运行PyTorch容器
sudo docker run --rm --gpus all -it pytorch/pytorch:latest
这将启动一个 PyTorch 容器,并分配所有可用的 GPU。
第五步测试构建自己的Docker镜像
FROM nvidia/cuda:12.0.1-base-ubuntu20.04
# 安装Python和Pip
RUN apt update && apt install -y python3 python3-pip
# 安装PyTorch
RUN pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu110
# 设置工作目录
WORKDIR /workspace
# 当容器启动时运行一个 shell
CMD ["/bin/bash"]
sudo docker build -t my-pytorch-image .
创建一个新的 Docker 镜像,名为 my-pytorch-image,其中包含了 PyTorch 和它的依赖。
5)cuDNN深度学习优化驱动安装
第一步到nVidia官网注册下载cuDNN离线安装包,并上传至云服务器
第二步安装离线包
dpkg -i cudnn-local-repo-ubuntu2004-8.9.7.29_1.0-1_amd64.deb
cp /var/cudnn-local-repo-ubuntu2004-8.9.7.29/cudnn-local-30472A84-keyring.gpg /usr/share/keyrings/
apt update
第三步查找对应的cuda版本
apt-cache madison libcudnn8

第四步 安装cudnn
apt install libcudnn8=8.9.7.29-1+cuda12.2
apt install libcudnn8-dev=8.9.7.29-1+cuda12.2
cat /usr/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
验证安装。
第五步 使用 PyTorch 来训练一个简单的 CNN 模型,框架在后台自动使用 cuDNN 来加速运算。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
# 定义一个简单的 CNN 模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
# 设置 PyTorch 以使用 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化模型、优化器和损失函数
net = Net().to(device)
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.5)
criterion = nn.CrossEntropyLoss()
# 加载数据集(在这里使用 MNIST)
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST(
'./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=64, shuffle=True)
# 训练模型
def train(epoch):
net.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = net(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
train(1) # 训练 1 个 epoch
PyTorch 示例中加载的 MNIST 数据集是一个经典的用于手写数字识别的数据集,由 60,000 个训练图像和 10,000 个测试图像组成。
- 当运行 PyTorch 示例中的
torchvision.datasets.MNIST函数时,它会自动检查指定的文件夹(在示例中是'./data')。 - 如果数据集尚未下载,PyTorch 会自动从互联网下载数据集。
- 数据集被下载后,PyTorch 会自动加载数据,使其准备好用于训练或测试。
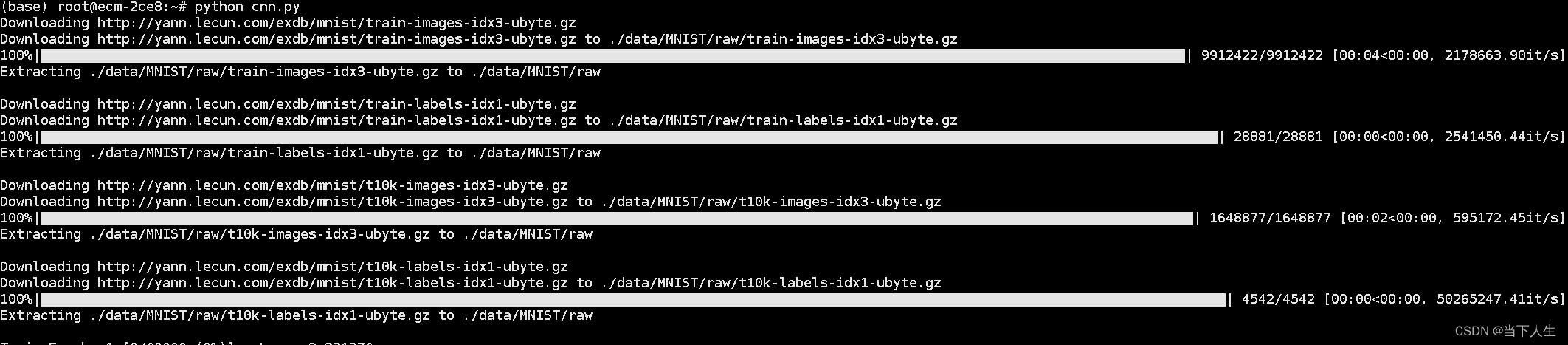
自动下载数据集
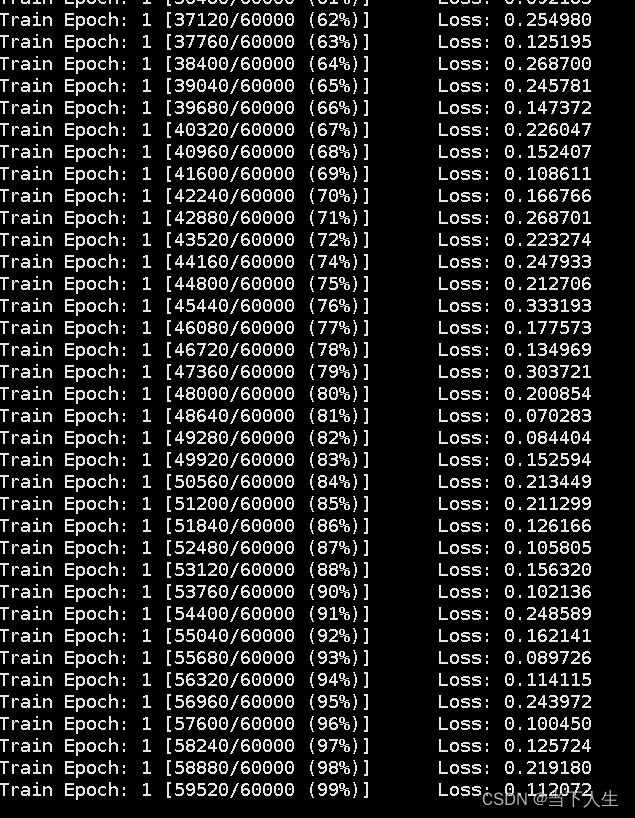
训练CNN网络速度非常快,训练速度: 显著的速度提升通常表明 GPU 正在被有效利用。
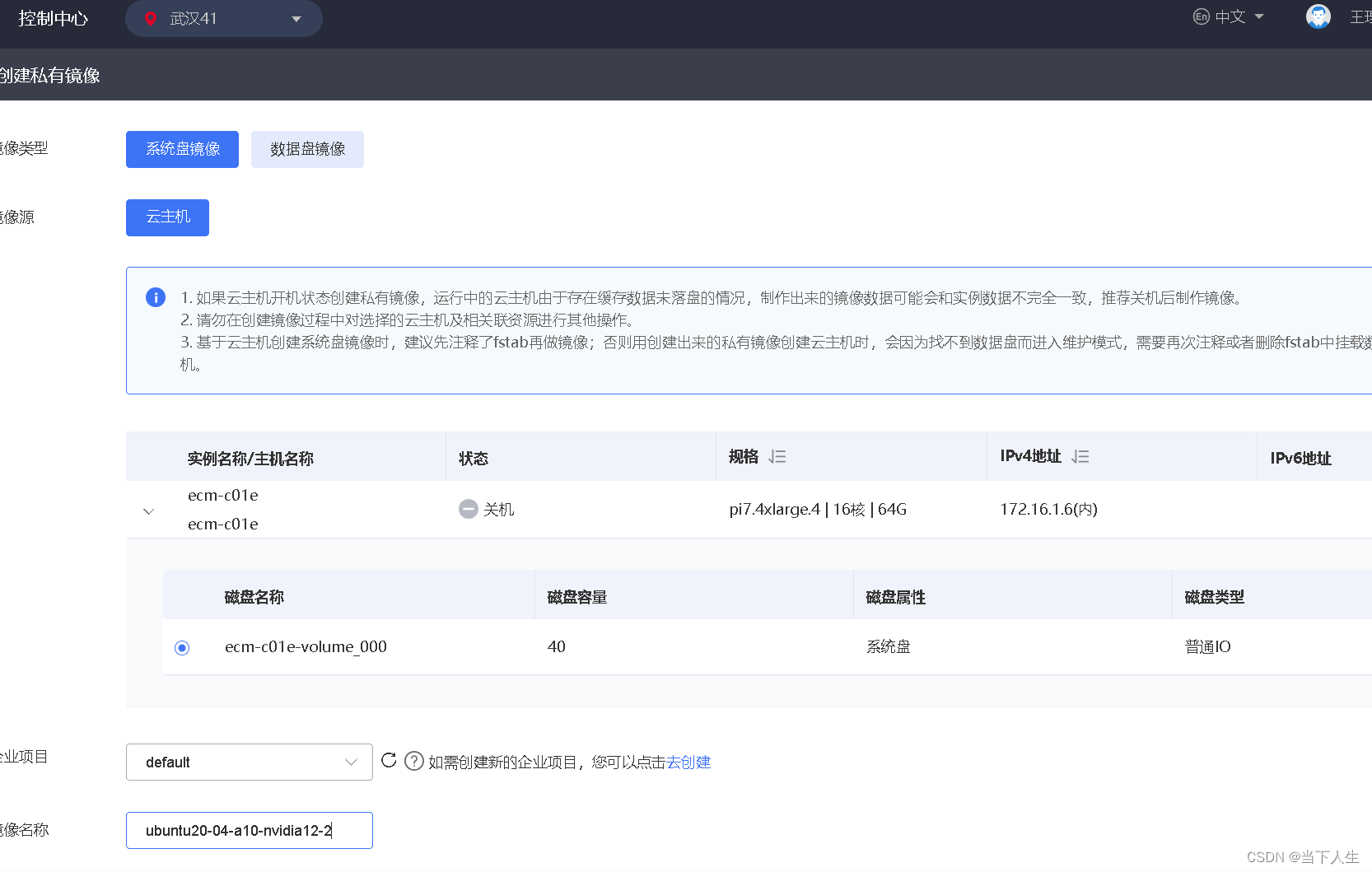
6)制作天翼云主机私有镜像
第一步先停机
第二步制作镜像
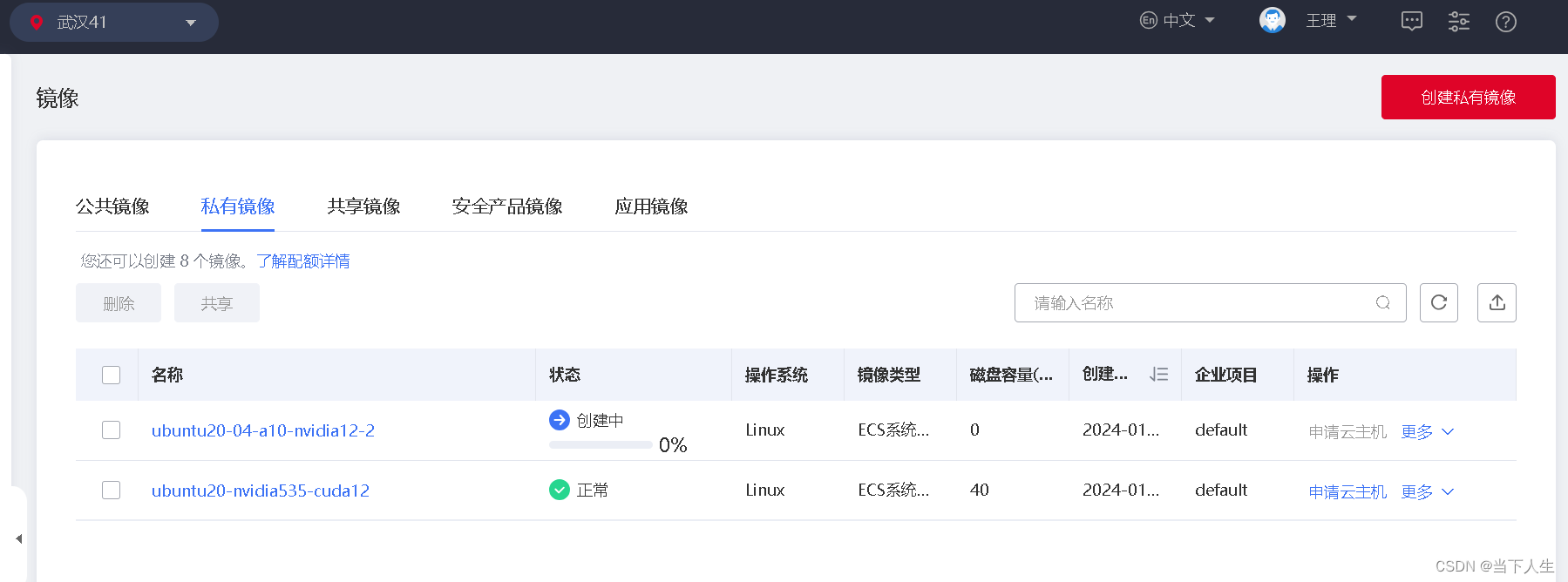
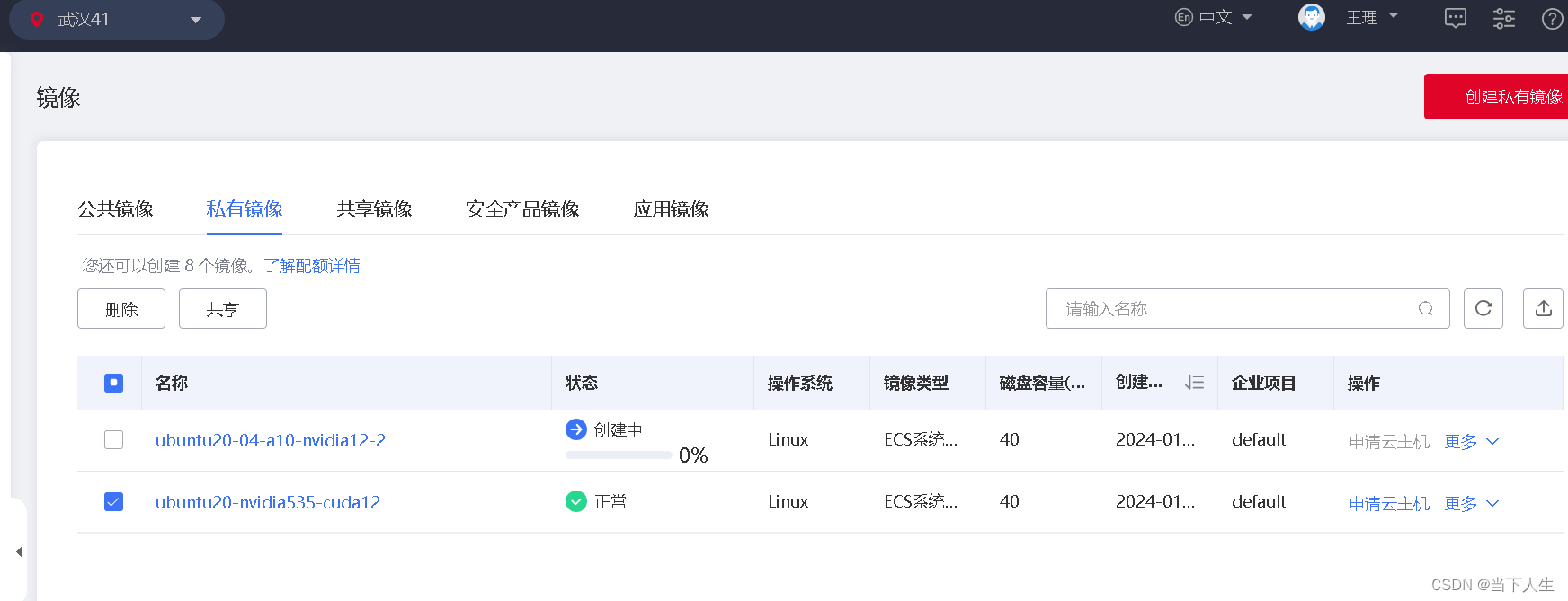
7)分享镜像给其他用户,实现天翼云A10显卡英伟达驱动环境共享
第一步选择需要共享的镜像名称
第二步输入天翼云接受者邮箱,也就是租户登录的账号
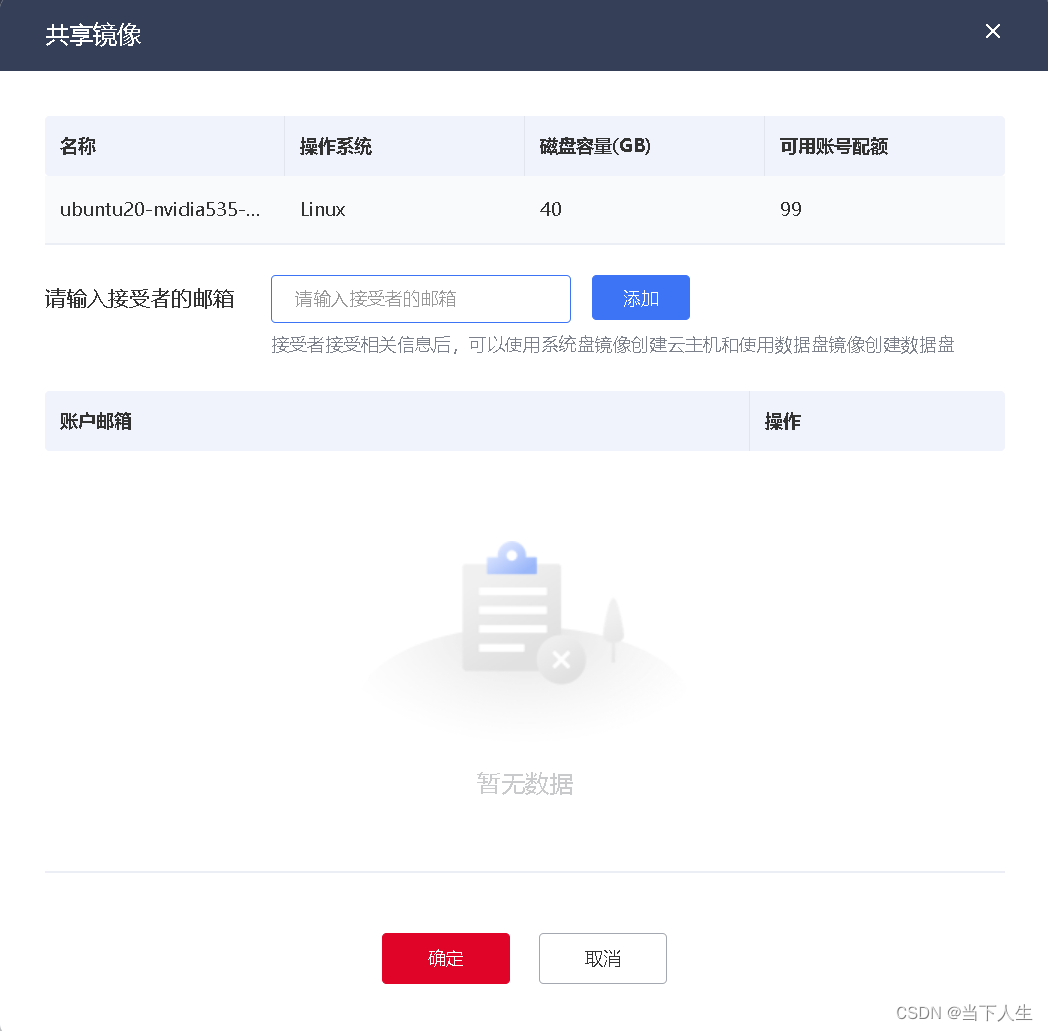
第三步登录接受者天翼云账号,在镜像服务中,选择接受私有共享镜像
第四步用这个镜像来创建GPU云主机即可。
三、经验总结
1、天翼云与友商在智算方面存在服务差距,友商在这种场景会根据GPU型号自动适配合适的英伟达驱动与智算运行环境给客户
2、天翼云销售GPU云主机必须要自己服务能力跟上,补齐暂时还不能对齐友商的服务能力。
3、本文提供的思路可以扩展到其他GPU服务器上。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









