







Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎,可以识别多种格式的图像文件并将其转换成文本,目前已支持60多种语言(包括中文)。 Tesseract最初由HP公司开发,后来由Google维护,目前发布在Googel Project上。地址为http://code.google.com/p/tesseract-ocr/。
使用默认的语言库识别
1.安装Tesseract
从
http://code.google.com/p/tesseract-ocr/downloads/list下载Tesseract,目前版本为Tesseract3.02。因为只是测试使用,这里直接下载winodws下的安装文件tesseract-ocr-setup-3.02.02.exe。安装成功后会在相应磁盘上生成一个Tesseract-OCR目录。通过目录下的tesseract.exe程序就可以对图像字符进行识别了。
2.准备一副待识别的图像,这里用画图工具随便写了一串数字,保存为number.jpg,如下图所示:
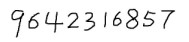
3. 打开命令行,定位到Tesseract-OCR目录,输入命令:
tesseract.exe 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









