







我没有混日子,只是辛苦的时候没人看到罢了
一、什么是Tesseract
- Tesseract是一个开源的OCR(Optical Character Recognition)引擎,OCR是一种技术,它可以识别和解析图像中的文本内容,使计算机能够理解并处理这些文本。
- Tesseract提供了丰富的配置选项和接口,使得开发者可以根据自己的需求和场景进行定制化和集成。
- 通过使用Tesseract,你可以将一张包含文字的图像(如扫描文档、照片或截屏)输入到引擎中,然后Tesseract会通过一系列的图像处理和模式识别技术来提取出图像中的文本信息。它将识别出的文本转换为可以被计算机编辑和搜索的文本内容。
简单来说,Tesseract是一个强大的OCR引擎,适用于将图像中的文字提取出来,并将其转换为计算机可处理的文本形式。它在许多领域和应用中被广泛使用,如扫描和数字化文档、自动化数据输入、图书馆和档案管理等。
二、创建开发环境
使用conda创建一个名字为openCV的开发环境
conda create -n openCV
引入openCV包
pip install opencv-python
引入pytesseract包
三、代码实战
检测图片中的字符串并打印
先准备一张如下格式的图片

编写代码解析
testDectection.py
import cv2
import pytesseract
img = cv2.imread('1.png') # 使用opencv将图片读进来
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 将图片的颜色通道格式由BGR转化成pytesseract能识别的RGB格式
print(pytesseract.image_to_string(img)) # 调用pytesseract引擎将图片中的内容输出出来
cv2.imshow('result', img) # 显示
cv2.waitKey(0)输出

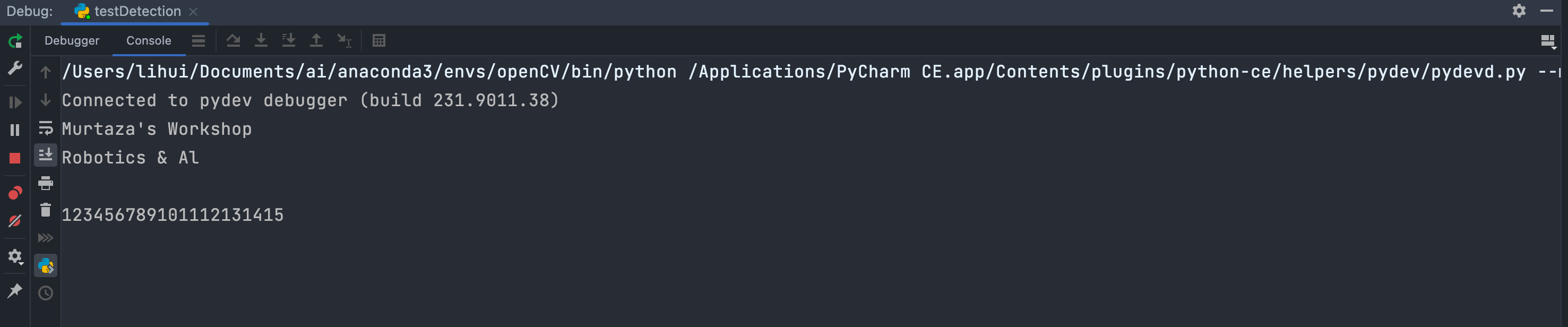
以上就是通过使用pytesseract简单获取图像原始信息的方法。
检测图中的字符并用红框标注
代码
import cv2
import pytesseract
img = cv2.imread('1.png') # 使用opencv将图片读进来
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 将图片的颜色通道格式由BGR转化成pytesseract能识别的RGB格式
# Detecting Characters
hImg, wImg, _ = img.shape # 找出图片的宽度和高度
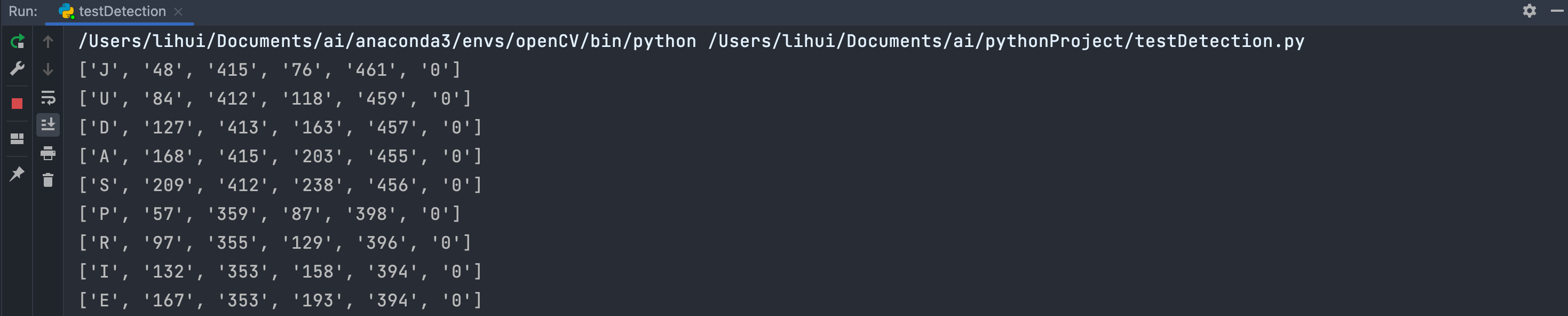
boxes = pytesseract.image_to_boxes(img) # 使用pytesseract找出图片中字符的坐标位置
for c in boxes.splitlines():
c = c.split(' ')
print(c)
x, y, w, h = int(c[1]), int(c[2]), int(c[3]), int(c[4])
cv2.rectangle(img, (x, hImg - y), (w, hImg - h), (0, 0, 255), 3) # 使用opencv画框框,使用红色,厚度为3
cv2.imshow('result', img) # 显示
cv2.waitKey(0)输入两张图片
1.png

2.png

输出
每一个检测出来字符串的坐标


图像中添加识别的文本内容
import cv2
import pytesseract
img = cv2.imread('1.png') # 使用opencv将图片读进来
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 将图片的颜色通道格式由BGR转化成pytesseract能识别的RGB格式
# Detecting Characters
hImg, wImg, _ = img.shape # 找出图片的宽度和高度
boxes = pytesseract.image_to_boxes(img) # 使用pytesseract找出图片中字符的坐标位置
for c in boxes.splitlines():
c = c.split(' ')
print(c)
x, y, w, h = int(c[1]), int(c[2]), int(c[3]), int(c[4])
cv2.rectangle(img, (x, hImg - y), (w, hImg - h), (0, 0, 255), 3) # 使用opencv画框框,使用红色,厚度为3
cv2.putText(img, c[0], (x, hImg - y + 25), cv2.FONT_HERSHEY_COMPLEX, 1, (50, 50, 255), 2) # 向图像中添加文本
cv2.imshow('result', img) # 显示
cv2.waitKey(0)关键
cv2.putText(img, c[0], (x, hImg - y + 25), cv2.FONT_HERSHEY_COMPLEX, 1, (50, 50, 255), 2)
这行代码使用OpenCV库中的putText函数向图像中添加文本。
解释如下:
img:表示要添加文本的图像。c[0]:表示要添加的文本内容,c[0]可能是一个字符串变量,用于指定要添加的文本。(x, hImg - y + 25):表示文本的起始位置,该位置是一个元组(x, y),其中x表示文本的横坐标,hImg - y + 25表示文本的纵坐标。hImg可能是整个图像的高度,y是用于定位白色文本的轮廓的顶端位置的变量。通过hImg - y + 25可以使文本出现在轮廓下方一些距离的位置。cv2.FONT_HERSHEY_COMPLEX:表示所使用的字体类型,这里使用的是复杂的字体类型。1:表示文本的字体缩放因子,1表示原始大小。(50, 50, 255):表示文本的颜色,该颜色为一个元组(B, G, R),其中B、G、R分别表示蓝色、绿色、红色通道的值。在这个例子中,文本颜色是一种深红色。2:表示文本的线宽,即文本边框的宽度。这里设置为2,使得文本边框较粗。
输出

检测连续的字符串
实际中一般不关注一个字符,更多是关注连起来的字符串
import cv2
import pytesseract
img = cv2.imread('1.png') # 使用opencv将图片读进来
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 将图片的颜色通道格式由BGR转化成pytesseract能识别的RGB格式
# Detecting Characters
hImg, wImg, _ = img.shape # 找出图片的宽度和高度
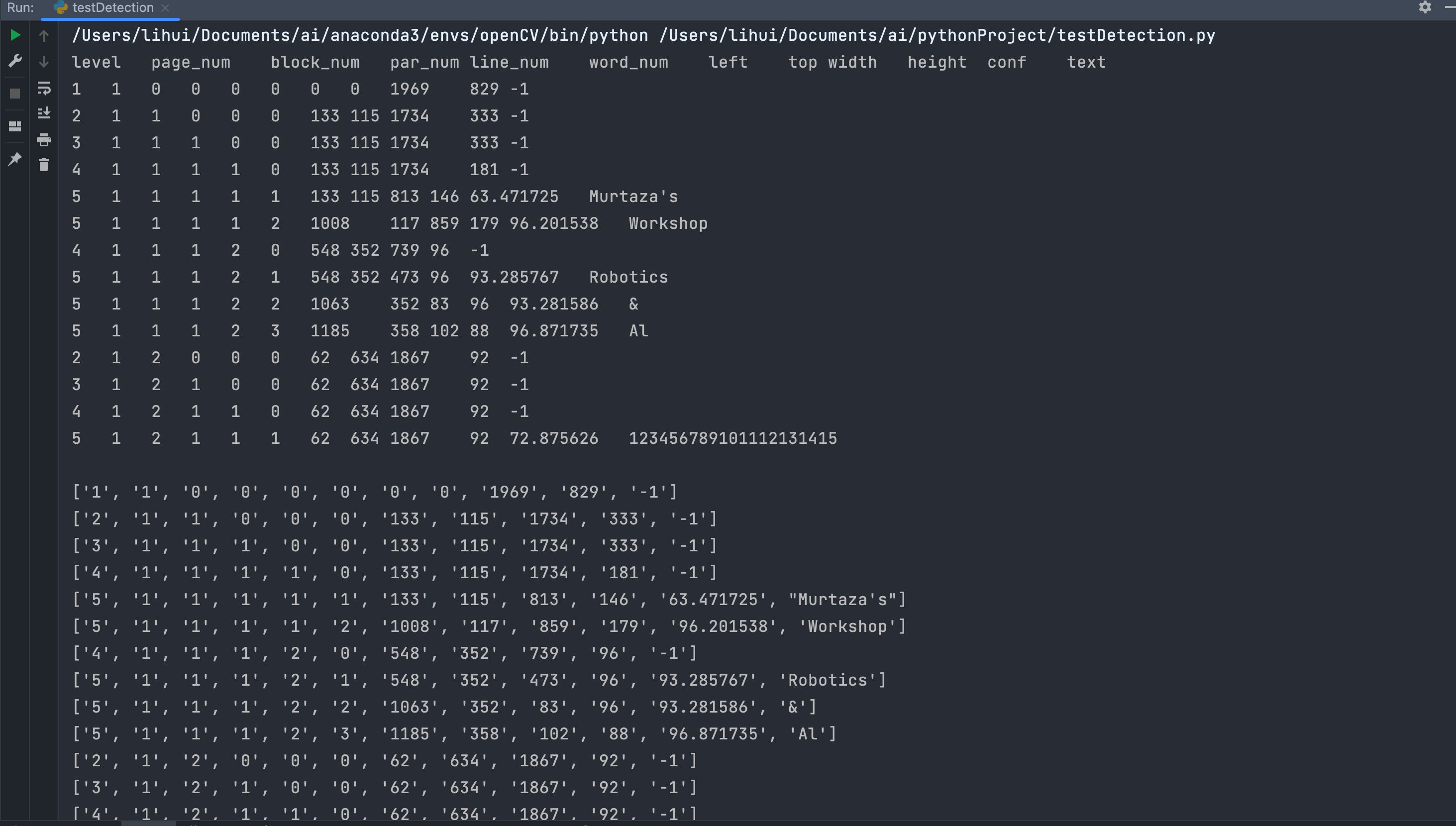
boxes = pytesseract.image_to_data(img) # 使用pytesseract找出图片中字符的坐标位置
for x, c in enumerate(boxes.splitlines()):
if x != 0:
c = c.split()
print(c)
if len(c) == 12:
x, y, w, h = int(c[6]), int(c[7]), int(c[8]), int(c[9])
cv2.rectangle(img, (x, y), (x + w, h + y), (0, 0, 255), 3) # 使用opencv画框框,使用红色,厚度为3
cv2.putText(img, c[11], (x, y), cv2.FONT_HERSHEY_COMPLEX, 1, (50, 50, 255), 2) # 向图像中添加文本
cv2.imshow('result', img) # 显示
cv2.waitKey(0)
输出
每个字段的含义:
level:代表文本在页面中的级别。这里的级别是从1开始的,表示文本的嵌套层级。page_num:代表文本所在的页码。在多页文档中,每一页都有一个唯一的页码。block_num:代表文本所在的文本块的编号。文本块是文档中的一个矩形区域,包含多个段落或行。par_num:代表文本所在的段落的编号。段落是文档中的一个文本段落,通常由一组相关的句子组成。line_num:代表文本所在行的编号。行通常是段落中的一个文本行。word_num:代表文本所在单词的编号。单词是文本的最小单位,通常由一个或多个字符组成。left:代表文本区域的左边界相对于页面的位置。top:代表文本区域的上边界相对于页面的位置。width:代表文本区域的宽度。height:代表文本区域的高度。conf:代表文本的置信度,通常在0到100之间。置信度表示OCR算法对所识别文本的可信程度。text:代表识别出的文本内容。

只识别图片中的数字
import cv2
import pytesseract
img = cv2.imread('1.png') # 使用opencv将图片读进来
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 将图片的颜色通道格式由BGR转化成pytesseract能识别的RGB格式
# Detecting Characters
hImg, wImg, _ = img.shape # 找出图片的宽度和高度
cong = r'--oem 3 --psm 6 outputbase digits'
boxes = pytesseract.image_to_data(img, config=cong) # 使用pytesseract找出图片中字符的坐标位置
for x, c in enumerate(boxes.splitlines()):
if x != 0:
c = c.split()
print(c)
if len(c) == 12:
x, y, w, h = int(c[6]), int(c[7]), int(c[8]), int(c[9])
cv2.rectangle(img, (x, y), (x + w, h + y), (0, 0, 255), 3) # 使用opencv画框框,使用红色,厚度为3
cv2.putText(img, c[11], (x, y), cv2.FONT_HERSHEY_COMPLEX, 1, (50, 50, 255), 2) # 向图像中添加文本
cv2.imshow('result', img) # 显示
cv2.waitKey(0)
重点
cong = r'--oem 3 --psm 6 outputbase digits'
boxes = pytesseract.image_to_data(img, config=cong)
参数解释:
oem是一个参数,用于指定OCR引擎的OCR引擎模式(OCR Engine Mode)。OCR引擎模式控制Tesseract在文本识别过程中的行为和算法。psm是一种页分割模式(Page Segmentation Mode),用于指定OCR引擎在识别文本时如何处理页面布局和分割问题。psm参数控制Tesseract在识别文本时如何将图像分割为单个字符、单词、行和文本块。















 4057
4057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









