






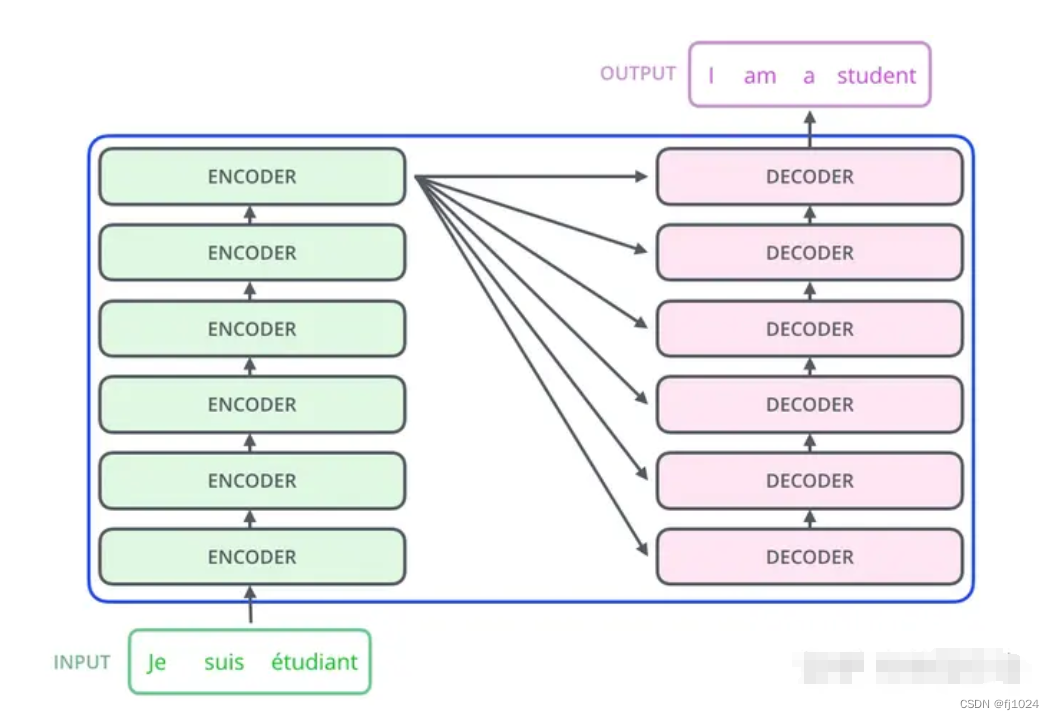
拆开encode和decode,完整结构如下所示:
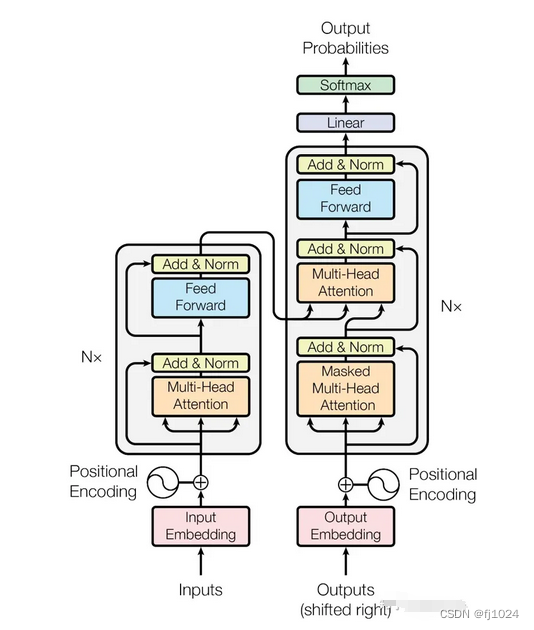
encode部分:一个多头注意力模块、两个残差网络和归一化层(防止网络退化、进行归一化)、一个前馈神经网络
decode部分:两个多头注意力模块、三个残差网络和归一化层(防止网络退化、进行归一化)、一个前馈神经网络
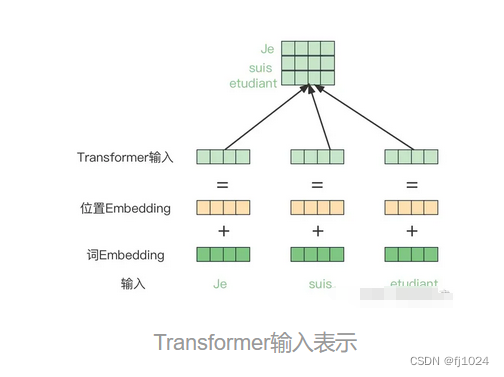
第一步:获取句子每个单词的向量x,由单词embedding和单词位置embedding组成
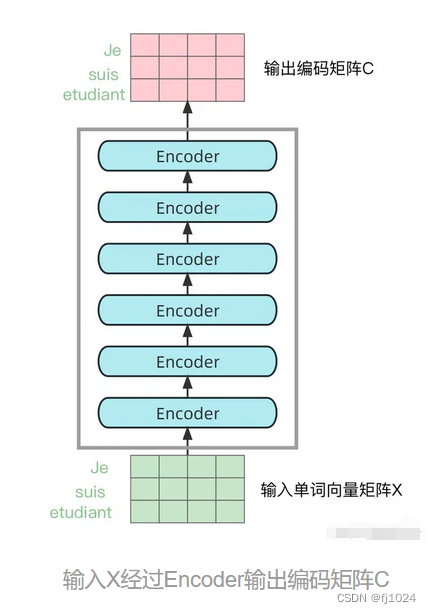
第二步:将单词向量传入n个encode模块,得到句子所有单词的编码信息C 维度为 单词个数n ✖ 向量维度d
第三步:将获得的编码句子C输入到Decode中,逐个单词进行解码。
具体部分细节:
单词embedding可以通过word2vec模型预训练得到,transformer没有单词间的序列信息,使用全局信息,可通过训练得到,也可以通过公式,transformer选择了后者。 pos代表位置信息,d代表信息维度的长度。i是信息维度长度的一般,i=0 计算第一列和 第二列位置编码
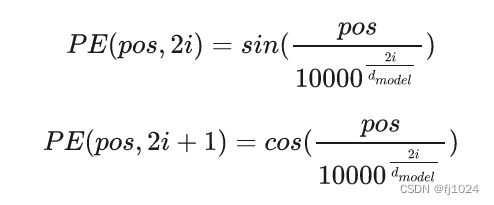
多头注意力机制:self-attention是重点。Q(查询)、K(键值)、V(值)通过输入矩阵X乘以权重矩阵WQ、WK、WV。
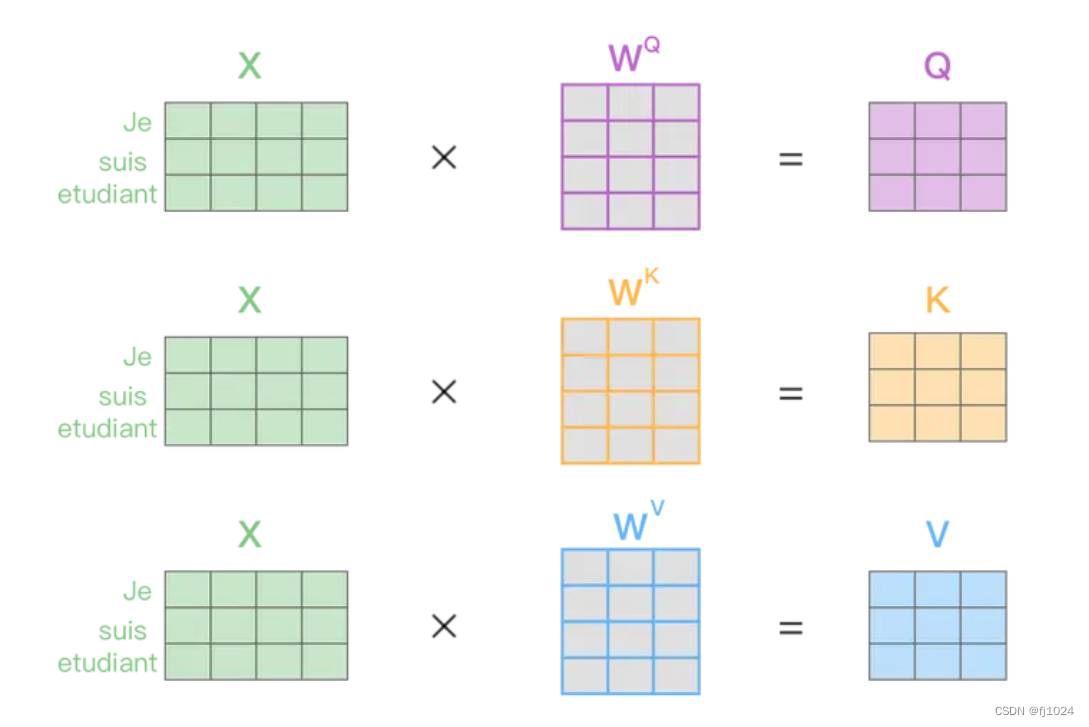
得到 qkv之后就可以计算出Self-Attention的输出。
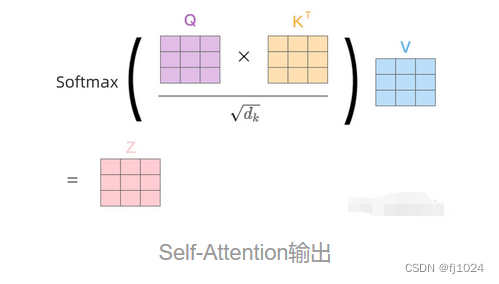
多头注意力, 包含多个Self-Attention层,输入到不同的Self-Attention层,得到不同的Z,拼接然后传入一个liner层,得到最终的Z。
了解Add & Norm和 Feed Forward部分。
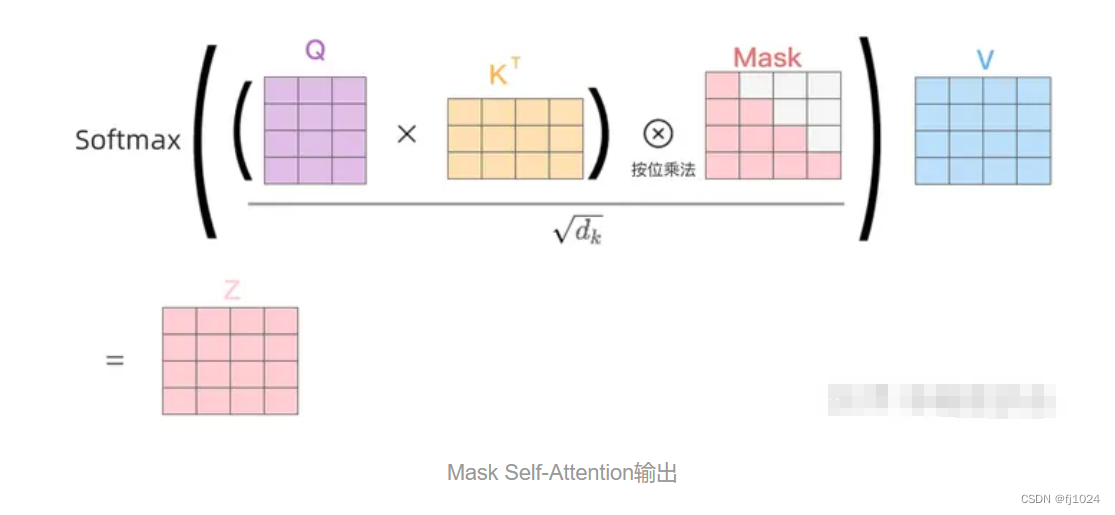
decode结构和encode结构比较相似,但也有一定区别。一个多头注意力采用了masked操作(通过 Masked 操作可以防止第i个单词知道第i+1个单词之后的信息,只是在Softmax之前需要进行Mask操作)、第二个的多头注意力机制KV由encode的编码信息C计算,而Q来自上一个Decode计算(这样做的好处是在Decoder的时候,每一位单词(这里是指"I am a student")都可以利用到Encoder所有单词的信息(这里是指"Je suis etudiant")。),最后有个softmax计算单词的概率。
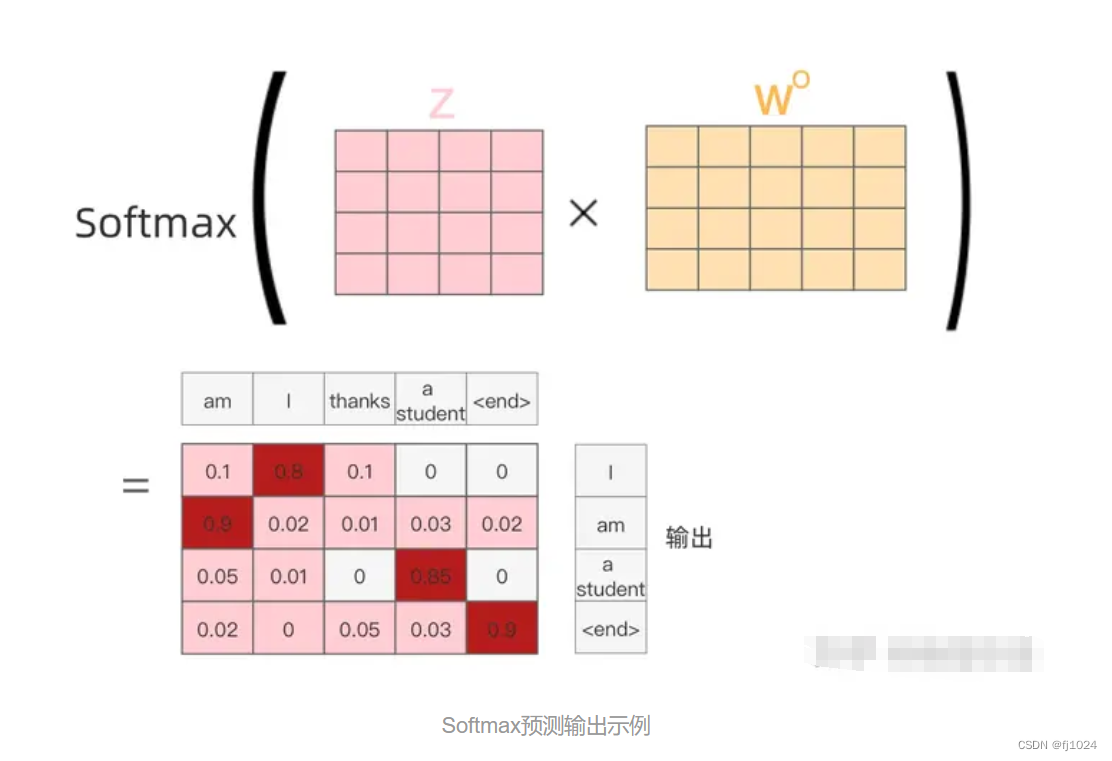
最后softmax输出:















 9661
9661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









