







关于支持向量机,看了一些理论讲解,比如周志华老师的《机器学习》,july大神的长文,zhouxy的系列博客。这里暂时贴几个推荐阅读哈哈。
推荐资料
july博文:支持向量机通俗导论(理解SVM的三层境界)
zhouxy博文:机器学习算法与Python实践之(二)支持向量机(SVM)初级 及之后的“进阶篇”和“实现篇”。
周志华的《机器学习》之“支持向量机”。
李航的《统计学习方法》
任柳江的《全栈数据之门》
SVM的实战
注意应当现将数据scaling处理(化为均值为0、方差为1的正态分布)。
Scikit-Learn官方的实例:Support Vector Machines(推荐)
莫烦教程:轻松使用机器学习(推荐)
莫烦的Github:教程
总结一下实战技巧:
一、核函数的选择
最常见的核函数有这几种(其他几种请参考其他资料):
linear:线性核,分割边界是直线或线段;无特殊参数(这里把惩罚参数C看成通用参数)。
rbf(default):高斯核,有参数gamma(为其系数),gamma值越小,分类界面越连续(光滑);gamma值越大,分类界面越“散”(波浪多),分类效果越好,但有可能会过拟合。
polynomial:多项式核,有参数gamma(为其系数)、coef0(为其常数项)、degree(为其幂次)。
sigmoid:sigmod核函数,有参数gamma(为其系数)、coef0(为其常数项)。
二、参数的设置
除了以上提到的参数,还有惩罚参数C,C趋于无穷大时要求分类没有错误,即C较大时为硬分割、C较小时为软分割。
直观地感受下各个参数对分类效果的影响:
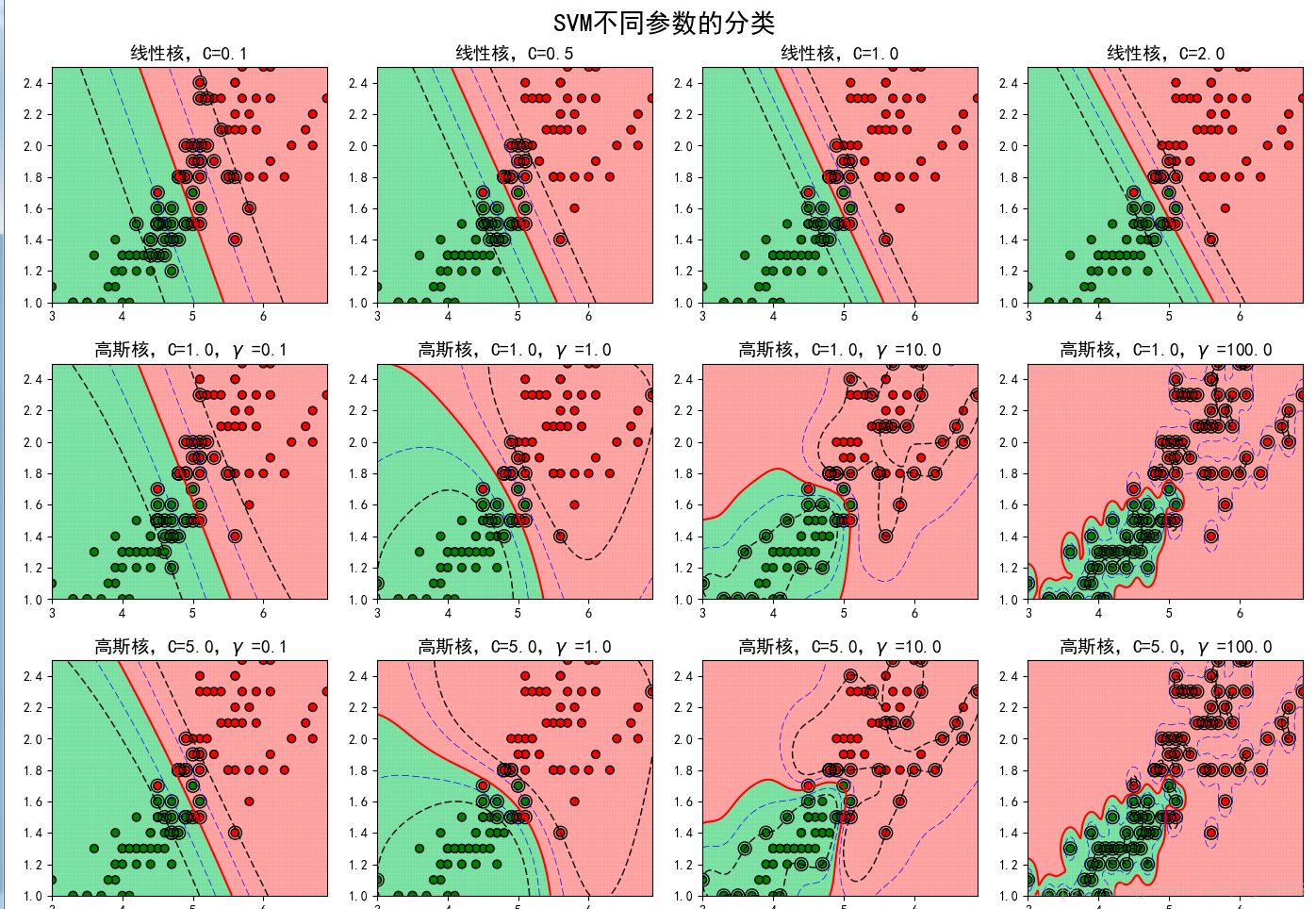
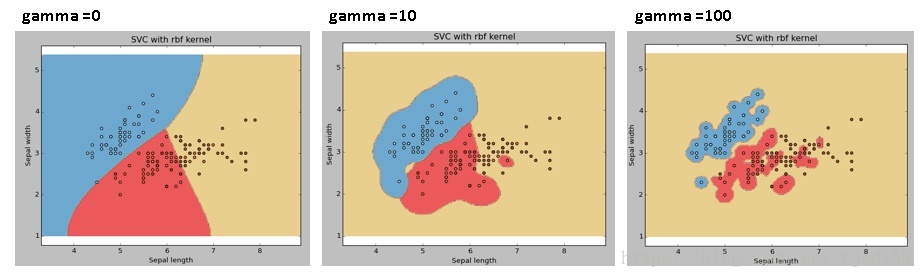
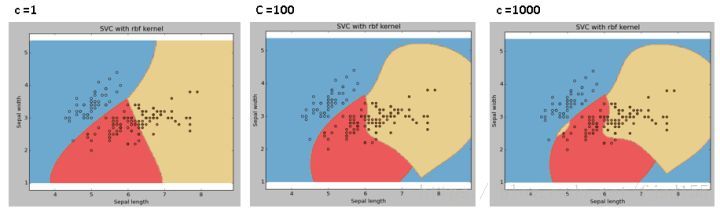
核函数怎么选取,参数怎么选择?本人目前一般采用枚举试探(官网的示例中也有枚举各个参数),用各种核函数和参数训练模型,看看哪种情形下的模型最好。最后选择最优的核函数和参数。
三、模型的评价
score()函数可以得到精度。
此外可以计算准确率,用预测的数据和观测的数据进行对比即可计算出来。
还有其他各种指标,如recall、F1、AUC,可以参考SVM 二分类与模型评估参数、sklearn中的模型评估等资料(随便找了2个博客,改天研究下)。
其他
扩展
另外,关于深度学习,常用框架包括Tensorflow、PyTorch 和 Keras 等。Tensorflow的入门,可以看看莫烦教程(再加上Tensorflow官网教程和花书/深度学习圣经)。
除了大家熟知的Scikit-Learn、Tensorflow、PyTorch 和 Keras 以外,Python中的机器学习库和框架还有很多,这里列举一些值得推荐的。
1. Theano
允许高效地定义、优化以及评估涉及多维数组的数学表达式。Theano最好的功能之一是拥有优秀的参考文档和大量的教程。事实上,多亏了此库的流行程度,使你在寻找资源的时候不会遇到太多的麻烦,比如如何得到你的模型以及运行等。
定位:神经网络和深度学习。
2. Pylearn2
大多数Pylearn2的功能实际上都是建立在Theano之上,所以它有一个非常坚实的基础。Pylearn2不同于scikit-learn,Pylearn2旨在提供极大的灵活性,使研究者几乎可以做任何想做的事情,而scikit-learn的目的是作为一个“黑盒”来工作,即使用户不了解实现也能产生很好的结果。Pylearn2在合适的时候会封装其它的库,如scikit-learn,所以在这里你不会得到100%用户编写的代码。然而,这确实很好,因为大多数错误已经被解决了。像Pylearn2这样的封装库在此列表中有很重要的地位。
定位:神经网络。
3. Shotgun
Shogun是个聚焦在支持向量机(Support Vector Machines, SVM)上的机器学习工具箱,用C++编写。它正处于积极开发和维护中,提供了Python接口,也是文档化最好的接口。但是,相对于Scikit-learn,我们发现它的API比较难用。而且,也没提供很多开箱可用的诊断和求值算法。但是,速度是个很大的优势。
定位:SVM。
4. Caffe :用于神经网络/视觉深度学习。
5. Pattern :用于NLP和分类。
6. NLTK :用于NLP。
还有很多,平时上网搜一搜就知道了。多扩展视野,善于利用资源。
关于机器学习的三个层次,有人总结如下:
- 调用:知道算法的基本思想,能应用现有的库来做测试。简单说,比如了解kNN是做什么的,会调用sklearn中的kNN算法。
- 调参:知道算法的主要影响参数,能进行参数调节优化。
- 嚼透:理解算法的实现细节,并且能用代码实现出来。
当然,从另外一个角度来说,尤其是在分布式环境下,机器学习还有另外三个层次,见《全栈数据之门》一书所述。
在海量数据的环境下,学学Hadoop其实也是有必要的。有空可以看看。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











