







本文为学习笔记,感兴趣的读者可在MOOC中搜索《数据结构与算法Python版》或阅读《数据结构(C语言版)》(严蔚敏)
目录链接:https://blog.csdn.net/floating_heart/article/details/123991211
2.3 哈夫曼树Huffman Tree
哈夫曼树,是一类带权路径长度最短的二叉树,也被称为最优二叉树。其权值较大的结点离根比较近。
目前,据笔者的了解,哈夫曼树在流程判定和数据压缩方面有所应用,类似的实例包括最佳判定算法和哈夫曼编码,这些会在后文介绍。
2.3.1 相关概念
要了解最优二叉树,我们先要厘清一些概念:
路径和路径长度:
- 树中一个结点到另一个节点之间的分支构成这两个结点之间的路径。
- 路径上的分支数目称为路径长度。
- 树的路径长度是根节点到每一个结点的路径长度之和。
权和带权路径长度:
- 给每一个结点赋予一个值,作为权重。
- 结点的带权路径长度为从根节点到该结点的路径长度和该结点权值的乘积。
- 树的带权路径长度为所有叶子结点的带权路径长度之和。
例如下图所示哈夫曼树:
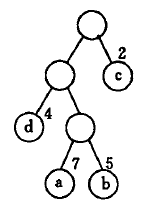
叶子结点上方表明权值,其带权路径长度为: W P L = 7 ∗ 3 + 5 ∗ 3 + 2 ∗ 1 + 4 ∗ 2 = 46 WPL\:=\:7*3+5*3+2*1+4*2\:=\:46 WPL=7∗3+5∗3+2∗1+4∗2=46
2.3.2 应用:最佳判定算法
此处以数据结构: C语言版, 严蔚敏, 2007. 中的例子来描述算法。
如果要编制一个将百分制转换成五级分制的程序,简单的方式如下:(python)
if a < 60:
b = 'bad'
elif a < 70:
b = 'pass'
elif a < 80:
b = 'general'
elif a < 90:
b = 'good'
else:
b = 'excellent'
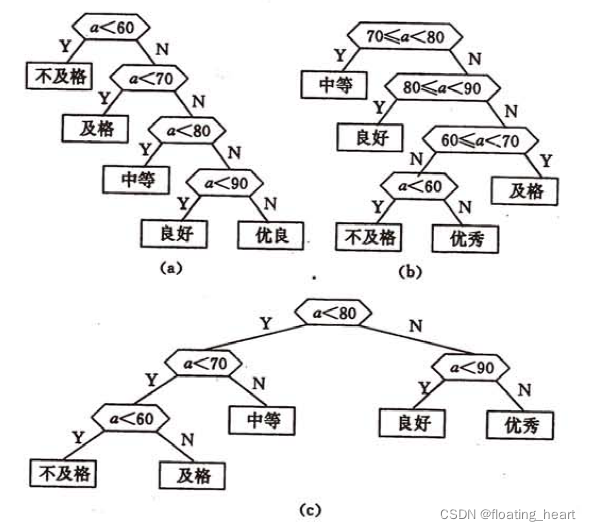
这个判定过程可以用图(a)的判定树来表示。
如果这段程序需要反复使用,而且每次的输入量很大,则应考虑上述程序的质量问题,即其操作所需时间。因为在实际生活中,学生的成绩在5个等级上的分布是不均匀的。假设其分布规律如下表所示:
| 分数 | 0-59 | 60-69 | 70-79 | 80-89 | 90-100 |
|---|---|---|---|---|---|
| 比例数 | 0.05 | 0.15 | 0.40 | 0.30 | 0.10 |
则80%以上的数据需要进行3次或3次以上的比较才能得出结果。假定以5,15,40,30和10为权(每个分数区间出现的比例)构造一棵有5个叶子节点的哈夫曼树,则可得到图(b)所示判定过程,可使大部分数据经过较少的比较次数得出结果。由于每个判定框都有两次比较,将这两次比较分开,可以得到图©所示判定树。
假设有10000个输入数据,根据图(a)的判定过程理论上需经过31500次比较,而根据图©的判定过程理论上仅需22000次比较。
通过不同情况出现的概率,确定每种情况的权值,借以构建Huffman Tree,获得最佳判定过程,即为最佳判定算法的实际体现。
2.3.3 应用:哈夫曼编码(Huffman Coding)
哈夫曼编码,又称霍夫曼编码,是可变字长编码(VLC)的一种。该方法完全依据字符出现的概率来构造异字头的平均长度最短的码字。
在一些信息传输的过程中,往往需要将需传送的文字转换为由二进制字符组成的字符串,同时在传送信息时,希望总长尽可能的短。以文字出现频率为权值,构建哈夫曼树,以不同的分支作为0或1的表达,即可针对每个字符设计出长度不等的编码。
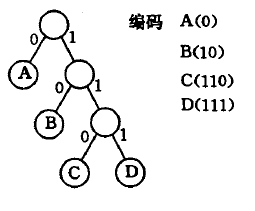
这样的编码即霍夫曼编码,编码总长度可达到最小。
注意一:要设计长度不等的编码,必须任何一个字符的编码都不是另一个字符的编码的前缀,这种编码称作前缀编码。
**注意二:**哈夫曼编码在使用中包含三个步骤。第一步通过全部的字符构建哈夫曼树;第二步根据哈夫曼树对字符进行编码;第三步根据哈夫曼树进行解码。编码和解码总共需要对全部数据遍历三遍,遍历过程不能并行,这在数据量较大的情况下虽然提高了信道的利用率,降低了传输成本,但对于处理器是一个非常庞大的时间消耗。这种方式也被称为静态哈夫曼编码,之后人们为了改善这一情况,又设计了动态哈夫曼编码,此为后话。
2.3.4 哈夫曼树的实现
1)定义Huffman Tree
与之前二叉树类似,此处我们定义的初始内容如下:
class HuffmanTree:
# 初始结构
def __init__(self,weight=1,value=None) -> None:
self.value = value
self.weight = weight # 权值,默认为1
self.parent = None # 维护parent属性,为了方便向上遍历
self.leftChild = None
self.rightChild = None
# 简单操作
def getWeight(self):
return self.weight
def setWeight(self,newWeight):
self.weight = newWeight
2)操作:构建Huffman Tree
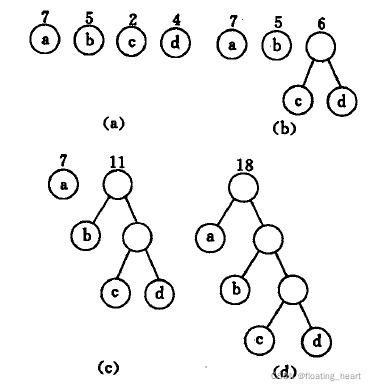
从常理上看,构建哈夫曼树只需要把权重低的结点依次连接起来并逐渐向根结点“进发”构建一棵树就可以,我们需要把这一方法总结为计算机可以操作的,带有一般规律的算法。
哈夫曼最早给出了这一算法,称为哈夫曼算法,叙述如下:
- 根据给定的n个权值 ω 1 , ω 2 , . . . , ω n {ω_1, ω_2, ..., ω_n} ω1,ω2,...,ωn构成n棵二叉树的集合 F = T 1 , T 2 , . . . , T n F={T_1,T_2,...,T_n} F=T1,T2,...,Tn,其中每棵二叉树 T i T_i Ti中只有一个带权为 ω i ω_i ωi的根节点,其左右子树均空。
- 在 F F F中选取两棵根节点的权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根节点权值为其左、右子树上根节点的权值之和。
- 在 F F F中删除这两棵树,同时将新得到的二叉树加入 F F F中。
- 重复2和3,直到 F F F中只含一棵树为止。这棵树便是Haffman Tree。
def findMinTree2(self,data):
# data是多个Huffman Tree的集合
# 找到data中weight最小的两个tree,tree1最小,tree2次之
_data = data.copy() # 浅拷贝
minTree1 = _data.pop()
minTree2 = _data.pop()
for t in _data:
if t.weight < minTree1.weight:
minTree1 = t
elif t.weight < minTree2.weight:
minTree2 = t
if minTree1.weight > minTree2.weight:
temp = minTree1
minTree1 = minTree2
minTree2 = temp
return (minTree1,minTree2)
def buildHuffmanTree(self,data):
# data是待构建的一系列数据,结构为集合{v1:w1,v2:w2,...,vn,wn}
# v是数据的值
# w是数据的权重
F = set()
print(data)
for item in data:
T = HuffmanTree(data[item],item)
F.add(T)
while len(F) > 1:
tree1,tree2 = self.findMinTree2(F) # 获得权值最小的两个树
# 去掉最小的两个树
F.remove(tree1)
F.remove(tree2)
# 建立新树
newTree = HuffmanTree(tree1.weight+tree2.weight)
# 新树与tree1,tree2的关系如下
newTree.leftChild = tree1
tree1.parent = newTree
newTree.rightChild = tree2
tree2.parent = newTree
# 新树加入集合
F.add(newTree)
result = F.pop()
# 方式一:返回Huffman Tree而不改变执行操作的树
return result
# 方式二:直接赋值给进行操作的树
# self.value = result.value
# self.weight = result.weight # 权值,默认为1
# self.parent = result.parent # 维护parent属性,为了方便向上遍历
# self.leftChild = result.leftChild
# self.rightChild = result.rightChild
3)操作:输出Huffman Tree
哈夫曼树主要有两个应用,应用于最佳判定算法时,输出的内容应当有助于构建判定树,应用于哈夫曼编码时,输出的内容应当有助于哈夫曼编码的编码和解码。
对于这两种应用,我们采用不同的输出方式:
- 应用于最佳判定算法时,采用嵌套列表的方式输出,同时打印结果;
- 应用于哈夫曼编码时,采用字典的方式输出,同时打印结果。
代码:嵌套列表输出
这一代码的逻辑较简单,只需要普通的递归即可。
递归的逻辑:将树简单分为左子树和右子树,置于列表index为0和1的位置,在位置上调用自身,其基本结束条件是叶节点,直接返回value。
# 输出嵌套列表,应用于最佳判定算法,只输出叶子节点即可
def exportByList(self,tree):
if tree.leftChild and tree.rightChild:
return [tree.exportByList(tree.leftChild),tree.exportByList(tree.rightChild)]
else:
return tree.value
# 返回的结果为['a', [['d', 'c'], ['b', 'f']]]
代码:字典输出
这一代码相对复杂,主体为对Huffman Tree进行遍历并记录路径。
遍历的顺序近似前序遍历,即母结点->左子树->右子树。
采用record字符串来记录当前结点编码,字符串在当前结点前进或后退时实时更新,编码标准按照code列表来设计。
为决定下一步的走向以及何时结束循环,代码采用了path集合来记录经过的结点,循环的几种情况如下:
- 当前结点为叶子节点(value存在),存入编码库(huffmanDict),向上退一步;
- 当前结点不是叶子节点,且是新的路径,则进入左子树;
- 当前结点不是叶子节点,是旧的路径,未进入过右子树,则进入右子树;
- 当前结点不是叶子节点,是旧的路径,进入过右子树,则判断其是否存在母结点,存在母结点则向上退一步,不存在母结点则结束循环。
这一循环中当前结点的基本路径为:根节点->左子树->右子树->根节点,以递归的方式按前述路径“行走”,完成循环。
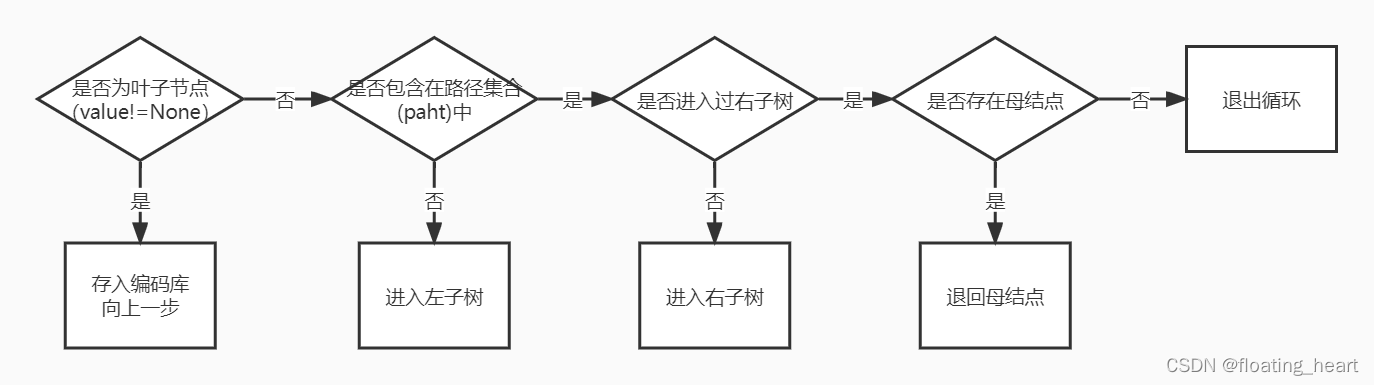
# 输出字典,标记Huffman编码
def exportByDict(self,tree):
huffmanDict = {}
code = ['0','1'] # 编码标准:左子树路径为0,右边为1
currentTree = tree # 当前位置
path = set() # 记录路径(经过的结点)
record = '' # 当前编码/当前路径结点
while True:
if currentTree.value: # 叶子结点
huffmanDict[currentTree.value] = record # 记录编码
path.add(record) # 存入路径
currentTree = currentTree.parent # 回退一步
record = record[:-1] # 编码更新
else:
if record not in path: # 新的路径,默认进入左子树
path.add(record)
currentTree = currentTree.leftChild
record += code[0]
else: # 旧的路径
if (record + code[1]) not in path:
# 没进入过右子树,进入右子树
currentTree = currentTree.rightChild
record += code[1]
else:
# 进入过右子树
if currentTree.parent:
# 存在母结点,存在则退一步,
currentTree = currentTree.parent
record = record[:-1]
else:
# 不存在母结点说明循环完毕,从右子树回到了根节点,退出循环
break
print(huffmanDict)
return huffmanDict
# print的结果为{'a': '0', 'd': '100', 'c': '101', 'b': '110', 'f': '111'}
4)操作:Huffman编码编译与解码
这些操作比较简单,这里把相关操作放在了类之外,代码如下:
# 编码
# code为之前输出的字典
# con为需要编译的内容(字符串)
def huffmanCode(code,con):
result = ''
for item in con:
result += code[item]
return result
# 解码
# code为编码字典 {实际的文字:编码后的文字}
# con为需要解码的内容
def huffmanDecode(code,con):
new_dict = {v:k for k,v in code.items()}
c = ''
result = ''
for item in con:
c += item
if c in new_dict:
result += new_dict[c]
c = ''
return result
在哈夫曼树的实现中,代码的操作没有过于复杂的地方,之后我会补充JavaScript的代码。
在了解图的搜索算法之后,也许能简化这些代码

















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









