







概述
论文链接: https://arxiv.org/pdf/2104.06935.pdf
论文名称: Stereo Radiance Fields (SRF):
Learning View Synthesis for Sparse Views of Novel Scenes
我们知道,对于原生的NeRF来说,重新训练一个场景往往需要两三天的时间。
这篇文章提出了所谓的Stereo Radiance Fields,即SRF,号称只用少量的视角就可以泛化至新的场景。这篇文章最吸引人的地方就在于对于新的场景并不需要一轮重新的训练,取而代之的,只需要10~15分钟的微调即可,而这种微调也只需要10余张的影像就够了。
其核心的idea受传统的MVS方法启发,即,通过寻找立体图像中patch的相似性来估计物方表面点。在SRF中,通过给定立体像对待相似性程度来预测物方点的颜色和体密度。这样做的好处是:深度学习网络可以显示地学习到图像块之间的相似性,而这种相似性对于所有的场景来说都是通用的。
实验表明SRF实在地学习了内在的结构,而非对一个场景进行过拟合。我们在DTU数据的多个场景上进行了训练,但是在泛化或者说测试新场景的时候并没有进行重新的训练,而是只用了10~15分钟的微调,就可以得到比那些对这个场景重新进行训练的模型更为锐利,更有细节的效果。此外对于新的场景来说,只需要10余张稀疏的影像作为输入。
方法
对于每一个物方点来说,都会被投影到可见的视图中,并提取像素级别的view features。
而后,view features将会逐对地去过一系列的滤波器,正如传统方法中寻找同名点的过程一样。所得到的matrix包含了逐对的相似性分数,该matrix将会再过一个CNN,目的是从所有可见的views之间预测得到3D点理想的radiance。
假设现在有十余张影像,首先使用一个编码网络去分别提取这十张影像的多尺度特征,然后再用一个MLP网络去替代传统的特征匹配模块,输出得到一个相似性分数的集合。
方法
背景
神经辐射场 NeRF
体密度编码了物体表面的区域(在物体表面处达到最大值,其他地方相对都要小一些)。NeRF通过函数
f
f
f对场景进行记忆,具体有:
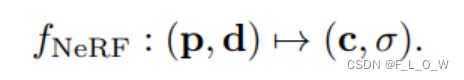
在有密集输入的情况下,NeRF的效果还是不错的。However, it fails to generalize to novel scenes as point coordinates do not carry scene-specific information.
这句话也比较好的概括了,为什么NeRF不能够泛化,即输入的点坐标,其实并没有携带与场景相关的信息。
我们简易的将NeRF新视图生成的过程,用下图表示:
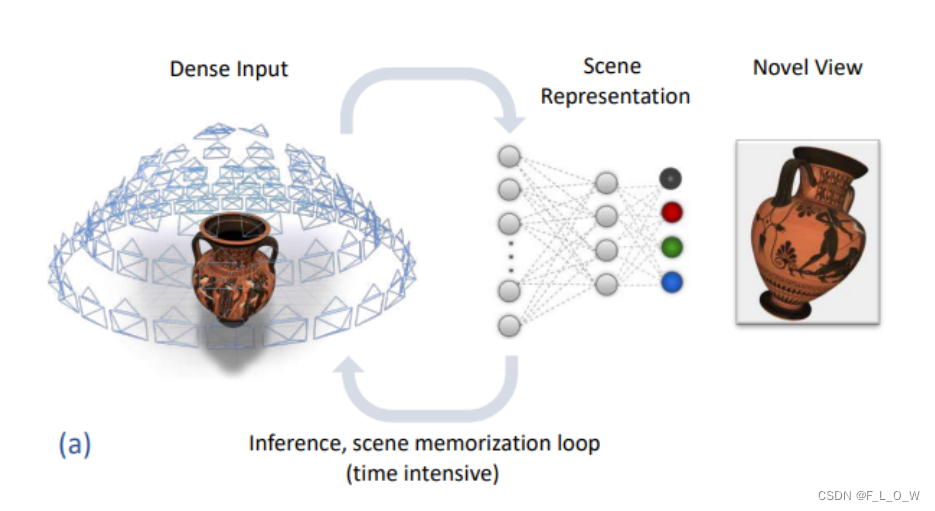
显然在这个时候,函数 f f f本身就变成了一种场景表达。
而SRF则旨在学习一个能够模拟多视图重建、合成视角内插的神经网络,且能够在场景测试的时候,真正的根据测试场景进行泛化。
SRF的示意图见下:

为了做到这个程度,文章使用了完全不同的点云编码架构,即:
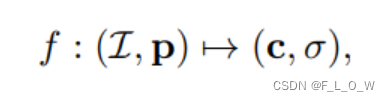
其中,
I
=
{
I
i
}
i
=
1
N
\mathcal{I}=\left\{I_i\right\}_{i=1}^N
I={Ii}i=1N表示N张参考图像。
注意,这里没有考虑到视角相关的effects。这将作为future work。
传统MVS方法
不管是sfm、mvs方法,还是本文提出的SRF方法,都基于一个基本观察:
In absence of occlusion, surface 3D points of an object project to corresponding photo-metrically consistent image regions in the multiple views, whereas nonsurface 3D points land on non-corresponding different regions.
自然地,而那些不在物体表面的点,也不会在多视图中取得一致性。如下图所示:
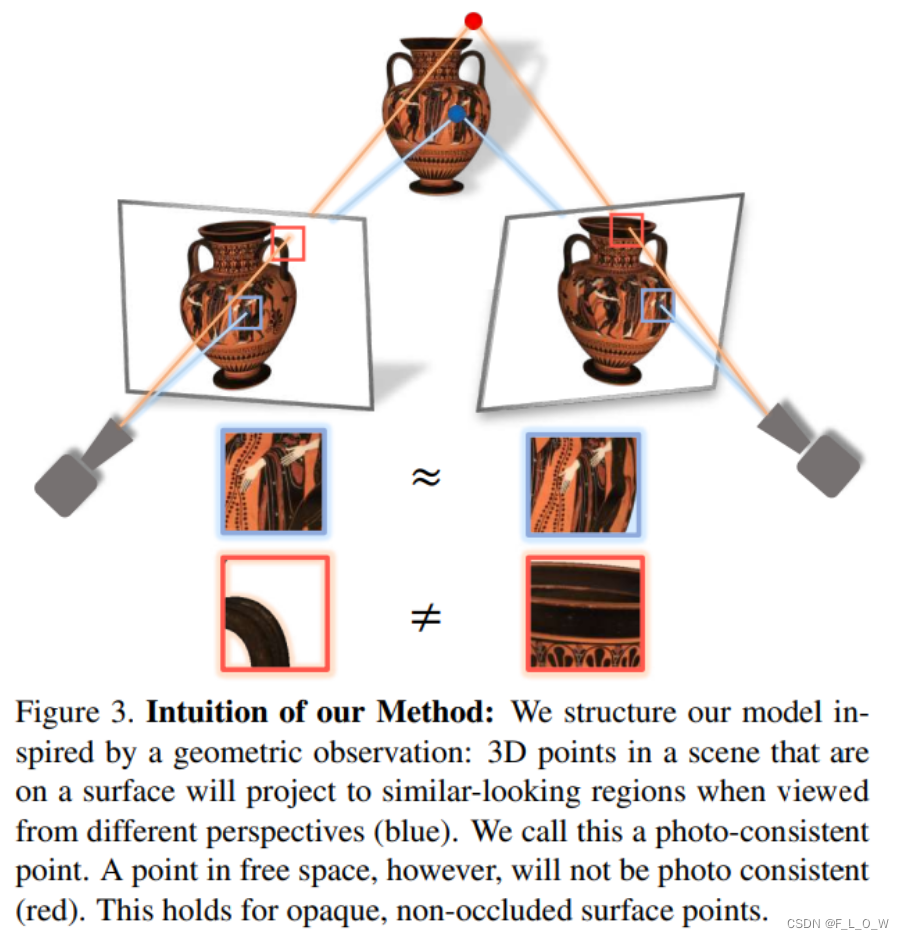
相反地,自然可以通过找多视图之间的相似性区域,并做三角化,来实现物方表面点的找寻。
在传统方法中,这样的过程是离散的pipeline。
首先,找到信息量多的、有特色的区域。
其次,使用如SIFT一类的算子进行特征匹配。多视图之间的描述子一致性比较高的情况下,将形成匹配。
SRF以一种端到端的无监督的方式(使用渲染损失),内在地模拟了对应点的匹配。
在SRF中,使用了一个2D CNN 图像编码网络来学习点的特征描述子。
Classical correspondence finding is emulated in SRF by processing point descriptors in pairs.
SRF


第一步,对物方点p进行编码,将其投影至每一张影像上,并建立其局部的特征描述子;
第二步,如果物方点落在了目标物体表面且多视图一致,那么第一步中所拿到的特征描述子集理应可以match,此时就会通过来模拟特征匹配的过程;
第三步,第二步中的编码将会通过解码器进行解码,形成NeRF的表达形式。
具体地,整个过程可以用数学语言描述成:
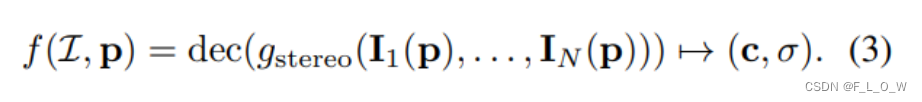
影像编码网络
NeRF的输入是三维点的坐标,可以说是一点和scene-specific的信息一点关系也没有。
而SRF对每一个三维点,编码了多视图影像上的特征。
首先构建了一个共享权重的2D CNN,能够输出多尺度的特征描述子,相当于既能够包含局部信息,又能够包含全局信息,整体来说,感受野比较全。
由于三维点的投影往往是连续的,而特征却位于离散的网格,因此,我们使用了双线性的内插。【怎么理解?】
当三维点p投影到影像外的时候,我们则直接使用零值padding。
更多的细节可以参照补充材料.
无监督的立体模块
当物方点 p在表面的时候,会满足多视图一致性,且应该有更高的体密度。
有序地,为了处理任意数量的影像,立体模块逐对地对影像进行处理,输出相似性比分:
如果两两进行组合,对每一个图像对都进行计算的话,最后将会产生一个size为的向量,使用个神经元对图像对进行相似性比分计算,如下图所示:

所谓的stereo features的高就是所有两两影像对的对数,宽则是神经元的数量。
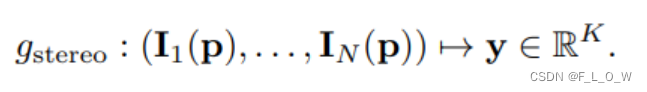
辐射场解码器
用了一个MLP
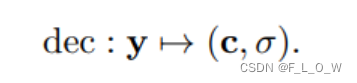
实验
泛化能力
首先,检验SRF的泛化能力。测试集是unseen的。

数据
DTU Multi-View StereoPsis Dataset。
baseline
NeRF、LLFF
生成彩色网格
SRF可以预测得到每一个点的颜色和体密度,然后通过设置阈值筛选提密度,而后再通过Marching cubes算法得到mesh。
此外,再以这种坐标作为SRF的输入,可以通过SRF获得三维点预测的颜色,并将这种颜色添加至三维点云上,即可得到带颜色的mesh模型。
当然,这种获得彩色模型的方式,也适用于常规的NeRF。

更加激进的泛化能力测试
在这之前我们已经知道集成几何信息以及数据信息可以有助于泛化。接下来我们将进一步的对网络结构进行泛化性测试,只不过在这一次测试中采用了更激进的设定,也就是我们在一个合成的拖拉机物体上进行30分钟以上的训练但是却在另外一个完全不同的物体上进行测试,所谓完全不同的物体在这里可以指为麦克风。
虽然在几何以及外表上有着非常大的差别,但是网络结构仍然留存着不错的泛化能力,如下图所示:
讨论与结论
这篇文章提出了一种模仿传统多视立体的视图合成方法。
文章将三维点反投影至影像中,并提取影像中的多尺度特征,并逐对地的进行处理。这样做之后,网络就会学习到一系列的相似性分数,且损失仅仅有渲染损失,也就是说整体结构上是自监督的。这样的过程模拟了传统立体视觉中的特征匹配步骤。
实验表明本文所提出的方法确实的学到了多个场景之间可通用的内在结构。
不管怎么说,能够结合传统的几何与神经渲染本就是一个令人兴奋的方向。

















 3578
3578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











