







我想很多人入门深度学习可能都是从这个项目开始的,相当于是机器学习的
Hello World。但我第一个深度学习项目是一年前跑的吴恩达的手指数字识别课后作业,感兴趣的读者也可以试着跑一下,写者认为看着机器学习的过程也是非常有意思的。本文代码具有详细注释,便于第一次入门深度学习的读者学习。

在本文中,我们将在
PyTorch中构建一个简单的卷积神经网络,并使用MNIST数据集训练它识别手写数字。 MNIST包含70,000张手写数字图像: 60,000张用于培训,10,000张用于测试。图像是灰度(即通道数为1),28x28像素,并且居中的,以减少预处理和加快运行。
PyTorch是一个非常流行的深度学习框架。但是与其他框架不同的是,PyTorch具有动态执行图,意味着计算图是动态创建的。

下面附上详细代码(读者可以注意看注释,其中详细介绍了每一步,绝对是最细的注释,助你看懂全过程)
import torch
import torchvision
from torch.utils.data import DataLoader
import torch.nn as nn #torch.nn层中包含可训练的参数
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
#注意下面两行在matplotlib使用上出错时,加上可不出错
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
n_epochs = 3 #epoch的数量定义了将循环整个训练数据集的次数
batch_size_train = 64 #每次投喂的样本数量
batch_size_test = 1000
learning_rate = 0.01
momentum = 0.5 #优化器的超参数
log_interval = 10
random_seed = 1
torch.manual_seed(random_seed) #对于可重复的实验,须为任何使用随机数产生的东西设置随机种子
#训练集数据
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=True, download=True, #加载该数据集(download=True)
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])), #Normalize()转换使用的值0.1307和0.3081是该数据集的全局平均值和标准偏差,这里将它们作为给定值
batch_size=batch_size_train, shuffle=True)
#测试集数据
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_test, shuffle=True) #使用size=1000对这个数据集进行测试
#查看一批测试数据由什么组成
examples = enumerate(test_loader) #enumerate指循环,类似for
batch_idx, (example_data, example_targets) = next(examples) #example_targets是图片实际对应的数字标签,example_data是指图片本身数据
print(example_targets)
print(example_data.shape) #输出torch.Size([1000, 1, 28, 28]),意味着我们有1000个例子的28x28像素的灰度(即没有rgb通道)
#定义卷积神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# batch*1*28*28(每次会送入batch个样本,输入通道数1(黑白图像),图像分辨率是28x28)
# 下面的卷积层Conv2d的第一个参数指输入通道数,第二个参数指输出通道数(即用了几个卷积核),第三个参数指卷积核的大小
self.conv1 = nn.Conv2d(1, 10, kernel_size=5) #因为图像为黑白的,所以输入通道为1,此时输出数据大小变为28-5+1=24.所以batchx1x28x28 -> batchx10x24x24
self.conv2 = nn.Conv2d(10, 20, kernel_size=5) #第一个卷积层的输出通道数等于第二个卷积层是输入通道数。
self.conv2_drop = nn.Dropout2d() #在前向传播时,让某个神经元的激活值以一定的概率p停止工作,可以使模型泛化性更强,因为它不会太依赖某些局部的特征
self.fc1 = nn.Linear(320, 50) #由于下部分前向传播处理后,输出数据为20x4x4=320,传递给全连接层。# 输入通道数是320,输出通道数是50
self.fc2 = nn.Linear(50, 10)#输入通道数是50,输出通道数是10,(即10分类(数字1-9),最后结果需要分类为几个就是几个输出通道数)。全连接层(Linear):y=x乘A的转置+b
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2)) # batch*10*24*24 -> batch*10*12*12(2*2的池化层会减半,步长为2)(激活函数ReLU不改变形状)
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) #此时输出数据大小变为12-5+1=8(卷积核大小为5)(2*2的池化层会减半)。所以 batchx10x12x12 -> batchx20x4x4。
x = x.view(-1, 320) # batch*20*4*4 -> batch*320
x = F.relu(self.fc1(x)) #进入全连接层
x = F.dropout(x, training=self.training) #减少遇到过拟合问题,dropout层是一个很好的规范模型。
x = self.fc2(x)
#计算log(softmax(x))
return F.log_softmax(x)
#初始化网络和优化器
#如果我们使用GPU进行训练,应使用例如network.cuda()将网络参数发送给GPU。将网络参数传递给优化器之前,将它们传输到适当的设备很重要,否则优化器无法以正确的方式跟踪它们。
network = Net()
optimizer = optim.SGD(network.parameters(), lr=learning_rate,
momentum=momentum)
train_losses = []
train_counter = []
test_losses = []
test_counter = [i*len(train_loader.dataset) for i in range(n_epochs + 1)]
#每个epoch对所有训练数据进行一次迭代。加载单独批次由DataLoader处理
#训练函数
def train(epoch):
network.train() #在训练模型时会在前面加上
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad() #使用optimizer.zero_grad()手动将梯度设置为零,因为PyTorch在默认情况下会累积梯度
output = network(data) #生成网络的输出(前向传递)
loss = F.nll_loss(output, target) #计算输出(output)与真值标签(target)之间的负对数概率损失
loss.backward() #对损失反向传播
optimizer.step() #收集一组新的梯度,并使用optimizer.step()将其传播回每个网络参数
if batch_idx % log_interval == 0: #log_interval=10,每10次投喂后输出一次
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
train_losses.append(loss.item()) #添加进训练损失列表中
train_counter.append(
(batch_idx * 64) + ((epoch - 1) * len(train_loader.dataset)))
#神经网络模块以及优化器能够使用.state_dict()保存和加载它们的内部状态。这样,如果需要,我们就可以继续从以前保存的状态dict中进行训练——只需调用.load_state_dict(state_dict)。
torch.save(network.state_dict(), './model.pth')
torch.save(optimizer.state_dict(), './optimizer.pth')
train(1)
#测试函数。总结测试损失,并跟踪正确分类的数字来计算网络的精度。
def test():
network.eval() #在测试模型时在前面使用
test_loss = 0
correct = 0
with torch.no_grad(): #使用上下文管理器no_grad(),我们可以避免将生成网络输出的计算结果存储在计算图(计算过程的构建,以便梯度反向传播等操作)中。(with是使用的意思)
for data, target in test_loader:
output = network(data) #生成网络的输出(前向传递)
# 将一批的损失相加
test_loss += F.nll_loss(output, target, size_average=False).item() #NLLLoss 的输入是一个对数概率向量和一个目标标签
pred = output.data.max(1, keepdim=True)[1] ## 找到概率最大的下标
correct += pred.eq(target.data.view_as(pred)).sum() #预测正确的数量相加
test_loss /= len(test_loader.dataset)
test_losses.append(test_loss)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
test()
#我们将在循环遍历n_epochs之前手动添加test()调用,以使用随机初始化的参数来评估我们的模型。
for epoch in range(1, n_epochs + 1):
train(epoch)
test()
#评估模型的性能,画损失曲线
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red')
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.show()
#输出自己找的测试图片,比较模型的输出。
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
with torch.no_grad():
output = network(example_data)
fig1 = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(
output.data.max(1, keepdim=True)[1][i].item()))
plt.xticks([])
plt.yticks([])
plt.show()
#继续对网络进行训练,并看看如何从第一次培训运行时保存的state_dicts中继续进行训练。我们将初始化一组新的网络和优化器。
continued_network = Net()
continued_optimizer = optim.SGD(network.parameters(), lr=learning_rate,
momentum=momentum)
network_state_dict = torch.load('model.pth') #见左侧项目列表,有该文件
continued_network.load_state_dict(network_state_dict) #使用.load_state_dict(),我们现在可以加载网络的内部状态,并在最后一次保存它们时优化它们。
optimizer_state_dict = torch.load('optimizer.pth') #见左侧项目列表,有该文件
continued_optimizer.load_state_dict(optimizer_state_dict)
#同样,运行一个训练循环应该立即恢复我们之前的训练。为了检查这一点,我们只需使用与前面相同的列表来跟踪损失值
for i in range(4,9):
test_counter.append(i*len(train_loader.dataset))
train(i)
test()
#我们再次看到测试集的准确性从一个epoch到另一个epoch有了(运行更慢的,慢的多了)提高。
#输出自己找的测试图片,比较模型的输出。
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
with torch.no_grad():
output = network(example_data)
fig1 = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(
output.data.max(1, keepdim=True)[1][i].item()))
plt.xticks([])
plt.yticks([])
plt.show()
如果在matplotlib使用上出错时,可加上
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
会使错误消失,具体我也不知道是为什么,但是百度得到的解决方案,好用就是了。
下面附上运行结果:
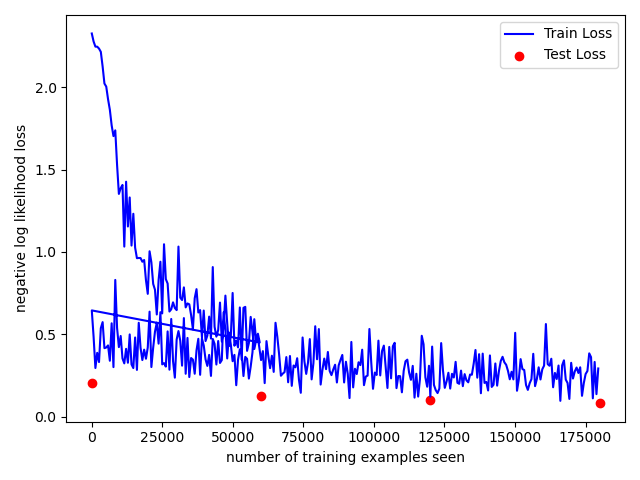
(1)训练曲线,可以看到测试的损失在一点一点变小
(2)这是在epoch=3时的结果,可以看到准确率已经达到97%,识别手写数字已经几乎没有问题


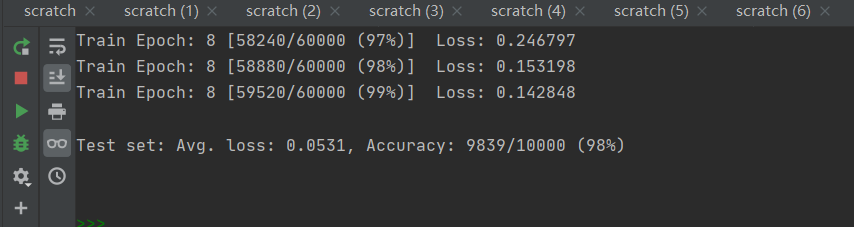
(3)这是在epoch=8时的结果,可以看到准确率已经达到98%,识别手写数字变得更准确

如果读者仍可以继续训练,可以再试试更高的epoch,不过要注意过拟合的问题,希望本文对你有所帮助。

end~

















 1494
1494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









