







Redis学习二
切片集群
应用场景主要存储的数据过大 导致内存不足和对ROB对数据的持久化以及对数据的恢复的问题
为了解决解决这种问题偶俩个方案
一纵向扩展(就是对硬件的加持 [软件不行硬件来凑])
二横向扩展(增加当前 Redis 实例的个数)
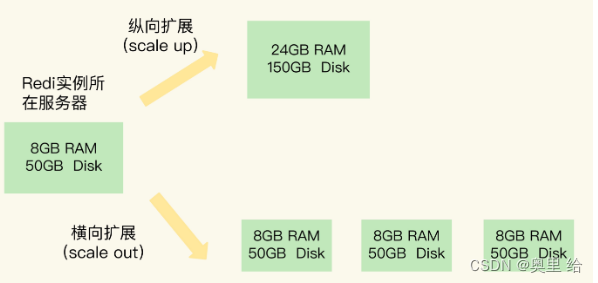
redis的数据切片和实例对应的分布
redis实现切片集群使用的是Redis Cluster方案
- Redis Cluster 方案采用哈希槽来处理数据和实例之间的映射关系。一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中。
- 我们在部署 Redis Cluster 方案时,可以使用 cluster create 命令创建集群,此时,Redis 会自动把这些槽平均分布在集群实例上。
- 客户和集群中的某个实例建立连接后,实例会将哈希槽的信息发给客户端,而实例会把自己的哈希槽发送给和他相连接的实例。(各个实例之间其实是相互连接的,类似图的结构 去中心化)
- 但实例中有增加和删除时会出现重新分配槽函数(主要为了负载均衡)Redis提供了重定向机制
当客户端把一个键值对的操作请求发给一个实例时,如果这个实例上并没有这个键值对映射的哈希槽,那么,这个实例就会给客户端返回下面的 MOVED命令响应结果,这个结果中就包含了新实例的访问地址。
上面是针对的是数据已经迁移完成但是数据没有迁移完成会返回ASK(也包含了新的实例的地址)客户端需要发送ASKING命令才能读取。数据迁移会有两种情况一种是迁移到新的实例会发送ASK命令 一种是客户端获取当前的key值还没有迁移过去会直接返回这个可以对应的value值
MOVE会更新客户端的哈希槽分配信息而ASK不会 .
- 负载均衡不是自动触发的,需要运维来维护。
需要了解的知识集群管理的两个核心知识
如何用更少的内存去存储更多的数据
string一切万物皆可用string去存储,但是string的结构和所占的容量有时候会违背开发的理念。
首先不要忘记redis维护了一个全集的哈希 每当插入一个string的时候就需要在全局哈希里分配一个值 而string内部是RedisObject
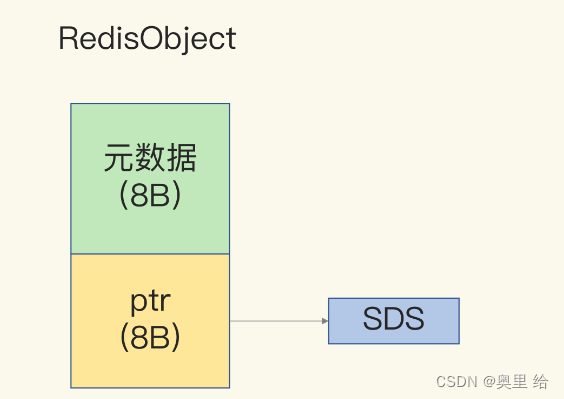
需要注意的是44个字节的计算和存储long类型整数的区别
redis底层有一个数据结构为压缩列表(ziplist)
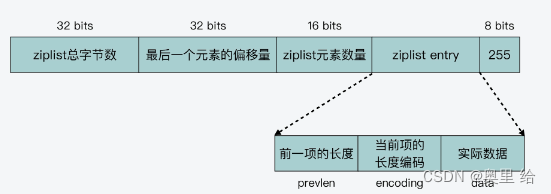
压缩列表是一个连续的空间其中entry是其中的元素
entry中的prevlen只有1和5字节之分
这种结构主要用来存储int类型吧 对int做了优化
集合的统计
集合类型常见的四种统计模式,包括聚合统计、排序统计、二值状态统计和基数统计。
聚合统计
聚合统计用于set类型 交集 (SINTERSTORE) 差集只能用于set (SDIFFSTORE) 并集(SUNIONSTORE)
Set 的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞。 可以从主从集群中选择一个从库,让它专门负责聚合计算,或者是把数据读取到客户端,在客户端来完成聚合统计,这样就可以规避阻塞主库实例和其他从库实例的风险了。
排序统计
在 Redis 常用的 4 个集合类型中(List、Hash、Set、Sorted Set),List 和 Sorted Set 就属于有序集合。List 是按照元素进入 List 的顺序进行排序的,而 Sorted Set 可以根据元素的权重来排序。
Sorted Set 的 ZRANGEBYSCORE 命令就可以按权重排序后返回元素。这样的话,即使集合中的元素频繁更新,Sorted Set 也能通过 ZRANGEBYSCORE 命令准确地获取到按序排列的数据。
二值状态统计
Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态。你可以把 Bitmap 看作是一个 bit 数组。
Bitmap 提供了 GETBIT/SETBIT 操作,使用一个偏移值 offset 对 bit 数组的某一个 bit 位进行读和写。不过,需要注意的是,Bitmap 的偏移量是从 0 开始算的,也就是说 offset 的最小值是 0。当使用 SETBIT 对一个 bit 位进行写操作时,这个 bit 位会被设置为 1。Bitmap 还提供了 BITCOUNT 操作,用来统计这个 bit 数组中所有“1”的个数。
,Bitmap 支持用 BITOP 命令对多个 Bitmap 按位做“与”“或”“异或”的操作,操作的结果会保存到一个新的 Bitmap 中。
基数统计
HyperLogLog 是一种用于统计基数的数据集合类型,它的最大优势就在于,当集合元素数量非常多时,它计算基数所需的空间总是固定的,而且还很小。
在统计 UV 时,你可以用 PFADD 命令(用于向 HyperLogLog 中添加新元素)把访问页面的每个用户都添加到 HyperLogLog 中。
PFADD page1:uv user1 user2 user3 user4 user5
接下来,就可以用 PFCOUNT 命令直接获得 page1 的 UV 值了,这个命令的作用就是返回 HyperLogLog 的统计结果。
PFCOUNT page1:uv
总结
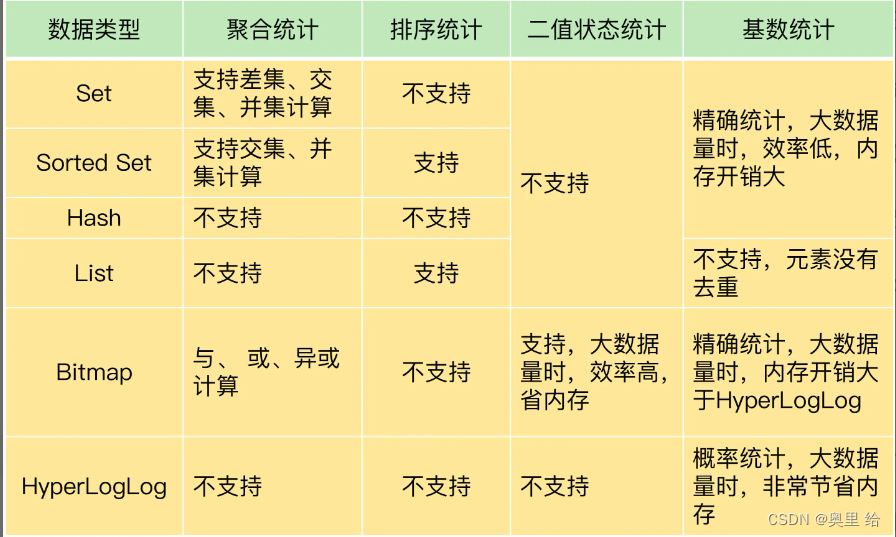
Set 和 Sorted Set 都支持多种聚合统计,不过,对于差集计算来说,只有 Set 支持。Bitmap 也能做多个 Bitmap 间的聚合计算,包括与、或和异或操作。
当需要进行排序统计时,List 中的元素虽然有序,但是一旦有新元素插入,原来的元素在 List 中的位置就会移动,那么,按位置读取的排序结果可能就不准确了。而 Sorted Set 本身是按照集合元素的权重排序,可以准确地按序获取结果,所以建议你优先使用它。
如果我们记录的数据只有 0 和 1 两个值的状态,Bitmap 会是一个很好的选择,这主要归功于 Bitmap 对于一个数据只用 1 个 bit 记录,可以节省内存。
对于基数统计来说,如果集合元素量达到亿级别而且不需要精确统计时,我建议你使用 HyperLogLog。
1.如果是在集群模式使用多个key聚合计算的命令,一定要注意,因为这些key可能分布在不同的实例上,多个实例之间是无法做聚合运算的,这样操作可能会直接报错或者得到的结果是错误的!
2. 当数据量非常大时,使用这些统计命令,因为复杂度较高,可能会有阻塞Redis的风险,建议把这些统计数据与在线业务数据拆分开,实例单独部署,防止在做统计操作时影响到在线业务。
3. Set数据类型,使用SUNIONSTORE、SDIFFSTORE、SINTERSTORE做并集、差集、交集时,选择一个从库进行聚合计算”。这3个命令都会在Redis中生成一个新key,而从库默认是readonly不可写的,所以这些命令只能在主库使用。想在从库上操作,可以使用SUNION、SDIFF、SINTER,这些命令可以计算出结果,但不会生成新key















 5170
5170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









