









一、写在最前
二、掌握spark的安装与环境配置
三、掌握Ubuntu下的Python的版本管理与第三方的安装
四、掌握windows下Pycharm与Ubuntu的同步连接
五、掌握Spark读取文件系统的数据
参考网站:
https://spark.apache.org/docs/1.1.1/quick-start.html
一、写在最前:实验环境
操作系统:Ubuntu16.04;
Spark版本:2.4.6;
Hadoop版本:2.7.2。
Python版本:3.5.。
点击下载:spark-2.4.6-bin-without-hadoop.tgz
二、掌握spark的安装与环境配置
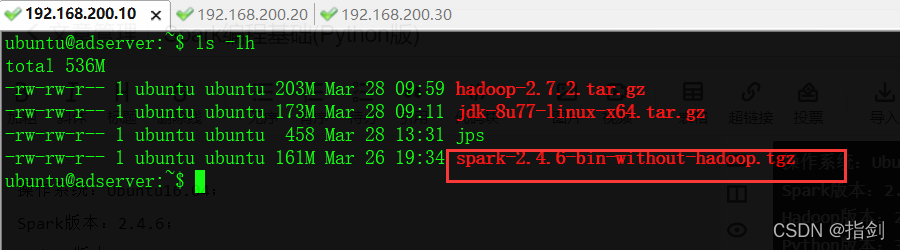
#### 1、解压缩spark压缩包,并移动ubuntu@adserver:~$ tar zxf spark-2.4.6-bin-without-hadoop.tgz
ubuntu@adserver:~$ ls -lh
total 536M
-rw-rw-r-- 1 ubuntu ubuntu 203M Mar 28 09:59 hadoop-2.7.2.tar.gz
-rw-rw-r-- 1 ubuntu ubuntu 173M Mar 28 09:11 jdk-8u77-linux-x64.tar.gz
-rw-rw-r-- 1 ubuntu ubuntu 458 Mar 28 13:31 jps
drwxr-xr-x 13 ubuntu ubuntu 4.0K May 30 2020 spark-2.4.6-bin-without-hadoop
-rw-rw-r-- 1 ubuntu ubuntu 161M Mar 26 19:34 spark-2.4.6-bin-without-hadoop.tgz
ubuntu@adserver:~$ sudo mv spark-2.4.6-bin-without-hadoop /usr/local/
ubuntu@adserver:~$ cd /usr/local/
ubuntu@adserver:/usr/local$ sudo mv spark-2.4.6-bin-without-hadoop/ spark
ubuntu@adserver:/usr/local$ ls -lh spark/

2、修改Spark环境变量文件
ubuntu@adserver:~$ cd /usr/local/spark/conf/
ubuntu@adserver:/usr/local/spark/conf$ pwd
/usr/local/spark/conf
ubuntu@adserver:/usr/local/spark/conf$ cp spark-env.sh.template spark-env.sh
ubuntu@adserver:/usr/local/spark/conf$ vi spark-env.sh
编辑spark-env.sh文件(vim ./conf/spark-env.sh),在第一行添加以下配置信息:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop-2.7.2/bin/hadoop classpath)
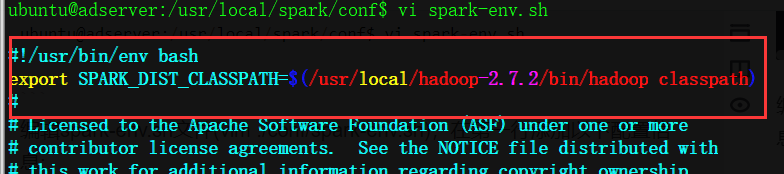
有了上面的配置信息以后,Spark就可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据。 配置完成后就可以直接使用,不需要像Hadoop运行启动命令。 通过运行Spark自带的示例,验证Spark是否安装成功。
执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中):
ubuntu@adserver:/usr/local/spark$ ./bin/run-example SparkPi 2>&1 | grep "Pi is"

修改/usr/local/spark/bin/pyspark 文件内容
修改45行 python 为 python3

执行命令sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 150
ubuntu@adserver:/usr/local/spark/bin$ sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 150

三、掌握Ubuntu下的Python的版本管理与第三方的安装
whereis python3 # 确定Python3目录
cd /usr/lib/python3.5 # 切换目录
sudo apt-get install python3-pip # 安装 pip 软件
sudo pip3 install -i https://pypi.doubanio.com/simple matplotlib # 安装 matplotlib
ubuntu@adserver:~$ whereis python3
python3: /usr/bin/python3 /usr/bin/python3.5 /usr/bin/python3.5m /usr/lib/python3 /usr/lib/python3.5 /etc/python3 /etc/python3.5 /usr/local/lib/python3.5 /usr/share/python3 /usr/share/man/man1/python3.1.gz
ubuntu@adserver:~$ cd /usr/lib/python3.5/
ubuntu@adserver:/usr/lib/python3.5$ sudo apt-get install python3-pip
ubuntu@adserver:/usr/lib/python3.5$ sudo pip3 install -i https://pypi.doubanio.com/simple matplotlib


四、掌握windows下Pycharm与Ubuntu的同步连接
#### 1) 打开 Pycharm ,打开 File --> settings --> 点击 + 号 , 然后 选择 SSH Interpreter 进行 Server 设置 ; 输入 虚拟机Ubuntu的IP地址以及用户名与密码

五、掌握Spark读取文件系统的数据
1)在pyspark中读取Linux系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
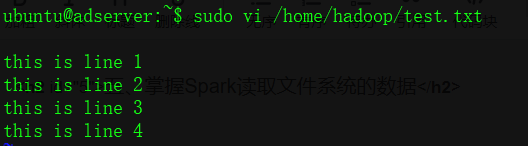
首先创建测试文件
$ vi /home/hadoop/test.txt
this is line 1
this is line 2
this is line 3
this is line 4
ubuntu@adserver:/usr/local/spark/bin$ pwd
/usr/local/spark/bin
ubuntu@adserver:/usr/local/spark/bin$ ./pyspark
Python 3.5.2 (default, Jan 26 2021, 13:30:48)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
22/03/28 15:57:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Python version 3.5.2 (default, Jan 26 2021 13:30:48)
SparkSession available as 'spark'.
>>> lines = sc.textFile("file:/home/hadoop/test.txt")
>>> lines.count()
4
>>>

2)在pyspark中读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;
ubuntu@adserver:~$ cd /home/hadoop/
ubuntu@adserver:/home/hadoop$ hadoop fs -ls /
Found 1 items
drwxrwx--- - ubuntu supergroup 0 2022-03-28 17:15 /tmp
ubuntu@adserver:/home/hadoop$ hadoop fs -mkdir -p /user/hadoop
ubuntu@adserver:/home/hadoop$ hadoop fs -put test.txt /user/hadoop/
ubuntu@adserver:/home/hadoop$ hadoop fs -ls /user/hadoop/
Found 1 items
-rw-r--r-- 3 ubuntu supergroup 60 2022-03-28 17:17 /user/hadoop/test.txt
ubuntu@adserver:/home/hadoop$ /usr/local/spark/bin/pyspark
>>> lines = sc.textFile("/user/hadoop/test.txt")
>>> lines.count()

3)编写独立应用程序,读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;
ubuntu@adserver:/home/hadoop$ sudo vi st-app.py
from pyspark import SparkContext
logFile = "/user/hadoop/test.txt" # Should be some file on your system
sc = SparkContext("local", "Simple App")
logData = sc.textFile(logFile).cache()
print("The HDFS file lines : ",logData.count())

ubuntu@adserver:/home/hadoop$ /usr/local/spark/bin/spark-submit --master local[4] st-app.py 2>&1 | grep "The HDFS"


















 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











