







机器学习实践中分类器常用的评价指标就是auc,不想搞懂,简单用的话,记住一句话就行
auc取值范围[0.5,1],越大表示越好,小于0.5的把结果取反就行。
想搞懂的,看An introduction to ROC analysis (Tom Fawcett)这篇论文把。我把这篇论文的要点整理了一下。
引子
假设有下面两个分类器,哪个好?
|
|
A类样本90个
|
B 类样本10个
| 分类精度(分类正确占比) |
|
分类器C1结果
|
A*
90 (100%)
|
A*10 (0%)
|
90%
|
|
分类器C2结果
|
A*70 + B*20
(78
%)
|
A*5 + B*5
(50%)
|
75%
|
测试样本中有A类样本90个,
B 类样本10个。
分类器C1
把所有的测试样本都分成了A类(比如分类器的输出只是一句代码 printf ("A") ),
分类器C2把A类的90个样本分对了70个,B类的10个样本分对了5个。
则C1的分类精度为 90%,C2的分类精度为75%,但直觉上,我们感觉C2更有用些。
我们需要一个评价指标,能客观反映对正样本、负样本综合预测的能力,还要考虑消除样本倾斜的影响(其实就是归一化之类的思想,实际中很重要,比如pv总是远远大于click),这就是auc指标能解决的问题。
啥是auc
roc曲线下的面积就是auc,所以要先搞清楚roc。
先看二分类问题,预测值跟实际值有4种组合情况,见下面的列联表
|
| 预测 | 合计 | ||
| 1 | 0 | |||
| 实际
| 1 (P) | True Positive(TP) | False Negative(FN) | Actual Positive(TP+FN) |
| 0 (N) | False Positive(FP) | True Negative(TN) | Actual Negative(FP+TN) | |
| 合计 | Predicted Positive(TP+FP) | Predicted Negative(FN+TN) | TP+FP+FN+TN | |
我们让:
纵坐标是true positive rate(TPR) = TP / (TP+FN=P) (分母是横行的合计)直观解释:实际是1中,猜对多少
横坐标是false positive rate(FPR) = FP / (FP+
TN=N
) 直观解释:实际是0中,错猜多少
|
|
FPR
|
TPR
|
|
c1
|
10/10=1
|
90/90=1
|
|
c2
|
5/10=0.5
|
70/90=0.78
|
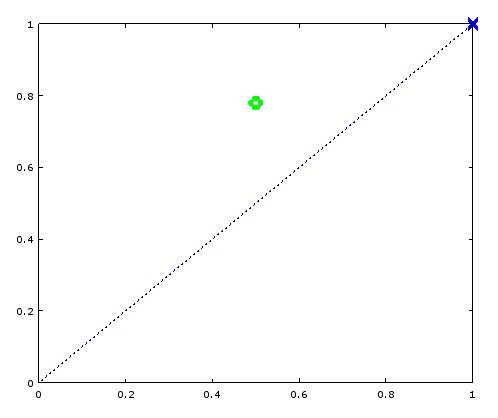
所以评估标准改成离左上角近的是好的分类器。(考虑了正负样本的综合分类能力)
如果一个分类器能输出score,调整分类器的阈值,把对应的点画在图上,连成线这条线就是roc,曲线下的面积就是auc(Area under the Curve of ROC )
有啥特点
- roc上的点,越靠近左上角越好。(tp rate is higher, fp rate is lower,or both )
- y = x这条对角线代表随机猜测的结果。比如用投掷硬币结果来猜测,点在(0.5, 0.5) ;假设硬币不均匀,90%概率向上,那就是(0.9, 0.9) (正例中,90%能猜对;反例中,90%猜错)
- auc范围[0.5, 1],小于0.5的分类器把结果取反一下把。
- 分类器不一定要输出概率,输出可比较的score也行。
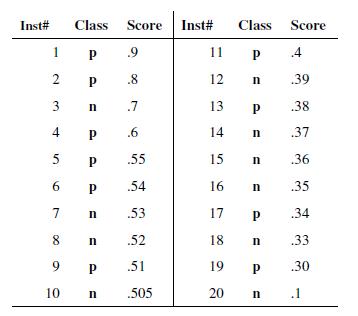
- 画roc曲线的时候,threshold采样点是有限的离散化点,其实就用score,毕竟score是有限的。Any ROC curve generated from a finite set of instances is actually a step function。画曲线需要两个值TP/P和FP/N。P和N可以先扫描一遍找出来,后面不会变的。把score排一下序,从高到底,依次作为threshold(>=threshold的我们预测为p,其他为n)。TP判断class为P的加一就行,FP判断class为N的也加一就行。变得很简单了。
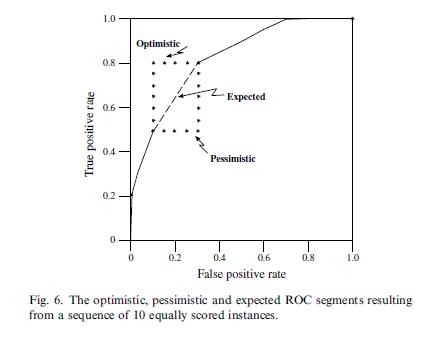
这里就有一个细节问题了,score相同的点怎么处理?
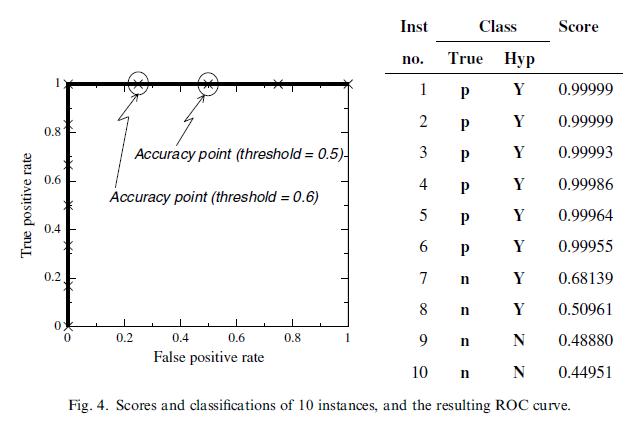
论文里给出一个直观的图,先累加正样本和先累加负样本的差异(先加TP往上走,还是FP往右走)。结论就是score相同的样本一起算,不要一个样本就输出一个采样点。 - auc的直观含义是任意取一个正样本和负样本,正样本得分大于负样本的概率。The ROC curve shows the ability of the classifier to rank the positive instances relative to the negative instances, and it is indeed perfect in this ability.(想想这个组合问题的概率怎么求?对每一个负样本,把分数大于这个负样本的正样本个数累加起来,最后除以总的组合数P*N,前面算roc curve是不是也类似这样累加?除了P或者N先除了。还不确定看下面的代码实现,代码里为了平滑,求的是小梯形的面积,而不是矩形,稍微有些差别。)论文里举了个例子,auc算出来是1,但是可以发现预测结果不是完全对的(7和8就预测错了)。但实际上只是threshold选择得不好而已,threshold选0.7这里就行了。
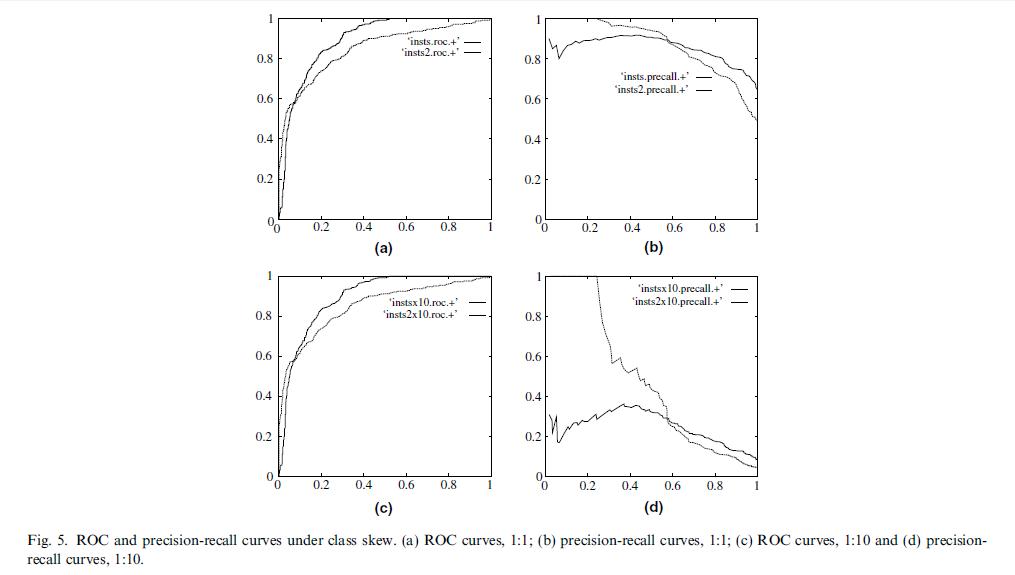
- 容忍样本倾斜的能力。ROC curves have an attractive property: they are insensitive to changes in class distribution. 看看公式TP/P 和FP/N本身就包含了归一化的思想(上面的表格每一行乘以常数C,TPR和FPR不变的),比如负样本*10的话 : FPR = (FP*10)/(N*10),不变的。
再看看precision和recall就不行了,因为一个表格里是竖行,一个是横行。
precision=tp/(tp+fp), recall=tp/(tp+fn)
负样本*10的话 :
precision=tp/(tp+fp*10), recall=tp/(tp+fn)


具体代码实现
求一个个小的梯形的面积。

搞到一个scoreKDD.py的代码
转载自:http://blog.csdn.net/dinosoft/article/details/43114935

















 1518
1518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









