







概述
使用Lex和Yacc构造编译器过程如下图所示:
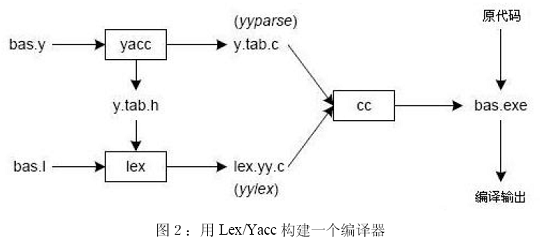 Yacc 读入bas.y 中的语法描述而后生成一个剖析器,即y.tab.c 中的函数 yyparse。b as.y 中包含的是一系列的标记声明。Lex 读入bas.l 中的正则表达式的说明,包含文件 y.tab.h,然后生成词汇解释器,即文件lex.yy.c 中的函数yylex。
Yacc 读入bas.y 中的语法描述而后生成一个剖析器,即y.tab.c 中的函数 yyparse。b as.y 中包含的是一系列的标记声明。Lex 读入bas.l 中的正则表达式的说明,包含文件 y.tab.h,然后生成词汇解释器,即文件lex.yy.c 中的函数yylex。
最终,这个解释器和剖析器被连接到一起,而组成一个可执行程序,bas.exe。我们从main 函数中调用yyparse 来运行这个编译器。函数yyparse 自动调用yylex 以便获取每一个标志。
Lex
在第一阶段,编译器读入源代码然后把字符串转换成对应的标记。使用正则表达式,我们可以为Lex设计特定的表达式以便从输入代码中扫描和匹配字符串。在Lex上每一个字符串对应一个动作。通常一个动作返回一个代表被匹配的字符串的标记给后面的剖析器使用。
每一个正则表达式代表一个有限状态自动机 (FSA)。 我们可以用状态和状态之间的转换来代表一个FSA 。其中包括一个开始状态以及一个或多个结束状态或接受状态。
lex 把正则表达式翻译成模拟FSA 的一个计算机程序。通过搜索计算机生成的状态表,很容易使用下一个输入字符和当前状态来判定下一个状态。
Lex使用后缀名l的文件,文件结构如下:
... 定义 ...
%%
... 规则 ...
%%
... 子程序 ...
定义段由替代式,C代码,和开始状态构成。
定义段中的C代码被简单地原样复制到生成的C文件的顶部,而且必须用%{和%}括起来。
替代式简化了正则表达式规则。例如,可以按如下方式定义数字和字母:
digit [0-9]
letter [A-Za-z]
替代式中定义的在规则段中使用时需要添加花括号{},如{letter}。
规则段指定正则表达式已经对配置的这个表达式所做的处理。
子程序端中定义代码会直接拷贝到目标源文件中去。
Lex中使用的模式匹配的正则表达式的符号表
| 表意字符 | 匹配字符 |
| . | 除换行外的所有字符 |
| /n | 换行 |
| * | 0次或无限次重复前面的表达式 |
| + | 1次或更多次重复前面的表达式 |
| ? | 0次或1次出现前面的表达式 |
| ^ | 行的开始 |
| $ | 行的结尾 |
| a|b | a或者b |
| (ab)+ | 1次或玩多次重复ab |
| "a+b" | 字符串a+b本身(C中的特殊字符仍然有效) |
| [] | 字符类 |
正则表达式举例:
| 表达式 | 匹配字符 |
| abc | abc |
| abc* | ab abc abcc abccc ... |
| abc+ | abc abcc abccc ... |
| a(bc)+ | abc abcbc abcbcbc ... |
| a(bc)? | a abc |
| [abc] | a,b,c中的一个 |
| [a-z] | 从a到z中的任意字符 |
| [a/-z] | a,-,z中的一个 |
| [-az] | -,a,z中的一个 |
| [AZaz09]+ | 一个或更多个字母或数字 |
| [ /t/n]+ | 空白区 |
| [^ab] | 除a,b 外的任意字符 |
| [a^b] | a, ^, b 中的一个 |
| [a|b] | a, |, b 中的一个 |
| a|b | a, b 中的一个 |
方括号中只保留两个操作,连字号(“-”)和抑扬号(“ ^” ) 。当把连字号用于两个字符中间时,表示字符的范围。当把抑扬号用在开始位置时,表示对后面的表达式取反。Lex中如果两个范式匹配相同的字符串,就会使用匹配长度最长的范式。如果两者匹配的长度相同,就会选用第一个列出的范式。
在lex中预定义的变量及其功能如下表所示:
| 名称 | 功能 |
| int yylex(void) | 调用扫描器,返回标记 |
| char *yytext | 指针,指向所匹配的字符串 |
| yyleng | 所匹配的字符串的长度 |
| yylval | 与标记相对应的值 |
| int yywrap(void) | 约束,如果返回1 表示扫描完成后程序就结束了,否则返回 0 |
| FILE *yyout | 输出文件 |
| FILE *yyin | 输入文件 |
| INITIAL | 初始化开始环境 |
| BEGIN | 按条件转换开始环境 |
| ECHO | 输出所匹配的字符串 |
其中ECHO宏是这么定义的:
#define ECHO fwrite(yytext, yyleng, 1, yyout)
变量yyout是输出文件,默认状态下是stdout。当lex读完输入文件之后就会调用函数yywrap。如果返回1 表示程序的工作已经完成了,否则返回0。
下面是一个扫描器,用于计算一个文件中的字符数,单词数和行数(类似Unix 中的wc 程序):
%{
int nchar, nword, nline;
%}
%%
/n { nline++; nchar++; }
[^ /t/n]+ { nword++, nchar += yyleng; }
. { nchar++; }
%%
int main(void) {
yylex();
printf("%d/t%d/t%d/n", nchar, nword, nline);
return 0;
}
使用Parser Generator2.07来完成生成工作,使用向导新建只有Alex的工程,注意Target Language的选择,上述例子使用了的是C;[Project]->[Rebuild All]就生成了此法分析的C源代码wc.c和wc.h文件;新建VC++工程,按照下述步骤配置环境
1.目录设置
在VC++中执行以下步骤,每个步骤只执行一次。
(1) 选择Tools菜单中的Options命令,在屏幕上即会出现Options对话框。
(2) 选择Directories选项卡。
(3) 在Show Directories for下拉列表框中选择Include Files。
(4) 在Directories框中,点击最后的空目录,并填入Parser Generator的include子目录的路径。
(5) 在Show Directories for下拉列表框中选择Library Files。
(6) 在Directories框中,点击最后的空目录,并填入Parser Generator的lib/msdev子目录的路径。
(7) 在Show Directories for下拉列表框中选择Source Files。
(8) 在Directories框中,点击最后的空目录,并填入Parser Generator的Source子目录的路径。
(9) 点击OK按钮,Options对话框将接受设置并关闭。
VC++在就可以找到包含文件yacc.h和lex.h以及YACC和Lex的库文件。
2.项目设置
对于每个VC++项目,都需在VC++中执行以下步骤:
(1) 选择Project菜单中的Settings命令,在屏幕上即会出现Project Settings对话框。
(2) 在Settings for下拉列表框中选择Win32 Debug。
(3) 选择C/C++标签。
(4) 在Category下拉列表框中选择General。
(5) 在Preprocessor Definitions框中,在当前文本的最后,输入YYDEBUG。
(6) 选择Link标签。
(7) 在Category下拉列表框中选择General。
(8) 在Object/Library Modules框中,在当前文本的后面,输入yld.lib ylmtd.lib ylmtrd.lib ylmtrid.lib。
(9) 在Settings for下拉列表框中选择Win32 Release。
(10) 重复第8步的工作,但是*.lib文件选择Release版的,及不带d的。
(11) 点击OK按钮,Project Settings对话框将接受设置并关闭。
配置完后编译,运行就可。














 8272
8272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









