







文章目录
1 scikit-learn
导航页与算法指南
API:数据预处理Preprocessing and Normalization,特征抽取Feature Extraction,特征选择Feature Selection,各种模型:Generalized linear models (GLM) for regression、Naive Bayes,Support Vector Machines、Decision Trees、Clustering,模型调优与超参数选择:Model Selection,模型融合与增强Ensemble Methods,模型评估Metrics
2 一个项目实战
2.1 项目目标
利用加州普查数据,建立一个加州房价模型。数据包含:每个街区人口、收入中位数、房价中位数等指标。
我们要建一个模型对数据进行学习,根据其他指标预测任何街区的房价中位数。
2.2 划定问题
问老板的第一个问题是:商业目标是什么。
建立模型不是最终目标,公司会如何使用模型,并从模型中如何受益。老板可能会告诉你你的模型输出会传给另外一个系统。
下一个问题是:现有的方案效果如何。
开始设计系统。是监督学习、非监督学习还是强化学习?是分类还是回归?
这是一个监督学习的问题,我们使用的是有标签(房价中位数)的训练样本数据。这是一个回归类问题。要预测的是一个数值。
2.3 选择性能指标
回归类问题一般选择均方根误差(RMSE)作为性能指标。
2.4 核实假设
跟下游沟通确定需要的值是什么:数值还是分类。
2.5 获取数据
- 下载数据
查看数据结构
housing.head()
housing.info()
housing.describe()
housing[“ocean_proximity”].value_counts()
housing.hist(bins=50, figsize=(20,15))
- 查看数据描述
重点看数据量、每个属性的类型和非空值的数量。查看数据是不是被截断了。
- 创建测试集
如果每次都重新采集测试集,效果很不稳定。可以把测试集保存下来,或者设置随机数生成种子,每次产生相同的测试集。
此外还有一点需要注意的是:如果测试集随机抽取数据可能不具有代表性。例如在本例中,测试集有可能涵盖不到高收入群体。我们需要按照原始数据集中收入中位数的分布分层抽样数据。可以使用StratifiedShuffleSplit实现。split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
# Divide by 1.5 to limit the number of income categories
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
# Label those above 5 as 5
housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)
from sklearn.model_selection import StratifiedShuffleSplit
# 提供分层抽样功能,确保每个标签对应的样本的比例
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
strat_test_set["income_cat"].value_counts() / len(strat_test_set)
housing["income_cat"].value_counts() / len(housing)
for set_ in (strat_train_set, strat_test_set):
set_.drop("income_cat", axis=1, inplace=True)
会发现测试集和原数据集中的income_cat分布是一致的。
2.6 数据探索和可视化、发现规律
对要处理的数据,要有整体了解。
首先测试集放在一边,不做了解。训练集如果很大可以在采样一个探索集。
第二,地理数据可视化
第三,查找关联
使用pandas提供的corr_matrix = housing.corr()方法查看关联性。
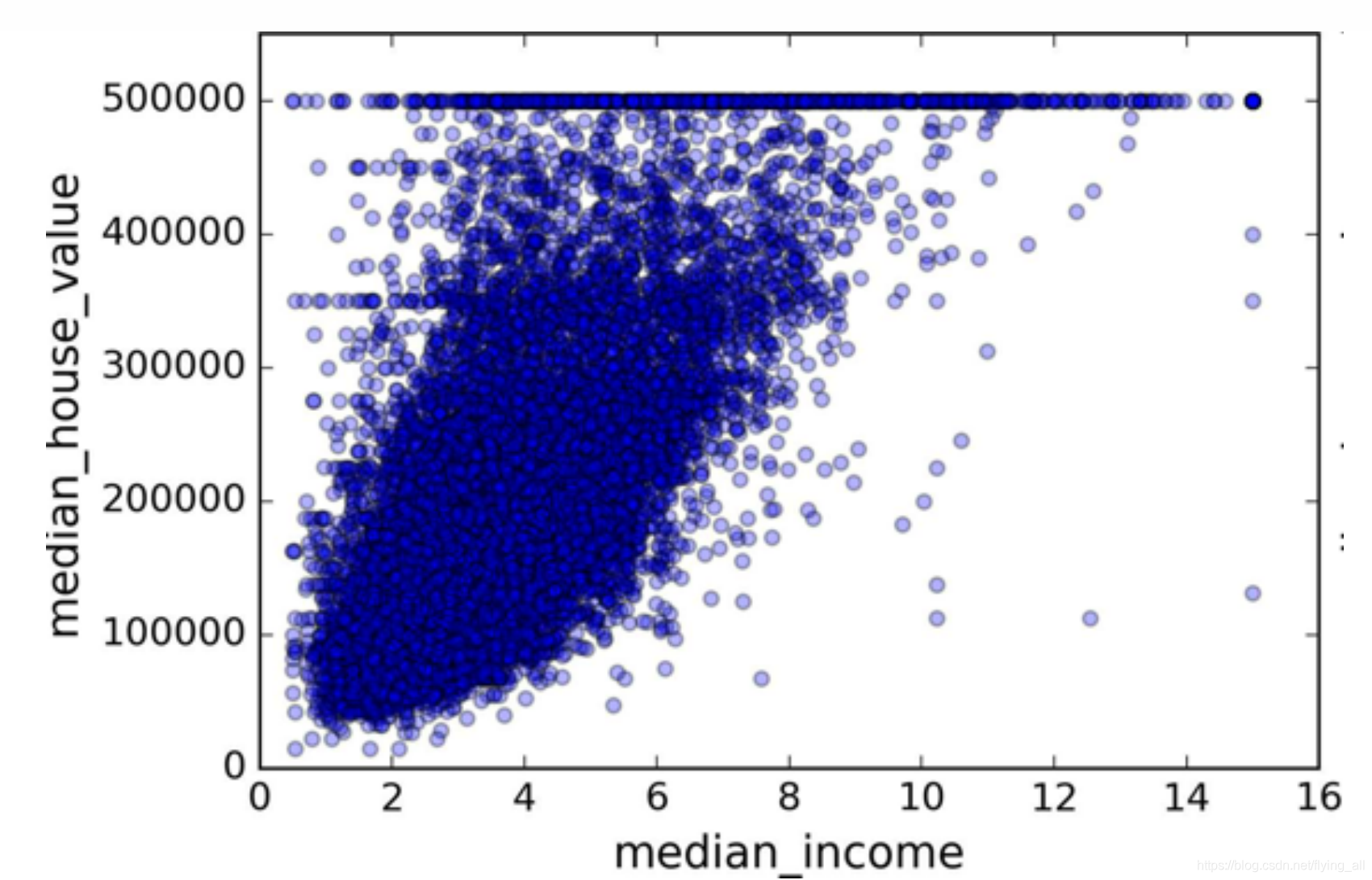
收入中位数与房价中位数关联度比较高。分析后发现,在500000,480000,350000等一些水平线会有明显的呈一条直线。可能需要去掉这些街区的数据,以防止算法重复这些巧合。
第四,属性组合试验
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
属性组合是打开脑洞的时间。可以尝试每户有几个房间,每个房间有几个卧室,每户人口数。
2.7 为机器学习算法准备数据
1 要写一些函数来做事情
这些函数可以让你重复利用。
2 数据清洗
如果数据数据缺失有三种处理方式:1 去掉数值缺失的那些数据(按行),2 去掉整个属性(按列),3 进行赋值(0,平均值、中位数等等)
3 处理文本和类别属性
处理文本属性:先将文本属性转为数值属性,接着使用one-hot编码:OrdinalEncoder、OneHotEncoder,也可以使用LabelBinarizer一步到位。
4 自定义转换器
继承BaseEstimator, TransformerMixin。
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room = True): # no *args or **kargs
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X, y=None):
rooms_per_household = X[:, rooms_ix] / X[:, household_ix]
population_per_household = X[:, population_ix] / X[:, household_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
5 特征缩放
通常我们不对目标值进行缩放。这里就是房价中位数,不缩放。
特征缩放针对的是训练集数据,在测试集,以及预测过程中需要做同样的操作。
有两种缩放方式:归一化和标准化。
归一化的操作是:
x
=
x
−
m
i
n
m
a
x
−
m
i
n
x=\dfrac{x-min}{max-min}
x=max−minx−min,值的范围是(0,1)。但是受异常值影响大。API:MinmaxScaler
标准化的操作是:
x
=
x
−
m
e
a
n
方
差
x=\dfrac{x-mean}{方差}
x=方差x−mean,值没有范围,受异常值影响小。API:StandardScaler。
6 转换流水线
from sklearn.base import BaseEstimator, TransformerMixin
# Create a class to select numerical or categorical columns
# since Scikit-Learn doesn't handle DataFrames yet
class DataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names = attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_names].values
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
num_pipeline = Pipeline([
('selector', DataFrameSelector(num_attribs)),
('imputer', Imputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
cat_pipeline = Pipeline([
('selector', DataFrameSelector(cat_attribs)),
('cat_encoder', OneHotEncoder(sparse=False)),
])
from sklearn.pipeline import FeatureUnion
full_pipeline = FeatureUnion(transformer_list=[
("num_pipeline", num_pipeline),
("cat_pipeline", cat_pipeline),
])
housing_prepared = full_pipeline.fit_transform(housing)















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









