







2014年,大数据开始成为热词,在神州大地的各大媒体,论坛,会议上出现。如果有人恰好在你身边谈论大数据,而你又一脸懵圈的只能应和着说,我同意,我赞成,我也是这么想的,那是怎一个囧字了得啊。而今,滚滚长江东逝水,一代新人胜旧人,人工智能站出来说:数风流人物还看今朝。好吧,亲,老司机带您上路,从此告别懵圈的稚嫩面庞,开始拉风的装X人生。
什么是人工智能,估计这对很多人来说,简直就是最熟悉的陌生人。终结者式的机器人肯定是吧!没错。我家的扫地机器人也算吧!没错,还有呢?  ….
….
凯文凯利在《必然》这本书里说,在他还too young too navie的时候问google的创始人,雅虎也做搜索,很多公司都做搜索,你们也做搜索,有什么特别的竞争优势呢? google创始人微微一笑,答,其实我们是做人工智能的。没错,google和百度的搜索引擎里大量的使用了人工智能的技术,为的是能够根据你输入的词句来为你找到最好的搜索结果。所以看似不相关的搜索引擎也属于人工智能。接下来小编不为你描述抽象的定义,小编为你列举一些常见的应用来告诉你,其实人工智能已经占据了我们生活的方方面面。
搜狗输入法在你输入拼音之后为你列出最有可能的汉字,淘宝为你推荐你喜欢的商品导致你家到处都堆积着无用之物,京东的当日送达让你惊讶这样都行,打开优酷,满屏都是你喜欢的节目,打开每日头条,全是你爱看的新闻, word可以校正你输入的错误英语,QQ邮箱自动帮你过滤垃圾邮件等等等等。这些应用的背后都或多或少的采用了人工智能的技术。还有百度的人脸识别,微软的小冰,google的无人驾驶,苹果的Siri语音助手,亚马逊的Echo音箱。这个世界其实已经被人工智能包围。你是否还在将信将疑,小编你到底懂不懂,你说的是真的吗?凭什么这样说啊。亲,老司机挥泪告诉您,真的没骗您,这些都是人工智能,只不过属于弱人工智能的范畴。
人工智能有三个层次,弱人工智能,强人工智能,超人工智能。目前纵观全人类,所达到的基本都是弱人工智能。因为强人工智能的定义是拥有自我意识,超人工智能客官可以自由发挥想象。
我们现在回到现实中,继续弱人工智能之旅。以上所说的种种常见的应用,背后的原理都可以归结为概率统计。京东统计一下你最近常浏览哪些网页,提前把你浏览的东西运到你家附近的仓储中心,OK,万事俱备,就等你上钩了。淘宝统计一下你最近经常看什么商品,然后为你推荐相似的商品,亲,心动不?优酷统计一下你最近看过哪些节目,为你展示相关的视频列表。输入法统计大量文章中的汉字热词组合,预测你输入的拼音和哪些常用字词的组合最相近。百度google将用户点击作为一项重要的数据来衡量网页的排名,找到搜索词最相关的网页,下次搜索相同的东西时,最好的网页就列在前面了。
是不是很简单?很多人可能又要说了,哪有你说的这么简单啊,这样岂不是所有人都可以做了? 小编弱弱的告诉你,其实就是这样,小编没有撒谎 。当然,这些具体的实现背后涉及大量的算法模型和数据挖掘知识,但基本原理其实就是这样,只不过大家都是在寻找更精确的统计预测方法,从大量看似无用的数据中,分离出有用的信息,透过现象探寻事物的本质。
。当然,这些具体的实现背后涉及大量的算法模型和数据挖掘知识,但基本原理其实就是这样,只不过大家都是在寻找更精确的统计预测方法,从大量看似无用的数据中,分离出有用的信息,透过现象探寻事物的本质。
你可能常听到一个高大上的词汇:机器学习(Machine Learning)。机器学习中的各种算法:回归分析,朴素贝叶斯,马尔可夫链,支持向量机,神经网络,深度学习(DeepLearning)等都是在做类似统计分析的事情。从纷繁杂乱的数据中,寻找出影响结果的关键因素。
说到这,数据的重要性有没有在客官心中留下深深的烙印?以上列举的这些杀手级应用的一个关键就是有没有可以使用的数据供人工智能的算法来分析。那什么是数据呢?什么样的数据才可以拿来使用呢?在互联网上,你的浏览记录,链接点击次数,论坛的灌水留言,视频的弹幕,大V的牢骚,GPS的定位,游戏的历史记录,支付宝的消费记录等等这些都是可以使用的数据。
这么多看似杂乱的数据,对于普通人来说毫无用处,但对于数据公司来说,那可是宝贝啊。他们可以从中窥探出舆论的走向,经济的发展形式,股票的前景,你的信用如何,你的喜好是什么等等等等,然后大把大把的赚钱。君不见阿里为何收购新浪,facebook最值钱的是什么?这个时代,数据就像未开采的金矿,使得淘金的人们蜂拥而至。安卓应用在安装时第一条就是,我会访问你的联系人列表,查看你的GPS定位,你同意吗?你不同意能怎么着,不同意就拜拜,爷不伺候了。Google地图为什么连你们村那通幽的小径都能知道,因为你拿着开启了GPS的手机从那走过啊! 聪明的小编早就看穿了一切。
聪明的小编早就看穿了一切。
你可能还会问:小编,你说的这些真的是人工智能吗?我还是觉得你说的太随意太简单了! 其实这些很多今天看似so easy的事情在互联网没有流行之前基本没法做。没有数据,怎么统计,再高大上的算法没法解决没有数据的寂寞。当然了,如果你很有钱(小编正好相反),组织五毛党发小礼品进行问卷调查也可以,但这样做浪费人力物力不说,调查的结果也不一定准确。因为即使小编爱看我是非诚勿扰,但小编肯定一脸严肃的告诉你,新闻联播才是我的最爱
其实这些很多今天看似so easy的事情在互联网没有流行之前基本没法做。没有数据,怎么统计,再高大上的算法没法解决没有数据的寂寞。当然了,如果你很有钱(小编正好相反),组织五毛党发小礼品进行问卷调查也可以,但这样做浪费人力物力不说,调查的结果也不一定准确。因为即使小编爱看我是非诚勿扰,但小编肯定一脸严肃的告诉你,新闻联播才是我的最爱 。所以,这样的问卷统计结果只会把你往沟里带。我这样的老司机是不会的。好了,说了这么多,一直在说人工智能简单,小编要不拿出点实力,估计很多人要向我扔鞋了
。所以,这样的问卷统计结果只会把你往沟里带。我这样的老司机是不会的。好了,说了这么多,一直在说人工智能简单,小编要不拿出点实力,估计很多人要向我扔鞋了 。下面带你进入轻度烧脑模式。
。下面带你进入轻度烧脑模式。
以上介绍的都是基本的原理知识,高级的应用实现其实路漫漫其修远兮,但是不要怕,老司机为你带路。设想一下,你是一个大boss,你有大把大把的历史销售数据,那你就可以用Excel统计出什么产品好卖,几月份热销。再设想下,你是一个围棋高手,我给你数十万盘的围棋游戏的记录数据,你能拿来做什么呢?你能用Excel从中找出什么有用的信息? 但Alpha狗嗅出来了。2016年,AlphaGo战胜韩国围棋世界冠军,职业九段选手李世石,成为这一轮人工智能爆发的舆论导火索。这一标志性的事件使得大众突然意识到,原来人工智能这么强悍
但Alpha狗嗅出来了。2016年,AlphaGo战胜韩国围棋世界冠军,职业九段选手李世石,成为这一轮人工智能爆发的舆论导火索。这一标志性的事件使得大众突然意识到,原来人工智能这么强悍 。但也有人质疑,切,早在1997年IBM的深蓝战胜国际象棋高手卡斯帕罗夫,怎么就没这么轰动呢,也没见当时有多少人去抱人工智能的大腿嘛。
。但也有人质疑,切,早在1997年IBM的深蓝战胜国际象棋高手卡斯帕罗夫,怎么就没这么轰动呢,也没见当时有多少人去抱人工智能的大腿嘛。
 老司机来告诉你why。深蓝取胜和AlphaGo取胜,其背后的原理有本质的区别。严格的说深蓝不属于人工智能,虽然看似很智能。深蓝采用的策略是利用强大的计算能力,穷举所有可能的下棋套路,在一秒钟内模拟千万次的走棋结果,这些走棋的套路,都是事先由IBM的攻城狮人为定义好的,所以深蓝是胜在计算能力上,和智能其实不怎么沾边,它是在秀肌肉,不是在秀大脑。试问有多少领域可以事先人为定义好套路让超级计算机去模拟所有的情况呢?所以深蓝的技术对其它领域的推广没有多少实际的意义。而AlphaGo却是不同的实现方式,没有人事先为AlphaGo定义围棋的下棋套路,Google的攻城狮只为AlphaGo编写了一个深度学习的算法,然后把数十万盘的围棋游戏记录喂给AlphaGo,然后AlphaGo就会下围棋了,神奇不?再然后工程师每天重复喂它个千八百万次,它就越来越厉害,然后的然后,李世石就输了。而且AlphaGo在和李世石对弈时只使用了几十台Google的普通服务器。(这里要注意一下,这里是说的是对弈时只使用了几十台服务器,之前每天喂狗时是使用上万台服务器进行训练的), 而且深度学习的算法并不是专为围棋而设计,它是一个通用的算法,很多领域,很多行业的数据都可以拿来喂这只狗,喂它什么数据它就是什么狗,忠诚可靠啊。读到这里,是不是有点云里雾里的感觉。这么神奇?没错,就是这么神奇。深度学习的神经网络算法还可以应用到机器翻译,图像识别,语音识别,搜索引擎的优化,输入法的优化,互联网广告的定向分发,淘宝的推荐,互联网金融的信用认证等等等等,而且就目前的行业发展来看,在引入了深度学习算法之后,以前棘手的难题就会有质的突破。
老司机来告诉你why。深蓝取胜和AlphaGo取胜,其背后的原理有本质的区别。严格的说深蓝不属于人工智能,虽然看似很智能。深蓝采用的策略是利用强大的计算能力,穷举所有可能的下棋套路,在一秒钟内模拟千万次的走棋结果,这些走棋的套路,都是事先由IBM的攻城狮人为定义好的,所以深蓝是胜在计算能力上,和智能其实不怎么沾边,它是在秀肌肉,不是在秀大脑。试问有多少领域可以事先人为定义好套路让超级计算机去模拟所有的情况呢?所以深蓝的技术对其它领域的推广没有多少实际的意义。而AlphaGo却是不同的实现方式,没有人事先为AlphaGo定义围棋的下棋套路,Google的攻城狮只为AlphaGo编写了一个深度学习的算法,然后把数十万盘的围棋游戏记录喂给AlphaGo,然后AlphaGo就会下围棋了,神奇不?再然后工程师每天重复喂它个千八百万次,它就越来越厉害,然后的然后,李世石就输了。而且AlphaGo在和李世石对弈时只使用了几十台Google的普通服务器。(这里要注意一下,这里是说的是对弈时只使用了几十台服务器,之前每天喂狗时是使用上万台服务器进行训练的), 而且深度学习的算法并不是专为围棋而设计,它是一个通用的算法,很多领域,很多行业的数据都可以拿来喂这只狗,喂它什么数据它就是什么狗,忠诚可靠啊。读到这里,是不是有点云里雾里的感觉。这么神奇?没错,就是这么神奇。深度学习的神经网络算法还可以应用到机器翻译,图像识别,语音识别,搜索引擎的优化,输入法的优化,互联网广告的定向分发,淘宝的推荐,互联网金融的信用认证等等等等,而且就目前的行业发展来看,在引入了深度学习算法之后,以前棘手的难题就会有质的突破。
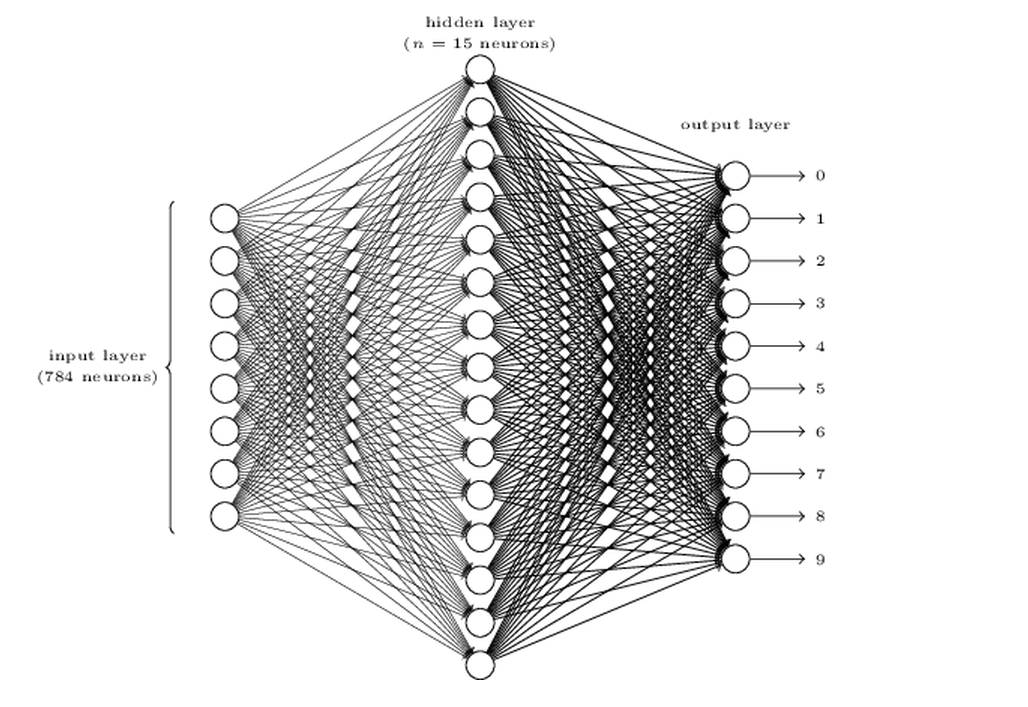
图 1 . 这张图是一个识别手写数字的神经网络,只有三层(输入层,隐藏层,输出层),输入层是784个神经元,因为输入层的神经元较多,所以图中省略了部分,其它层没有任何省略。之所以输入层是784个神经元,是因为输入的手写数字图片是28×28的灰度图片,总共有784个像素,因为是灰度图片,每个像素只有一个整数值,所以28×28的灰度图片总共是784个整数值,每一个整数值对应到一个输入神经元上作为这个神经网络的输入。
很多人可能对小编以上偶尔提及的算法感到迷惑了,你说的到底是什么算法,是深度学习还是神经网络,如果你是说神经网络,不是早就有了吗?我们图书馆八百年前就有这书了。没错,神经网络早就有了,我说的是深度神经网络。???? 耍我啊? 客官莫生气,小编为你慢慢道来。目前大家所说的算法都是深度学习,但深度学习的前身是神经网络,神经网络的前身是感知机,这都是一点一点演化而来的,正所谓长大后我就成了你。深度学习本质上也是神经网络,之所以叫深度学习是为了重点突出现在所实现的神经网络的深度和以往所说的神经网络在深度上有很大的区别,以前的神经网络使用单一的反向传播的训练方式,而且由于以前硬件计算能力的限制,顶多训练两三层就已经是极限了(这里不是说反向传播的训练算法不好,只能说不完善),而深度学习算法在训练上使用稍微不同的方式,使得神经网络的层数可以达到很多很多层(我只能说很多层,因为随着计算节点的增加,神经网络的层数也可以增加),这是在2006年取得的突破,由Geoffrey Hinton提出可以使用一种被称为贪婪逐层预训练的方式来有效的训练多层神经网络(简单的说就是先使用大量无标签的数据对层数很深的神经网络进行热身,把这个神经网络的参数先训练出一些粗糙的数值,虽然此时这些参数值还不太正确,但没关系,就是这么洒脱----这叫无监督学习,然后再用少量有标签的数据基于反向传播算法进行微调,这时,之前不太正确的参数值在这里被一点点的优化----有监督学习),并且被很多专家验证可行。外加上云计算在计算能力上的助推,以前只存在于书本理论中的神经网络算法,终于以一种崭新的面貌开始进入实际使用了,这就是深度学习算法(Deep Learning)。你在很多文章上有时既看到深度学习,又会同时看到CNN(卷积神经网络),RNN(循环神经网络)。到底说的什么,这要取决于你从哪个角度来理解。
截至2016年,一个粗略的经验法则是,有监督的深度学习算法在每类给定约5000个标注样本进行训练的情况下,一般能够达到人类可以接受的性能和准确性,当至少有1000万个标注样本的数据集用于训练时,它将达到或超过人类的表现。深度学习算法在机器学习(Machine Learning)领域的算法大家族里已经是傲视群雄。但另外再说一点,我并不是说其它所有的机器学习算法都不如深度学习,重点是选取适合你自己应用的算法才是明智之举。
觉得小编写的如何,感觉好就给小编点个赞吧!小编会继续给自己打鸡血,为您介绍人工智能方面的知识,如果您有感兴趣的话题,请给小编留言。















 1967
1967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









