







索引概述
MYSQL官方对索引的解释How MySQL Uses Indexes
MySQL官方对索引的解释为:索引用于快速查找具有特定列值的行。
8.3.1 How MySQL Uses Indexes
Indexes are used to find rows with specific column values quickly. Without an index,
MySQL must begin with the first row and then read through the entire table to find the relevant rows.
The larger the table, the more this costs. If the table has an index for the columns in question,
MySQL can quickly determine the position to seek to in the middle of the data file without having to look at all the data.
This is much faster than reading every row sequentially.
百度翻译
MySQL如何使用索引
索引用于快速查找具有特定列值的行。在没有索引的情况下,MySQL必须从第一行开始,然后通读整个表以找到相关的行。
数据表越大,花费就越多。如果该表具有用于所讨论的列的索引,MySQL可以快速确定要在数据文件中间查找的位置,而无需查看所有数据。
这比按顺序读取每一行要快得多。
索引(Index)是帮助MySQL高效获取数据的数据结构。
索引是经过了排序了的,可以快速查找数据的'特殊数据结构',它定义在作为查找条件的字段上,它通过存储引擎实现。
索引优缺点
优点:
1.索引可以降低检索时需要扫描的数据量,减少了IO次数。(字典通过偏旁部首或拼音可以直接翻到对应字的页数)
2.索引可以避免服务器排序和使用临时表。
3.索引可以帮助随机IO转为顺序IO.
缺点:
1.索引占用额外的磁盘空间,每个索引都还占据一定的物理空间。
2.索引有创建和维护成本,随着数据量的增加,索引需要投入的成本也就越高。
3.索引影响数据的插入和修改速度。
(试想,新华大字典的检字表里突然需要增加一个7画的字,那7画的这个字就得插入到6画的和8画的字的中间,
此时7画字的详情页码占用了原来8画字的页码,所以8画以后的字,9画,10画,11画...等等大于7画的字的页码都得依次往后挪一挪,
这就是一个巨大的索引维护成本。)
索引类型:
B+Tree、HASH、R TREE、FULL TEXT
索引结构
Mysql的索引使用B树、B+树等数据结构
了解B树和B+树之前需要先了解二叉树、红黑树、平衡树等数据结构.
二叉树,红黑树,B-Tree,B+Tree
stack结构动画演示链接
由下面的动图可以看出Push入栈和Pop出栈都是根据索引角标[01234]去查找的.

二叉树
二叉树动画演示参考链接
二叉树是如何遍历的
由下面的动图可以看出二叉树数据存放时,总是和根节点先做比较,再决定是存放在根节点的左节点还是有节点,就像二分法一样。

当delete二叉树中的数据时,也是会去遍历与之二分出来的数据做比较。

二叉树特点
1.二叉树存在左右子节点缺失的情况;
2.当子节点较长时,需要遍历的时间也就越长;
3.遍历根节点左右两边的子节点时,较长的节点遍历时间长,较短的节点遍历时间短;
4.二叉树不平衡;
红黑树

红黑树特点
1.为了保持平衡,红黑树在不断地交换根节点的位置;
2.根节点是黑色的;
3.从根节点到达根节点的左右子节点的时间是相当的;(老王老师说,时间相当了就说明它性能比较平稳,而二叉树时间有长有短就不稳定)
B-Tree

B+Tree

B+Tree的特点
1.B+Tree的根节点和分支节点不存储数据记录本身,只存放索引相关信息(指针等);
2.B+Tree的数据记录存放在树的叶子节点;
3.B+Tree的高度一般为2~3层,但它却能满足千万级的数据存储;
4.B+Tree的叶子节点之间有链表指针,也就是数据之间相互链接,适合查询范围内的数据;
5.B+Tree索引按顺序存储,每一个叶子节点到根结点的距离是相同的;
索引使用技巧
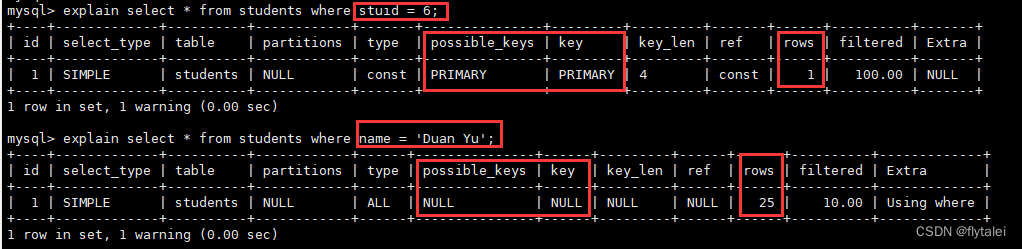
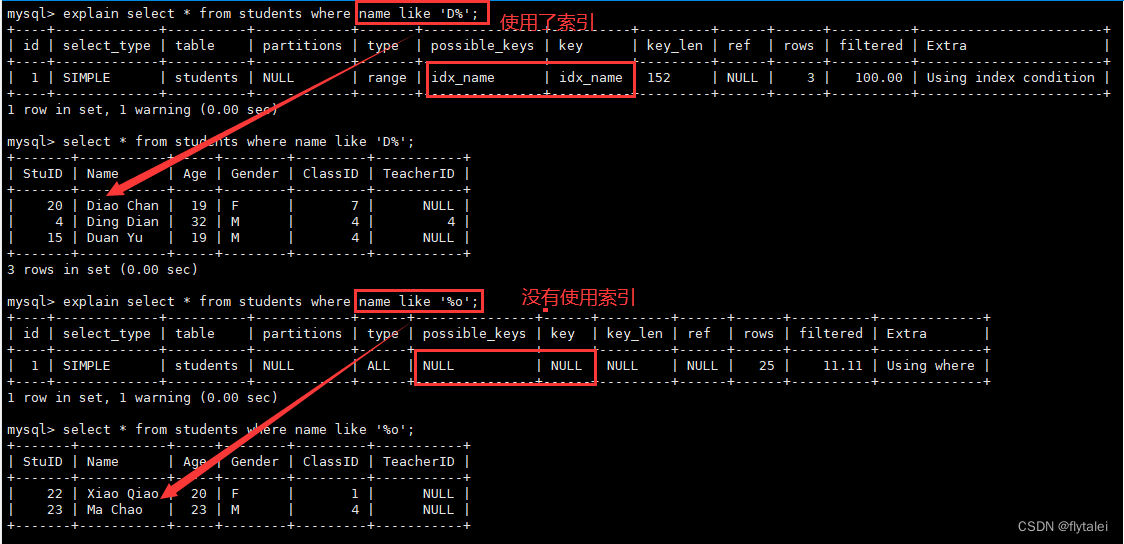
1.创建索引后,并不意味着时时刻刻就能使用索引,索引得配合着查询条件使用;
2.一张学生信息表中,如果是以学生编号建立的索引,但查询条件是学生姓名,这时索引是利用不起来的,因为查询条件和索引没有关系;
3.当学生信息表中建立以学生姓名为索引时,B+Tree是以按照字母'左前缀'的a-z排序的,第一个字母相同则比较第二个字母;
4.当姓名索引以name like '*%'为查询条件时,是可以利用到索引的;
5.当姓名索引以name like '%*%'或者'%*'为查询条件时,是不会使用到索引的;(模糊查询包含和后缀关键字时,索引无效,仍需全盘扫描);
索引优化
1.对于经常在where子句使用的列,最好设置索引;
2.对于有多个列where或者order by 子句,应该建立复合索引;
3.对于like子句的使用,参考上面的索引使用技巧;
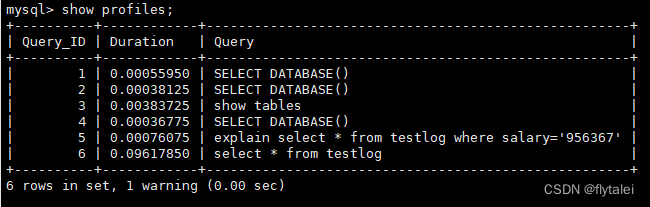
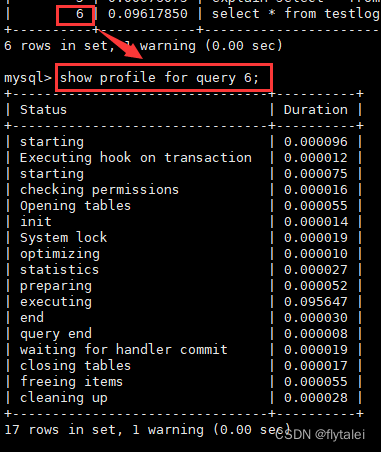
4.多使用explain和profile分析查询语句;
5.查看慢查询日志,找出执行时间长的sql语句优化;
索引管理
查看索引
mysql> show indexes from students\G
*************************** 1. row ***************************
Table: students
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: StuID
Collation: A
Cardinality: 25
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
1 row in set (0.01 sec)
explain 工具
可以通过explain来分析索引的有效性,获取查询执行计划信息,用来查看查询优化器如何执行查询
explan输出信息说明
| 列名 | 说明 |
|---|---|
| id | 执行编号,标识select所属的行。如果在语句中没子查询或关联查询,只有唯一的select,每行都显示1. |
| select_type | 简单查询:simple |
| table | 访问引用哪个表 |
| type | 关联类型或访问类型,即MySQL决定如何去查询表中的行的方式 |
| possible_keys | 查询可能会用到的索引 |
| key | 显示mysql决定采用哪个索引来优化查询 |
| key_len | 显示mysql在索引里使用的字节数 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | 为了找到所需的行而需要读取的行数,预算值,不精确。通过把所有rows列值相乘,可粗略估算整个查询会检查的行数 |
| Extra | 额外信息Using index:MySQL将会使用覆盖索引,以避免访问表 |
创建索引
mysql> create index idx_name on students(name);
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0

profiles工具















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









