







文章目录
黑马阿伟
基本数据结构
数据结构概述
数据结构是计算机底层存储、组织数据的方式,是指数据相互之间以什么样的方式组织排列在一起的。
数据结构是为了更加方便的管理和使用数据,需要结合具体的业务场景来进行选择。
一般情况下,经过精心选择的数据结构可以带来更高效的运行或存储效率。
数据结构的三个核心
1.每种数据结构长什么样子?
2.如何添加数据
3.如果删除数据
栈
栈:先进后出,后进先出
栈的数据结构:
先进后出,后进先出
队列
队列:先进先出,后进后出
队列的数据结构
先进先出,后进后出
数组
数组:内存连续区域,查询快,增删慢
数组数据结构:数组是一种查询快,增删慢的模型
1.查询速度快:查询数据通过地址值和索引定位,查询任意数据耗时相同。(元素在内存中是连续存储的)
2.删除效率低:要将原始数据删除,同时前移后面的每一个数据。
3.添加效率极低:添加位置后的每个数据后移,再添加元素。
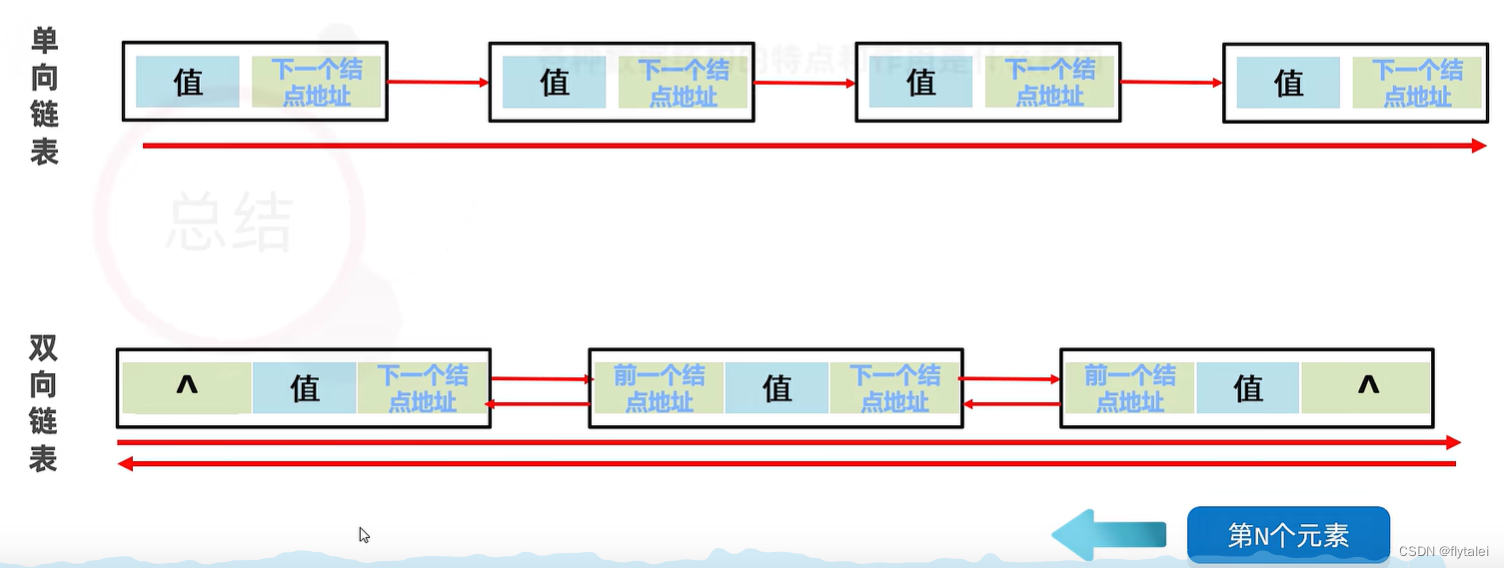
链表
链表:元素是游离的,查询慢,首尾操作极快。
链表数据结构
1.链表中的每个结点都是独立的对象,在内存中是不连续的,每个结点都包含"数据值"和"下一个结点的地址"(单向链表)。
2.链表查询慢,无论查询哪个数据都要从头开始查找。
3.链表增删数据相对较快,且首尾操作极快。
二叉树
二叉树概念
度:每个节点的子节点数量,二叉树中任意节点的度<=2
树高:数的总层数
根节点:最顶层的节点
左子节点:左下方的节点
右子节点:右下方的节点
二叉树的遍历:
前序遍历:根左右
中序遍历:左根右(从小到大的顺序遍历)
后序遍历:左右根
层序遍历:一层一层的遍历
注意:所谓的前中后序指的是"根节点"的位置,根在前是前序,根在中间是中序,根在后面是后序
自平衡二叉树,遵循左小右大原则存放,所以存放时会进行比较。
二叉查找树
二叉查找树又称二叉排序树或者二叉搜索树
1.每一个节点上最多有两个子节点
2.任意节点左子树上的值都小于当前节点
3.任意节点右子树上的值都大于当前节点
二叉查找树添加节点规则:
1.小的存左边
2.大的存右边
3.一样的不存
二叉查找树的弊端:
如果存储的数据一直比根节点小或大,就会导致根节点的左子树或右子树一直增长,从而导致二叉树不平衡。
平衡二叉树
平衡二叉树规则:
1.任意节点左右子树高度差不超过1
平衡二叉树通过旋转规则保持平衡
规则1:左旋
规则2:右旋
旋转规则
1.触发时机:当添加一个元素后,该树不是一个平衡二叉树时
2.确定支点:从添加的节点开始,不断的往父节点找不平衡的节点
红黑树
红黑树增删改查的性能都很好
红黑规则
1.每一个节点或是红色的,或者是黑色的
2.根节点必须是黑色
3.如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的
4.如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
5.对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点
哈希表
哈希表的数据结构
1.哈希表是一种对于增删改查数据性能都较好的数据结构
哈希表组成
1.JDK1.8之前:数组+链表
2.JDK1.8之后:数组+链表+红黑树
为什么要使用泛型
泛型的优点
1.集合中存储的元素类型统一了
2.从集合中取出来的元素类型是泛型指定的类型,不需要进行大量的“向下转型”
泛型的缺点
1.导致集合中存储的元素缺乏多样性。
Collection-单列集合
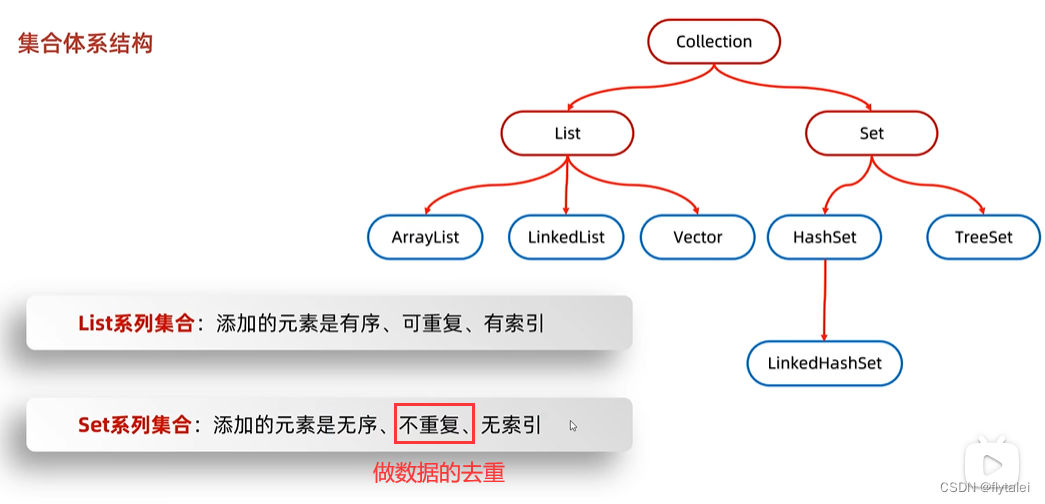
List
ArrayList原理
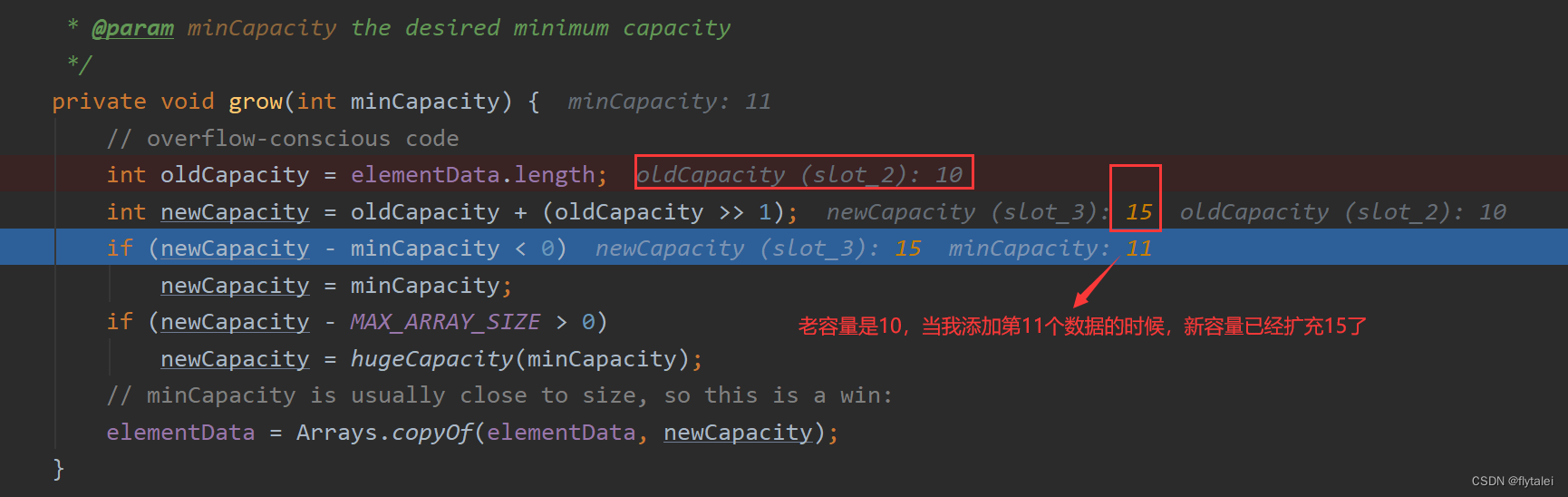
ArrayList集合底层原理
1.利用空参创建的集合,在底层创建一个默认长度为0的数组;
2.当添加第一个元素时,底层才会创建一个新的长度为10的数组;
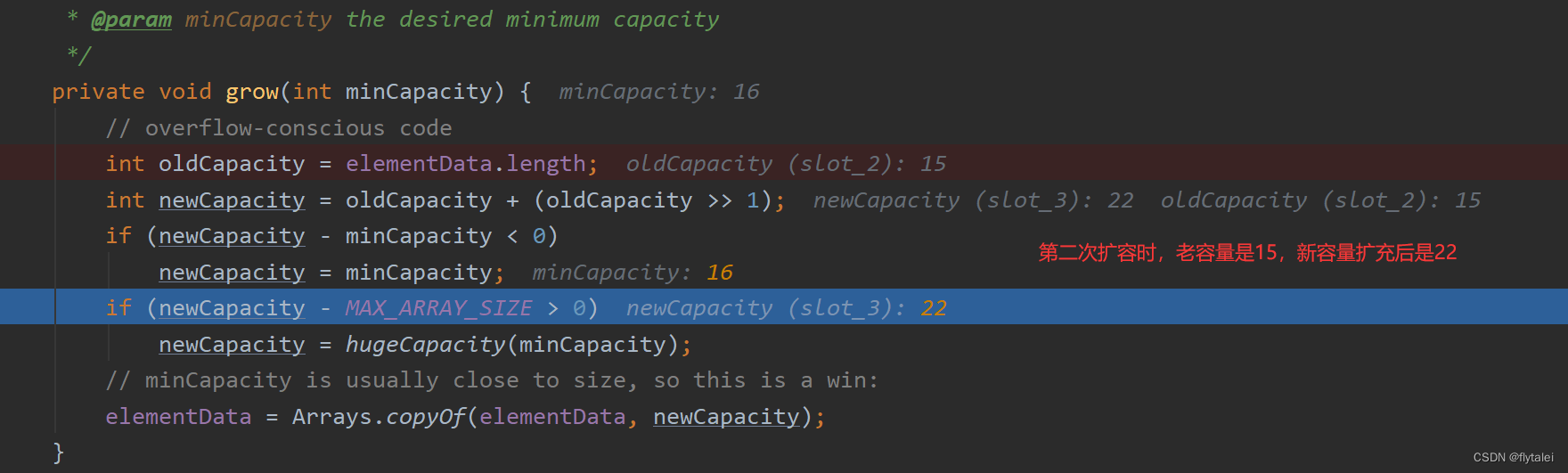
3.当长度为10的数组存满时,数组会自动扩容原来数组的1.5倍;
4.完成扩容之后,把原来的数组元素拷贝到新扩容的数组中;
5.如果一次添加多个元素,1.5倍还放不下,则新创建数组的长度以实际为准;
比如:你一次要新加100个数据,那新数组的长度就为110;
6.建议给定一个预估计长度的初始化容量,减少数组的扩容次数,这是ArrayList集合比较重要的优化策略。
第一次扩容
第二次扩容
数组的扩容消耗性能
1.数组扩容效率较低,因为涉及到拷贝的问题,所以在开发中请注意:尽可能少的进行数组的拷贝。
2.在创建数组对象的时候最好预估一下多长合适,这样可以减少数组的扩容次数,提高效率。
数组的优缺点
数组的优点
1.数组的检索效率比较高。
为什么数组的检索效率高?
数组中每个元素占用空间大小相同,内存地址是连续的,知道首元素内存地址,然后知道下标,
通过数学表达式计算出元素的内存地址,所以检索的效率高。
2.数组向数组末尾添加元素的效率还是很高的,也就是数组的添加效率很高。
数组的缺点
1.数组随机增删元素效率比较低
LinkedList
链表数据结构的特点
链表的优点:
1.由于链表上的元素在空间存储上内存地址不连续,所以随机增删元素的时候不会有大量元素的位移,因此随机增删的效率高。
在以后得开发中,如果遇到随机增删集合中元素的业务比较多时,建议使用LinkedList
链表的缺点
1.不能通过数学表达式计算被查找元素的内存地址,每一次查找都是从头节点开始遍历,直到找到为止,
所以LinkedList集合检索/查找的效率较低。
LinkedList特点
1.LinkedList底层采用了双向链表数据结构
Vecter
Vecter特点
1.Vector底层也采用了数组的数据结构是线程安全的。
2.Vector底层方法都使用了synchronized关键字修饰虽然线程安全但效率不高,一般使用较少了。
Set
Set集合特点
1.无序:存取顺序不一致
2.不重复:可以利用它来去除重复数据
3.无索引:没有索引的方法,所以不能使用普通for循环遍历,也不能通过索引来获取元素
Set集合的实现类
1.HashSet:无序、不重复、无索引
2.LinkedHashSet:有序、不重复、无索引
3.TreeSet:可排序、不重复、无索引
Set集合常用方法
1.public boolean add(E e) 将给定的对象添加到当前集合中,当添加重复数据时会返回false
2.public void clear()
3.boolean remove(E e)
4.public boolean contains(Object ogj)
5.public boolean isEmpty()
6.public int size()
HashSet原理
HashSet特点:
1.HashSet创建时实际上是底层new了一个HashMap集合,也就意味着HashSet是将数据存储到了HashMap集合中了,
HashMap是一个哈希表数据结构;
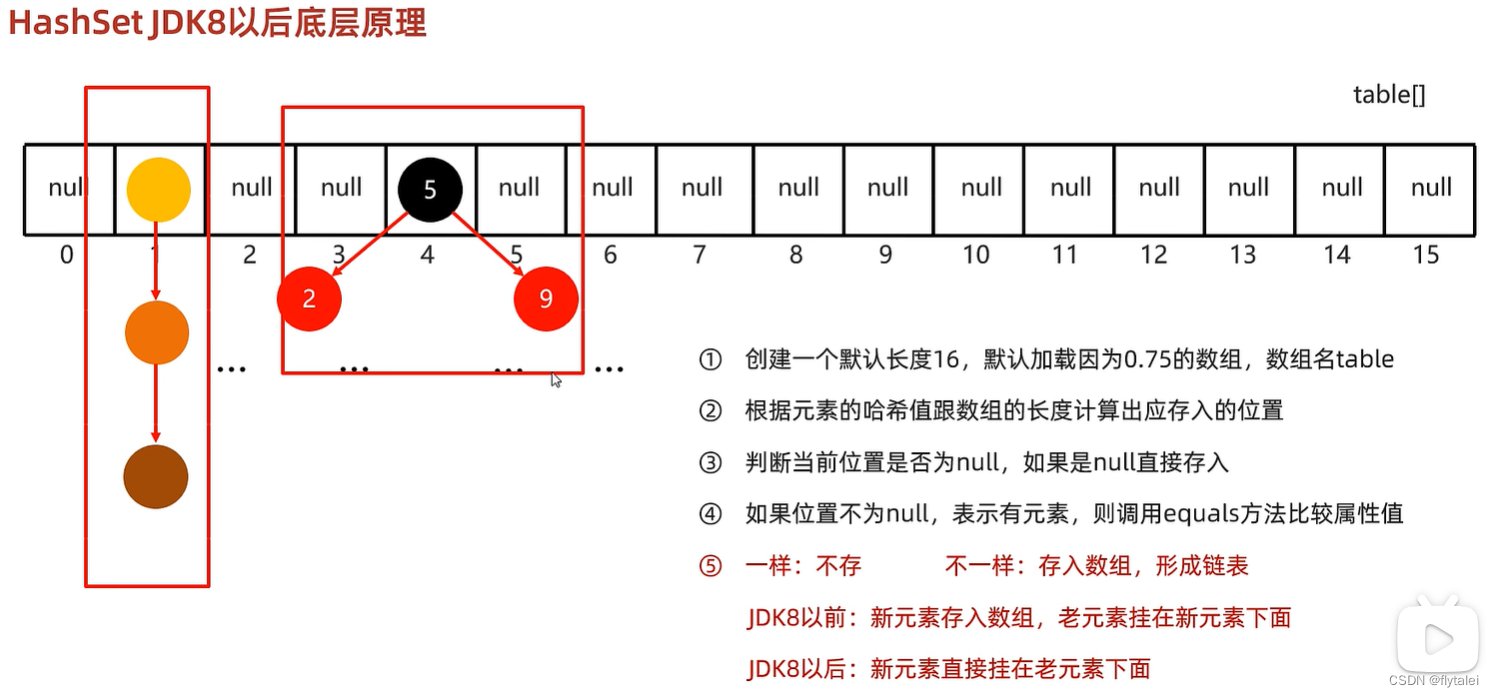
HashSet底层原理
1.初始化时创建一个默认长度为16,默认加载因子为0.75的数组,数组名为table
2.根据元素的哈希值和数组的长度计算出应存入的位置
3.判断当前位置会否为null,如果是null直接存入
4.如果位置不为null,表示有元素,则调用equals方法比较属性值
5.一样:不存;不一样:存入数组,形成链表
JDK8以前:新元素存入数组,老元素改在新元素下面
JDK8以后:新元素直接挂在老元素下面
6.JDK8以后当链表的长度大于8,并且数组长度大于等于64,那当前的链表就会自动转为红黑树
7.如果集合中存储的是自定义对象,必须要重写hashCode和equals方法
如果是String和Integer类型则不需要重新hashCode和equals方法,因为Java已经重写了
HashSet三连问
1.HashSet为什么是无序的?
存的时候是通过哈希算法算出来的存储位置,这个位置并不是连续的;
而取的时候却是挨个去遍历的数组,这个数组又是连续的空间,所以存取顺序不一致。
2.HashSet为什么没有索引
因为HashSet底层使用数组加链表加红黑色的存储方式,它的存储结构不够纯粹,
数组中的每个元素下面可能还挂着链表,链表中又有许多节点,用一个索引去表示这么多的数据显然不合适。所以干脆就去掉了索引。
3.HashSet使用什么机制保证值的唯一性
HashSet使用重写hashCode和equals方法来保证值的唯一性
LinkedHashSet
LinkedHashSet原理
1.有序、不重复、无索引
2.底层基于哈希表,使用双链表记录添加顺序
在以后得开发中如果数据要去重,我们使用哪个?
1.默认使用HashSet
2.如果要求去重且存储有序,才使用LinkedHashSet
TreeSet
TreeSet的父级接口是SortSet,SortSet继承了Set接口,接口是抽象的,无法实例化。
TreeSet的特点
1.可排序,不重复,无索引
2.TreeSet底层基于红黑树实现排序,增删改查的性能都较好
3.无顺不可重复,但存储的元素可以自动按照大小顺序或字幕A~Z排序
4.TreeSet创建的时候,底层new了一个TreeMap,TreeMap底层又使用了红黑树数据结构
TreeSet自定义排序规则有几种方式
方式一:JavaBean类实现Comparable接口,指定比较规则
方式二:创建集合时,自定义Comparator比较器对象,指定比较规则
方法返回值的特点
负数:表示当前要添加的元素是小的,存左边
正数:表示当前要添加的元素是大的,存右边
0:表示当前要添加的元素已经存储,舍弃
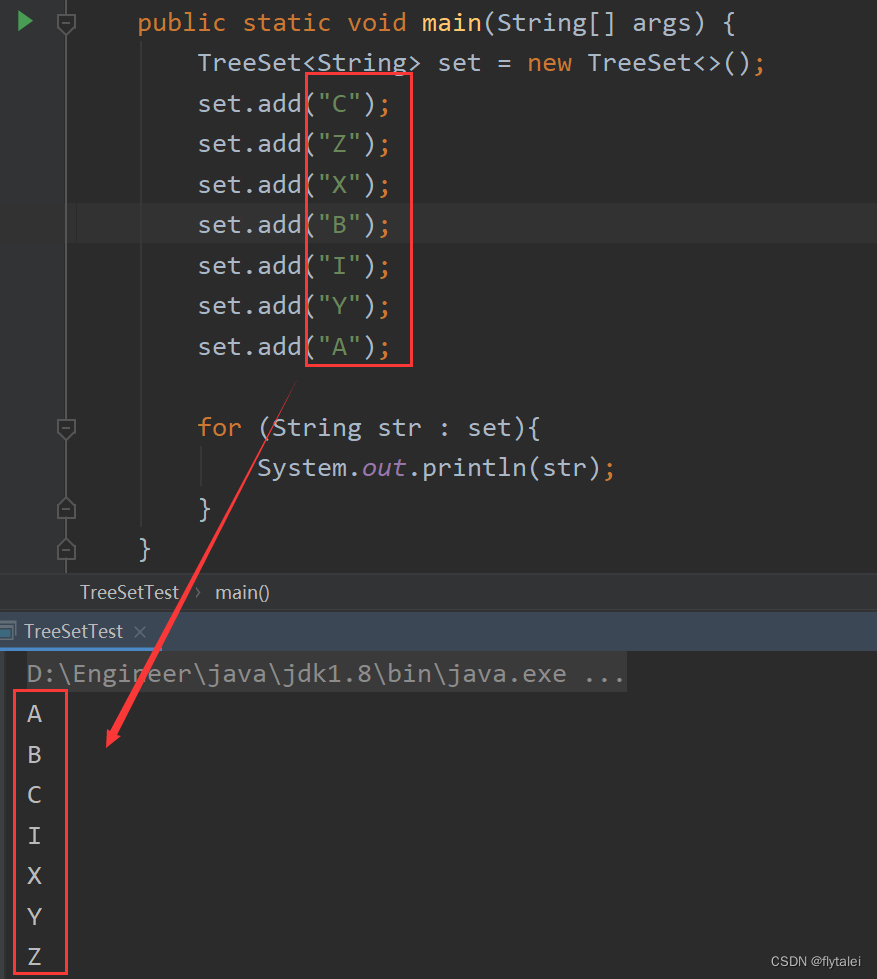
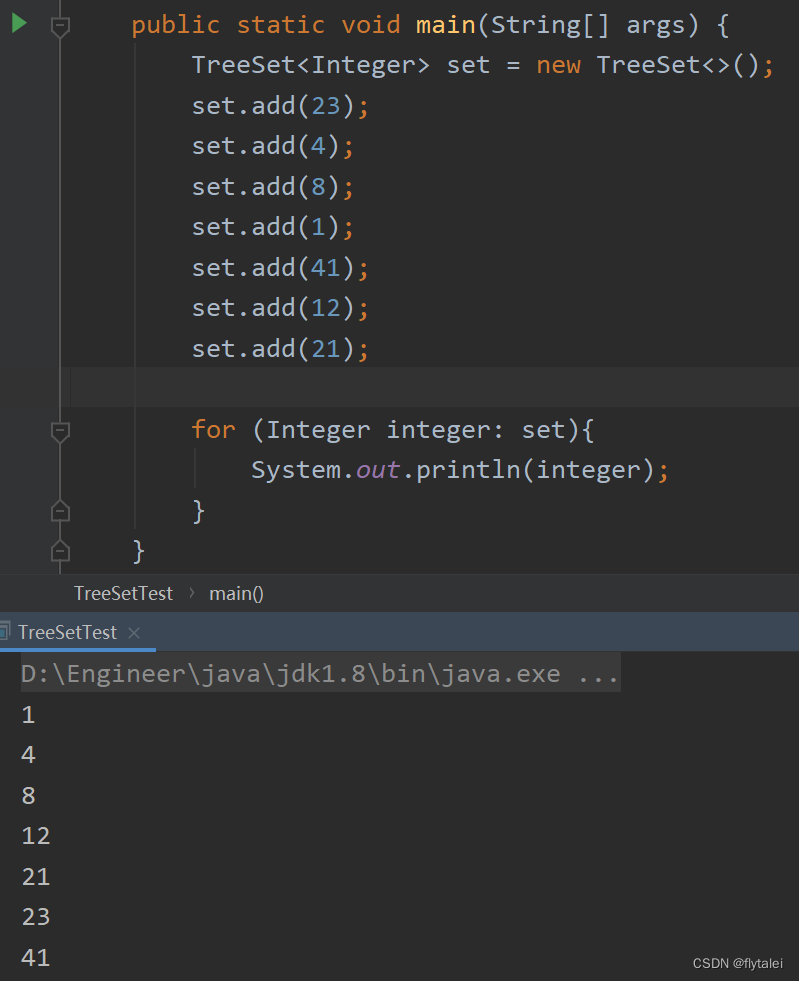
TreeSet两种自定义比较/排序规则
两种方式的使用规则:默认使用第一种,如果第一种不能满足当前需求,就使用第二种
方式一
方式一:
默认排序/自然排序:JavaBean类实现Comparable接口指定比较规则
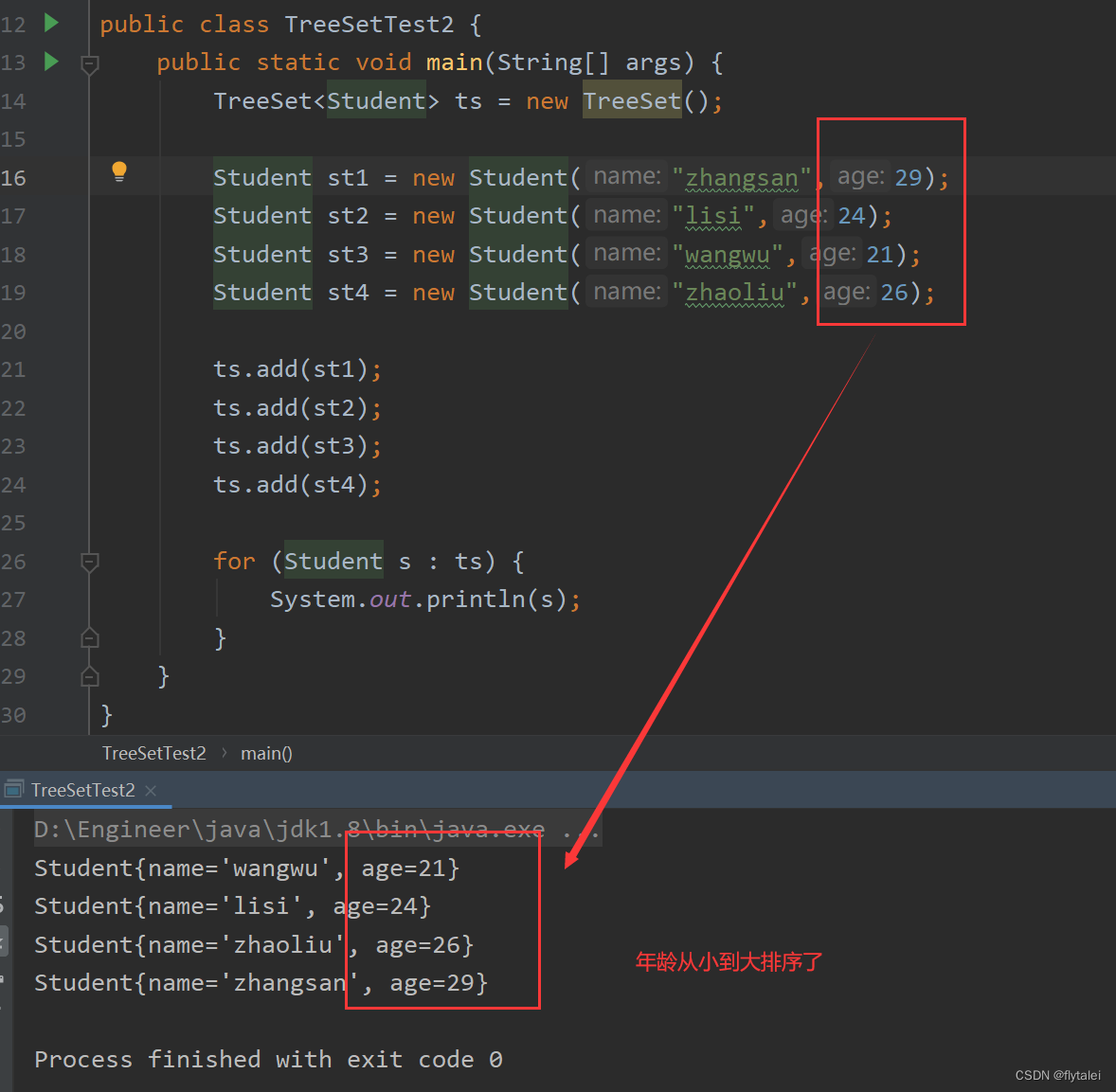
需求将Student类按学生年龄从小到大排序
public class Student implements Comparable<Student>{
private String name;
private int age;
@Override
//this: 表示当前要添加的元素
//0: 表示已经在红黑树中存在的元素
public int compareTo(Student o) {
/**
* 返回值:
* 负数:表示当前要添加的元素是小的,存左边
* 正数:表示当前要添加的元素是大的,存右边
* 0:表示当前哟啊添加的元素已经存储,舍弃
*/
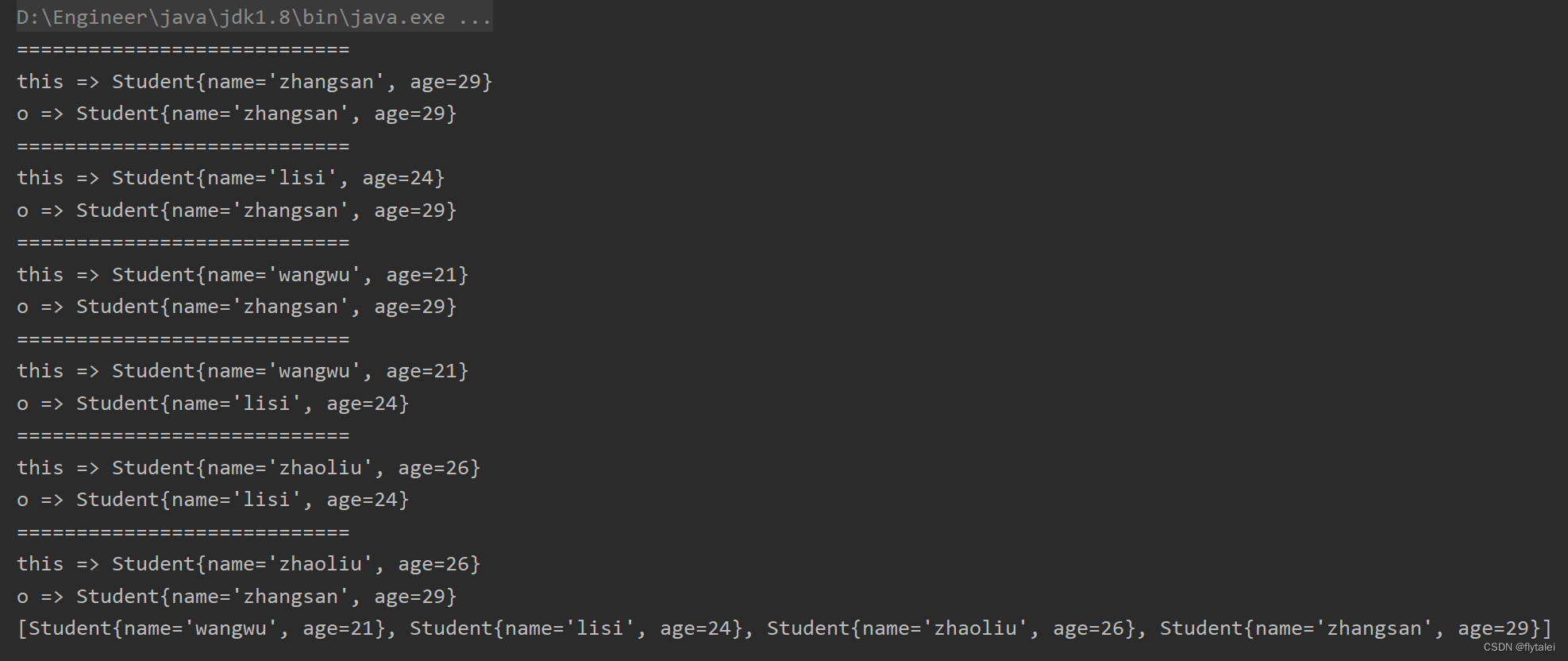
System.out.println("============================");
System.out.println("this => "+this);
System.out.println("o => "+o);
return this.getAge()- o.getAge();
}
省略setter、getter、toString
}
方式二
方式二:
比较器排序:创建TreeSet对象时候,传递比较器Comparator指定规则
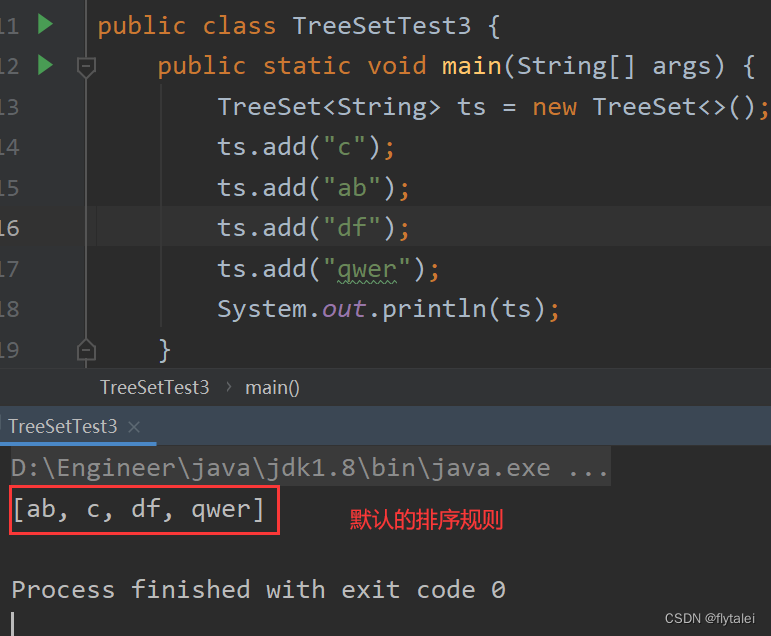
需求:请自行选择比较器和自然排序两种方式,存入四个字符串"c","ab","df","qwer"
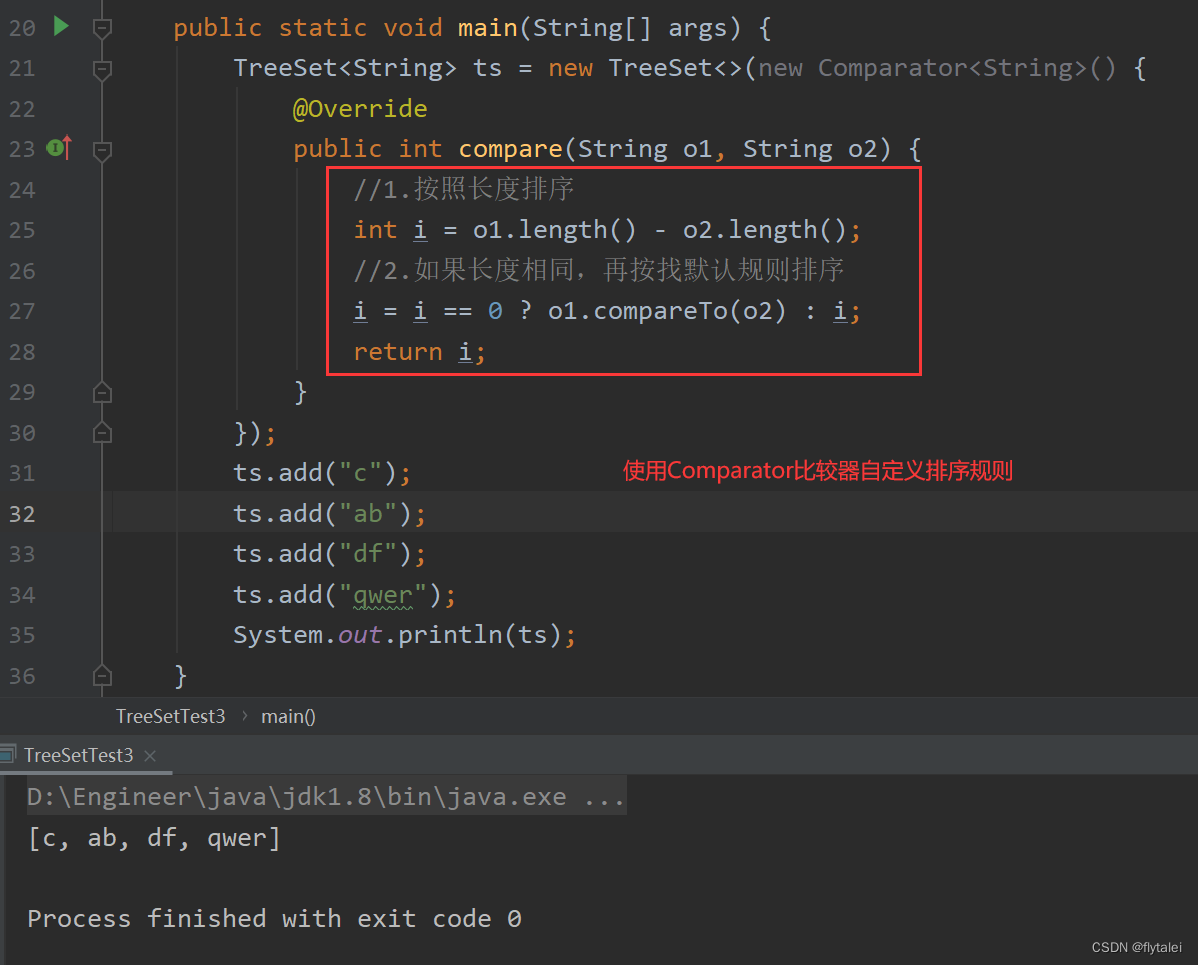
1.按照长度排序,如果一样长则按照字幕排序
自定义先按照长度排序,在按照默认的规则排序
public static void main(String[] args) {
TreeSet<String> ts = new TreeSet<>(new Comparator<String>() {
/**
* @param o1 表示当前要添加的元素
* @param o2 表示已经在红黑树存在的元素
* @return 返回值规则和实现Comparable接口是一样的
*/
@Override
public int compare(String o1, String o2) {
//1.按照长度排序
int i = o1.length() - o2.length();
//2.如果长度相同,再按找默认规则排序
i = i == 0 ? o1.compareTo(o2) : i;
return i;
}
});
ts.add("c");
ts.add("ab");
ts.add("df");
ts.add("qwer");
System.out.println(ts);
}
List和Set的使用场景
1.如果想要集合中的元素可重复
使用ArrayList集合,基于数组实现。(实际开发中用的比较多)
2.如果想要集合中的元素可重复,而且当前的增删操作明显多于查询时
用LinkedList集合,基于链表实现。
3.如果想对集合中的元素去重
用HashSet集合,基于哈希表实现。(用的最多)
4.如果想对集合中的元素去重,而且保持存取顺序
用LinkedHashSet集合,基于哈希表和双链表,效率低于HashSet。
5.如果想对集合中的元素进行排序
用TreeSet集合,基于红黑树。后续也可以用List集合实现排序。
Map-键值对集合特点
Map-键值对集合特点:
1.Map是以key(键)和value(值)的方式存储数据:键值对;
2.key(键)不能重复,value(值)可以重复;
3.key(键)和value(值)都是引用数据类型,存储对象的内存地址;
4.key(键)和value(值)一一对应,每一个键只能找到自己对应的值,key起到主导的地位,value是key的一个附属品。
5.key(键)和value(值)是一个整体,称为"键值对"或者"键值对对象",在Java中叫做"Entry对象"。
Map常用API
Map接口中常用方法:
* V put(K key,V value) 向Map集合中添加键值对
* V get(Object key) 通过Key获取value
* void clear() 清空Map集合
* boolean containsKey(Object key) 判断Map中是否包含某个Key
* boolean containsValue(Object value) 判断Map中是否包含某个value
* boolean isEmpty() 判断Map集合中元素个数是否为0
* Set<K> keySet() 获取Map集合中所有的key(所有的键是一个set集合)
* V remove(Object key) 通过key删除键值对
* int size() 获取Map集合中键值对的个数
* Collection<V> values() 获取Map集合中所有的value,返回一个Collection
代码中选中Map关键字Ctrl+B去到Map的源码中
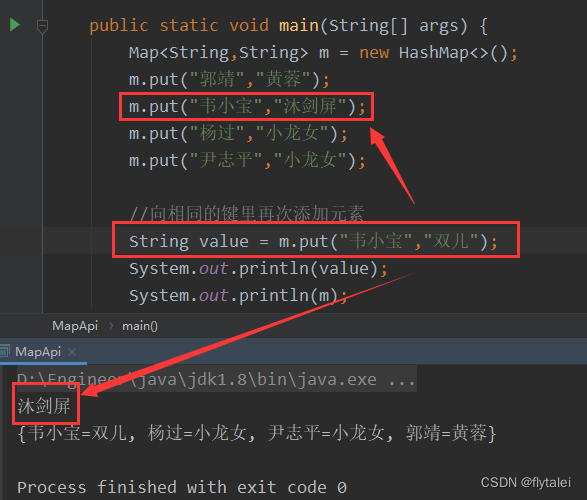
put添加细节
1.put对象是,Map有返回值
put:添加/覆盖
在添加数据的时候,如果键不存在,那么直接把键值对对象提提添加到map集合当中,方法返回null
在添加数据的时候,如果键是存在的,那么会把原有的键值对对象覆盖,会把被覆盖的值进行返回。
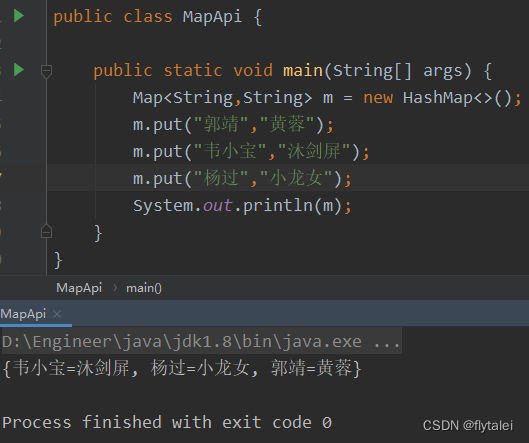
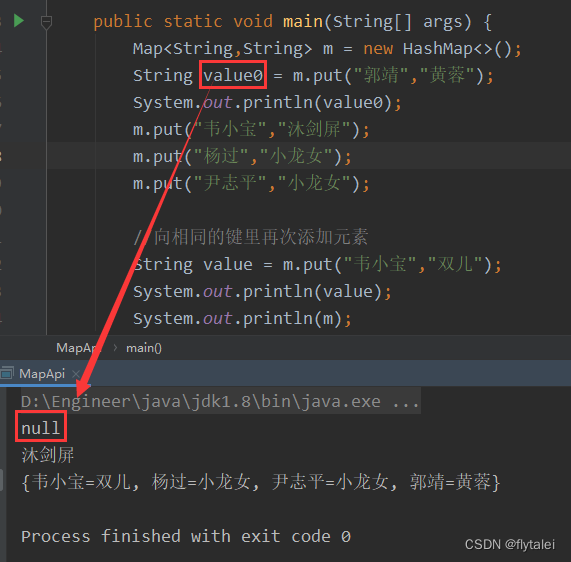
public class MapApi {
public static void main(String[] args) {
Map<String,String> m = new HashMap<>();
String value0 = m.put("郭靖","黄蓉");
System.out.println(value0);
m.put("韦小宝","沐剑屏");
m.put("杨过","小龙女");
m.put("尹志平","小龙女");
//向相同的键里再次添加元素
String value = m.put("韦小宝","双儿");
System.out.println(value);
System.out.println(m);
}
}
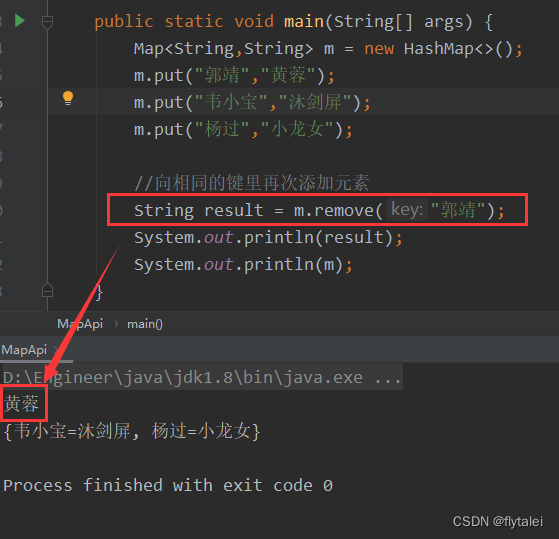
remove
remove时也有返回值,返回的是被删除的键值对对象的值。
public class MapTest01 {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
//1.向Map中添加key-value
map.put(101,"zhangsan");
map.put(202,"lisi");
map.put(303,"wangwu");
map.put(404,"zhaoliu");
System.out.println(map);
//2.获取添加到Map中的key-value的个数
System.out.println("2.Map中所有键值对的个数:"+map.size());
//3.通过key取value
String value = map.get(303);
System.out.println("3.通过key取到的value为:"+value);
//4.获取所有的value
Collection<String> values = map.values();
System.out.println("4.values()获取Map中的所有value:"+values);
//foreach values
for(String str : values){
System.out.println("5.遍历取出:"+str);
}
//6.获取所有的key
Set<Integer> keys = map.keySet();
System.out.println("6.keySet()返回Map中所有的key:"+keys);
//7.判断是否包含某个key和value
System.out.println("7.判断是否包含202的key的结果为:"+map.containsKey(202));
System.out.println("8.判断是否包含leilei的value的结果为:"+map.containsValue("leilei"));
//9.通过key删除key-value
map.remove(404);
System.out.println("9.调用remove()方法后的键值对的数量:"+map.size());
//10.清空Map集合
map.clear();
System.out.println("10.clear()后键值对的数量为:"+map.size());
}
}
{404=zhaoliu, 101=zhangsan, 202=lisi, 303=wangwu}
2.Map中所有键值对的个数:4
3.通过key取到的value为:wangwu
4.values()获取Map中的所有value:[zhaoliu, zhangsan, lisi, wangwu]
5.遍历取出:zhaoliu
5.遍历取出:zhangsan
5.遍历取出:lisi
5.遍历取出:wangwu
6.keySet()返回Map中所有的key:[404, 101, 202, 303]
7.判断是否包含202的key的结果为:true
8.判断是否包含leilei的value的结果为:false
9.调用remove()方法后的键值对的数量:3
10.clear()后键值对的数量为:0
Map的三种遍历方式
1.通过键找值
public static void main(String[] args) {
Map<String,String> m = new HashMap<>();
m.put("郭靖","黄蓉");
m.put("韦小宝","沐剑屏");
m.put("杨过","小龙女");
System.out.println(m);
Set<String> keys = m.keySet();
for(String str : keys){
String key = str;
String value = m.get(key);
System.out.println(key + "=" + value);
}
}
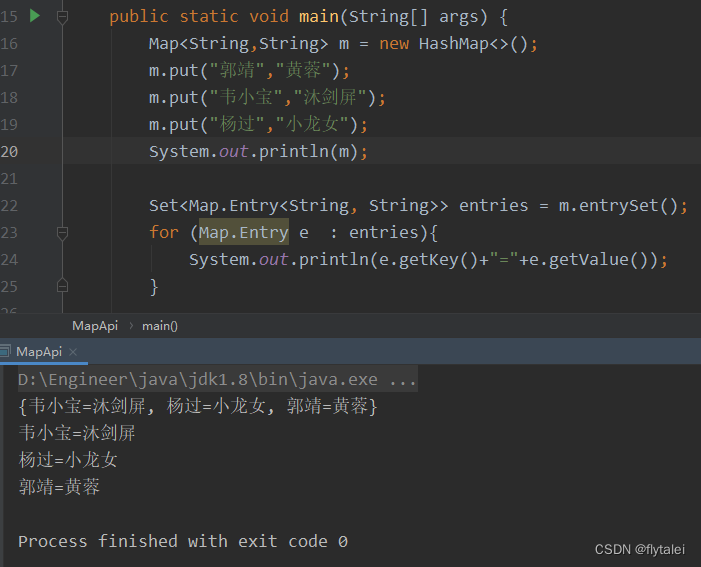
2.通过"键值对"
public static void main(String[] args) {
Map<String,String> m = new HashMap<>();
m.put("郭靖","黄蓉");
m.put("韦小宝","沐剑屏");
m.put("杨过","小龙女");
System.out.println(m);
Set<Map.Entry<String, String>> entries = m.entrySet();
for (Map.Entry e : entries){
System.out.println(e.getKey()+"="+e.getValue());
}
}
Ctrl+Alt+V自动生成方法的返回值类型,或者在方法名后加.var也可以
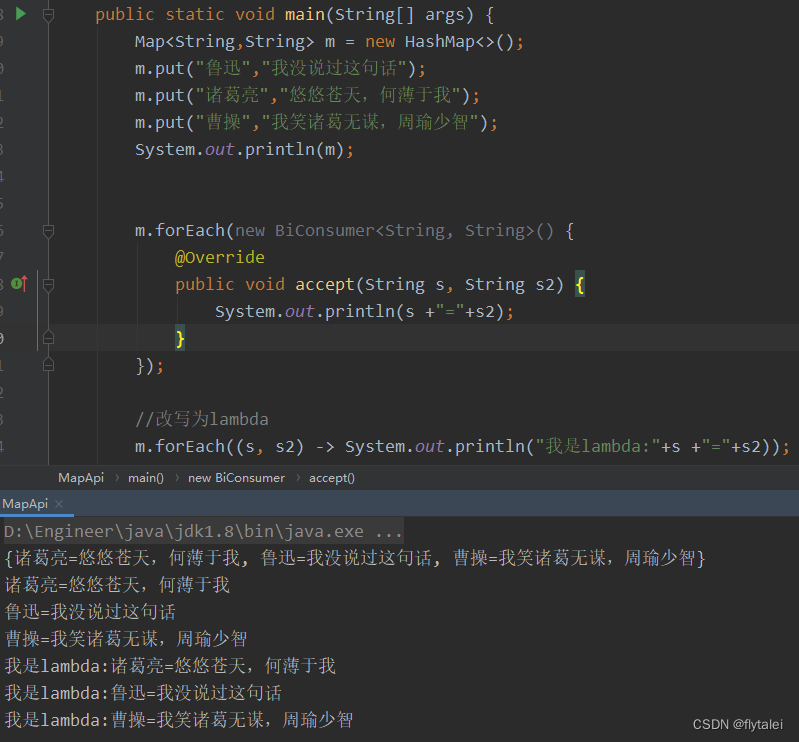
3.Lambda表达式
public static void main(String[] args) {
Map<String,String> m = new HashMap<>();
m.put("鲁迅","我没说过这句话");
m.put("诸葛亮","悠悠苍天,何薄于我");
m.put("曹操","我笑诸葛无谋,周瑜少智");
System.out.println(m);
m.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String s, String s2) {
System.out.println(s +"="+s2);
}
});
//改写为lambda
m.forEach((s, s2) -> System.out.println("我是lambda:"+s +"="+s2));
}
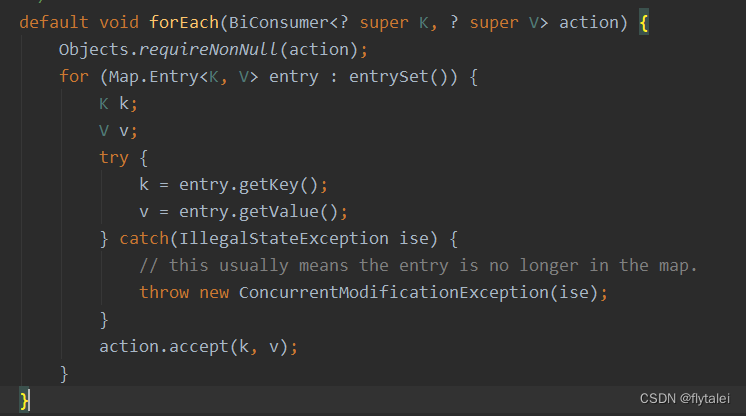
foreach源码
foreach的缺点
foreach底层也是使用的增强for循环,它没有下标,不能通过下标查询元素
HashMap
HashMap底层原理
1.HashMap底层是哈希表结构
2.依赖hashCode方法和equals方法保证键的唯一
3.如果键存储的是自定义对象,需要重写hashCode和equals方法
如果值存储字定义对象,不需要重写hashCode和equals方法
哈希表
为什么哈希表的随机增删和查询效率都高?
1.增删是在链表上完成的;
2.查询也不需要都扫描,只需要部分扫描
重点:
HashMap集合的key会先后调用两个方法,一个方法是hashCode(),一个方法是equqls(),这两个方法都需要重写。
需求
创建一个HashMap集合,
1.键是学生对象(Student),值是籍贯(String).
2.存储三个键值对元素,并遍历
3.要求:同姓名同年龄认为是同一个学生。
public class Student {
private int age;
private String name;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(age, name);
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
getter setter省略
......
}
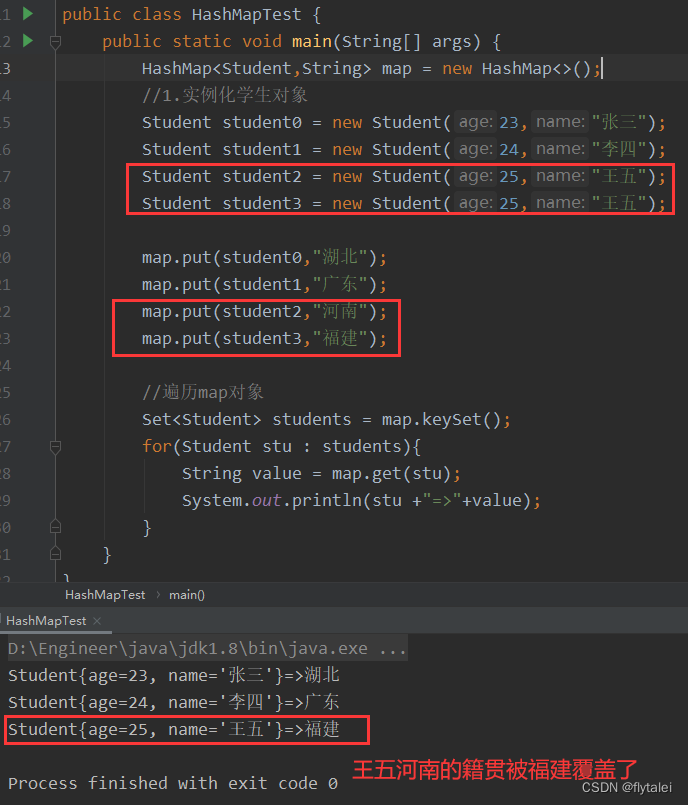
public class HashMapTest {
public static void main(String[] args) {
HashMap<Student,String> map = new HashMap<>();
//1.实例化学生对象
Student student0 = new Student(23,"张三");
Student student1 = new Student(24,"李四");
Student student2 = new Student(25,"王五");
Student student3 = new Student(25,"王五");
map.put(student0,"湖北");
map.put(student1,"广东");
map.put(student2,"河南");
map.put(student3,"福建");
//遍历map对象
Set<Student> students = map.keySet();
for(Student stu : students){
String value = map.get(stu);
System.out.println(stu +"=>"+value);
}
}
}














 3345
3345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









