






【class15】
本节课,我们将学习以下三个知识点:
1. wav文件
2. 从视频中获取音频文件
3. 对音频文件进行参数设置
接下来,我们一起学习吧~
声音是一种波,电脑只能对采样后所得的数字进行处理。常见的音频格式有很多,比如mp3、wma、ape和wav等格式。那么,我们采样所得的数字信息该用哪种文件格式进行存储呢?
常见的mp3等格式都是压缩格式。
语音识别中,音频文件一般需要使用非压缩的纯波形文件来处理,比如Windows PCM文件,也就是俗称的wav文件。
wav文件
定义
wav是最常见的声音文件格式之一,一种标准的数字音频文件,该文件能记录各种单声道或立体声的声音信息,并能保证声音不失真。
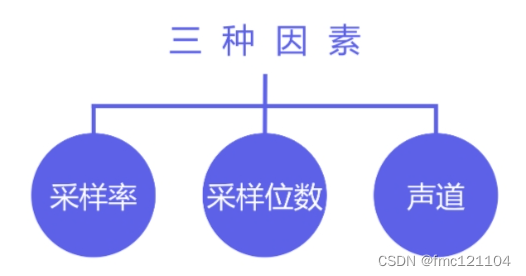
影响wav文件的三个因素:
1. 采样率:每秒钟采集音频数据的次数;
2. 采样位数:用来衡量声音波动变化的一个参数,也是声卡的分辨率。目前计算机中配置声卡的采样位数包括8位和16位两种;
3. 声道:有单声道和立体声之分。
接下来我们需要加载视频,并处理加载后视频,得到需要的音频文件。
模块介绍
本节课,为了从视频中导出音频文件并设置参数,将会用到这两个第三方模块:
1. Moviepy 2. Pydub


要使用Python将视频转化为音频格式,我们需要使用moviepy模块。
moviepy是一个强大的视频处理开源模块。 安装过程非常简单,在终端中输入代码:pip install moviepy即可。如果在自己电脑上无法安装或安装缓慢,可在命令后添加如下配置进行加速:pip install moviepy -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装完moviepy模块后,下一步就是导入该模块。我们在导入moviepy模块时,使用的是moviepy.editor里面的VideoFileClip,可以理解为从moviepy模块下最常用的editor子模块中导入VideoFileClip类。具体代码如下:
# 使用from...import从moviepy.editor导入VideoFileClip
from moviepy.editor import VideoFileClip
安装和导入完moviepy模块后: 我们完成“获取百度API要求的音频”的第一步——获取音频文件。
接下来,我们使用VideoFileClip类: 加载视频,并处理加载后视频,得到需要的音频文件。
让我们一起尝试一下~
代码结构
将从视频文件中获取音频文件分为两部分:
part1. 导入模块
part2. 获取音频文件

代码执行顺序
获取音频文件部分代码的执行顺序为:
1.加载视频
2.获取音频
3.保存音频

# 使用from...import从moviepy.editor导入VideoFileClip 1
from moviepy.editor import VideoFileClip 2
3
# 使用VideoFileClip()加载视频文件"大话西游.mp4" 4
video = VideoFileClip("/Users/yequ/大话西游.mp4") 5
# 使用VideoFileClip类中的audio属性获取加载后视频文件的音频 6
audio = video.audio 7
# 使用write_audiofile()函数将音频文件写入"大话西游.wav" 8
audio.write_audiofile("/Users/yequ/大话西游.wav") 9
分析代码:
获取音频文件
代码的作用
导入模块,加载视频文件,并获取音频文件。
第2行,从moviepy.editor导入VideoFileClip;
第5行,使用VideoFileClip()加载视频文件;
第7行,使用VideoFileClip类中的audio方法获取加载后视频文件的音频;
第9行,使用write_audiofile()函数写入音频文件。
导入VideoFileClip类
需要使用的是moviepy.editor模块里面的VideoFileClip类。使用from...import从moviepy.editor导入VideoFileClip类
加载视频文件
导入后,需要对视频文件进行加载。使用VideoFileClip()加载视频文件"大话西游.mp4。
视频文件路径
传入路径"/Users/yequ/大话西游.mp4"加载视频文件大话西游.mp4。
获取音频
加载完视频文件后,提取相应的音频。使用VideoFileClip类中的.audio属性获取加载后视频文件的音频。
.audio
使用.audio属性可以获取视频中的音频对象。与调用函数不同,这里.audio后面不用带括号。
写入音频文件
获取了音频后,写入音频文件。使用write_audiofile()函数将音频文件写入"大话西游.wav"。
音频文件路径
将 获得音频对象保存在"/Users/yequ/大话西游.wav"路径下。
在从视频中提取音频对象并保存为音频文件时:
moviepy模块会自动输出一些信息,用来提示写入进度、写入路径和写入结果。Output:
chunk: 0%| | 0/562 [00:00<?, ?it/s, now=None]
chunk: 68%|██████▊ | 383/562 [00:00<00:00, 3829.79it/s, now=None]
MoviePy - Writing audio in /Users/yequ/大话西游.wav
MoviePy - Done.
从视频中获取了音频文件后,我们需要对音频进行参数设置:设置wav文件的采样率和声道,以满足百度语音识别接口对音频的要求。

要使用Python做参数设置,我们需要使用pydub模块。
pydub是一个语音端点检测开源模块。 安装过程非常简单,在终端中输入代码:pip install pydub即可。
如果在自己电脑上无法安装或安装缓慢,可在命令后添加如下配置进行加速:
pip install pydub -i Simple Index
安装和导入完pydub模块后: 我们完成“获取百度API要求的音频”的第二步——音频文件参数设置。
完成模块的导入后,我们使用AudioSegment类: 读取音频,并设置wav文件的采样率和声道数。
接下来让我们一起尝试一下。
代码结构
将音频文件参数设置分为两部分:
part1. 导入模块
part2. 参数设置

代码执行顺序
参数设置部分代码执行顺序为:
1.加载音频
2.设置采样率
3.设置声道
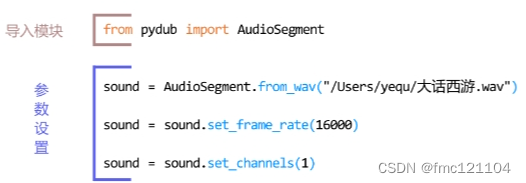
# 使用from...import从pydub导入AudioSegment
from pydub import AudioSegment
# 使用AudioSegment类中的from_wav()函数读取音频文件"大话西游.wav"
sound = AudioSegment.from_wav("/Users/yequ/大话西游.wav")
# 使用set_frame_rate()函数设置采样率为16000
sound = sound.set_frame_rate(16000)
# 使用set_channels()函数设置声道数为1,即单声道
sound = sound.set_channels(1)
分析代码:
音频文件参数设置
代码的作用
导入模块,读取音频文件,设置文件参数。
第2行,从pydub导入AudioSegment;
第5行,使用AudioSegment类中的from_wav()函数读取音频文件;
第7行,使用set_frame_rate()函数设置采样率为16000;
第9行,使用set_channels()函数设置声道数为1,即单声道。
导入AudioSegment类
需要使用的是pydub模块里面的AudioSegment类。使用from...import从pydub导入AudioSegment类。
读取音频文件
导入AudioSegment类后,需要对音频文件进行加载。使用AudioSegment类中的from_wav()函数读取音频文件"大话西游.wav"。
音频文件路径
传入文件路径"/Users/yequ/大话西游.wav"读取音频文件。
设置采样率
读取音频文件后,设置音频采样率。 使用set_frame_rate()函数设置采样率为16000Hz。
采样率
传入参数16000,设置采样率为16000Hz。
设置声道
设置完采样率后,使用set_channels()函数设置声道。
声道
传入参数1,设置音频声道为单声道。
此外,若传入参数2,则设置音频声道为多声道立体声。
代码整理
将今日学习的代码分为两个部分:
part1. 获取音频文件
part2. 音频文件参数设置

本节课,我们获取了视频中的音频文件,并做了处理,为正式语音识别前做了一些准备工作。下节课,我们将学习语音端点检测,切分音频并保存音频片段。















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









