






【class16】
上节课,我们学习了:
wav文件的相关概念知识,并通过代码从视频中获取了音频以及设置了参数。
学习新的课程之前,我们先来复习一下吧!
代码复习
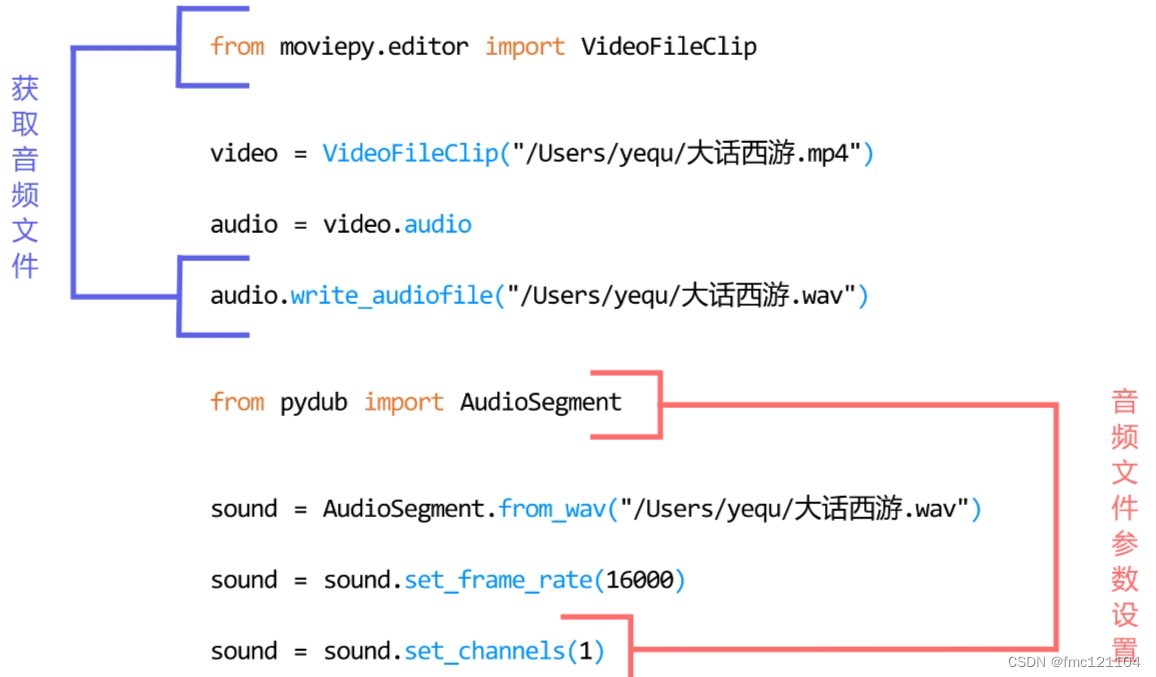
将上节课学习的代码分为两个部分:
part1. 获取音频文件
part2. 音频文件参数设置
wav文件是非压缩音频文件 , pydub模块是用于音频处理的Python模块, moviepy是用于视频处理的Python模块,D选项错误。
本节课,我们将学习这些知识点:
1. 语音端点检测 2. 切分音频 3. 保存语音片段文件
wav文件由文件头和数据体组成,数据体也就是声音波形经过采样所得的一个个数据点了。读取wav文件绘制波形图可以看到:一段音频包括静音段和语音段。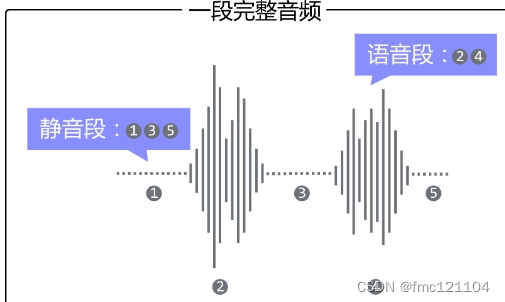
语音段是wav文件中的有效信息,我们需要的文字信息就储存在语音段。
静音段在wav文件中对应的是说话的间隙部分,不包含文字信息。

将不包含文字信息的静音段切除, 以降低静音段对后续处理所造成的干扰。这个切除静音的操作被称为语音端点检测(VAD), VAD操作之后一段完整的音频就被切分为若干个只有语音段的音频文件。
语音端点检测
定义
语音端点检测(Voice Activity Detection,VAD)又称语音活动检测,语音边界检测。 目的是从声音信号流里识别和消除静音段。

语音端点检测从字义上理解就是对语音的端点进行检测。
这里的端点实际上就是语音段和静音段的分界点,语音端点检测后就可以去除音频中的静音段,只保留语音段的部分。
VAD的目的
由于字幕文件包括时间信息,声音和字幕应该同步出现。如果两句话有较长的静音段间隙,不做VAD的话,就会出现语音和字幕不匹配的情况。
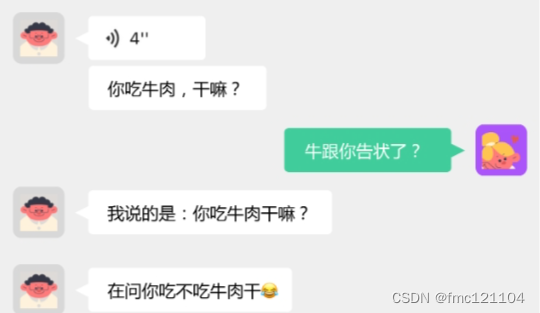
切分语音不难,最简单的方法就是按照时间平均切分。 问题在于怎么能不把一句话切成两半,或者一个词切成两半。看看图中因一句话切成两半而引发的笑话吧!语音端点检测就可以解决这个问题。

音频这个东西,看波形就可以看出来有没有声音,哪部分是语音段,哪部分是静音段一目了然。语音段是一段持续高幅度的信号,而静音段幅度很低。
我们可以通过设定一个数值(声音强度)当作基准, 当一个输入的数值序列中出现持续低于基准数值的声音时:
比如,连续2秒出现幅度低于0.1的数时,我们就认定这段音频属于静音段。
学习完语音端点检测的相关概念和原理之后: 我们完成“语音端点检测”的第一步——切分音频去除静音段。
首先需要导入pydub模块。
我们在导入pydub模块做音频切分时,使用的是pydub.silence模块里面的split_on_silence,可以理解为从pydub模块中的silence子模块下中导入split_on_silence类。
完成模块的导入后,我们利用语音端点检测的原理: 对split_on_silence类,设置适当的参数切分音频。
接下来让我们一起尝试一下。
代码结构
将切分音频分为两部分:
part1. 导入模块
part2. 切分音频

分析代码:
切分音频
代码的作用
第11-17行,导入模块,设置参数,切分音频。
第12行,从pydub.silence导入split_on_silence;
16行,设置参数sound,min_silence_len和silence_thresh的数值;
第17行,使用split_on_silence()切分音频,并传入参数sound,min_silence_len,silence_thresh。
导入split_on_silence类
需要使用的是pydub.silence模块里面的split_on_silence类。使用from...import从pydub.silence导入split_on_silence类
split_on_silence()
导入模块后,通过split_on_silence()切分音频。
sound
sound为必选参数,即待切分的音频文件。
min_silence_len
min_silence_len为可选参数,它表示的是静音段的最小长度,默认值:1000(毫秒)。设置min_silence_len = 500,表示静音部分长度值任何比这大的值将被视为静音段。参数500不是固定值,根据不同音频可以进行调参。
silence_thresh
silence_thresh为可选参数,它表示的是需要进行识别的静音段的最小声音强度,默认值:-16dbfs。(任何小于该值的声音将直接被视为静音,不需要进行识别)设置silence_thresh = -50,表示任何比这安静(比如-55)的值将被视为静音。参数-50不是固定值,根据不同音频可以进行调参。
返回的对象
将切分完获得的音频片段对象赋值给变量pieces。

完成切分音频处理后,获得了音频片段对象。输出查看切分完的音频片段对象变量pieces,结果为保存了多个音频片段对象的列表。
得到了切分好的无静音段音频对象之后:
我们完成“语音端点检测”的第二步——导出保存音频片段文件。
接下来,通过for循环导出音频片段,遍历pieces列表,将获得的多个音频片段对象保存为wav文件。
代码结构
将导出音频文件通过for循环实现:
音频片段按序号保存为wav文件,文件保存至/Users/yequ/路径下。

导出音频片段
代码的作用
第10-16行,通过for循环将切分完的多个音频片段对象保存为wav文件。
# 变量count用于计数,赋初始值为0
count = 0
# 通过for循环将切分完的音频片段对象保存为wav文件
for i in pieces:
# 文件保存至路径变量path,文件名从音乐片段0.wav-音乐片段11.wav
path = "/Users/yequ/音频片段"+str(count)+".wav"
# 遍历pieces,将音频片段对象导出为wav文件,文件路径为path
i.export(path,format = "wav")
# 计数器加1
count += 1
分析代码:
计数
定义变量count用于计数,赋初始值为0。
遍历
使用for循环遍历pieces音乐音频对象列表,i为列表中的每个元素。
文件路径
文件保存至路径变量path,路径为/Users/yequ/下的音频文件,文件名从音乐片段0.wav-音乐片段11.wav音乐。
待导出音频片段
变量i为pieces列表中每个元素,即待导出音频片段对象。
export()函数
使用export()函数将音频对象导出为音频文件。 用法:export(a,b),a为路径,b为文件格式。
音频格式
通过参数format设置保存的音频文件格式为wav文件。
完成切分音频和导出音频片段这两步操作,我们获得了多个无静音段的音频文件。打开文件夹可以看到命名为音频片段0.wav-音频片段11.wav的12个wav文件。
代码整理
将今日学习的代码分为两个部分:
part1. 切分音频
part2. 导出音频


本节课,我们对音频文件进行了语音端点检测并切分和保存了音频。下节课,我们将学习语音识别系统模型,并调用创建好的AipSpeech客户端实现语音转文字功能。















 5261
5261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









