







Neo4j GDS 2.0 配置与使用
GDS插件安装:Neo4j官方文档
一、Neo4j Graph Data Science
1.1 GDS简介
Neo4j GDS 是一种用于图数据分析的库,提供了一系列图算法和机器学习工具。这些工具可以帮助你发现数据中的模式、进行社交网络分析、图模型的构建等。
1.2 GDS版本管理
具体可参考:Neo4j与GDS版本对应关系
| 序号 | Neo4j 版本 | GDS 版本 |
|---|---|---|
| 1 | 5.26 | 2.13 |
| 2 | 5.25 | 2.12 |
| 3 | 5.24 | 2.12, 2.11, 2.10 |
| 4 | 5.23 | 2.11, 2.10, 2.9 |
| 5 | 5.22 | 2.10, 2.9, 2.8 |
| 6 | 5.21 | 2.9, 2.8, 2.7 |
| 7 | 5.20 | 2.9, 2.8, 2.7, 2.6.7 and later |
| 8 | 5.19 | 2.9, 2.8, 2.7, 2.6.5 and later |
| 9 | 5.18 | 2.9, 2.8, 2.7, 2.6.2 and later |
| 10 | 5.17 | 2.9, 2.8, 2.7, 2.6.1 and later |
1.3 Neo4j 版本查看
版本查看命令:
CALL dbms.components() YIELD name, versions, edition
RETURN name, versions, edition

二、GDS的工作方式
在高层次上, GDS的工作方式是将数据转化并加载到一个为高性能图分析而优化的内存格式中. GDS在这种内存图格式上执行图算法, 特征工程和机器学习方法. 使得数据科学能够高效和可扩展地应用于展示整个或大部分图数据库的大型图
2.1 基本工作流程
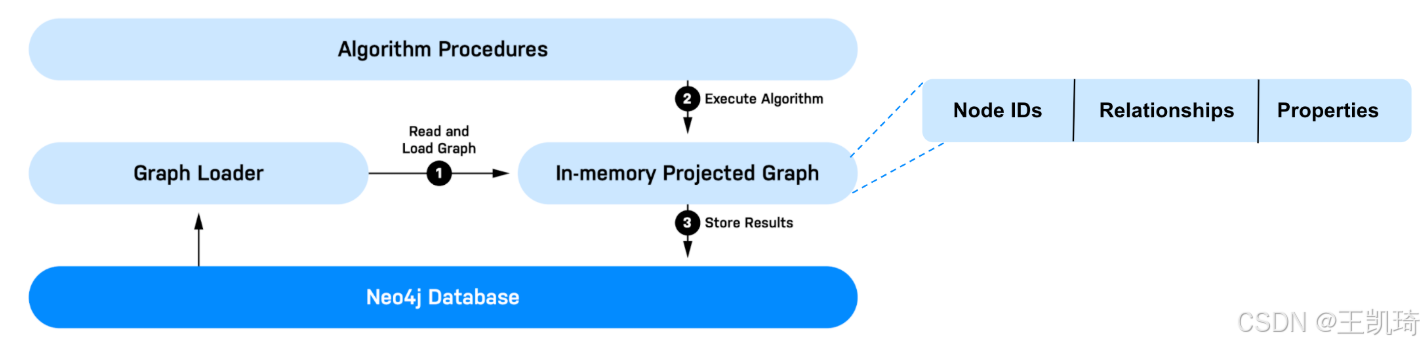
- 1.读取和加载图: GDS需要从Neo4j数据库中读取数据, 进行转换, 并将其加载到内存图中. 在GDS中, 这个过程称为投射图 (projecting a graph) , 把内存中的图称为图的投影(graph projection) . GDS可以同时容纳多个图的投影, 由一个叫做图目录 (Graph Catalog) 的组件管理. 图目录和图投影管理将在下一个模块中更详细地介绍.
- 2.执行算法: 包括经典的图算法, 如中心性算法 (centrality) , 社区检测算法 (community detection) , 路径搜索算法 (path finding) 等. 它还包括嵌入法 (embeddings) , 一种强大的图特征工程的形式, 以及机器学习管道 (machine learning pipelines) .
- 3.储存结果: 结果可以写回到数据库, 以csv格式导出, 或输出到另一个应用程序或下游工作流程.
三、GDS安装与配置
3.1 GDS下载
下载地址:GitHub下载地址
3.2 GDS配置
配置步骤:
-
- 将下载好的gds.jar放在 NEO4J/HOME/plugins中
-
- 修改neo4j.conf文件,在这个配置项中,追加gds.*
dbms.security.procedures.unrestricted=apoc.*,gds.*
-
- 重启neo4j
-
- 在neo4j里,执行
RETURN gds.version()
出现版本号,即证明安装成功

四、GDS操作
4.1 数据准备
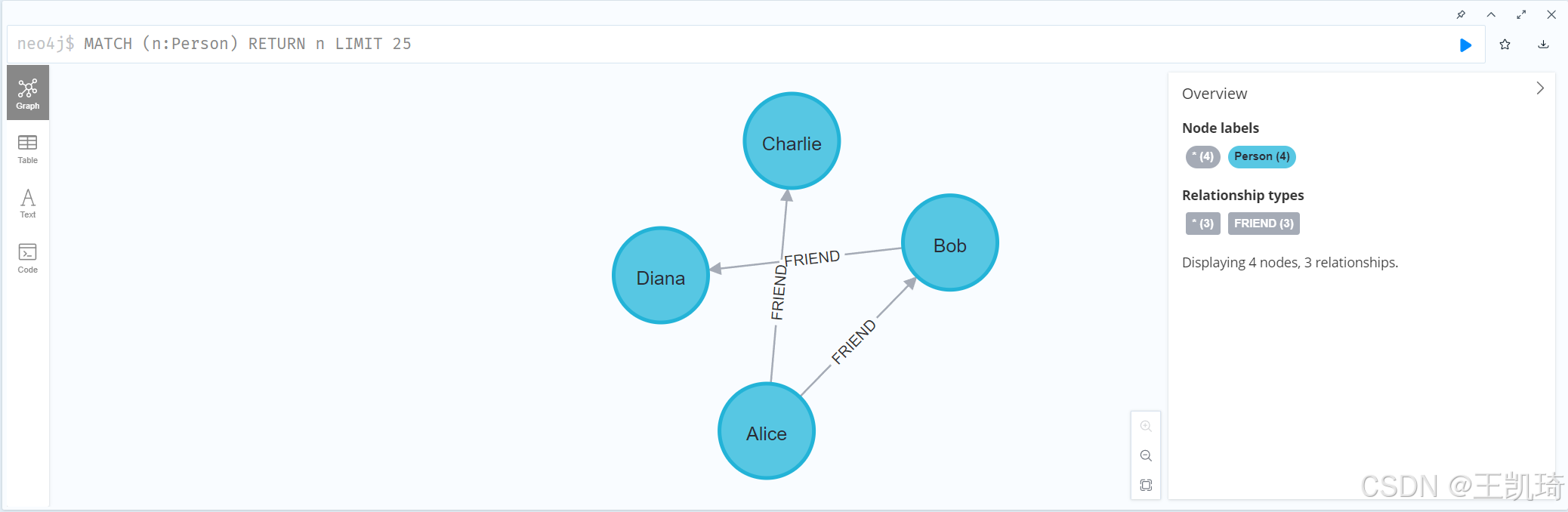
首先,我们需要准备图数据。在 Neo4j 中,可以使用以下代码插入一些示例数据:
CREATE (Alice:Person {name: 'Alice'}),
(Bob:Person {name: 'Bob'}),
(Charlie:Person {name: 'Charlie'}),
(Diana:Person {name: 'Diana'}),
(Alice)-[:FRIEND]->(Bob),
(Alice)-[:FRIEND]->(Charlie),
(Bob)-[:FRIEND]->(Diana)
以上代码创建了四个节点,并通过 FRIEND 关系将它们连接起来。
4.2 图目录使用
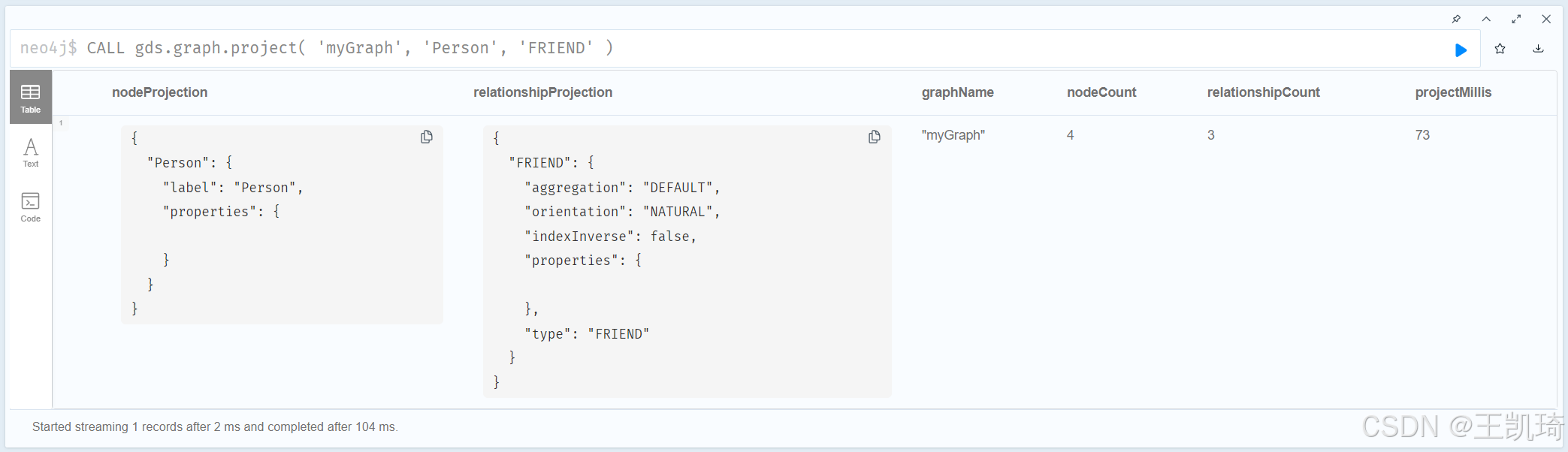
- 创建图
在使用 GDS 之前,我们需要创建图模型。我们可以使用以下命令创建一个基础图:
CALL gds.graph.project(
'myGraph',
'Person',
'FRIEND'
)
注意这里不是CALL gds.graph.create,create是老版本语法,已经不支持了
这里 ‘myGraph’ 是图的名称,‘Person’ 为节点标签,‘FRIEND’ 是关系类型。
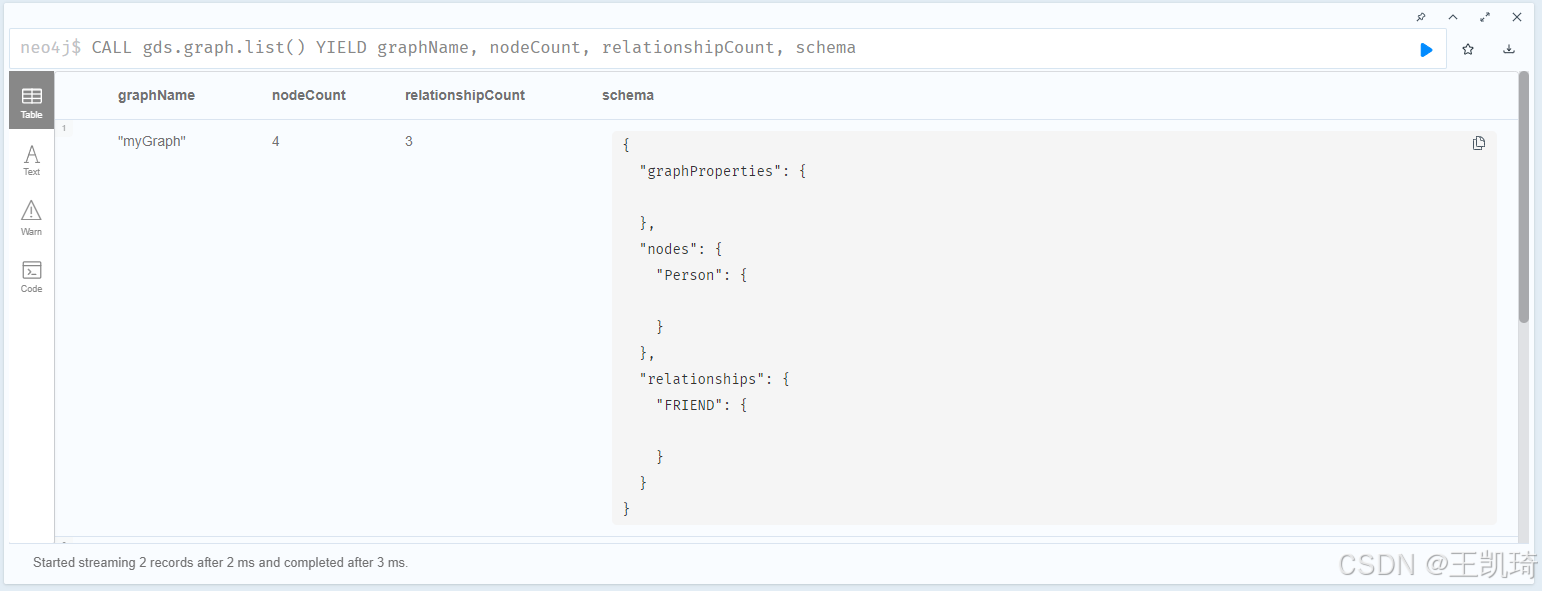
- 图展示
再次列出图表,我们可以看到刚刚创建的图的信息:
CALL gds.graph.list() YIELD graphName, nodeCount, relationshipCount, schema
4.3 运行算法
创建投影是为高效地运行图算法和进行图数据科学提供空间
4.3.1 运行算法1
计算Actor节点的度中心性 (degree centrality) . 具体的度中心算法 (degree centrality algorithm) 之类的在Neo4j图数据科学基础课程中有介绍. 目前只需要知道它将会计算每个人的朋友数量, 并将数据储存到一个叫totalOfFriends的节点属性中 (还不会被写入到数据库中) .
CALL gds.degree.mutate('myGraph', {mutateProperty:'totalOfFriends'})
- CALL gds.degree.mutate: 这部分指定了要调用的GDS过程,即degree算法的mutate模式。degree算法计算每个节点的度,也就是与该节点直接相连的边的数量。mutate模式意味着计算的结果不会立即返回给用户,而是会存储在图中,以便后续的查询或处理能够利用这些计算结果。
- (‘my-graph-projection’): 这是传给degree.mutate过程的第一个参数,表示你想要在其上执行操作的图的名称。在这个例子中,图的名字叫做’my-graph-projection’。这通常是你之前通过类似gds.graph.project等命令创建的一个图投影。
- {mutateProperty:‘numberOfMoviesActedIn’}: 这是一个配置项对象,其中包含了具体的配置选项。mutateProperty键指定了一条信息,即计算出来的度数将作为节点的一个属性保存,并且这个属性的名字将是’numberOfMoviesActedIn’。换句话说,对于图中的每个节点,其度数(即与之关联的边的数量)将会被计算出来,并以’numberOfMoviesActedIn’为名添加到该节点上作为一个新的属性。
执行结果为:
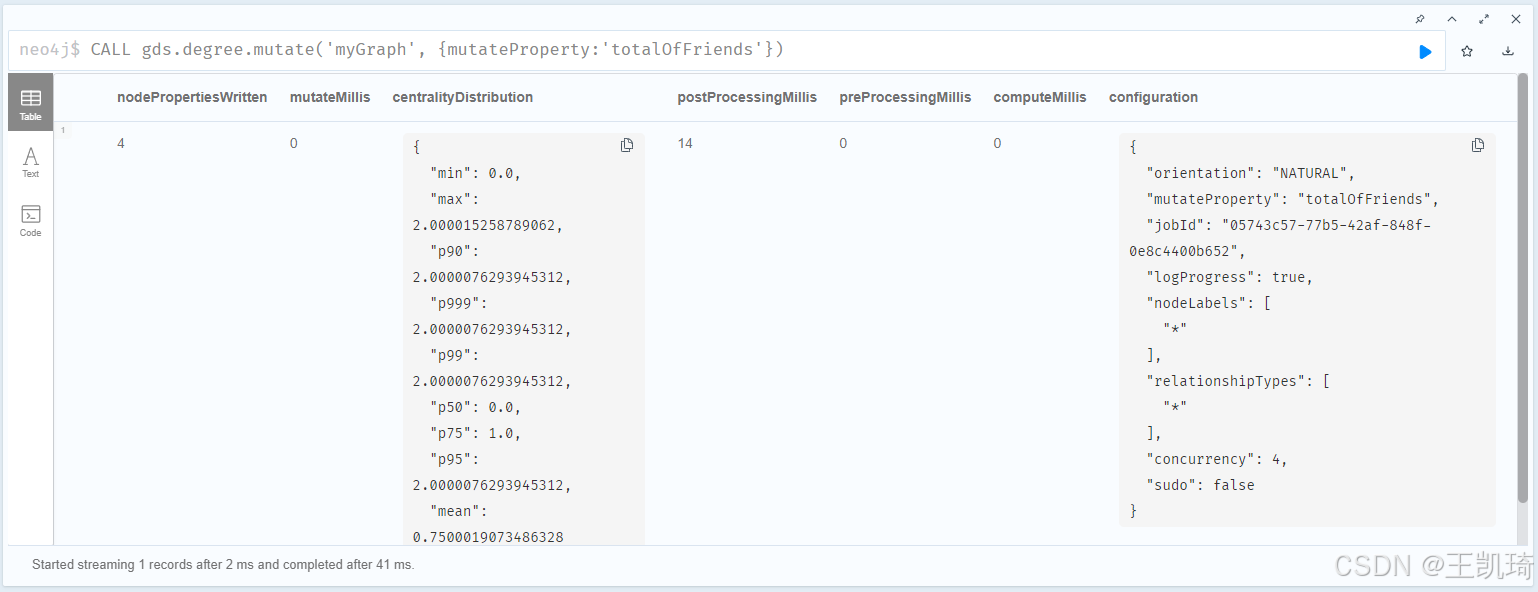
结果解析:
- nodePropertiesWritten:4
这表示有 4 个节点属性被写入图中。这意味着图中的每个节点现在都有一个新的属性 ‘totalOfFriends’,表示该节点的度数。 - mutateMillis:0
这是 mutate 阶段所花费的时间,为 0 毫秒。这个阶段涉及将计算的结果写回到节点上。 - centralityDistribution
min: 0.0
最小度数为 0。
max: 2.000015258789062
最大度数为 2.000015258789062。
p90: 2.0000076293945312
90% 分位数的度数为 2.0000076293945312。
p99: 2.0000076293945312
99% 分位数的度数为 2.0000076293945312。
p999: 2.0000076293945312
99.9% 分位数的度数为 2.0000076293945312。
p50: 0.0
50% 分位数(中位数)的度数为 0.0。
p75: 1.0
75% 分位数的度数为 1.0。
p95: 2.0000076293945312
95% 分位数的度数为 2.0000076293945312。
mean: 0.7500019073486328
度数的平均值为 0.7500019073486328。 - postProcessingMillis:14
这是后处理阶段所花费的时间,为 14 毫秒。这个阶段涉及对计算结果的进一步处理。 - preProcessingMillis:0
这是预处理阶段所花费的时间,为 0 毫秒。这个阶段涉及数据的准备和初始化。 - computeMillis:0
这是计算阶段所花费的时间,为 0 毫秒。这个阶段涉及实际的计算过程。 - configuration
orientation: “NATURAL”
表示算法的方向设置为自然方向。
mutateProperty: “totalOfFriends”
表示要存储的节点属性名称为 ‘totalOfFriends’。
jobId: “05743c57-77b5-42af-848f-0e8c4400b652”
这是任务的唯一标识符。
logProgress: true
表示是否记录进度,默认为 true。
nodeLabels: [““]
表示所有节点标签都被考虑。
relationshipTypes: [””]
表示所有关系类型都被考虑。
concurrency: 4
表示并发级别为 4。
sudo: false
表示是否以超级用户模式运行,默认为 false。
4.3.2 运行算法2
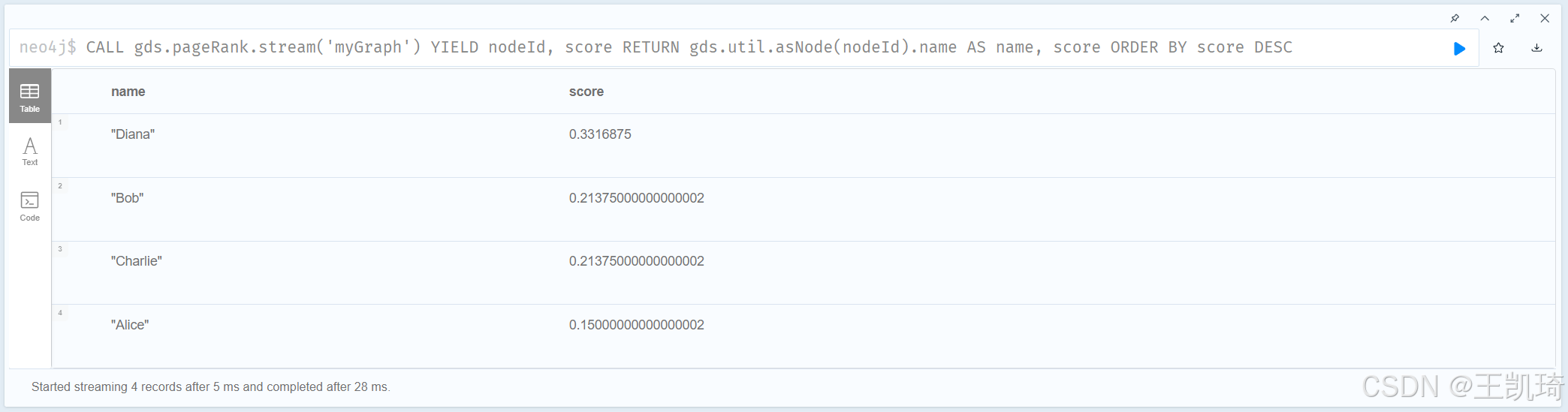
利用PageRank计算得分:
CALL gds.pageRank.stream('myGraph')
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS name, score
ORDER BY score DESC
上述代码计算了图中每个节点的 PageRank 值,并按得分降序返回结果。


















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











