






“ 这两天根据官方文档搭建国产开源大模型 ChatGLM2-6b,不说七七四十九难,也碰到不少坑,坑坑不一样。”

01
—
之前ChatGLM2-6B 初体验文章发出时,答应朋友搭建一个免申请的版本,方便朋友们试用咱们的国产大语言模型。
从官方指引开始,官方 Git 仓库:
https://github.com/THUDM/ChatGLM2-6B

看着很简单,统共3行命令。
我就信心满满的撸起袖子开干:买个虚拟空间开始。没想到,这才是碰个满头包的开始。
按传统的思路,买了一台云服务器,操作系统为国产 OpenCloudOS Server 8。远程登录上去,一顿前置软件安装:yum update, git, python,docker。
过程也没少遇到各种报错,好在本人经验丰富,一一摆平!
但是由于 python 的版本没注意,安装是按搜索教程里面的版本,略低,导致给后面的步骤埋下了坑。
ChatGLM2-6B 仓库克隆到本地后,用 pip 安装依赖库出现第一个大坑:
“No matching distribution found for transformers>=4.20.1 (from chatgpt==0.1.0) #2752”。
最重要的依赖 transformer 居然安装不上,这怎么行!

stackoverflower 有个同样的问题,回答是:“You need Python >=3.7.”。
一检查发现之前安装的 Python 是 3.6.8。继续折腾,重新安装 3.8 版本。
再重试还是不行,卒。
再找,关于安装 transformer 的方案有个试用 Docker 安装的建议:
“https://github.com/hpcaitech/ColossalAI#Use-Docker”。
一顿折腾,此方案,卒。
找到官方网站,加入微信交流群,有朋友建议把依赖的版本降低,降到上面报错信息里面提示可以找到的最高版本。也就是 4.18.0,这次可以继续了。
但是安装另外一个重要依赖:torch 也出现了同样问题,降版本再试。安装完后,启动测试代码,依然不行。
此方案,卒。
还有说可以用谷歌的在线 Colab 运行模型,立刻动手。
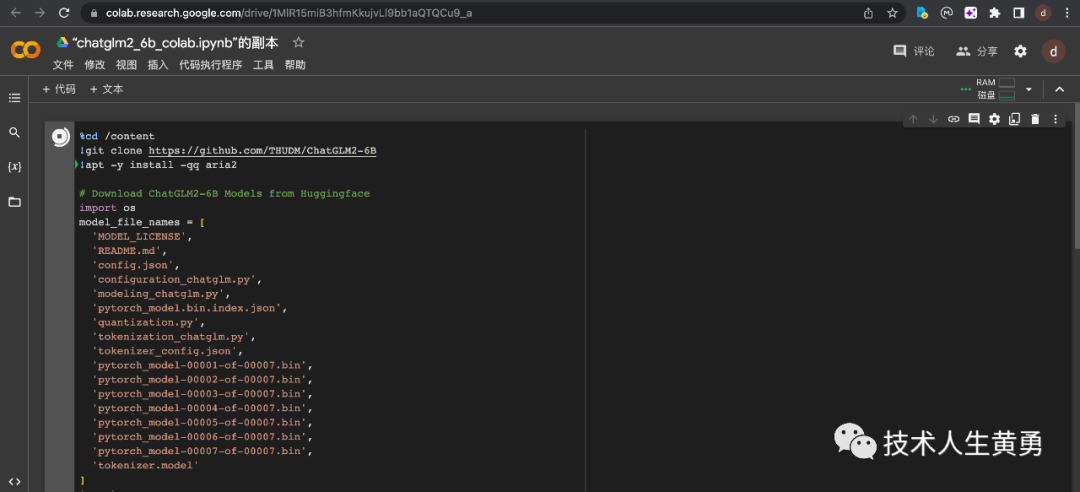

等了半天,等到安装过程中途报了一个错,同样无法解决。
此方案,卒!
02
—
进展受挫,暂时休战。
正准备睡觉,刷了一下官方交流群里的内容,忽然受到这句启发:“我跟着B站一个教程做的云里雾里的”。
爬起来,到B站用“ChatGLM”一搜索,果然找到有最新的一个视频,讲解了如何用GPU云资源来搭建最新的ChatGLM2-6B的过程。
视频链接:
https://www.bilibili.com/video/BV1414y1m7mE
按视频讲解的过程,注册登录,购买GPU,登录到操作界面,命令行。
中间也经历不少坑,好在GPU的预安装环境是符合要求的,再没出现各种莫名其妙的错误。只是在网络上出现了卡壳的问题,加了镜像站的配置后,就解决了。
一开始按视频教程,手动下载7个大文件,再修改 web_demo.py 里面的加载模型文件的路径,出现错误提示,失败。
后来抱着死马当活马医的思路,已经都进展到这里了,直接运行官方的示例代码,试试。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda')
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)凌晨4点半,终于看到了下面这个成功的界面!
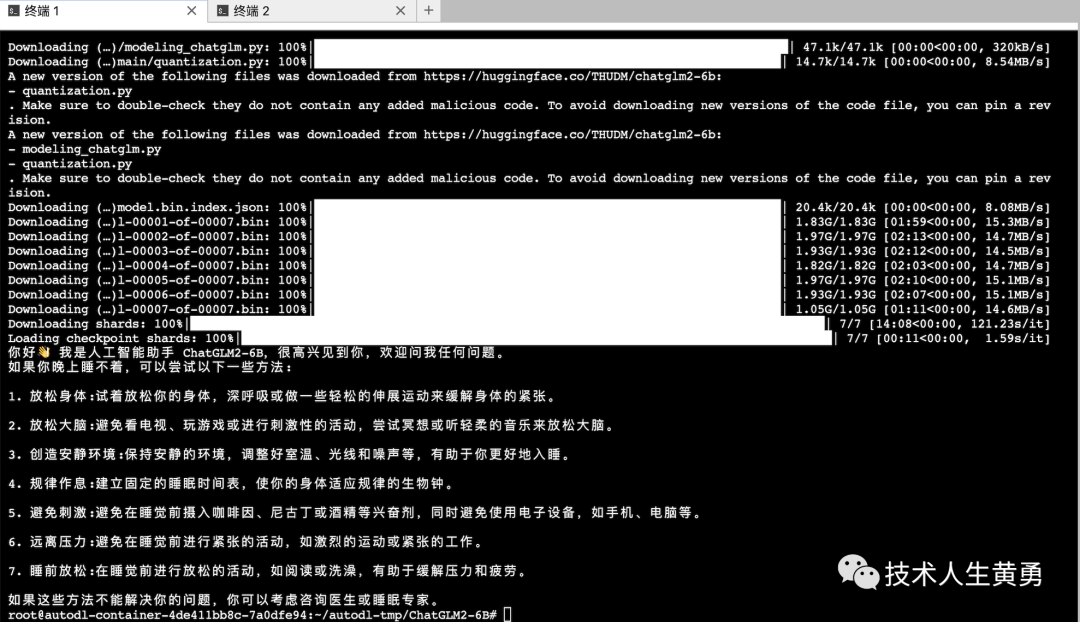
实验成功,再试试命令启动:python web_demo.py
吼吼!最终的成果:
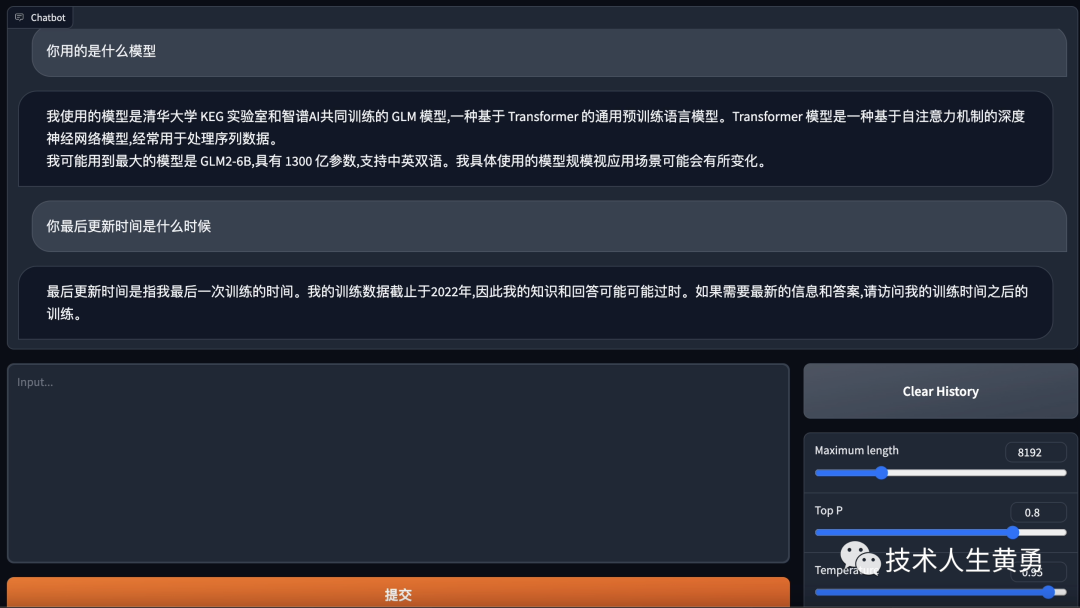
“我使用的模型是清华大学KEG实验室和智谱A共同训练的 GLM 模型一种基于 Tansformer 的通用预训练语言模型。
Transhormer模型是一种基于自注意力机制的深度神经网络模型,经常用于处理序列数据。
我可能用到最大的模型是 GLM2-6B,具有 1300 亿参数,支持中英双语。我具体使用的模型规模视应用场景可能会有所变化。”
早上,官方交流群里又传来好消息:“这有个安装教程,亲测,成功部署”
https://blog.csdn.net/stay_foolish12/article/details/131437090?spm=1001.2014.3001.5502
我去看了一下,这个是全程手动部署版本,不依赖上面视频提供的预安装环境。有兴趣的朋友可以趟一下坑。
03
—
预告:ChatGLM2-6B,已经搭建成功,这两天合适的时候,网上发布出来,提供给朋友们使用和反馈。
往期热门文章推荐:
性能提升571%,32K超长上下文,推理速度提升42%,允许商用,国产开源大模型推出了二代 ChatGLM2-6B
技术科普与解读:ChatGPT 大模型硬核解读!(二)GPT4 的多模态涌现能力-接近人类关键特征
不允许还有人不知道可以免费用 ChatGPT 的网站,ChatGPT3 和 4,Claude 和 Claude+ 一网打尽
拥抱未来,学习 AI 技能!关注我,免费领取 AI 学习资源。














 1340
1340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









