







SuperCLUE团队
2025/03

摘要内容
1. DeepSeek-R1和国内外推理模型对比
背景
自2023年以来,AI大模型在过去两年掀起了全球范围内的人工智能浪潮。进入2025年,全球大模型竞争态势日益加剧,特别是随着o3-mini、DeepSeek-R1、Claude-3.7-Sonnet、QwQ-32B等推理模型的发布,国内外大模型在2025年一季度进行了波澜壮阔的大模型追逐赛。

中文大模型测评基准SuperCLUE持续对国内外大模型的发展趋势和综合效果进行了实时跟踪,正式发布《中文大模型基准测评2025年3月报告》。
报告全文共46页,本文仅展示报告中关键内容,完整内容可点击文章底部【阅读原文】查看高清完整PDF版。
在线完整报告地址(可下载):
www.cluebenchmarks.com/superclue_2503
SuperCLUE排行榜地址:
www.superclueai.com
报告关键内容
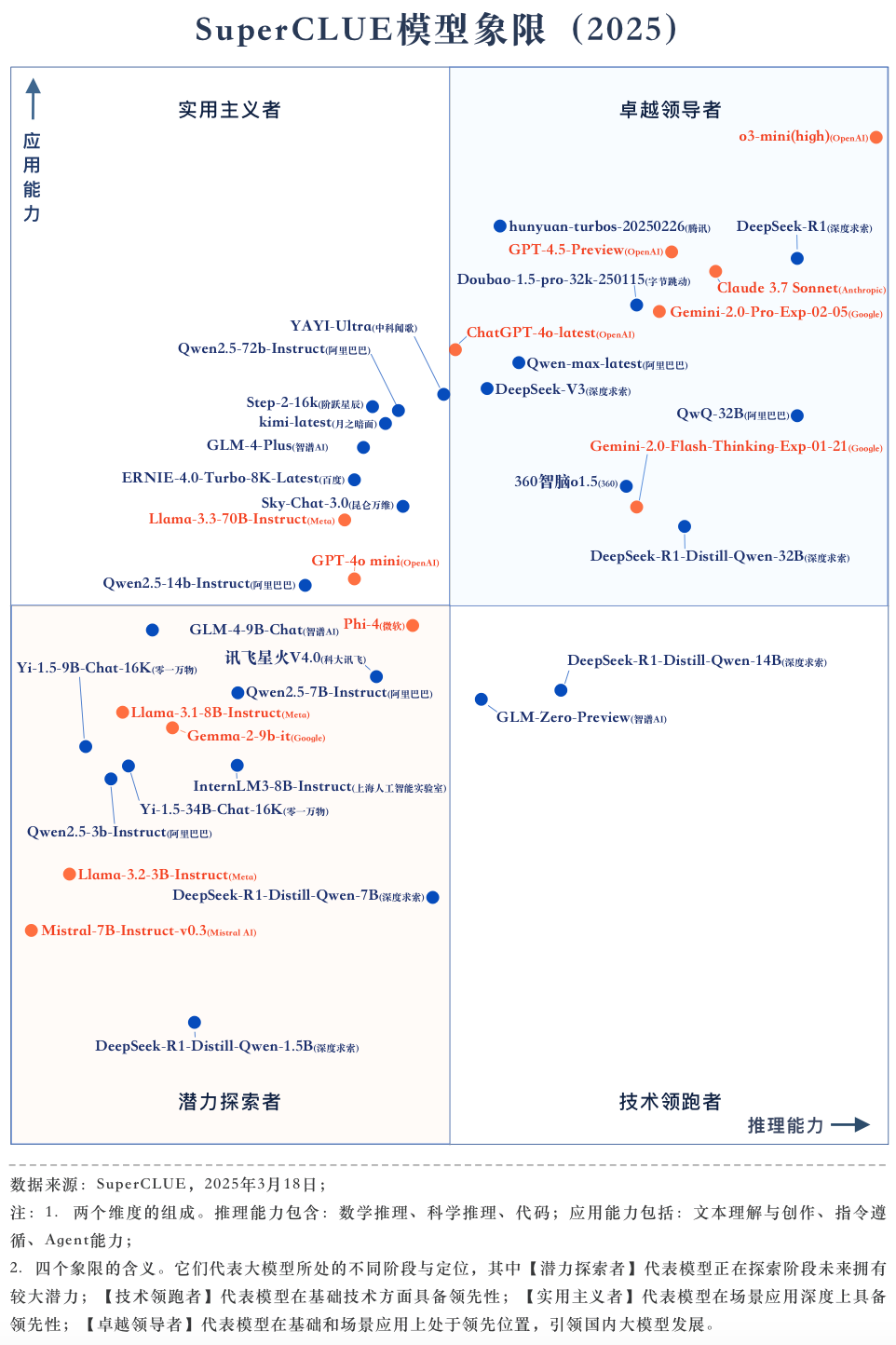
关键内容1:2025年最值得关注的大模型全景图

关键内容2:3月总榜及模型象限
#测评介绍

【SuperCLUE通用数据集】分为数学推理、科学推理、代码生成、智能体Agent、精确指令遵循、文本理解与创作;
【SuperCLUE评价方式】分为基于人工校验参考答案的评估(0-1得分);基于代码单元测试的评估(0-1得分);结合任务完成与否、系统状态比对的评估(0-1得分);基于规则脚本的评估(0-1得分);人工校验参考答案的、多维度评价标准的评估。
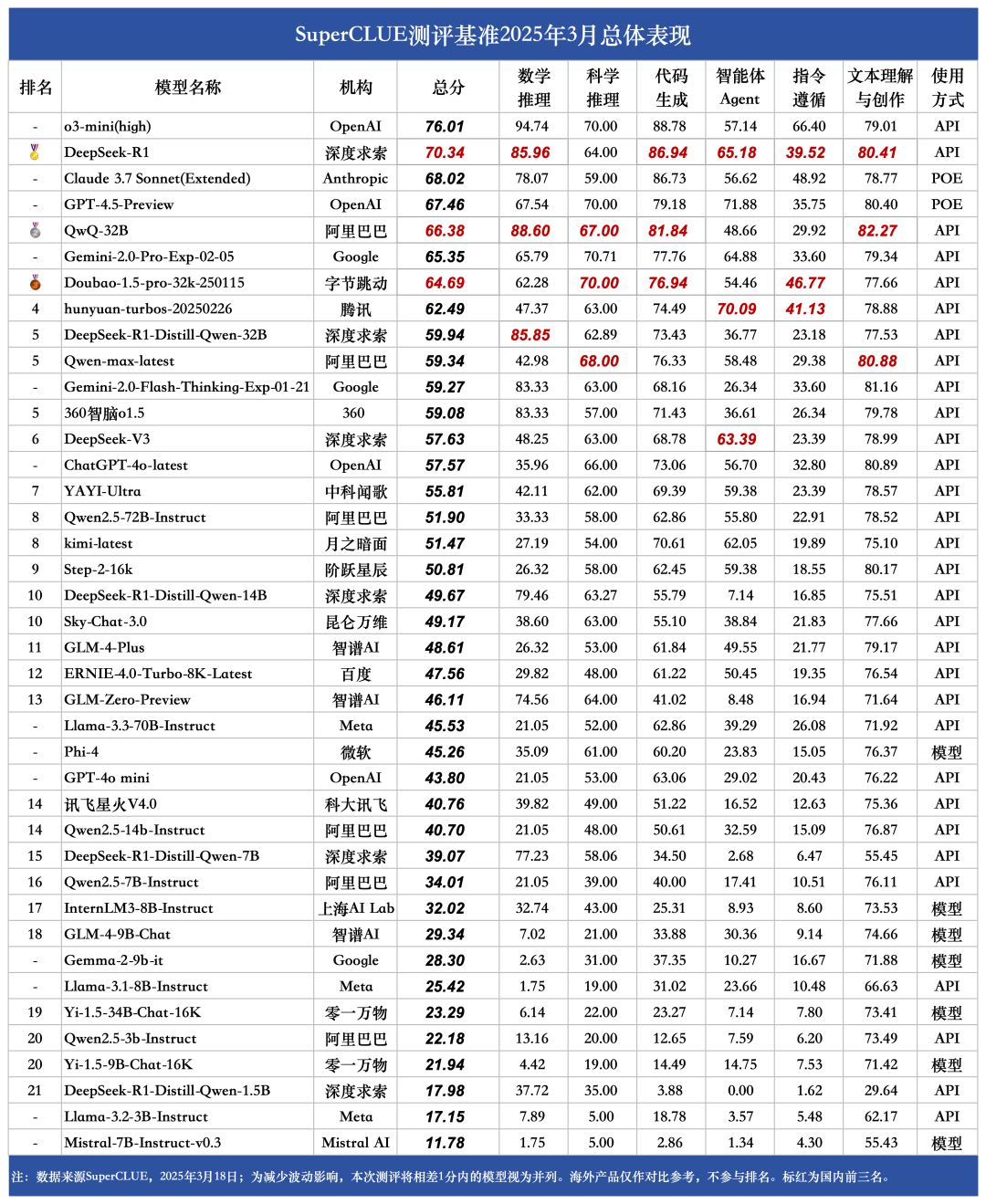
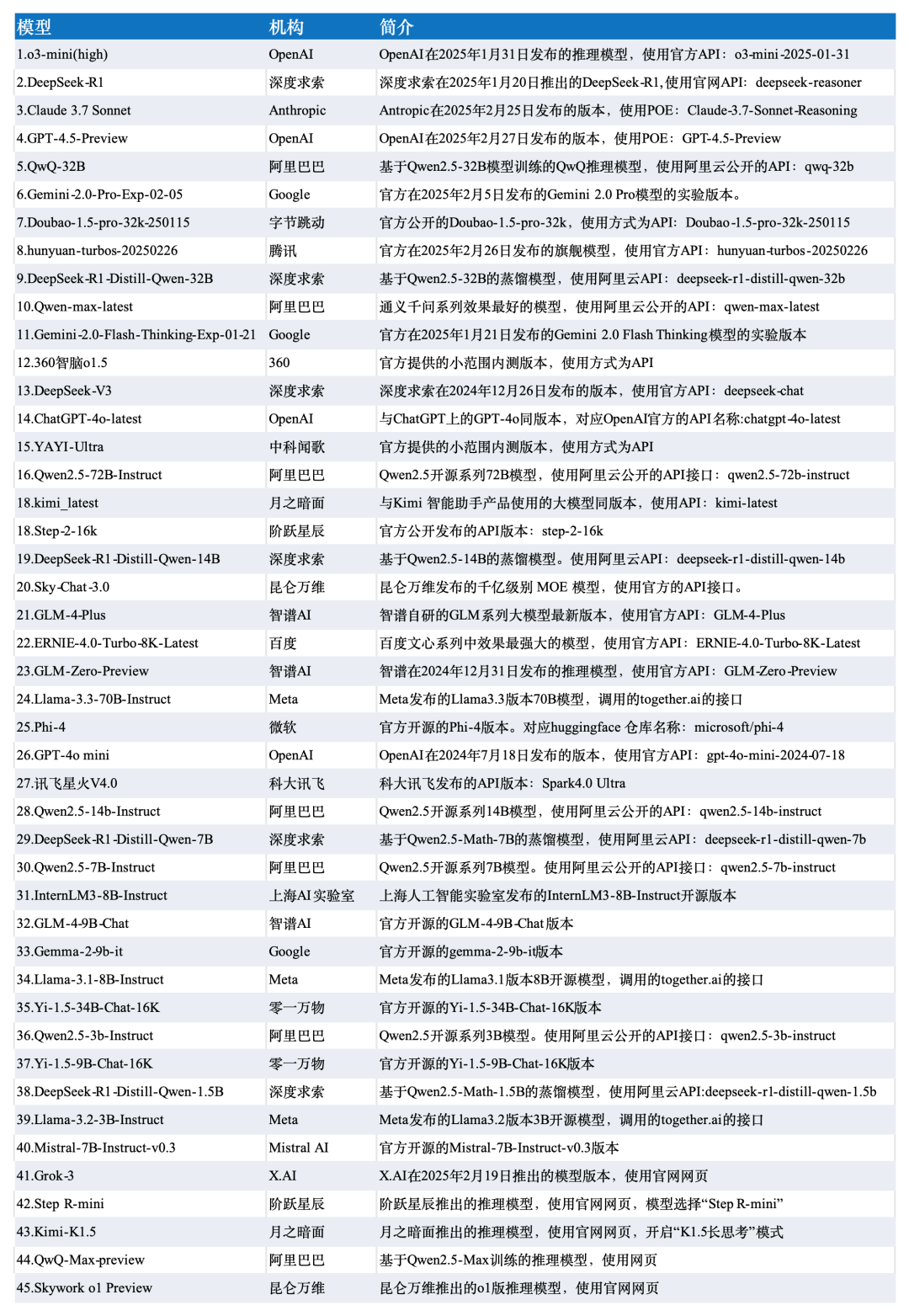
本次测评数据选取了SuperCLUE-3月测评结果,模型选取了国内外有代表性的45个大模型在3月份的版本。
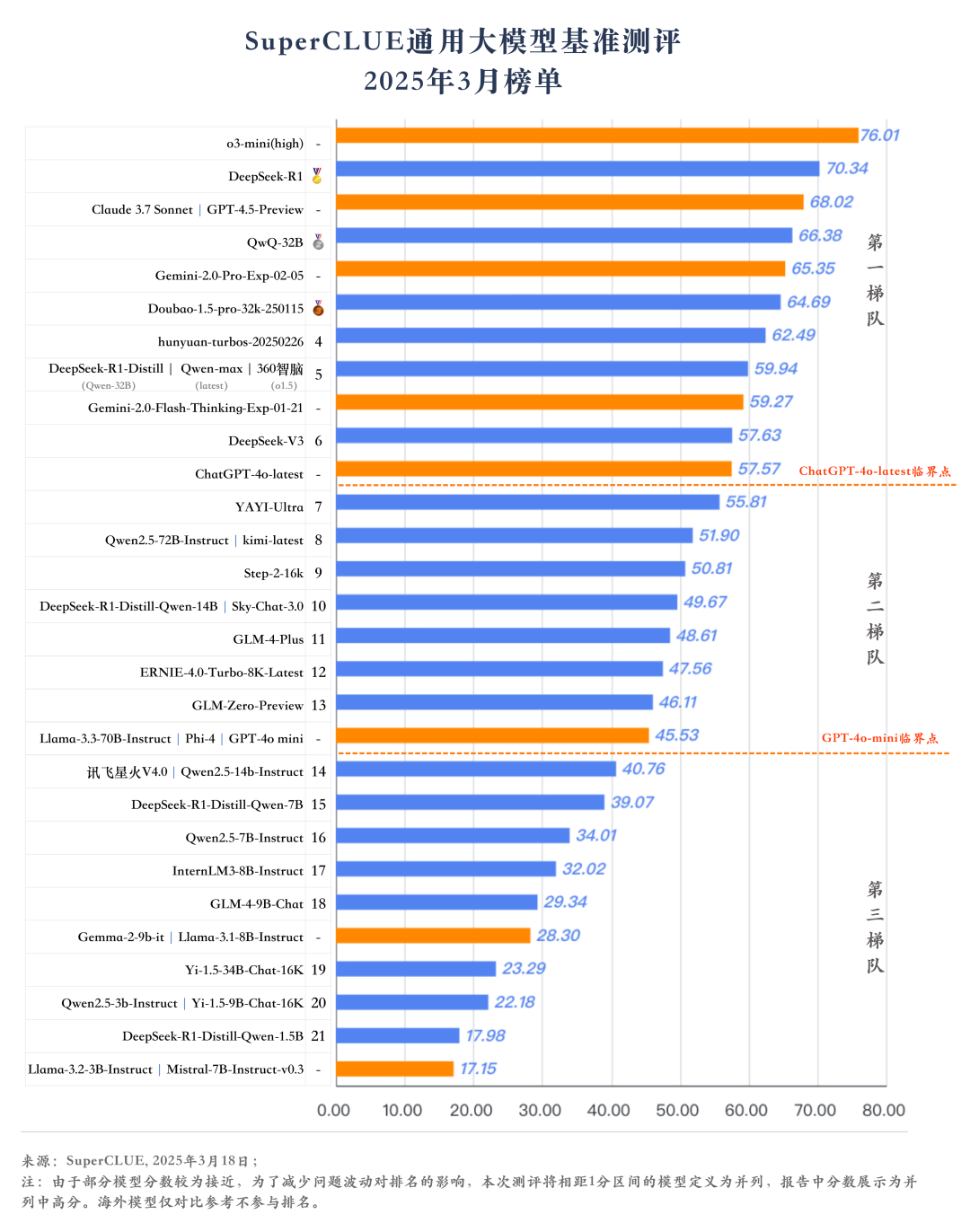
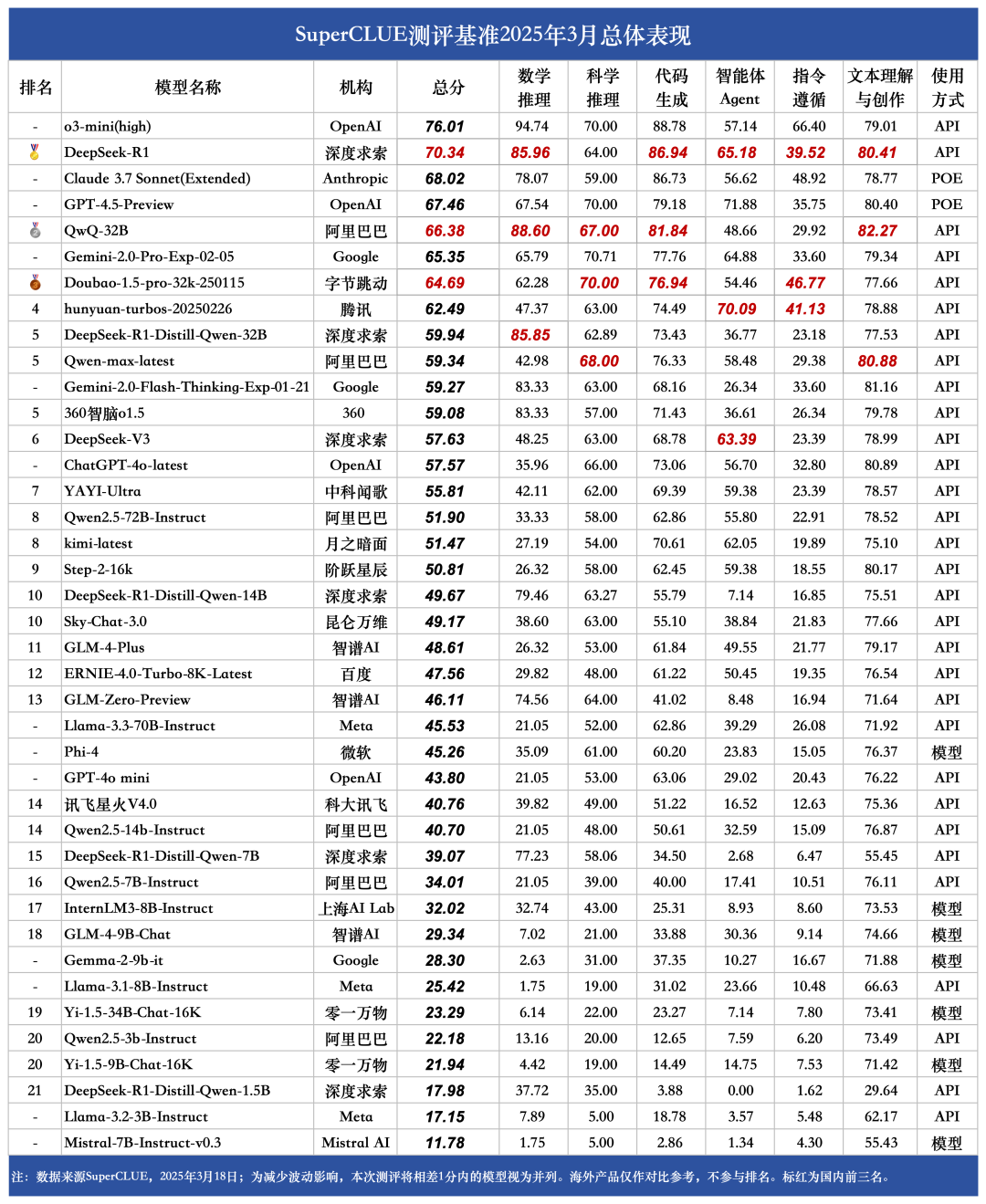
#2025年3月总榜
#2025年3月模型象限
关键内容3:DeepSeek-R1及其蒸馏模型对比
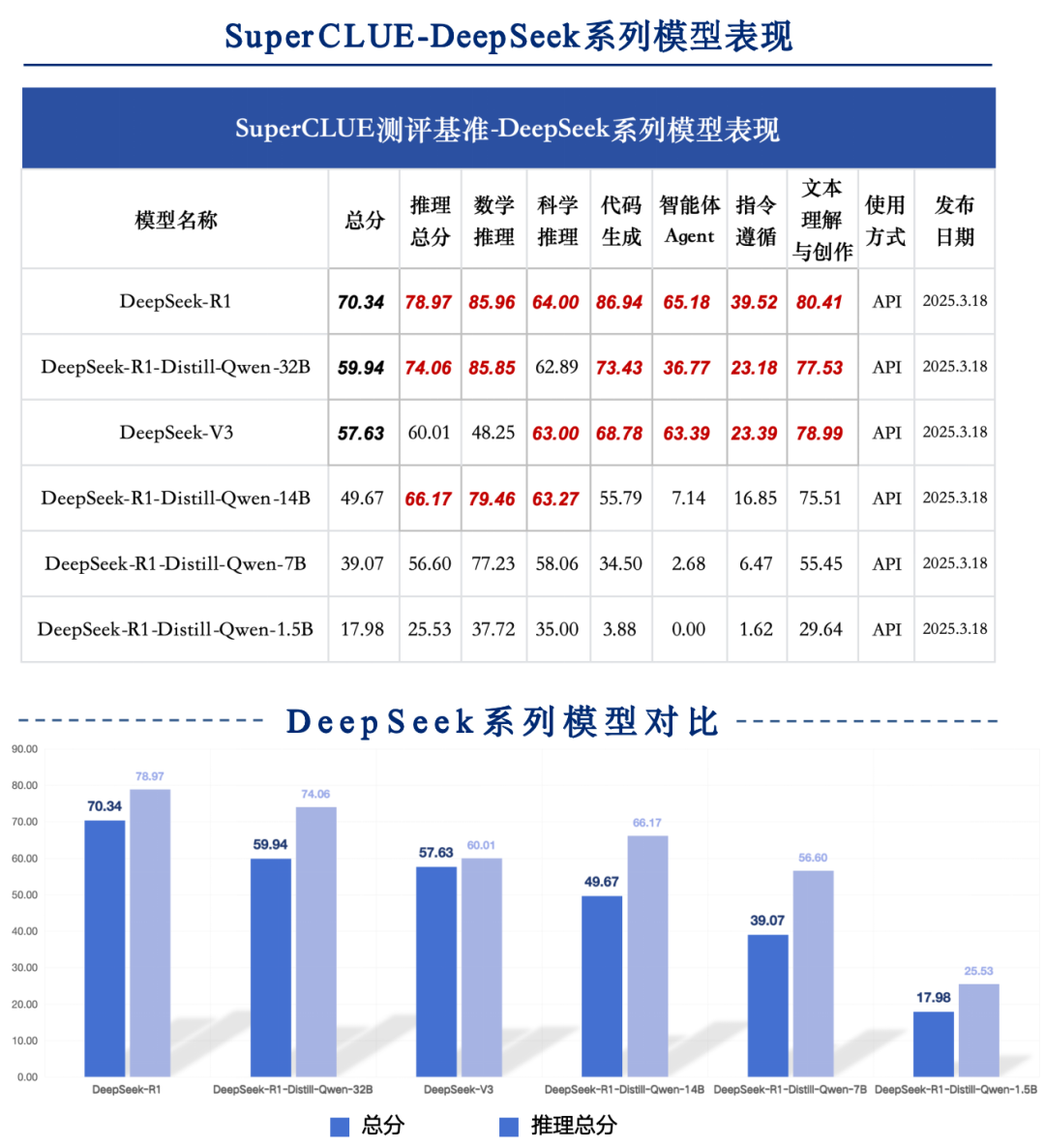
DeepSeek-R1在各个维度均排行第一
R1在总榜和推理任务榜单上得分均超过70,在六大任务维度上明显领先其他模型。DeepSeek-R1-Distill-Qwen-32B在数学、科学推理和文本创作与理解任务上和R1得分接近,但在其余任务上相差10-30分左右。
推理模型在总榜和推理任务榜单上分差较大
R1和R1系列的蒸馏模型在总榜和任务榜单上的得分差距在10-20分之间,如R1在推理任务上的得分比在总榜上高出7分,DeepSeek-R1-Distill-Qwen-14B有近17分的分差,但DeepSeek-V3分差在3分之内。
R1-Qwen蒸馏模型系列在推理任务中具有较高实用性
DeepSeek-R1在科学推理上的取得 64.00,与o3-mini(high)相差6分,与QwQ-32B相差3分,在科学推理任务上还有一定的提升空间。
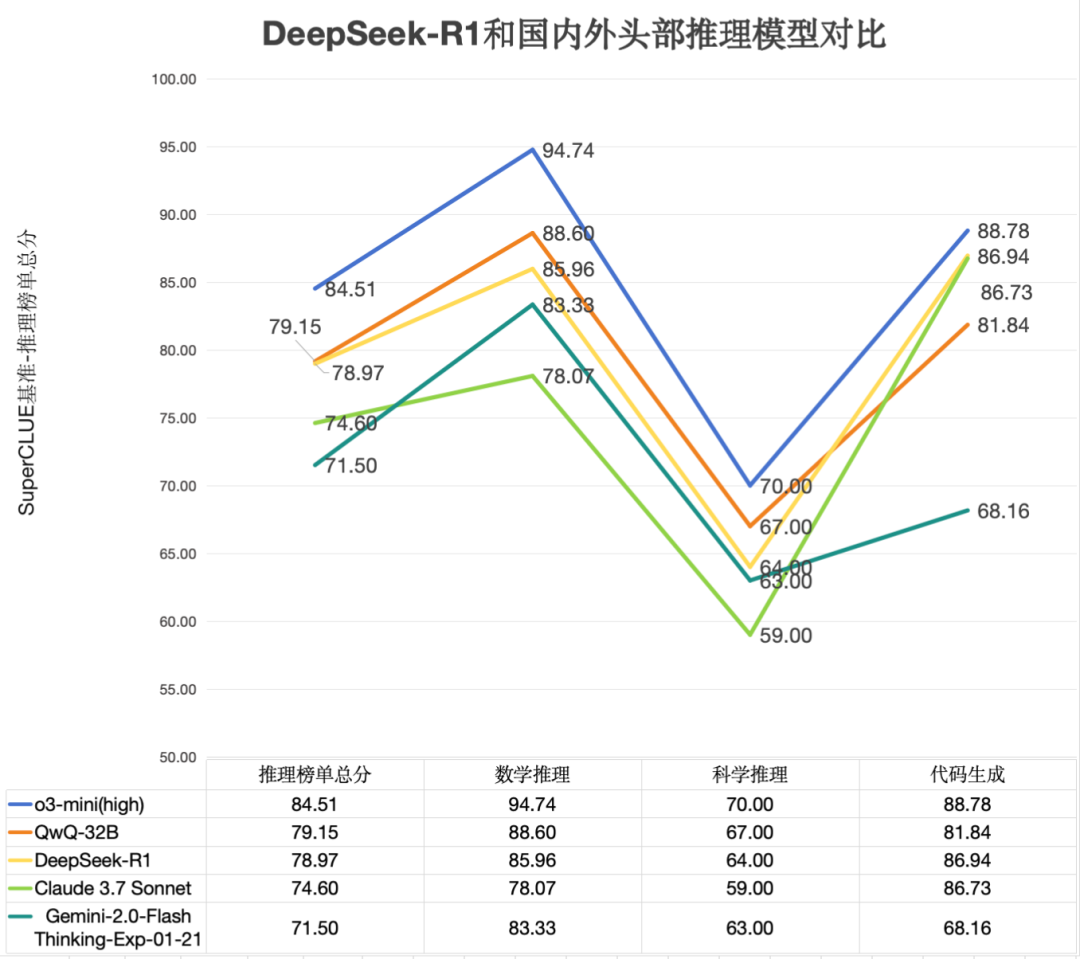
关键内容4: DeepSeek-R1和国内外推理模型对比
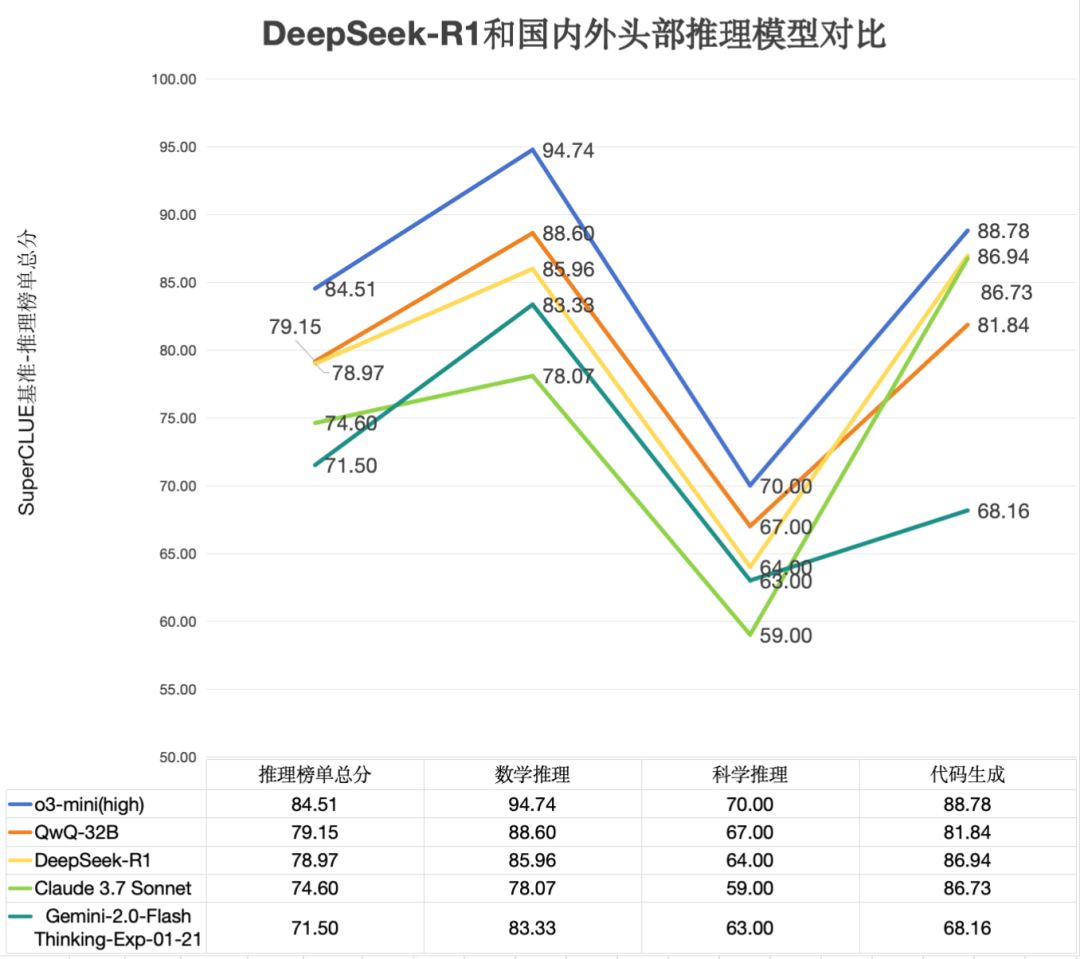
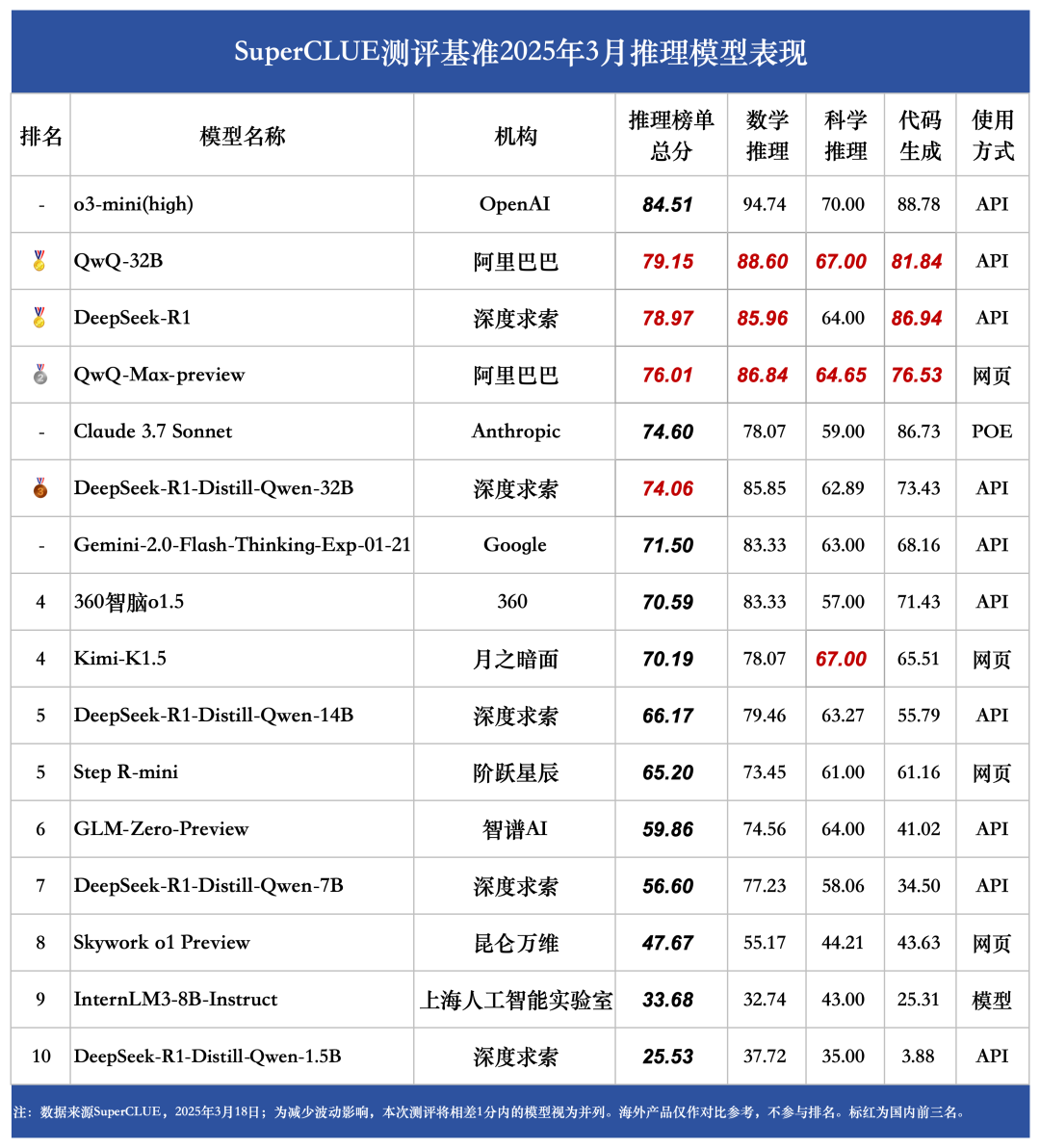
综合能力接近海外头部模型
DeepSeek-R1 推理总分 78.97,分别领先 Claude 3.7 Sonnet、 Gemini-2.0-Flash-Thinking-Exp-01-21近4.37、7.47分,与o3-mini(high)相差5.54分,展现出较强的推理能力
数学推理和代码生成任务表现优异
DeepSeek-R1 在数学推理和代码生成任务上得分均超过80分。在数学推理上得分 85.96,超过Claude 3.7 Sonnet近7.89分,和QwQ-32B得分接近;在代码生成任务上与o3-mini(high)仅差1.84分。
科学推理相对薄弱,仍需优化
DeepSeek-R1在科学推理上的取得 64.00,与o3-mini(high)相差6分,与QwQ-32B相差3分,在科学推理任务上还有一定的提升空间。
关键内容5:性价比区间分布
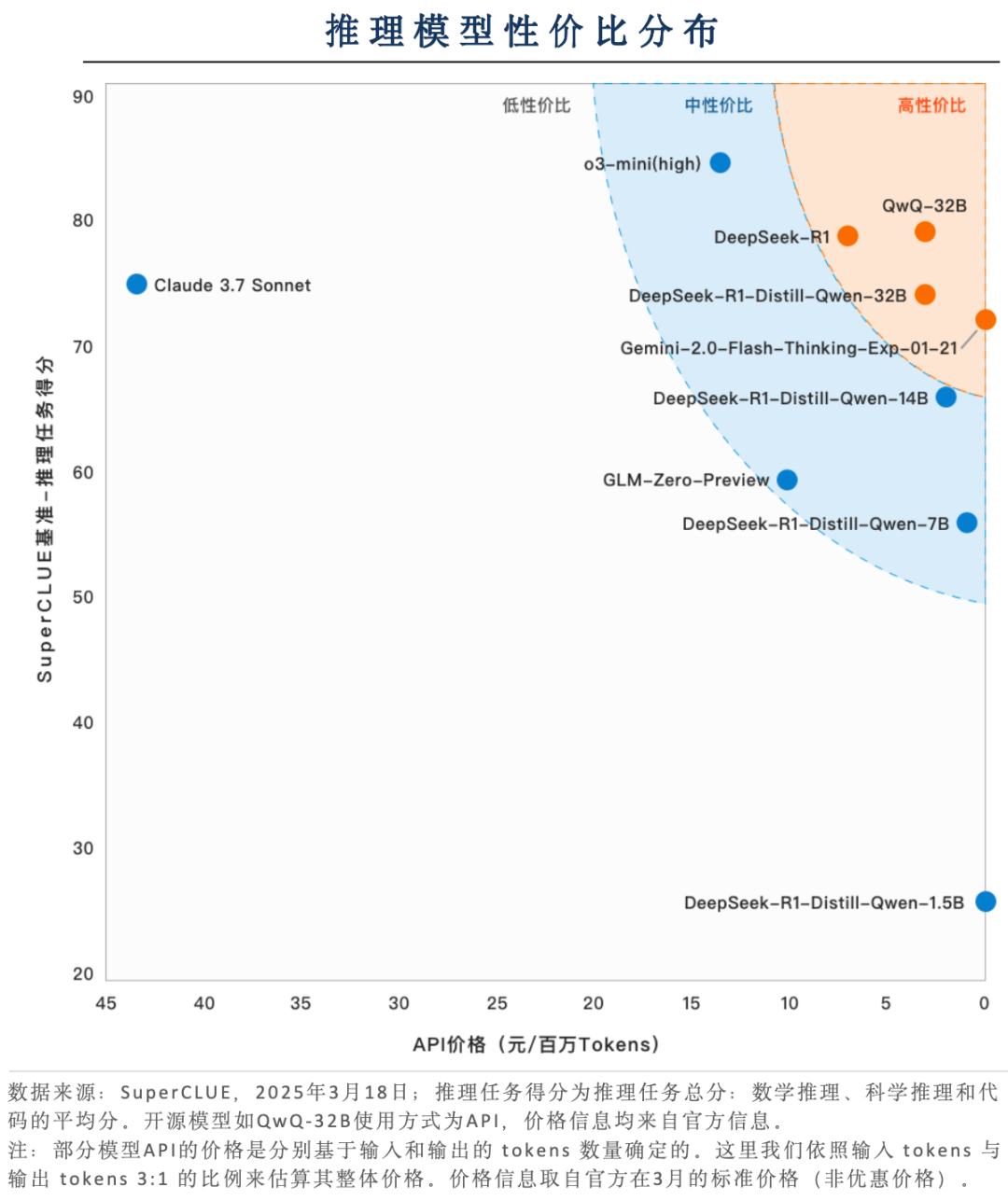
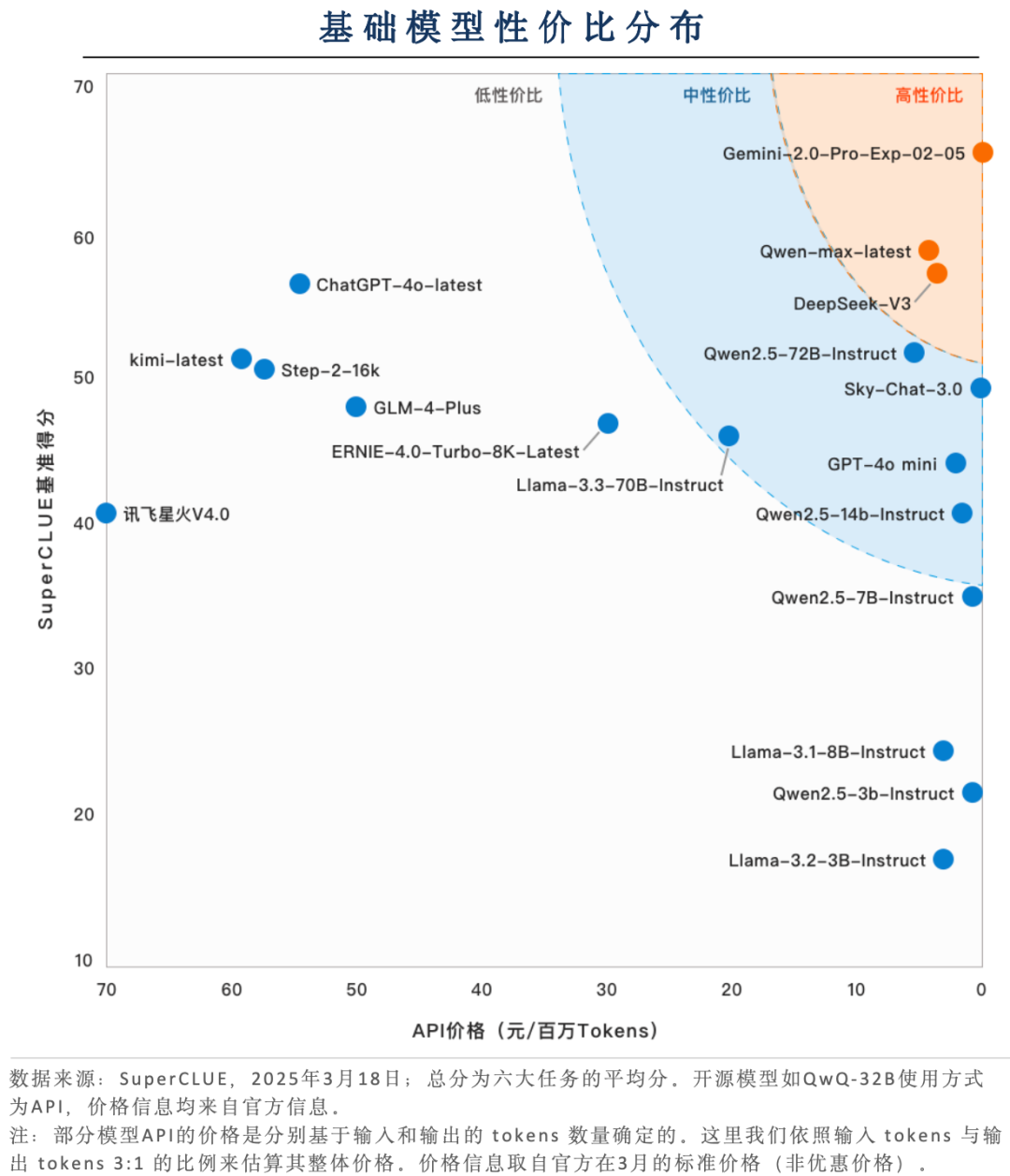
国产推理模型凭借较低的价格实现高质量输出,展现出显著的性价比优势。
国产推理模型QwQ-32B、DeepSeek-R1和DeepSeek-R1-Distill-Qwen-32B在性价比方面展现出强大竞争力。它们在保持高水平性能的同时,保持了极低的应用成本,展现出较好的落地可用性。而海外模型Gemini 2.0 Flash Thinking exp(暂时免费)也具备高性价比,但在推理任务上的表现略逊色于其他国产高性价比模型。
位于低性价比区间的基础模型较为集中,便可划分为高性高价和低性低价
位于低性价比区域的基础模型,在价格或性能上略逊于中高性价比模型,例如GPT-4o-latest,kimi-latest等价格较高但性能可圈可点;而Llama-3.2-3B-Instruct、Qwen2.5-3B-Instruct等的性能尚有提升空间,但价格较为实惠。表明这些模型的发展表面上显得过于片面,影响用户体验。
关键内容6:推理效率区间分布
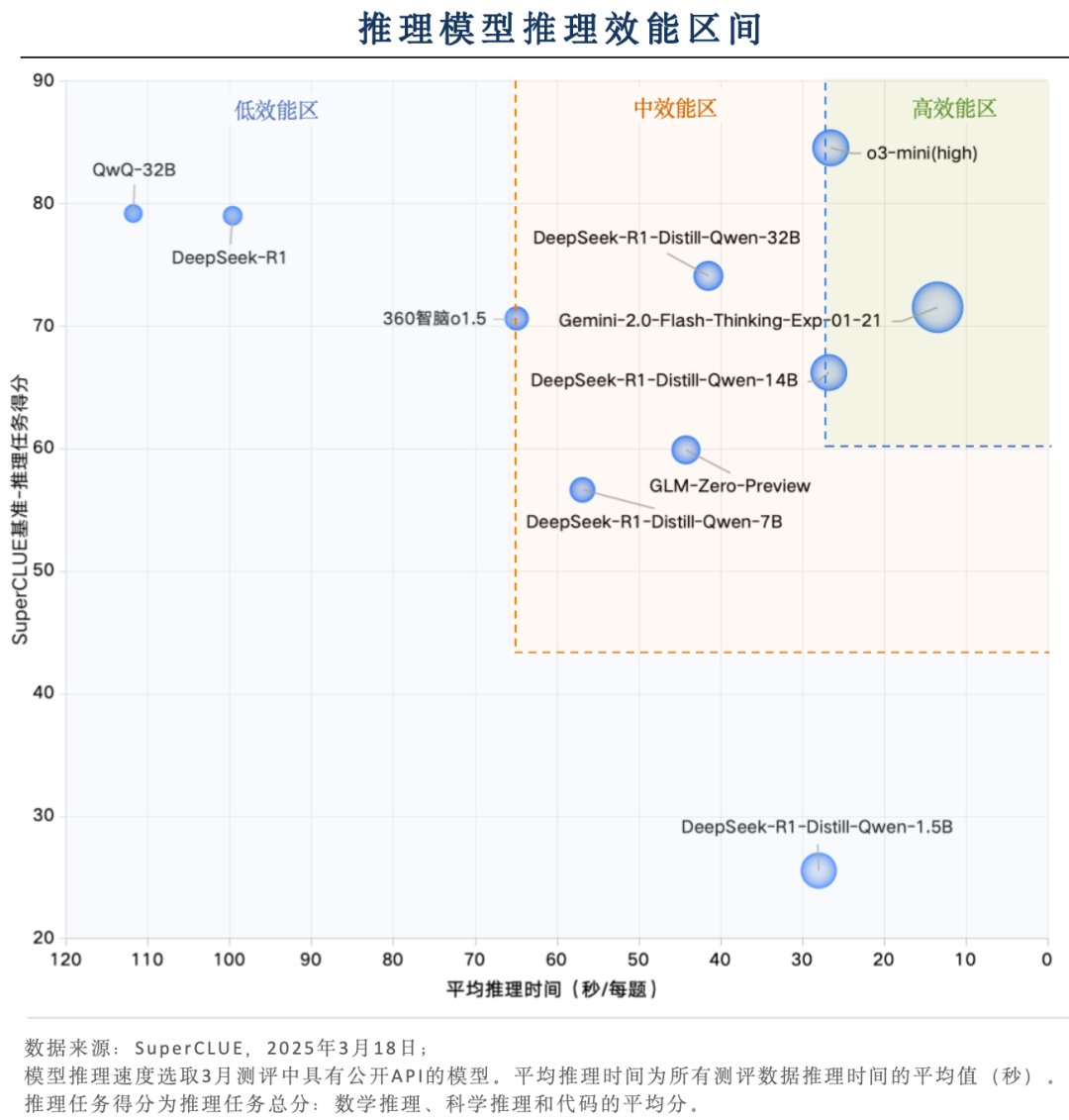
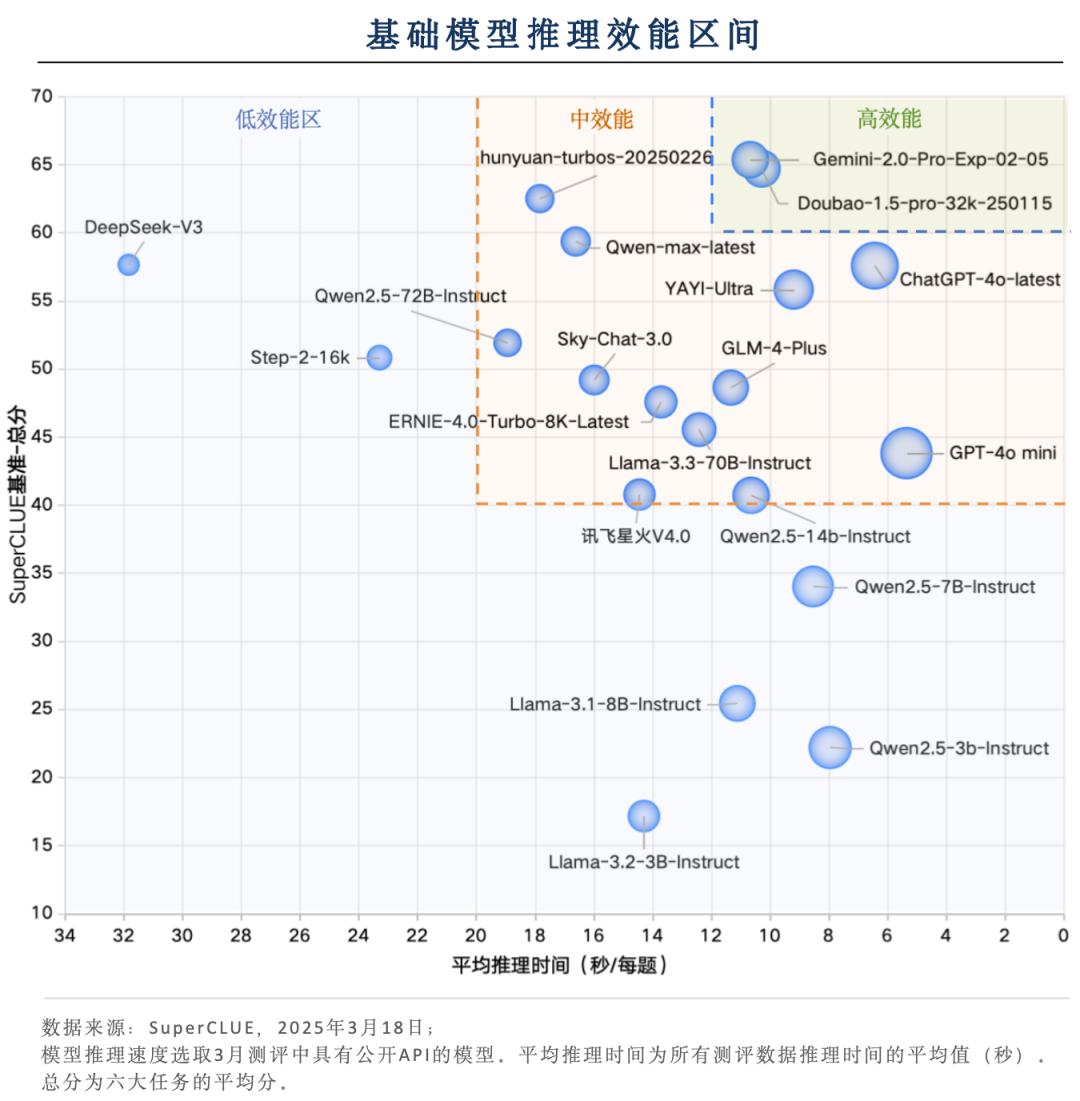
海外推理模型综合效能领先
o3-mini (high) 和 Gemini-2.0-Flash-Thinking-Exp-01-21 在推理速度和基准得分的综合表现上处于领先地位, 推理任务分数均在70分以上,平均推理耗时在30秒内。
国内推理模型大部分处于中低效能区间
国内推理模型中,QWQ-32B推理任务得分最高(79.15分),但平均推理耗时超过110秒。推理任务得分超过70分的国内推理模型,平均推理耗时均超过40秒。
国内基础模型综合效能与海外基础模型无明显优劣
在高效能区中,国内基础模型表现与海外基础模型在伯仲之间。中效能区中,国内基础模型表现与海外基础模型表现各有优劣,在推理速度上,ChatGPT-4o-latest和GPT-4o-mini领先,但在得分上只有hunyuan-turbos-20250226达到了60分。
关键内容7:2025年国内外大模型差距及趋势
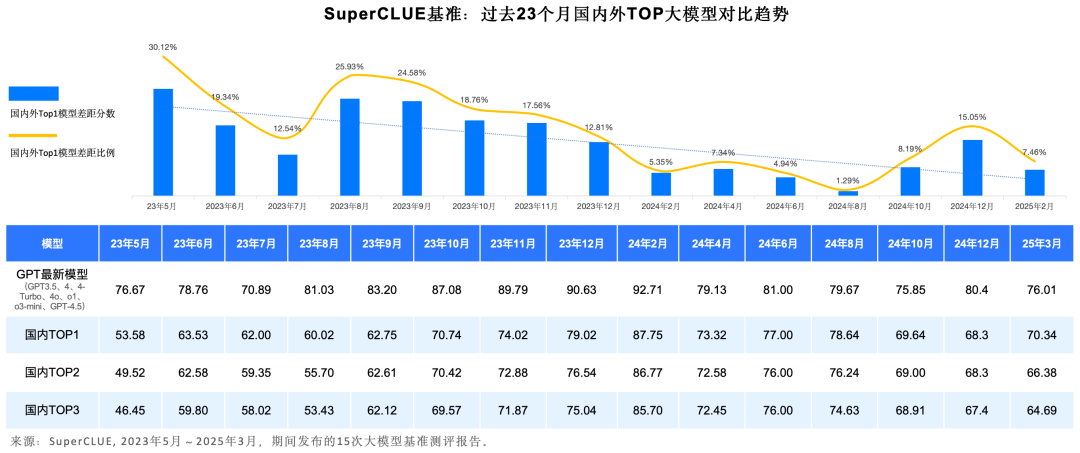
总体趋势上,国内外第一梯队大模型在中文领域的通用能力差距正在缩小。
2023年5月至今,国内外大模型能力持续发展。其中GPT系列模型为代表的海外最好模型经过了从GPT3.5、GPT4、GPT4-Turbo、GPT4o、o1、o3-mini、GPT-4.5的多个版本版迭代升级。
国内模型也经历了波澜壮阔的23个月的迭代周期。但随着DeepSeek-R1的发布,差距从15.05%缩小至7.46%。
关键内容8:榜单概览
#总榜
#推理模型总榜
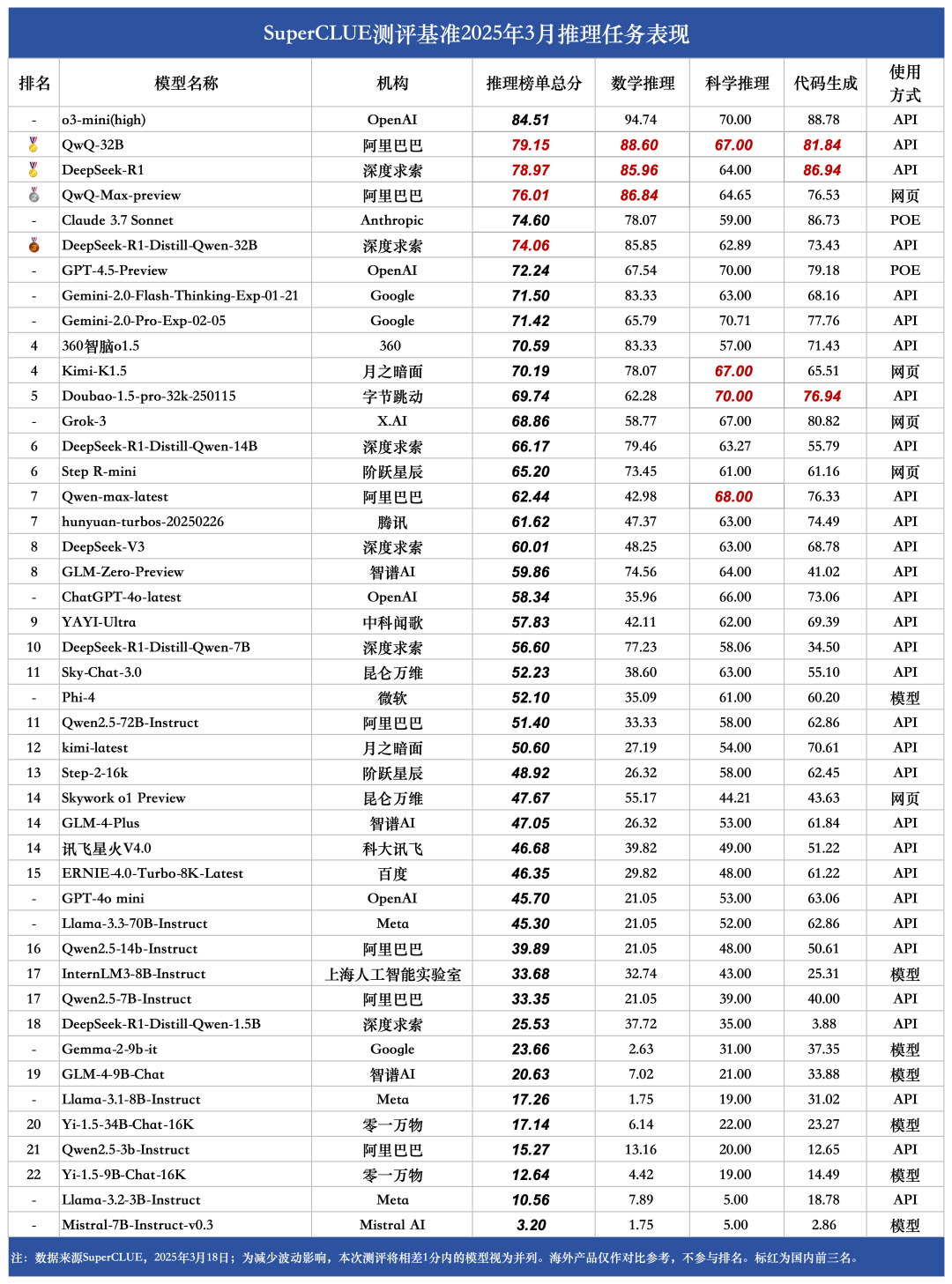
#推理任务总榜
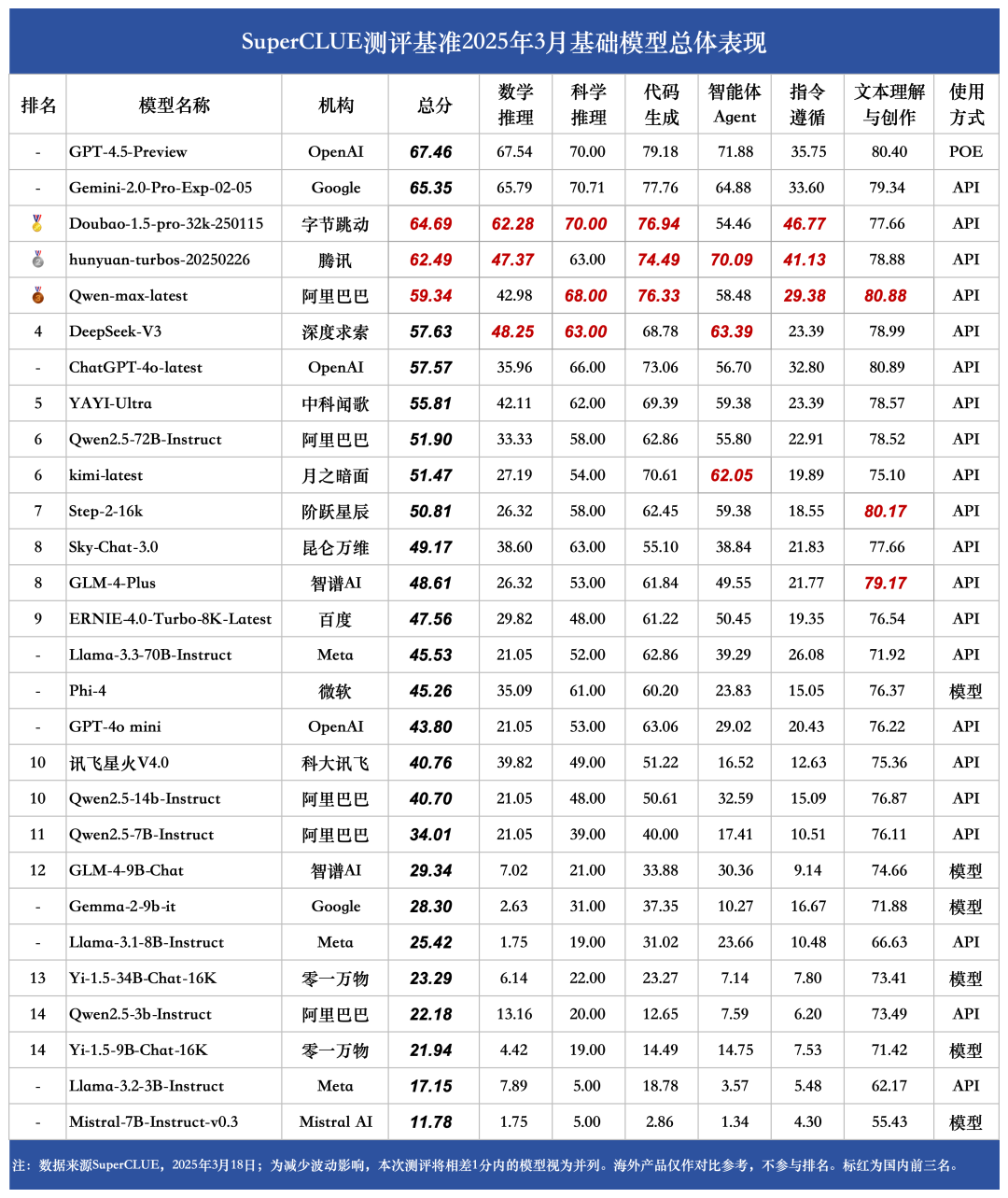
#基础模型总榜
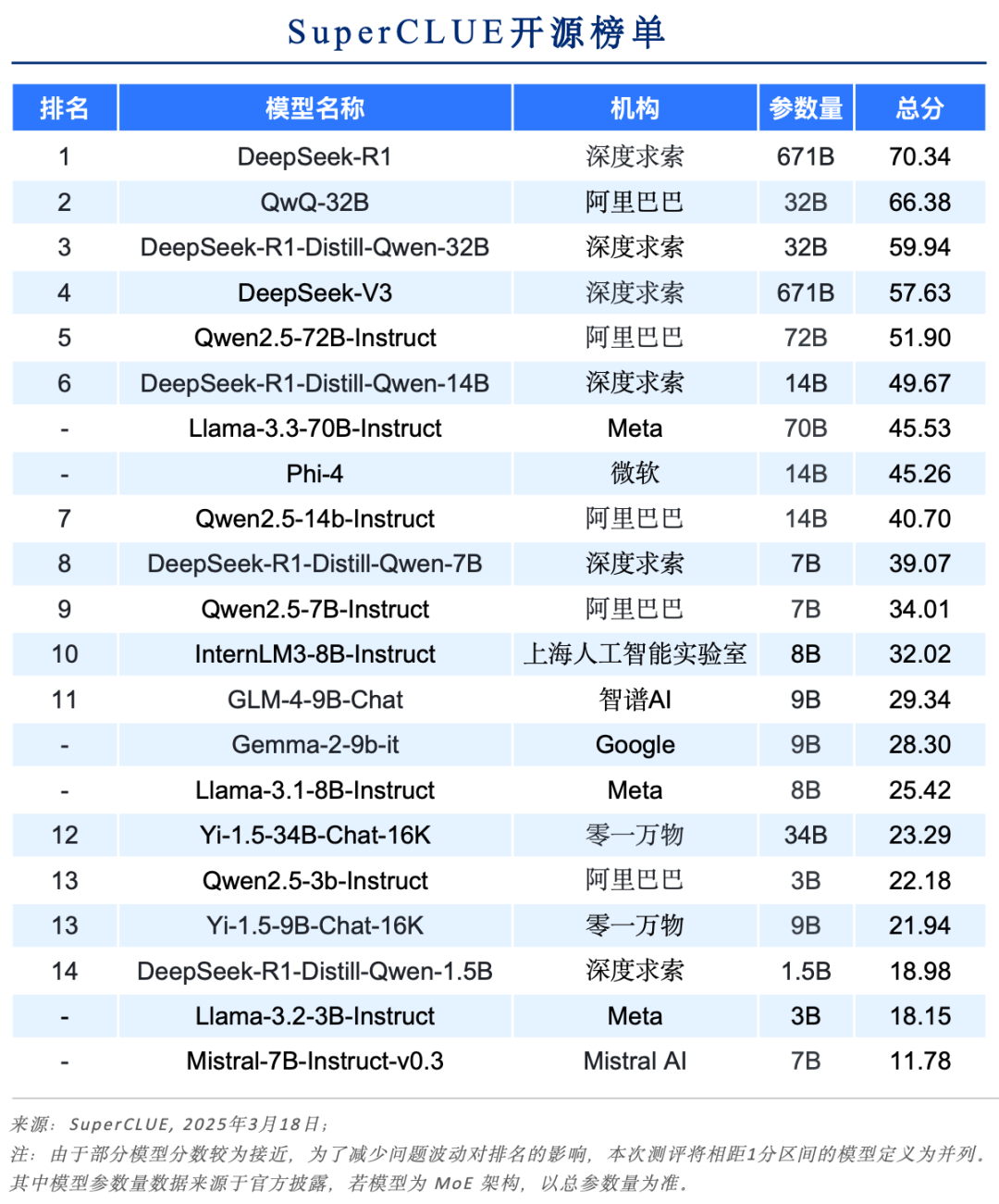
#开源模型榜单
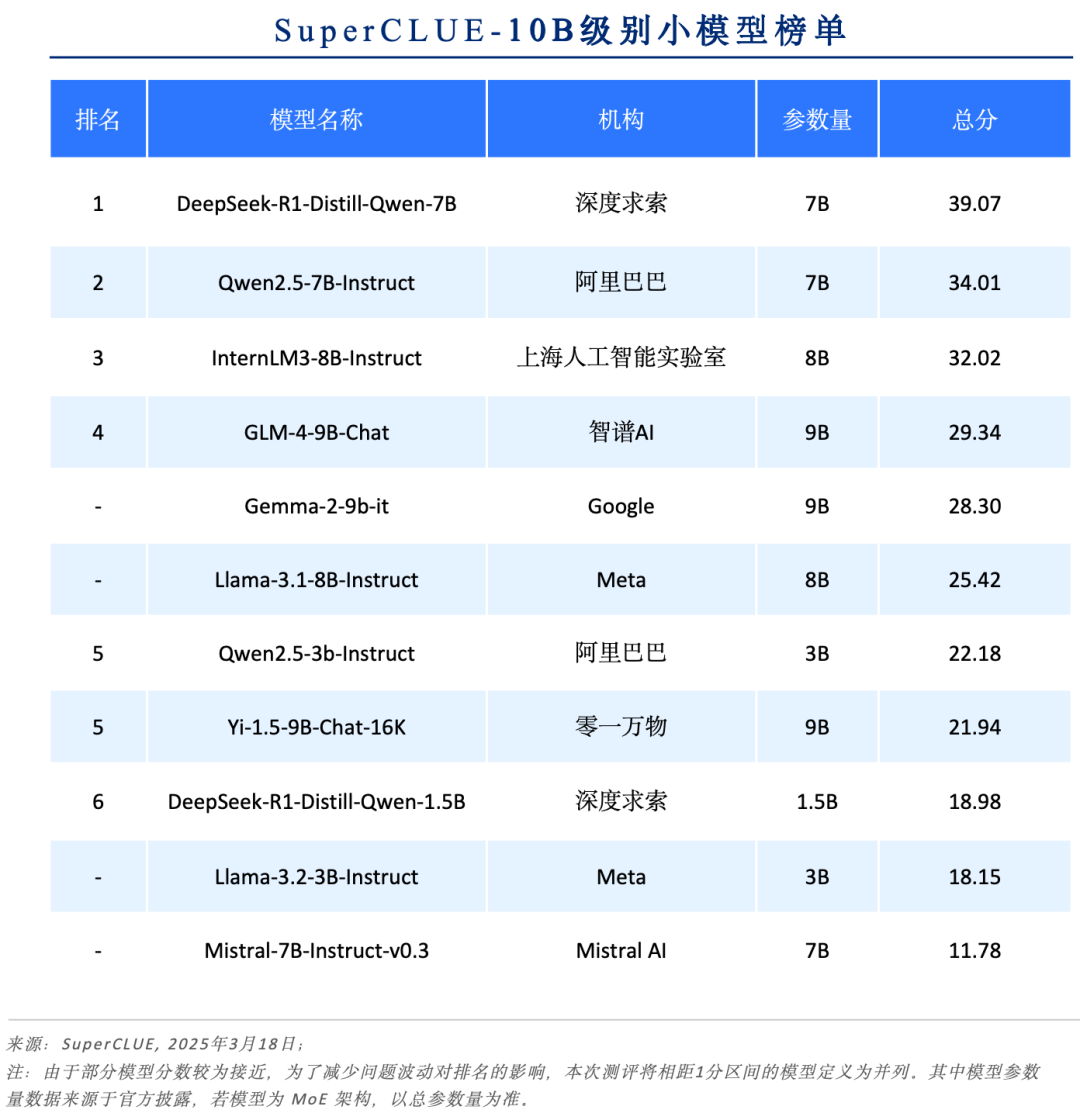
#10B以内模型榜单
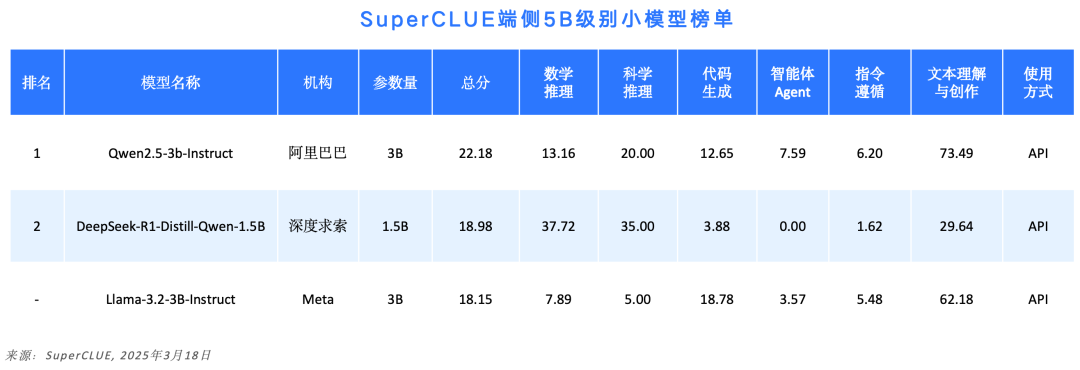
#5B以内端侧模型榜单

由于篇幅有限,本文仅展示报告中部分内容。完整内容包括测评方法、测评示例、子任务榜单、多模态、应用、推理基准介绍等。可点击文章底部【阅读原文】查看高清完整PDF版。
在线完整报告地址(可下载):
www.cluebenchmarks.com/superclue_2503
欢迎加入【2025年报告】交流群。


扩展阅读
[1] CLUE官网:www.CLUEBenchmarks.com
[2] SuperCLUE排行榜网站:www.superclueai.com
[3] Github地址:https://github.com/CLUEbenchmark/SuperCLUE

















 169
169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









