







项目简介
爬取趣头条新闻(http://home.qutoutiao.net/pages/home.html),具体内容:1、列表页(json):标题,简介、封面图、来源、发布时间
2、详情页(html):详细内容和图片
目录结构
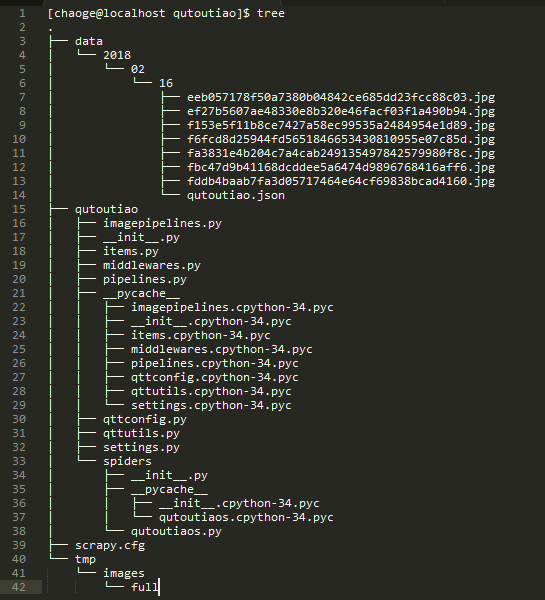
生成的数据文件-单条记录

主要代码说明
爬虫:#爬取趣头条列表和详情页
qutoutiao.spiders.qutoutiaos.QutoutiaosSpider
管道文件:
#封面图片处理类
qutoutiao.imagepipelines.CoverImagePipeline
#内容图片处理类
qutoutiao.imagepipelines.ContentImagePipeline
#数据处理类
qutoutiao.pipelines.QutoutiaoPipeline
中间件:
#请求头设置类-这里只设置了user agent
qutoutiao.middlewares.RandomUserAgent
#代理设置类
qutoutiao.middlewares.RandomProxy
自定义:
#配置文件
qutoutiao.qttconfig.py
#工具类
qutoutiao.qttutils.QttUtils
创建项目
cd /home/chaoge/mypython/crawler/scrapy startproject qutoutiao
创建爬虫类即(qutoutiao.spiders.qutoutiaos.QutoutiaosSpider)
cd qutoutiao/ qutoutiao/spidersscrapy genspider qutoutiaos "api.1sapp.com"
执行
scrapy crawl qutoutiaos
#scrapy crawl qutoutiaos --nolog#不显示log
#scrapy crawl qutoutiaos -o qutoutiaos_log.json #将log输出到qutoutiaos_log.json
代码实现
qutoutiao.qttconfig.py# 爬取域名(趣头条)
DOMAIN = 'http://home.qutoutiao.net/pages/home.html'
#数据存储路径
DATA_STORE = '/home/chaoge/mypython/crawler/qutoutiao/data'
#列表:http://api.1sapp.com/content/outList?cid=255&tn=1&page=1&limit=10
#列表API
LIST_API = 'http://api.1sapp.com/content/outList?'
#列表记录数
LIST_LIMIT = 10
#分类
CATEGORY_INFO = [
{"cid":255,"name":"推荐"},
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1004
1004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









